FoundCause: Causal Discovery with Latent Confounders from Observational Data
Pith reviewed 2026-06-27 01:36 UTC · model grok-4.3
The pith
FoundCause is the first amortized model to explicitly recover causal graphs with latent confounders from observational data in one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FoundCause maps observational datasets to causal graphs in a single forward pass after training on synthetic structural causal models. Its architecture uses a permutation-invariant transformer with statistics-conditioned attention, a factorized decoder that separates edge presence from direction, a triangular refinement module, and a confounder module of learnable latent tokens that explicitly represents hidden common causes. The model also accepts masked inputs to handle missing data. On 15 real-world datasets it improves F1 by 9.6 percent, AUROC by 1.2 percent, and reduces structural Hamming distance by 18.9 percent relative to the strongest non-amortized baselines while running faster tha
What carries the argument
The confounder module based on learnable latent tokens that explicitly models hidden common causes, combined with the permutation-invariant transformer encoder and statistics-conditioned attention that injects classical asymmetry signals.
If this is right
- Causal discovery becomes feasible at scale because inference requires only one forward pass instead of iterative optimization per dataset.
- Explicit modeling of latent confounders improves graph recovery accuracy on data where hidden common causes are present.
- Training once on synthetic data allows the same model to be applied to many different real-world problems without retraining.
- The separation of edge existence and direction in the decoder plus motif-level refinement produces graphs with fewer orientation errors.
- Masked input handling makes the method directly applicable to incomplete observational records common in practice.
Where Pith is reading between the lines
- If the synthetic training distribution can be made even closer to real data distributions, performance gaps on new domains may shrink further.
- The single-pass design opens the possibility of embedding the model inside larger systems that require repeated causal queries, such as online decision-making agents.
- Extending the confounder module to also output estimates of confounder strength could support downstream tasks like effect-size calculation.
- Because the model already processes variable-wise distributions, it may be straightforward to adapt it for mixed continuous-discrete data without major architectural changes.
Load-bearing premise
The synthetic structural causal models used for training produce statistical patterns that are sufficiently representative of the real-world observational datasets on which the model is evaluated.
What would settle it
Evaluating FoundCause on a fresh collection of real-world datasets whose ground-truth graphs are known and that contain latent confounders; if its F1, AUROC, and structural Hamming distance are no better than the strongest classical baselines, the performance claim is falsified.
Figures

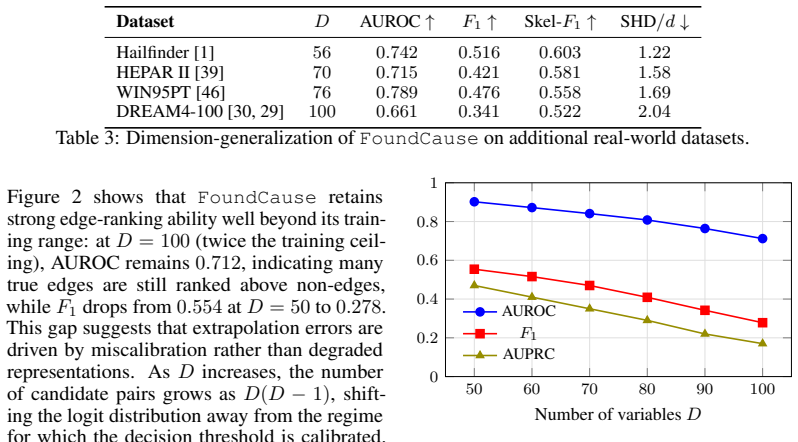

read the original abstract
Causal discovery from observational data remains challenging due to the need to recover directed structure and latent confounding without interventions. We propose FoundCause, an amortized causal discovery model trained entirely on synthetic data that maps datasets directly to causal graphs in a single forward pass. By learning from large collections of simulated structural causal models, FoundCause captures transferable statistical patterns that generalize beyond individual datasets. The architecture incorporates several key inductive biases for causal discovery. It uses a permutation-invariant transformer encoder with alternating attention over samples and variables to jointly model cross-variable dependence and per-variable distributions. Pairwise statistical features derived from classical asymmetry measures are injected through statistics-conditioned attention, guiding the model toward known causal signals. A factorized decoder separates edge existence from direction, while a triangular refinement module enables reasoning over higher-order causal motifs such as chains and colliders. In addition, a dedicated confounder module based on learnable latent tokens explicitly models hidden common causes, and the model explicitly handles missing data via its masked input representation. To our knowledge, FoundCause is the first amortized causal discovery approach to explicitly model latent confounding. FoundCause outperforms 11 classical non-amortized methods (e.g., PC, GES, NOTEARS-style optimization) and 4 amortized causal discovery methods on 15 real-world datasets, achieving +9.6% improvement in $F_1$, +1.2% in AUROC, and an 18.9% reduction in structural Hamming distance relative to the strongest non-amortized methods, while performing inference in a single forward pass.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FoundCause, an amortized causal discovery model trained exclusively on synthetic structural causal models. It employs a permutation-invariant transformer encoder with alternating attention, statistics-conditioned attention using classical asymmetry measures, a factorized decoder, a triangular refinement module, and a dedicated confounder module with learnable latent tokens to explicitly handle latent confounding and missing data. The central claim is that FoundCause is the first amortized method to model latent confounders and outperforms 11 classical non-amortized methods (PC, GES, NOTEARS-style) and 4 amortized baselines on 15 real-world datasets, with reported gains of +9.6% F1, +1.2% AUROC, and 18.9% reduction in SHD, while enabling single-forward-pass inference.
