SpeechDx: A Multi-Task Benchmark for Clinical Speech AI
Pith reviewed 2026-06-27 03:05 UTC · model grok-4.3
The pith
No current audio representation generalizes reliably across the clinical speech landscape.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
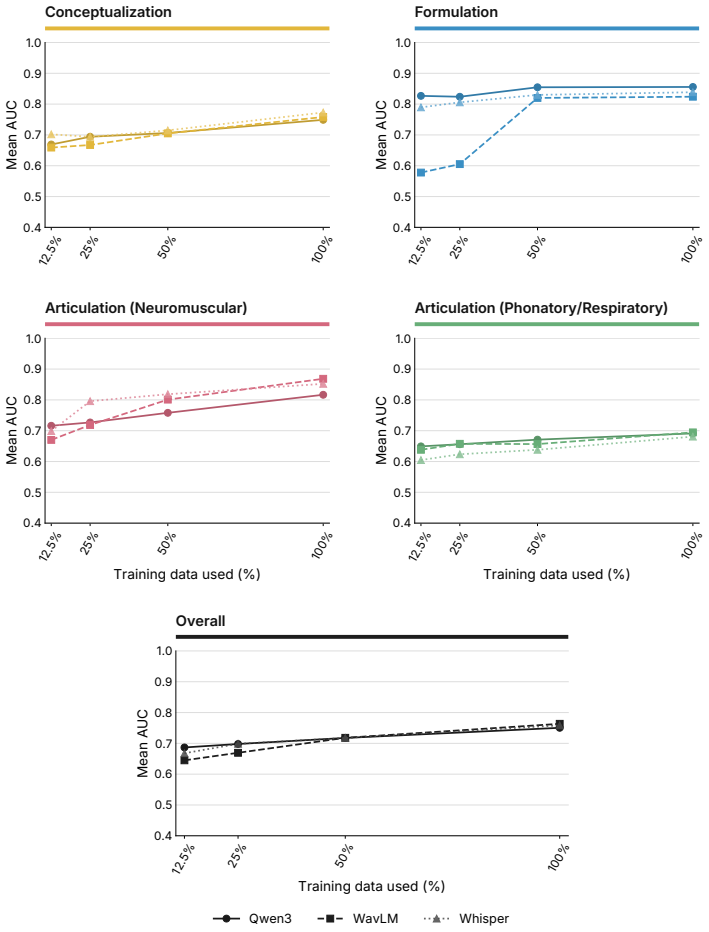
SpeechDx shows that large-scale speech models are the strongest baselines overall, domain-specific models improve performance only on closely matched tasks, and no current representation generalizes reliably across the clinical speech landscape when tested on tasks with limited labels and the same condition across multiple datasets.
What carries the argument
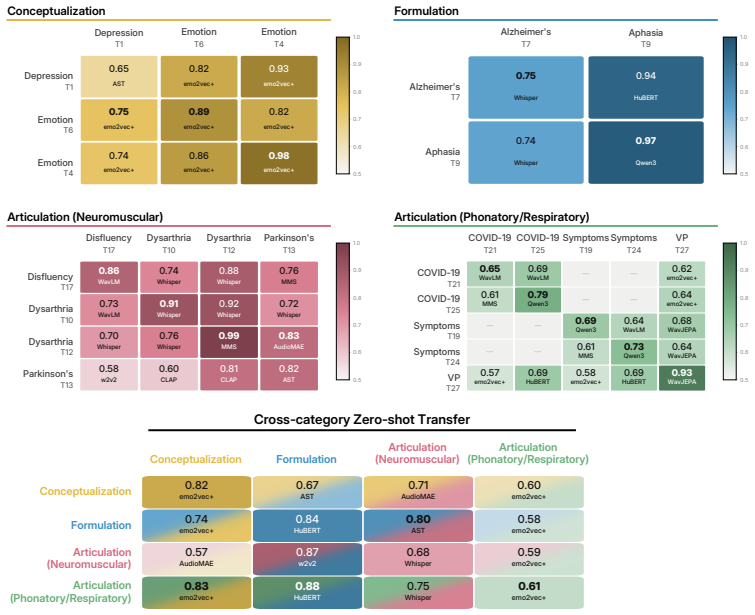
SpeechDx benchmark, which organizes 27 tasks across 12 datasets by the stage of speech production disrupted (conceptualization, formulation, articulation) to test shared clinical mechanisms.
If this is right
- Large-scale pretrained speech models should serve as the default starting point for new clinical speech applications.
- Domain-specific adaptation yields gains only when the target task closely matches the adaptation data.
- Cross-condition and cross-dataset transfer remains an open requirement for any general-purpose clinical speech system.
- Future models can be compared directly on the same 27-task suite to measure genuine generalization gains.
- The stage-based structure provides a way to diagnose which parts of the speech pipeline a representation fails to capture.
