Transformer-Based Warm-Starting for Feasible and Optimal Terminal Approach to Tumbling Objects with Space Manipulators
Pith reviewed 2026-06-27 02:41 UTC · model grok-4.3
The pith
A causal transformer warm-start cuts SCP iteration count by 28 percent and runtime by 23 percent for space manipulator terminal approach to tumbling targets while preserving control-cost distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
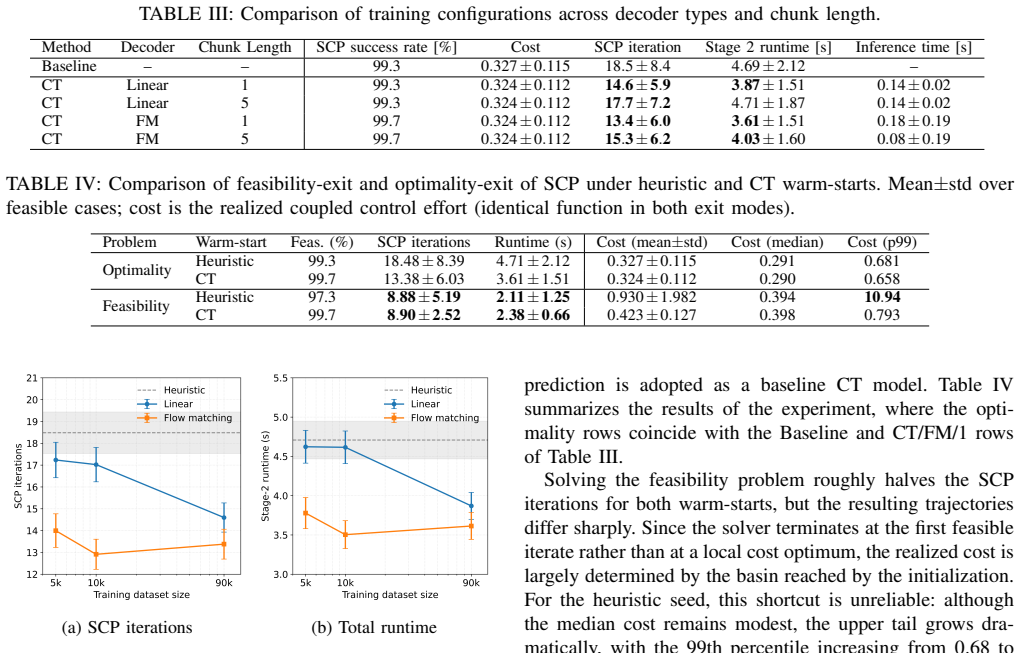
The central claim is that transformer-generated warm-starts for the attitude-manipulator stage of sequential convex programming reduce second-stage iteration count by up to 28 percent and runtime by 23 percent on held-out scenarios, preserve the final control-cost distribution, and, when used for feasibility projection, nearly halve runtime relative to cost-optimal SCP while eliminating the catastrophic high-cost tail seen with heuristic initialization.
What carries the argument
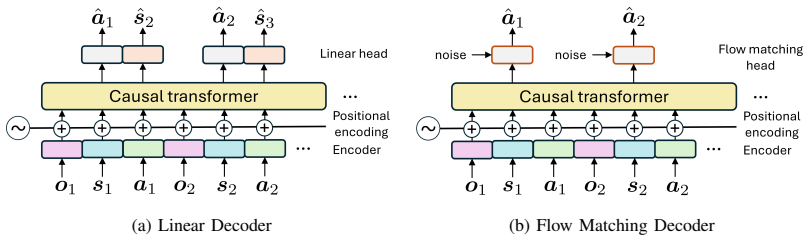
A causal transformer that predicts action chunks for the attitude-manipulator torque-allocation stage inside the second-stage SCP solver.
If this is right
- Second-stage SCP iteration counts drop by as much as 28 percent when the transformer supplies the initial guess.
- Overall solver runtime falls by 23 percent without altering the distribution of achieved control costs.
- Feasibility-projection solves using the learned starts run nearly twice as fast as cost-optimal SCP.
- High-cost outlier trajectories that appear under heuristic initialization disappear when the transformer warm-start is used.
Where Pith is reading between the lines
- The same warm-start architecture could be tested on other nonconvex trajectory problems that admit sequential convex programming, such as multi-agent docking or debris removal.
- Varying the action-chunk length or decoder type during training might produce further reductions in solver effort.
- Closing the loop with onboard vision would require checking whether perception noise still leaves the transformer outputs inside the basin of attraction of the SCP solver.
Load-bearing premise
The transformer trained on the chosen simulation datasets and chunking schemes continues to produce warm-starts that remain valid and non-degrading when passed to the SCP solver across the full range of tumbling target dynamics and visibility constraints.