Significance. If the generalization from synthetic training data holds and the performance gains are reproducible, the work would be significant for enabling scalable, fast causal discovery that explicitly accounts for latent confounding—an area where most amortized methods have been limited. The explicit modeling of confounders via latent tokens and the handling of missing data represent concrete architectural contributions that could transfer to other graph-learning tasks.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): The central performance claim of outperforming baselines on 15 real-world datasets with specific metric improvements (+9.6% F1, etc.) is presented without any description of experimental protocol, baseline implementations, statistical testing, data preprocessing, or how ground-truth graphs are obtained for real datasets. This absence makes it impossible to assess whether the reported gains are load-bearing or artifacts of implementation choices.
- [§3, §4] §3 (Method) and §4: The load-bearing assumption that synthetic SCM training data produce statistical patterns representative of the 15 real-world evaluation datasets is stated but unsupported by any quantitative validation (e.g., moment matching, distribution divergence metrics, or ablation on confounding strength). Without such checks, the generalization claim that underpins all real-data results cannot be evaluated.
- [§3.3] §3.3 (Confounder module): The claim that the learnable latent tokens 'explicitly model hidden common causes' is central to the novelty assertion, yet the manuscript provides no derivation or ablation showing that these tokens recover identifiable confounding structure rather than acting as generic capacity boosters.
minor comments (2)
- [§3.2] Notation for the triangular refinement module and factorized decoder should be clarified with explicit equations showing how higher-order motifs are enforced.
- [Abstract] The abstract states 'to our knowledge' regarding being the first amortized method with explicit latent confounding; a brief related-work table comparing against the four cited amortized baselines on this dimension would strengthen the claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, agreeing where additional material is needed and outlining the planned revisions.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): The central performance claim of outperforming baselines on 15 real-world datasets with specific metric improvements (+9.6% F1, etc.) is presented without any description of experimental protocol, baseline implementations, statistical testing, data preprocessing, or how ground-truth graphs are obtained for real datasets. This absence makes it impossible to assess whether the reported gains are load-bearing or artifacts of implementation choices.
Authors: We agree that the current manuscript lacks sufficient detail on the experimental protocol, which is necessary for proper evaluation and reproducibility. In the revised version, we will expand §4 with a complete description of the experimental setup. This will include: (i) exact baseline implementations and any adaptations made to the original code or papers, (ii) the statistical testing procedures (number of runs, significance tests if applied), (iii) all data preprocessing steps, and (iv) the sources and construction of ground-truth graphs for each of the 15 real-world datasets. revision: yes
-
Referee: [§3, §4] §3 (Method) and §4: The load-bearing assumption that synthetic SCM training data produce statistical patterns representative of the 15 real-world evaluation datasets is stated but unsupported by any quantitative validation (e.g., moment matching, distribution divergence metrics, or ablation on confounding strength). Without such checks, the generalization claim that underpins all real-data results cannot be evaluated.
Authors: We acknowledge that the manuscript would benefit from explicit quantitative checks supporting the synthetic-to-real generalization. While training exclusively on diverse synthetic SCMs is standard practice in amortized causal discovery, we will add in the revision: (i) moment-matching and distribution-divergence comparisons between the synthetic training distribution and the real-world evaluation datasets, and (ii) an ablation varying confounding strength in the synthetic data to demonstrate robustness of the learned patterns. revision: yes
-
Referee: [§3.3] §3.3 (Confounder module): The claim that the learnable latent tokens 'explicitly model hidden common causes' is central to the novelty assertion, yet the manuscript provides no derivation or ablation showing that these tokens recover identifiable confounding structure rather than acting as generic capacity boosters.