Where Pith is reading between the lines
- Models that succeed on this benchmark could support diagnostic tools usable across multiple neurological and motor conditions without retraining per disease.
- The benchmark could guide development of hybrid encoders that combine broad pretraining with targeted adaptation for underrepresented stages like conceptualization.
- If generalization improves, clinical speech AI could shift from single-condition tools to integrated systems that monitor overall speech health.
- Extending the benchmark with more languages or recording conditions would test whether the current generalization failures are language- or hardware-specific.
Load-bearing premise
Grouping tasks by the stage of speech production they disrupt lets evaluation measure shared clinical mechanisms rather than dataset-specific artefacts.
What would settle it
A single audio encoder achieving consistently high performance on all 27 tasks, including zero-shot cross-condition transfer and repeated conditions across different datasets, without performance dropping on any subset.
Figures

read the original abstract
Speech offers a uniquely informative window into health by simultaneously engaging neurological, motor, respiratory, and vocal systems. Current clinical speech AI methods have largely progressed through isolated condition-specific studies, making results difficult to compare and generalization difficult to assess. We introduce SpeechDx, a large-scale benchmark for clinical speech AI spanning 12 datasets and 27 tasks across diverse health conditions. To enable evaluation across shared clinical mechanisms, SpeechDx structures tasks by the stage of speech production they disrupt: conceptualization, formulation, and articulation. The benchmark tests generalization by including tasks with limited labeled data and evaluating the same health condition across multiple datasets, distinguishing clinically meaningful patterns from dataset artefacts. We systematically evaluate 12 state-of-the-art audio encoders across all tasks and under zero-shot cross-condition transfer. Results show that large-scale speech models represent the strongest overall baselines, domain-specific models improve performance only on closely matched tasks, and no current representation generalizes reliably across the clinical speech landscape. SpeechDx establishes a shared evaluation framework for tracking progress toward general-purpose clinical speech representations
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpeechDx, a benchmark spanning 12 datasets and 27 tasks across health conditions, structured by speech production stages (conceptualization, formulation, articulation) to evaluate generalization of audio encoders. It systematically tests 12 state-of-the-art encoders under in-domain and zero-shot cross-condition settings, concluding that large-scale models are strongest overall, domain-specific models help only on matched tasks, and no current representation generalizes reliably across the clinical speech landscape.
Significance. If the benchmark's task grouping and evaluation protocol hold, the work would provide a valuable shared framework for clinical speech AI, moving beyond isolated condition-specific studies and enabling tracking of progress toward general-purpose representations. The scale (12 datasets, 27 tasks) and systematic comparison of multiple encoders are strengths that could influence future model development.
major comments (2)
- [Abstract and §4] Abstract and §4: The abstract states evaluation results and conclusions but supplies no details on data splits, statistical tests, error bars, or exclusion criteria, so it is impossible to verify whether the data supports the generalization claims.
- [§2.3] §2.3: The stage-based task grouping (conceptualization, formulation, articulation) is presented without explicit mapping to clinical literature or ablation studies confirming that within-stage tasks exhibit more similar performance patterns than across-stage tasks; this grouping is load-bearing for the central claim that observed failures reflect representation limitations rather than dataset artefacts.
minor comments (2)
- [Table 1] Table 1: Dataset and task metadata would benefit from explicit column headers for recording conditions and label distributions to aid reproducibility.
- [Figure 2] Figure 2: Axis labels on the performance heatmaps are small and could be enlarged for readability in the published version.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight opportunities to improve transparency and grounding in the manuscript. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4: The abstract states evaluation results and conclusions but supplies no details on data splits, statistical tests, error bars, or exclusion criteria, so it is impossible to verify whether the data supports the generalization claims.
Authors: We agree that the abstract would benefit from greater transparency on the evaluation protocol. In the revised manuscript we will add a concise clause to the abstract noting the use of dataset-specific train/test splits, bootstrap-derived 95% confidence intervals, and audio-quality-based exclusion criteria. Section 4 already specifies the splits, the bootstrap procedure for error bars, and the exclusion rules; we will add an explicit summary paragraph at the start of §4 that cross-references these elements and reports the statistical tests (paired t-tests with Bonferroni correction) used for model comparisons. These changes will make the support for the generalization claims directly verifiable from the abstract and §4. revision: yes
-
Referee: [§2.3] §2.3: The stage-based task grouping (conceptualization, formulation, articulation) is presented without explicit mapping to clinical literature or ablation studies confirming that within-stage tasks exhibit more similar performance patterns than across-stage tasks; this grouping is load-bearing for the central claim that observed failures reflect representation limitations rather than dataset artefacts.