What would settle it
Measure whether the reported iteration and runtime reductions, together with preservation of the control-cost distribution, still appear when the same transformer is evaluated on trajectories generated from a different dynamics simulator or from real hardware telemetry.
Figures

read the original abstract
Real-time trajectory generation for on-orbit robotic servicing is challenging due to the nonlinear coupling between spacecraft bus motion, manipulator dynamics, visibility cone, and trajectory-level safety constraints. This paper studies learning-based warm-starting for sequential convex programming (SCP) in the terminal approach of a space manipulator toward a tumbling target. The proposed framework decomposes the problem into a system center-of-mass translational planning stage and a coupled attitude--manipulator torque-allocation stage, and applies a causal transformer warm-start to the latter, which constitutes the dominant computational bottleneck. Linear and flow matching action decoders are compared under different action-chunking and training dataset sizes, and the resulting warm-starts are evaluated under both cost-optimal and feasibility projection using SCP. Across 300 held-out scenarios, the learned warm-start reduces the second-stage SCP iteration count by up to 28% and the runtime by 23% while preserving the final control-cost distribution. When the learned warm-starts are used for nonconvex feasibility projection, they nearly halve the runtime relative to cost-optimal SCP, while avoiding the catastrophic high-cost tail behavior observed when initialized heuristically. These results indicate that sequence-model warm-starts can improve both the computational efficiency and trajectory robustness of optimization-based terminal guidance for space manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a causal transformer-based warm-starting method for sequential convex programming (SCP) in the terminal approach phase of space manipulators to tumbling targets. The approach decomposes the problem into center-of-mass translation and attitude-manipulator torque allocation stages, with the transformer applied to the latter bottleneck stage. It compares linear and flow matching action decoders with different chunking and dataset sizes, and demonstrates on 300 held-out scenarios reductions of up to 28% in SCP iterations and 23% in runtime for cost-optimal SCP, and nearly halved runtime for feasibility projection without high-cost tails.
Significance. If the empirical results generalize, the method offers a promising way to accelerate real-time trajectory optimization for on-orbit servicing by providing effective warm-starts that maintain solution quality. The comparison of decoder variants and the dual evaluation under cost-optimal and feasibility modes provide useful insights into practical deployment of learning for optimization warm-starting in robotics.
major comments (2)
- [Abstract] The reported gains (up to 28% iteration reduction and 23% runtime reduction on 300 held-out scenarios) are presented without error bars, variance measures, or details on training hyperparameters and dataset-size controls, which undermines verification that the central performance figures are robust.
- [Evaluation on held-out scenarios] All 300 held-out scenarios are drawn from the same simulation distribution used for training; no experiments evaluate performance under tumbling dynamics or visibility constraints outside this support, which is load-bearing for the claim that the warm-starts remain valid and non-degrading across the full operational range.
minor comments (1)
- [Abstract] The abstract references comparisons across action-chunking schemes and dataset sizes but does not state the specific configurations or sizes that produced the headline 28% and 23% figures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on result robustness and evaluation scope. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] The reported gains (up to 28% iteration reduction and 23% runtime reduction on 300 held-out scenarios) are presented without error bars, variance measures, or details on training hyperparameters and dataset-size controls, which undermines verification that the central performance figures are robust.
Authors: We agree that variance measures would improve verifiability of the reported gains. While the manuscript already includes comparisons across dataset sizes and decoder variants, the revised version will add error bars or standard deviations (computed over repeated training runs or scenario batches) to the abstract and evaluation figures. Training hyperparameters and explicit dataset-size controls will be documented in the methods or an appendix. revision: yes
-
Referee: [Evaluation on held-out scenarios] All 300 held-out scenarios are drawn from the same simulation distribution used for training; no experiments evaluate performance under tumbling dynamics or visibility constraints outside this support, which is load-bearing for the claim that the warm-starts remain valid and non-degrading across the full operational range.
Authors: The 300 scenarios are sampled from the training distribution, consistent with standard in-distribution evaluation. The manuscript's claims and abstract are scoped to these held-out cases; we will revise the text to explicitly delimit the evaluation domain and remove any phrasing that could be read as asserting out-of-distribution robustness. New experiments outside the training support are not feasible within the current revision but represent a natural direction for follow-on work. revision: partial
Circularity Check
No circularity: empirical performance metrics on held-out data do not reduce to fitted inputs or self-citations by construction
full rationale
The paper's central results consist of measured runtime and iteration reductions (up to 28% and 23%) plus feasibility improvements on 300 held-out scenarios drawn from the training distribution. These are direct empirical observations from running the trained transformer warm-starts inside an external SCP solver; they are not derived quantities that equal the training loss or any fitted parameter by algebraic identity. No self-definitional equations, no renaming of known results as novel derivations, and no load-bearing self-citations appear in the provided abstract or reader summary. The method description (decomposition into CoM and attitude-manipulator stages, causal transformer with action decoders) is a standard pipeline whose outputs are validated externally rather than tautologically. Generalization concerns raised by the skeptic pertain to experimental coverage, not to any step that collapses the claimed derivation to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sequential convex programming produces feasible and locally optimal solutions when supplied with a sufficiently good initial guess.