Authors: The confounder module was introduced to explicitly represent latent variables via dedicated tokens rather than relying solely on implicit capacity. We agree that an empirical demonstration is required. In the revision we will add a controlled ablation on synthetic data with known latent confounding: performance with the full confounder module versus a version where the tokens are removed or replaced by generic capacity. We will also include a short discussion clarifying the intended role of the tokens in capturing common causes. revision: yes
Circularity Check
No significant circularity; claims rest on external real-world evaluation.
full rationale
The paper trains FoundCause exclusively on collections of simulated SCMs and reports performance on 15 separate real-world datasets using F1, AUROC, and SHD metrics that require ground-truth graphs external to the training distribution. No equations, self-citations, or architectural steps reduce the reported gains to the synthetic training inputs by construction. The generalization assumption is stated explicitly and is falsifiable via the held-out real datasets; the derivation chain (transformer encoder, confounder module, factorized decoder) is self-contained against those external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic structural causal models used for training produce statistical patterns representative of real-world observational data
invented entities (1)
-
learnable latent tokens for confounders
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Hail- finder: A bayesian system for forecasting severe weather.International Journal of Forecasting, 12(1):57–71, 1996
Bruce Abramson, John Brown, Ward Edwards, Allan Murphy, and Robert L Winkler. Hail- finder: A bayesian system for forecasting severe weather.International Journal of Forecasting, 12(1):57–71, 1996
1996
-
[2]
Causal reasoning in the presence of latent confounders via neural ADMG learning
Matthew Ashman, Chao Ma, Agrin Hilmkil, Joel Jennings, and Cheng Zhang. Causal reasoning in the presence of latent confounders via neural ADMG learning. InInternational Conference on Learning Representations, 2023
2023
-
[3]
Cresswell, and Rahul Krishnan
Vahid Balazadeh, Hamidreza Kamkari, Valentin Thomas, Junwei Ma, Bingru Li, Jesse C. Cresswell, and Rahul Krishnan. CausalPFN: Amortized causal effect estimation via in-context learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[4]
DAGMA: Learning dags via m-matrices and a log-determinant acyclicity characterization.Advances in Neural Information Processing Systems, 35:8226–8239, 2022
Kevin Bello, Bryon Aragam, and Pradeep Ravikumar. DAGMA: Learning dags via m-matrices and a log-determinant acyclicity characterization.Advances in Neural Information Processing Systems, 35:8226–8239, 2022
2022
-
[5]
Differentiable causal discovery under unmeasured confounding
Rohit Bhattacharya, Tushar Nagarajan, Daniel Malinsky, and Ilya Shpitser. Differentiable causal discovery under unmeasured confounding. InProceedings of the 24th International Conference on Artificial Intelligence and Statistics, volume 130 ofProceedings of Machine Learning Research, pages 2314–2322. PMLR, 2021
2021
-
[6]
Dowhy-gcm: An extension of dowhy for causal inference in graphical causal models.Journal of Machine Learning Research, 25(147):1–7, 2024
Patrick Blöbaum, Peter Götz, Kailash Budhathoki, Atalanti A Mastakouri, and Dominik Janzing. Dowhy-gcm: An extension of dowhy for causal inference in graphical causal models.Journal of Machine Learning Research, 25(147):1–7, 2024
2024
-
[7]
Differentiable causal discovery from interventional data
Philippe Brouillard, Sébastien Lachapelle, Alexandre Lacoste, Simon Lacoste-Julien, and Alexandre Drouin. Differentiable causal discovery from interventional data. InAdvances in Neural Information Processing Systems, volume 33, 2020
2020
-
[8]
Cam: Causal additive models, high-dimensional order search and penalized regression.The Annals of Statistics, 42, 10 2013
Peter Bühlmann, Jonas Peters, and Jan Ernest. Cam: Causal additive models, high-dimensional order search and penalized regression.The Annals of Statistics, 42, 10 2013
2013
-
[9]