Authors: The grouping follows established clinical models of speech production (Levelt 1989; Duffy 2019 on motor speech disorders). We will revise §2.3 to include a table that explicitly maps each of the 27 tasks to one of the three stages together with primary clinical citations. We did not perform an intra- versus inter-stage performance correlation ablation; the paper’s cross-condition zero-shot experiments already separate representation limitations from dataset-specific artefacts. We will therefore add the literature mapping and table (revision_made = partial) but note that a full ablation would require substantial additional compute and is not required to support the main claims. revision: partial
Circularity Check
No circularity: empirical benchmark with no derivation chain
full rationale
The paper introduces SpeechDx as a multi-task benchmark spanning datasets and tasks, structures them by speech production stages as a methodological choice, and reports empirical evaluations of audio encoders. No equations, parameter fitting, predictions, or first-principles derivations are present; the central claim about generalization failures is an empirical observation from the benchmark results rather than a reduction to inputs or self-citations. The stage-based grouping is asserted for enabling cross-mechanism evaluation but is not derived from or equivalent to the results themselves.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Call, and Guy Fagherazzi
Vesna Despotovic, Mohamad Ismael, Marc Cornil, Romain M. Call, and Guy Fagherazzi. Detection of covid-19 from voice, cough and breathing patterns: Dataset and preliminary results.Computer Biology and Medicine, 138:104944, 2021
2021
-
[2]
Speech as a biomarker for covid-19 detection using machine learning
Mohammed Usman, Vinit Kumar Gunjan, Mohd Wajid, Mohammed Zubair, and Kazy Noor- e-alam Siddiquee. Speech as a biomarker for covid-19 detection using machine learning. Computational Intelligence and Neuroscience, 2022(1):6093613, 2022
2022
-
[3]
Shih, Chih-Hao Liao, Tzu-Wei Wu, Xiao-Yu Xu, and Ming-Hsiang Shih
David H. Shih, Chih-Hao Liao, Tzu-Wei Wu, Xiao-Yu Xu, and Ming-Hsiang Shih. Dysarthria speech detection using convolutional neural networks with gated recurrent unit.Healthcare, 10(10):1956, 2022
1956
-
[4]
Ríos-Urrego, Jan Rusz, Elmar Nöth, and Juan R
Carlos D. Ríos-Urrego, Jan Rusz, Elmar Nöth, and Juan R. Orozco-Arroyave. Automatic classification of hypokinetic and hyperkinetic dysarthria based on gmm-supervectors. In Proceedings of INTERSPEECH 2023. ISCA, 2023
2023
-
[6]
Exemplar-based sparse representations for detection of parkinson’s disease from speech.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:1386–1396, 2023
Mittapalle Kiran Reddy and Paavo Alku. Exemplar-based sparse representations for detection of parkinson’s disease from speech.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:1386–1396, 2023
2023
-
[7]
Improving parkinson’s disease recognition through voice analysis using deep learning.Pattern Recognition Letters, 168:64–70, 2023
Rania Khaskhoussy and Yosra Ben Ayed. Improving parkinson’s disease recognition through voice analysis using deep learning.Pattern Recognition Letters, 168:64–70, 2023
2023
-
[8]
Gomez-Garcia, Juan D
Laura Moro-Velazquez, Juan A. Gomez-Garcia, Juan D. Arias-Londoño, Najim Dehak, and Juan I. Godino-Llorente. Advances in parkinson’s disease detection and assessment using voice and speech: A review of the articulatory and phonatory aspects.Biomedical Signal Processing and Control, 66:102418, 2021
2021
-
[9]
Mahsa Zolnoori, Arash Zolnour, and Maxim Topaz. Adscreen: A speech processing-based screening system for automatic identification of patients with alzheimer’s disease and related dementia.Artificial Intelligence in Medicine, 143:102624, 2023
2023
-
[10]
Israel Martínez-Nicolás, Thide E Llorente, Francisco Martínez-Sánchez, and Juan José G Meilán. Ten years of research on automatic voice and speech analysis of people with alzheimer’s disease and mild cognitive impairment: a systematic review article.Frontiers in Psychology, 12:620251, 2021
2021
-
[11]
Classifying dementia in the presence of depression: A cross-corpus study
Felix Braun, Maria Schuster, Florian Honig, Elmar Noeth, and Juan Rafael Orozco-Arroyave. Classifying dementia in the presence of depression: A cross-corpus study. InProceedings of INTERSPEECH 2023. ISCA, 2023
2023
-
[12]