Reference graph
Works this paper leans on
-
[1]
Equa- tions of motion of free-floating spacecraft-manipulator systems: an engineer’s tutorial,
M. Wilde, S. Kwok Choon, A. Grompone, and M. Romano, “Equa- tions of motion of free-floating spacecraft-manipulator systems: an engineer’s tutorial,”Frontiers in Robotics and AI, vol. 5, p. 41, 2018
2018
-
[2]
Motion planning for the on-orbit grasping of a non- cooperative target satellite with collision avoidance,
R. Lampariello, “Motion planning for the on-orbit grasping of a non- cooperative target satellite with collision avoidance,”i-SAIRAS 2010, 2010
2010
-
[3]
A convex-programming-based guidance algorithm to capture a tumbling object on orbit using a spacecraft equipped with a robotic manipulator,
J. Virgili-Llop, C. Zagaris, R. Zappulla, A. Bradstreet, and M. Ro- mano, “A convex-programming-based guidance algorithm to capture a tumbling object on orbit using a spacecraft equipped with a robotic manipulator,”The International journal of robotics research, vol. 38, no. 1, pp. 40–72, 2019
2019
-
[4]
Transformers for trajectory optimization with application to spacecraft rendezvous,
T. Guffanti, D. Gammelli, S. D’Amico, and M. Pavone, “Transformers for trajectory optimization with application to spacecraft rendezvous,” inIEEE Aerospace Conference, pp. 1–13, 2024
2024
-
[5]
Transformer-based model predictive control: Trajectory optimization via sequence modeling,
D. Celestini, D. Gammelli, T. Guffanti, S. D’Amico, E. Capello, and M. Pavone, “Transformer-based model predictive control: Trajectory optimization via sequence modeling,”IEEE Robotics and Automation Letters, vol. 9, no. 11, pp. 9820–9827, 2024
2024
-
[6]
Towards robust spacecraft trajectory optimization via transformers,
Y . Takubo, T. Guffanti, D. Gammelli, M. Pavone, and S. D’Amico, “Towards robust spacecraft trajectory optimization via transformers,” in2025 IEEE Aerospace Conference, pp. 1–13, IEEE, 2025
2025
-
[7]
Agile tradespace exploration for space rendezvous mission design via trans- formers,
Y . Takubo, D. Gammelli, M. Pavone, and S. D’Amico, “Agile tradespace exploration for space rendezvous mission design via trans- formers,” inIEEE Aerospace Conference, 2026
2026
-
[8]
Decision transformer: Reinforcement learning via sequence modeling,
L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, and I. Mordatch, “Decision transformer: Reinforcement learning via sequence modeling,”Conf. on Neural Information Processing Systems, vol. 34, pp. 15084–15097, 2021
2021
-
[9]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown,et al., “π 0: A vision-language-action flow model for general robot control,”arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Language-conditioned safe trajectory generation for spacecraft rendezvous,
Y . Takubo, A. Dwivedi, S. Ramkumar, L. A. Pabon, D. Gammelli, M. Pavone, and S. D’Amico, “Language-conditioned safe trajectory generation for spacecraft rendezvous,”AIAA Journal of Guidance, Control, and Dynamics (accepted), 2026
2026
-
[11]
Conditioned se- quence models for warm-starting sequential convex trajectory opti- mization in space robots,
M. D’Ambrosio, S. Silvestrini, and M. Lavagna, “Conditioned se- quence models for warm-starting sequential convex trajectory opti- mization in space robots,”Aerospace, vol. 13, no. 2, p. 137, 2026
2026
-
[12]
Convex Optimization for Trajectory Generation: A Tutorial on Generating Dynamically Feasible Trajectories Reliably and Efficiently,
D. Malyuta, T. P. Reynolds, M. Szmuk, T. Lew, R. Bonalli, M. Pavone, and B. Ac ¸ıkmes ¸e, “Convex Optimization for Trajectory Generation: A Tutorial on Generating Dynamically Feasible Trajectories Reliably and Efficiently,”IEEE Control Systems Magazine, vol. 42, no. 5, pp. 40– 113, 2022
2022
-
[13]
A review of space robotics technologies for on-orbit servicing,
A. Flores-Abad, O. Ma, K. Pham, and S. Ulrich, “A review of space robotics technologies for on-orbit servicing,”Progress in aerospace sciences, vol. 68, pp. 1–26, 2014
2014
-
[14]
Robotic manipulation and capture in space: A survey,
E. Papadopoulos, F. Aghili, O. Ma, and R. Lampariello, “Robotic manipulation and capture in space: A survey,”Frontiers in Robotics and AI, vol. 8, p. 686723, 2021
2021
-
[15]