Modeling causal mechanisms with diffusion models for interventional and counterfactual queries.Trans
Patrick Chao, Patrick Blöbaum, Sapan Patel, and Shiva Prasad Kasiviswanathan. Modeling causal mechanisms with diffusion models for interventional and counterfactual queries.Trans. Mach. Learn. Res., 2024, 2023
2024
-
[10]
Optimal structure identification with greedy search.Journal of machine learning research, 3(Nov):507–554, 2002
David Maxwell Chickering. Optimal structure identification with greedy search.Journal of machine learning research, 3(Nov):507–554, 2002
2002
-
[11]
Maathuis
Diego Colombo and Marloes H. Maathuis. Order-independent constraint-based causal structure learning.Journal of Machine Learning Research, 15(116):3921–3962, 2014
2014
-
[12]
The road less scheduled.Advances in Neural Information Processing Systems, 37:9974–10007, 2024
Aaron Defazio, Xingyu Yang, Harsh Mehta, Konstantin Mishchenko, Ahmed Khaled, and Ashok Cutkosky. The road less scheduled.Advances in Neural Information Processing Systems, 37:9974–10007, 2024
2024
-
[13]
Causal chambers as a real-world physical testbed for ai methodology.Nature Machine Intelligence, 7(1):107–118, 2025
Juan L Gamella, Jonas Peters, and Peter Bühlmann. Causal chambers as a real-world physical testbed for ai methodology.Nature Machine Intelligence, 7(1):107–118, 2025
2025
-
[14]
Deep end-to-end causal inference.Transac- tions on Machine Learning Research, 2024
Tomas Geffner, Javier Antoran, Adam Foster, Wenbo Gong, Chao Ma, Emre Kiciman, Amit Sharma, Angus Lamb, Martin Kukla, Nick Pawlowski, Agrin Hilmkil, Joel Jennings, Meyer Scetbon, Miltiadis Allamanis, and Cheng Zhang. Deep end-to-end causal inference.Transac- tions on Machine Learning Research, 2024
2024
-
[15]
Review of causal discovery methods based on graphical models.Frontiers in Genetics, 10:524, 2019
Clark Glymour, Kun Zhang, and Peter Spirtes. Review of causal discovery methods based on graphical models.Frontiers in Genetics, 10:524, 2019
2019
-
[16]
The petshop dataset—finding causes of performance issues across microservices
Michaela Hardt, William Roy Orchard, Patrick Blöbaum, Elke Kirschbaum, and Shiva Ka- siviswanathan. The petshop dataset—finding causes of performance issues across microservices. InCausal Learning and Reasoning, pages 957–978. PMLR, 2024. 10
2024
-
[17]
Gaussian error linear units (gelus).arXiv preprint arXiv:1606.08415, 2016
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus).arXiv preprint arXiv:1606.08415, 2016
Pith/arXiv arXiv 2016
-
[18]
Hoyer, D
P. Hoyer, D. Janzing, J. Mooij, J. Peters, and B Schölkopf. Nonlinear causal discovery with additive noise models. In D. Koller, D. Schuurmans, Y . Bengio, and L. Bottou, editors, Proceedings of the conference Neural Information Processing Systems (NIPS) 2008, Vancouver, Canada, 2009. MIT Press
2008
-
[19]
Highly accurate protein structure prediction with alphafold.Nature, 596(7873):583–589, 2021
John Jumper, Richard Evans, Alexander Pritzel, et al. Highly accurate protein structure prediction with alphafold.Nature, 596(7873):583–589, 2021
2021
-
[20]
Mozer, and Danilo Jimenez Rezende
Nan Rosemary Ke, Silvia Chiappa, Jane Wang, Anirudh Goyal, Jorg Bornschein, Melanie Rey, Theophane Weber, Matthew Botvinick, Michael C. Mozer, and Danilo Jimenez Rezende. Learning to induce causal structure. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[21]
Gradient- based neural DAG learning
Sébastien Lachapelle, Philippe Brouillard, Tristan Deleu, and Simon Lacoste-Julien. Gradient- based neural DAG learning. InInternational Conference on Learning Representations, 2020
2020
-
[22]
Greedy relaxations of the sparsest permu- tation algorithm
Wai-Yin Lam, Bryan Andrews, and Joseph Ramsey. Greedy relaxations of the sparsest permu- tation algorithm. InUncertainty in Artificial Intelligence, pages 1052–1062. PMLR, 2022
2022
-
[23]
Set transformer: A framework for attention-based permutation-invariant input
Juho Lee, Yoonho Lee, Jungtaek Kim, Adam Kosiorek, Seungjin Choi, and Yee Whye Teh. Set transformer: A framework for attention-based permutation-invariant input. InInternational Conference on Machine Learning (ICML), 2019
2019
-
[24]