Automatic depression recognition by intelligent speech signal processing: A systematic survey.CAAI Transactions on Intelligence Technology, 8(3):701–711, 2023
Pingping Wu, Ruihao Wang, Han Lin, Fanlong Zhang, Juan Tu, and Miao Sun. Automatic depression recognition by intelligent speech signal processing: A systematic survey.CAAI Transactions on Intelligence Technology, 8(3):701–711, 2023
2023
-
[13]
Speech as a biomarker for depression.CNS & Neurological Disorders-Drug Targets-CNS & Neurological Disorders), 22(2):152–160, 2023
Sanne Koops, Sanne G Brederoo, Janna N De Boer, Femke G Nadema, Alban E V oppel, and Iris E Sommer. Speech as a biomarker for depression.CNS & Neurological Disorders-Drug Targets-CNS & Neurological Disorders), 22(2):152–160, 2023
2023
-
[14]
A review of depression and suicide risk assessment using speech analysis
Nicholas Cummins, Stefan Scherer, Jarek Krajewski, Sebastian Schnieder, Julien Epps, and Thomas F Quatieri. A review of depression and suicide risk assessment using speech analysis. Speech communication, 71:10–49, 2015
2015
-
[15]
Sung, and Philip C
Guo-Shiang Liu, Nikola Jovanovic, Chang K. Sung, and Philip C. Doyle. A scoping review of artificial intelligence detection of voice pathology: Challenges and opportunities. Otolaryngology–Head and Neck Surgery, 171(3):658–666, 2024. 10
2024
-
[16]
MVP: Multi-source V oice Pathology detection
Alkis Koudounas, Moreno La Quatra, Gabriele Ciravegna, Marco Fantini, Erika Crosetti, Giovanni Succo, Tania Cerquitelli, Sabato Marco Siniscalchi, and Elena Baralis. MVP: Multi-source V oice Pathology detection. InInterspeech 2025, pages 3548–3552, 2025
2025
-
[17]
The acm multimedia 2022 computational paralinguistics challenge: V ocalisations, stuttering, activity, & mosquitoes
Björn Schuller, Anton Batliner, Shahin Amiriparian, Christian Bergler, Maurice Gerczuk, Natalie Holz, Pauline Larrouy-Maestri, Sebastien Bayerl, Korbinian Riedhammer, Adria Mallol-Ragolta, Maria Pateraki, Harry Coppock, Ivan Kiskin, Marianne Sinka, and Stephen Roberts. The acm multimedia 2022 computational paralinguistics challenge: V ocalisations, stutte...
2022
-
[18]
Gale, Megan Fleegle, Gerasimos Fergadiotis, and Steven Bedrick
Richard C. Gale, Megan Fleegle, Gerasimos Fergadiotis, and Steven Bedrick. The post-stroke speech transcription (psst) challenge. InProceedings of the LREC 2022 RaPID-4 Workshop, pages 41–55, 2022
2022
-
[19]
Alzheimer’s Dementia Recognition Through Spontaneous Speech: The ADReSS Challenge
Saturnino Luz, Fasih Haider, Sofia de la Fuente, Davida Fromm, and Brian MacWhinney. Alzheimer’s Dementia Recognition Through Spontaneous Speech: The ADReSS Challenge. InInterspeech 2020, pages 2172–2176, 2020
2020
-
[20]
The 1st speechwellness challenge: Detecting suicide risk among adolescents
Wen Wu, Ziyun Cui, Chang Lei, Yinan Duan, Diyang Qu, Ji Wu, Bowen Zhou, Runsen Chen, and Chao Zhang. The 1st speechwellness challenge: Detecting suicide risk among adolescents. InInterspeech 2025, pages 399–403. ISCA, 2025
2025
-
[21]
Dicova challenge: Dataset, task, and baseline system for covid-19 diagnosis using acoustics, 2021
Ananya Muguli, Lancelot Pinto, Nirmala R., Neeraj Sharma, Prashant Krishnan, Prasanta Kumar Ghosh, Rohit Kumar, Shrirama Bhat, Srikanth Raj Chetupalli, Sriram Ganapathy, Shreyas Ramoji, and Viral Nanda. Dicova challenge: Dataset, task, and baseline system for covid-19 diagnosis using acoustics, 2021
2021
-
[22]
Multilingual alzheimer’s dementia recognition through spontaneous speech: a signal processing grand challenge, 2023
Saturnino Luz, Fasih Haider, Davida Fromm, Ioulietta Lazarou, Ioannis Kompatsiaris, and Brian MacWhinney. Multilingual alzheimer’s dementia recognition through spontaneous speech: a signal processing grand challenge, 2023
2023
-
[23]
Are reported accuracies in the clinical speech machine learning literature overoptimistic? In Proceedings of INTERSPEECH 2022, pages 2453–2457
Visar Berisha, Chelsea Krantsevich, Gabriela Stegmann, Shira Hahn, and Julie Liss. Are reported accuracies in the clinical speech machine learning literature overoptimistic? In Proceedings of INTERSPEECH 2022, pages 2453–2457. ISCA, 09 2022
2022
-
[24]
Guilherme Schu, Parvaneh Janbakhshi, and Ina Kodrasi. On using the ua-speech and torgo databases to validate automatic dysarthric speech classification approaches.ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, 2022
2023
-
[25]