Generating feasible trajectories for autonomous on-orbit grasping of spinning debris in a useful time,
R. Lampariello and G. Hirzinger, “Generating feasible trajectories for autonomous on-orbit grasping of spinning debris in a useful time,” in2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 5652–5659, IEEE, 2013
2013
-
[16]
Control barrier functions for safe real-time control of spacecraft onboard robotic manipulators,
J. L. Loettgen, K. Worrall, G. Aragon-Camerasa, M. Ceriotti, and R. Lampariello, “Control barrier functions for safe real-time control of spacecraft onboard robotic manipulators,” in2025 International Conference on Space Robotics (iSpaRo), pp. 539–546, IEEE, 2025
2025
-
[17]
Coupled control of chaser platform and robot arm for the e. deorbit mission,
J. Telaar, S. Estable, M. De Stefano, W. Rackl, R. Lampariello, F. Ankersen, and J. G. Fernandez, “Coupled control of chaser platform and robot arm for the e. deorbit mission,” in10th Int. ESA conference on Guidance Navigation and Control Systems (GNC), p. 4, 2017
2017
-
[18]
Filtering-linearization: A first-order method for nonconvex trajectory optimization with filter- based warm-starting,
M. Yuan, R. J. Caverly, and Y . Yu, “Filtering-linearization: A first-order method for nonconvex trajectory optimization with filter- based warm-starting,” in2025 American Control Conference (ACC), pp. 547–552, IEEE, 2025
2025
-
[19]
Deep learning warm starts for trajectory optimization on the international space station,
S. Banerjee, A. Cauligi, and M. Pavone, “Deep learning warm starts for trajectory optimization on the international space station,” in Proceedings of the Space Robotics Workshop at Robotics: Science and Systems (RSS), 2025
2025
-
[20]
Transformer-based tight constraint prediction for efficient powered descent guidance,
J. Briden, T. Gurga, B. Johnson, A. Cauligi, and R. Linares, “Transformer-based tight constraint prediction for efficient powered descent guidance,”Journal of Guidance, Control, and Dynamics, vol. 48, no. 5, pp. 1054–1070, 2025
2025
-
[21]
Guided policy search,
S. Levine and V . Koltun, “Guided policy search,” inInternational conference on machine learning, pp. 1–9, PMLR, 2013
2013
-
[22]
Guided pol- icy search using sequential convex programming for initialization of trajectory optimization algorithms,
T. Kim, P. Elango, D. Malyuta, and B. Ac ¸ıkmes ¸e, “Guided pol- icy search using sequential convex programming for initialization of trajectory optimization algorithms,” in2022 American Control Conference (ACC), pp. 3572–3578, IEEE, 2022
2022
-
[23]
A robust observation, plan- ning, and control pipeline for autonomous rendezvous with tumbling targets,
K. Albee, C. Oestreich, C. Specht, A. Ter ´an Espinoza, J. Todd, I. Hokaj, R. Lampariello, and R. Linares, “A robust observation, plan- ning, and control pipeline for autonomous rendezvous with tumbling targets,”Frontiers in Robotics and AI, vol. 8, p. 641338, 2021
2021
-
[24]
Spacecraft robotics toolkit: An open-source simulator for spacecraft robotic arm dynamic modeling and control,
J. Virgili-Llop, J. V . Drew, and M. Romano, “Spacecraft robotics toolkit: An open-source simulator for spacecraft robotic arm dynamic modeling and control,” in6th International Conference on Astrody- namics Tools and Techniques (ICATT), (Darmstadt, Germany), 2016
2016
-
[25]
Terminal guidance system for satel- lite rendezvous,
W. Clohessy and R. Wiltshire, “Terminal guidance system for satel- lite rendezvous,”Journal of the aerospace sciences, vol. 27, no. 9, pp. 653–658, 1960
1960
-
[26]
Successive convexification of non-convex optimal control problems and its convergence properties,
Y . Mao, M. Szmuk, and B. Ac ¸ıkmes ¸e, “Successive convexification of non-convex optimal control problems and its convergence properties,” in2016 IEEE 55th Conference on Decision and Control (CDC), pp. 3636–3641, IEEE, 2016
2016
-
[27]
Successive convexification with feasibility guarantee via augmented lagrangian for non-convex optimal control problems,
K. Oguri, “Successive convexification with feasibility guarantee via augmented lagrangian for non-convex optimal control problems,” in Proc. IEEE Conf. on Decision and Control, pp. 3296–3302, IEEE, 2023
2023
-
[28]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,”arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.