Investigating biases in covid-19 diagnostic systems processed with automated speech anonymization algorithms
Yi Zhu, Mohamed Imoussaine, Carolyn Côté-Lussier, and Tiago Falk. Investigating biases in covid-19 diagnostic systems processed with automated speech anonymization algorithms. pages 46–54, 08 2023
2023
-
[26]
Responsible development of clinical speech ai: Bridging the gap between clinical research and technology.npj Digital Medicine, 7, 08 2024
Visar Berisha and Julie Liss. Responsible development of clinical speech ai: Bridging the gap between clinical research and technology.npj Digital Medicine, 7, 08 2024
2024
-
[27]
Rosen, and Ryan C
Katherine Verdolini, Clark A. Rosen, and Ryan C. Branski, editors.Classification Manual for Voice Disorders-I. Psychology Press, 1 edition, 2006
2006
-
[28]
V oice for health: the use of vocal biomarkers from research to clinical practice.Digital biomarkers, 5(1):78–88, 2021
Guy Fagherazzi, Aurélie Fischer, Muhannad Ismael, and Vladimir Despotovic. V oice for health: the use of vocal biomarkers from research to clinical practice.Digital biomarkers, 5(1):78–88, 2021
2021
-
[29]
Harrison, Liam D
Jessica Robin, John E. Harrison, Liam D. Kaufman, Frank Rudzicz, William Simpson, and Maria Yancheva. Evaluation of speech-based digital biomarkers: Review and recommendations. Digital Biomarkers, 4(3):99–108, 10 2020
2020
-
[30]
Speech as a biomarker: Opportunities, interpretability, and challenges.Perspectives of the ASHA Special Interest Groups, 7:276–283, 01 2022
Vikram Ramanarayanan, Adam Lammert, Hannah Rowe, Thomas Quatieri, and Jordan Green. Speech as a biomarker: Opportunities, interpretability, and challenges.Perspectives of the ASHA Special Interest Groups, 7:276–283, 01 2022. 11
2022
-
[31]
An end-to-end overview of clinical speech ai.IEEE Transactions on Audio, Speech and Language Processing, 34:1016–1048, 2026
Si-Ioi Ng, Lingfeng Xu, Ingo Siegert, Nicholas Cummins, Nina R Benway, Julie Liss, and Visar Berisha. An end-to-end overview of clinical speech ai.IEEE Transactions on Audio, Speech and Language Processing, 34:1016–1048, 2026
2026
-
[32]
Opensmile: the munich versatile and fast open-source audio feature extractor
Florian Eyben, Martin Wollmer, and Björn Schuller. Opensmile: the munich versatile and fast open-source audio feature extractor. InProceedings of the 18th ACM International Conference on Multimedia, MM ’10, page 1459–1462, New York, NY , USA, 2010. Association for Computing Machinery
2010
-
[33]
Covid-19 detection via fusion of modulation spectrum and linear prediction speech features
Yi Zhu, Abhishek Tiwari, João Monteiro, Shruti Kshirsagar, and Tiago Henrique Falk. Covid-19 detection via fusion of modulation spectrum and linear prediction speech features. IEEE/ACM transactions on audio, speech, and language processing, 31:1536–1549, 2023
2023
-
[34]
Parkinson’s disease and aging: Analysis of their effect in phonation and articulation of speech.Cognitive Computation, 9(6):731–748, 2017
Tomas Arias-Vergara, Juan Camilo Vasquez-Correa, and Juan Rafael Orozco-Arroyave. Parkinson’s disease and aging: Analysis of their effect in phonation and articulation of speech.Cognitive Computation, 9(6):731–748, 2017
2017
-
[35]
Effectiveness of voice quality features in detecting depression
Ahmed Afshan, Jian Guo, Seong Joon Park, Venkatesh Ravi, Jonathan Flint, and Abeer Alwan. Effectiveness of voice quality features in detecting depression. InProceedings of INTERSPEECH 2018, pages 1676–1680. ISCA, 2018
2018
-
[36]
Association of daily lung condition in copd patients with wearable speech and physiological data.Scientific reports., 15(1), 2025-12-29
Sejal Bhalla, Deshang Kong, Salaar Liaqat, Daniyal Liaqat, Robert Wu, Andrea Gershon, Eyal de Lara, and Alex Mariakakis. Association of daily lung condition in copd patients with wearable speech and physiological data.Scientific reports., 15(1), 2025-12-29
2025
-
[37]
Towards an automatic evaluation of the dysarthria level of patients with parkinson’s disease
Juan Camilo Vasquez-Correa, Juan Rafael Orozco-Arroyave, Tobias Bocklet, and Elmar Noeth. Towards an automatic evaluation of the dysarthria level of patients with parkinson’s disease. Journal of Communication Disorders, 76:21–36, 2018
2018
-
[38]
Intelligibility evaluation of pathological speech through multigranularity feature extraction and optimization
Chunying Fang, Haifeng Li, Lin Ma, and Mancai Zhang. Intelligibility evaluation of pathological speech through multigranularity feature extraction and optimization. Computational and Mathematical Methods in Medicine, 2017(1):2431573, 2017
2017
-
[39]
Schuller
Nicholas Cummins, Alice Baird, and Björn W. Schuller. Speech analysis for health: Current state-of-the-art and the increasing impact of deep learning.Methods, 151:41–54, 2018. Health Informatics and Translational Data Analytics
2018
-
[40]
Deep learning-based speech analysis for alzheimer’s disease detection: A literature review.Alzheimer’s Research & Therapy, 14(1):186, 2022
Qin Yang, Xin Li, Xinyun Ding, Feiyang Xu, and Zhenhua Ling. Deep learning-based speech analysis for alzheimer’s disease detection: A literature review.Alzheimer’s Research & Therapy, 14(1):186, 2022
2022
-
[41]
V oice pathology detection using convolutional neural networks with electroglottographic (egg) and speech signals
Rumana Islam, Esam Abdel-Raheem, and Mohammed Tarique. V oice pathology detection using convolutional neural networks with electroglottographic (egg) and speech signals. Computer Methods and Programs in Biomedicine Update, 2:100074, 2022
2022
-
[42]
End-to-end convolutional neural network enables covid-19 detection from breath and cough audio: a pilot study.BMJ Innovations, 7(2):356–362, 2021
Harry Coppock, Alex Gaskell, Panagiotis Tzirakis, Alice Baird, Lyn Jones, and Björn Schuller. End-to-end convolutional neural network enables covid-19 detection from breath and cough audio: a pilot study.BMJ Innovations, 7(2):356–362, 2021
2021
-
[43]
Automatic assessment of aphasic speech sensed by audio sensors for classification into aphasia severity levels to recommend speech therapies.Sensors, 22(18), 2022
Herath Mudiyanselage Dhammike Piyumal Madhurajith Herath, Weraniyagoda Arachchilage Sahanaka Anuththara Weraniyagoda, Rajapakshage Thilina Madhushan Rajapaksha, Patikiri Arachchige Don Shehan Nilmantha Wijesekara, Kalupahana Liyanage Kushan Sudheera, and Peter Han Joo Chong. Automatic assessment of aphasic speech sensed by audio sensors for classification...
2022
-
[44]
Automatic depression detection using smartphone-based text-dependent speech signals: Deep convolutional neural network approach.J Med Internet Res, 25:e34474, Jan 2023
Ah Young Kim, Eun Hye Jang, Seung-Hwan Lee, Kwang-Yeon Choi, Jeon Gue Park, and Hyun-Chool Shin. Automatic depression detection using smartphone-based text-dependent speech signals: Deep convolutional neural network approach.J Med Internet Res, 25:e34474, Jan 2023. 12
2023
-
[45]
Yi Zhu, Alex Mariakakis, Eyal De Lara, and Tiago H. Falk. How generalizable and interpretable are speech-based covid-19 detection systems?: A comparative analysis and new system proposal. In2022 IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI), pages 1–5, 2022
2022
-
[46]
Masked autoencoders are scalable vision learners, 2021
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners, 2021
2021
-
[47]
Dinov2: Learning robust visual features without supervision, 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick La...
2024
-
[48]
Self-supervised learning from images with a joint-embedding predictive architecture, 2023
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture, 2023
2023
-
[49]
Bert: Pre-training of deep bidirectional transformers for language understanding, 2019
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding, 2019
2019
-
[50]
Improving language understanding by generative pre-training
Alec Radford and Karthik Narasimhan. Improving language understanding by generative pre-training. 2018
2018
-
[51]
Llama: Open and efficient foundation language models, 2023
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models, 2023
2023
-
[52]
wav2vec 2.0: A framework for self-supervised learning of speech representations, 2020
Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations, 2020
2020
-
[53]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units, 2021
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. Hubert: Self-supervised speech representation learning by masked prediction of hidden units, 2021
2021
-
[54]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing.IEEE Journal of Selected Topics in Signal Processing, 16(6):1505–1518, October 2022
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Xiangzhan Yu, and Furu Wei. Wavlm: Large-scale self-supervised pre-training for full stack speech processing.IEEE Journal of Selected Topics in Signal Pr...
2022
-
[55]
Pre-trained models for detection and severity level classification of dysarthria from speech.Speech Communication, 158:103047, 2024
Farhad Javanmardi, Sudarsana Reddy Kadiri, and Paavo Alku. Pre-trained models for detection and severity level classification of dysarthria from speech.Speech Communication, 158:103047, 2024
2024
-
[56]
Gruia, Patrick A
Giulia Sanguedolce, Sophie Brook, Dragos C. Gruia, Patrick A. Naylor, and Fatemeh Geranmayeh. When Whisper Listens to Aphasia: Advancing Robust Post-Stroke Speech Recognition. InInterspeech 2024, pages 1995–1999, 2024
2024
-
[57]
Exploring self-supervised models for depressive disorder detection: A study on speech corpora
Bubai Maji, Shazia Nasreen, Rajlakshmi Guha, Aurobinda Routray, Debabrata Majumdar, and Km Poonam. Exploring self-supervised models for depressive disorder detection: A study on speech corpora. In2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), pages 1–4, 2024
2024
-
[58]
Emotion Recognition from Speech Using wav2vec 2.0 Embeddings
Leonardo Pepino, Pablo Riera, and Luciana Ferrer. Emotion Recognition from Speech Using wav2vec 2.0 Embeddings. InInterspeech 2021, pages 3400–3404, 2021
2021
-
[59]
Probing whisper for dysarthric speech in detection and assessment, 2025
Zhengjun Yue, Devendra Kayande, Zoran Cvetkovic, and Erfan Loweimi. Probing whisper for dysarthric speech in detection and assessment, 2025. 13
2025
-
[60]
Supervised and self-supervised pretraining based covid-19 detection using acoustic breathing/cough/speech signals
Xing-Yu Chen, Qiu-Shi Zhu, Jie Zhang, and Li-Rong Dai. Supervised and self-supervised pretraining based covid-19 detection using acoustic breathing/cough/speech signals. InICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), page 561–565. IEEE, May 2022
2022
-
[61]
Wavrx: A disease-agnostic, generalizable, and privacy-preserving speech health diagnostic model.IEEE Journal of Biomedical and Health Informatics, 29(9):6353–6365, 2025
Yi Zhu and Tiago Falk. Wavrx: A disease-agnostic, generalizable, and privacy-preserving speech health diagnostic model.IEEE Journal of Biomedical and Health Informatics, 29(9):6353–6365, 2025
2025
-
[62]
Corrado, Shwetak Patel, Shravya Shetty, Shruthi Prabhakara, Monde Muyoyeta, and Diego Ardila
Sebastien Baur, Zaid Nabulsi, Wei-Hung Weng, Jake Garrison, Louis Blankemeier, Sam Fishman, Christina Chen, Sujay Kakarmath, Minyoi Maimbolwa, Nsala Sanjase, Brian Shuma, Yossi Matias, Greg S. Corrado, Shwetak Patel, Shravya Shetty, Shruthi Prabhakara, Monde Muyoyeta, and Diego Ardila. Hear – health acoustic representations, 2024
2024
-
[63]
Lin, Andy T
Shu wen Yang, Po-Han Chi, Yung-Sung Chuang, Cheng-I Jeff Lai, Kushal Lakhotia, Yist Y . Lin, Andy T. Liu, Jiatong Shi, Xuankai Chang, Guan-Ting Lin, Tzu-Hsien Huang, Wei- Cheng Tseng, Ko tik Lee, Da-Rong Liu, Zili Huang, Shuyan Dong, Shang-Wen Li, Shinji Watanabe, Abdelrahman Mohamed, and Hung yi Lee. SUPERB: Speech Processing Universal PERformance Benchm...
2021
-
[64]
Schuller, Christian J
Joseph Turian, Jordie Shier, Humair Raj Khan, Bhiksha Raj, Björn W. Schuller, Christian J. Steinmetz, Colin Malloy, George Tzanetakis, Gissel Velarde, Kirk McNally, Max Henry, Nicolas Pinto, Camille Noufi, Christian Clough, Dorien Herremans, Eduardo Fonseca, Jesse Engel, Justin Salamon, Philippe Esling, Pranay Manocha, Shinji Watanabe, Zeyu Jin, and Yonat...
2022
-
[65]
The distress analysis interview corpus of human and computer interviews
Jonathan Gratch, Ron Artstein, Gale Lucas, Giota Stratou, Stefan Scherer, Angela Nazarian, Rachel Wood, Jill Boberg, David DeVault, Stacy Marsella, David Traum, Skip Rizzo, and Louis-Philippe Morency. The distress analysis interview corpus of human and computer interviews. In Nicoletta Calzolari, Khalid Choukri, Thierry Declerck, Hrafn Loftsson, Bente Mae...
2014
-
[66]
Livingstone and Frank A
Steven R. Livingstone and Frank A. Russo. The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english.PLOS ONE, 13(5):e0196391, 2018
2018
-
[67]
Iemocap: Interactive emotional dyadic motion capture database.Language Resources and Evaluation, 42:335–359, 12 2008
Carlos Busso, Murtaza Bulut, Chi-Chun Lee, Abe Kazemzadeh, Emily Mower Provost, Samuel Kim, Jeannette Chang, Sungbok Lee, and Shrikanth Narayanan. Iemocap: Interactive emotional dyadic motion capture database.Language Resources and Evaluation, 42:335–359, 12 2008
2008
-
[68]
Multilingual alzheimer’s dementia recognition through spontaneous speech: a signal processing grand challenge
Saturnino Luz, Fasih Haider, Davida Fromm, Ioulietta Lazarou, Ioannis Kompatsiaris, and Brian MacWhinney. Multilingual alzheimer’s dementia recognition through spontaneous speech: a signal processing grand challenge. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–2. IEEE, 2023
2023
-
[69]
Forbes, Davida Fromm, and Brian MacWhinney
Margaret M. Forbes, Davida Fromm, and Brian MacWhinney. Aphasiabank: A resource for clinicians.Aphasiology, 26(11):1281–1295, 2012
2012
-
[70]
The torgo database of acoustic and articulatory speech from speakers with dysarthria.Language Resources and Evaluation, 46:1–19, 01 2010
Frank Rudzicz, Aravind Namasivayam, and Talya Wolff. The torgo database of acoustic and articulatory speech from speakers with dysarthria.Language Resources and Evaluation, 46:1–19, 01 2010
2010
-
[71]
Huang, Kenneth Watkin, and Simone Frame
Heejin Kim, Mark Hasegawa-Johnson, Adrienne Perlman, Jon Gunderson, Thomas S. Huang, Kenneth Watkin, and Simone Frame. Dysarthric speech database for universal access research. InInterspeech 2008, pages 1741–1744, 2008
2008
-
[72]
Mobile device voice recordings at king’s college london (mdvr-kcl) from both early and advanced parkinson’s disease patients and healthy controls.Zenodo, 2019
Hagen Jaeger, Dhaval Trivedi, and Michael Stadtschnitzer. Mobile device voice recordings at king’s college london (mdvr-kcl) from both early and advanced parkinson’s disease patients and healthy controls.Zenodo, 2019. 14
2019
-
[73]
Ksof: The kassel state of fluency dataset – a therapy centered dataset of stuttering
Sebastian Peter Bayerl, Alexander Wolff von Gudenberg, Florian Hönig, Elmar Noeth, and Korbinian Riedhammer. Ksof: The kassel state of fluency dataset – a therapy centered dataset of stuttering. InProceedings of the Language Resources and Evaluation Conference, pages 1780–1787, Marseille, France, June 2022. European Language Resources Association
2022
-
[74]
Covid-19 sounds: A large-scale audio dataset for digital respiratory screening
Tong Xia, Dimitris Spathis, Chloe Brown, Jagmohan Chauhan, Andreas Grammenos, Jing Han, Apinan Hasthanasombat, Erika Bondareva, Ting Dang, Andres Floto, Pietro Cicuta, and Cecilia Mascolo. Covid-19 sounds: A large-scale audio dataset for digital respiratory screening. InProceedings of the 35th Conference on Neural Information Processing Systems Datasets a...
2021
-
[75]
Chandrakiran, Sahiti Nori, K
Debarpan Bhattacharya, Neeraj Kumar Sharma, Debottam Dutta, Srikanth Raj Chetupalli, Pravin Mote, Sriram Ganapathy, C. Chandrakiran, Sahiti Nori, K. K. Suhail, Sadhana Gonuguntla, and Murali Alagesan. Coswara: A respiratory sounds and symptoms dataset for remote screening of sars-cov-2 infection.Scientific Data, 10(1):397, 2023
2023
-
[76]
Jesus, Inês Belo, Jessica Machado, and Andreia Hall
Luis M.T. Jesus, Inês Belo, Jessica Machado, and Andreia Hall. The advanced voice function assessment databases (avfad): Tools for voice clinicians and speech research. InAdvances in Speech-language Pathology, chapter 14. IntechOpen, London, 2017
2017
-
[77]
Investigating self-supervised pretraining frameworks for pathological speech recognition, 2022
Lester Phillip Violeta, Wen-Chin Huang, and Tomoki Toda. Investigating self-supervised pretraining frameworks for pathological speech recognition, 2022
2022
-
[78]
V oice disorder classification using wav2vec 2.0 feature extraction.Journal of Voice, 2024
Jie Cai, Yuliang Song, Jianghao Wu, and Xiong Chen. V oice disorder classification using wav2vec 2.0 feature extraction.Journal of Voice, 2024
2024
-
[79]
Scaling speech technology to 1,000+ languages, 2023
Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, Alexei Baevski, Yossi Adi, Xiaohui Zhang, Wei-Ning Hsu, Alexis Conneau, and Michael Auli. Scaling speech technology to 1,000+ languages, 2023
2023
-
[80]
Hangrui Hu, Xinfa Zhu, Ting He, Dake Guo, Bin Zhang, Xiong Wang, Zhifang Guo, Ziyue Jiang, Hongkun Hao, Zishan Guo, Xinyu Zhang, Pei Zhang, Baosong Yang, Jin Xu, Jingren Zhou, and Junyang Lin. Qwen3-tts technical report.arXiv preprint arXiv:2601.15621, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[81]
Robust speech recognition via large-scale weak supervision, 2022
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.