Efficient neural causal discovery without acyclicity constraints
Phillip Lippe, Taco Cohen, and Efstratios Gavves. Efficient neural causal discovery without acyclicity constraints. InInternational Conference on Learning Representations, 2022
2022
-
[25]
DiBS: Differentiable bayesian structure learning
Lars Lorch, Jonas Rothfuss, Bernhard Schölkopf, and Andreas Krause. DiBS: Differentiable bayesian structure learning. InAdvances in Neural Information Processing Systems, volume 34, 2021
2021
-
[26]
Amortized inference for causal structure learning
Lars Lorch, Scott Sussex, Jonas Rothfuss, Andreas Krause, and Bernhard Schölkopf. Amortized inference for causal structure learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[27]
Scalable differentiable causal discovery in the presence of latent confounders with skeleton posterior
Pingchuan Ma, Rui Ding, Qiang Fu, Jiaru Zhang, Shuai Wang, Shi Han, and Dongmei Zhang. Scalable differentiable causal discovery in the presence of latent confounders with skeleton posterior. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 2141–2152. Association for Computing Machinery, 2024
2024
-
[28]
Amortized inference of causal models via conditional fixed-point iterations.Transactions on Machine Learning Research, 2025
Divyat Mahajan, Jannes Gladrow, Agrin Hilmkil, Cheng Zhang, and Meyer Scetbon. Amortized inference of causal models via conditional fixed-point iterations.Transactions on Machine Learning Research, 2025. J2C Certification
2025
-
[29]
Prill, Thomas Schaffter, Claudio Mattiussi, Dario Floreano, and Gus- tavo Stolovitzky
Daniel Marbach, Robert J. Prill, Thomas Schaffter, Claudio Mattiussi, Dario Floreano, and Gus- tavo Stolovitzky. Revealing strengths and weaknesses of methods for gene network inference. Proceedings of the National Academy of Sciences, 107(14):6286–6291, 2010
2010
-
[30]
Generating realistic in silico gene networks for performance assessment of reverse engineering methods.Journal of Computational Biology, 16(2):229–239, 2009
Daniel Marbach, Thomas Schaffter, Claudio Mattiussi, and Dario Floreano. Generating realistic in silico gene networks for performance assessment of reverse engineering methods.Journal of Computational Biology, 16(2):229–239, 2009
2009
-
[31]
Identifiability of cause and effect using regularized regression
Alexander Marx and Jilles Vreeken. Identifiability of cause and effect using regularized regression. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 852–861, 2019
2019
-
[32]
De- mystifying amortized causal discovery with transformers.Transactions on Machine Learning Research, 2025
Francesco Montagna, Max Cairney-Leeming, Dhanya Sridhar, and Francesco Locatello. De- mystifying amortized causal discovery with transformers.Transactions on Machine Learning Research, 2025. 11
2025
-
[33]
Mooij, Jonas Peters, Dominik Janzing, Jakob Zscheischler, and Bernhard Schölkopf
Joris M. Mooij, Jonas Peters, Dominik Janzing, Jakob Zscheischler, and Bernhard Schölkopf. Distinguishing cause from effect using observational data: methods and benchmarks.Journal of Machine Learning Research, 17(32):1–102, 2016
2016
-
[34]
Counterfactual identifiability of bijective causal models
Arash Nasr-Esfahany, Mohammad Alizadeh, and Devavrat Shah. Counterfactual identifiability of bijective causal models. InForty-second International Conference on Machine Learning, 2023
2023
-
[35]
Extremely greedy equivalence search
Achille Nazaret and David Blei. Extremely greedy equivalence search. InThe 40th Conference on Uncertainty in Artificial Intelligence, 2024
2024
-
[36]
On the role of sparsity and dag constraints for learning linear dags.Advances in Neural Information Processing Systems (NeurIPS), 33:17943–17954, 2020
Ignavier Ng, AmirEmad Ghassami, and Kun Zhang. On the role of sparsity and dag constraints for learning linear dags.Advances in Neural Information Processing Systems (NeurIPS), 33:17943–17954, 2020
2020
-
[37]
Zero-shot causal learning.Advances in Neural Information Processing Systems, 36:6862–6901, 2023
Hamed Nilforoshan, Michael Moor, Yusuf Roohani, Yining Chen, Anja Šurina, Michihiro Yasunaga, Sara Oblak, and Jure Leskovec. Zero-shot causal learning.Advances in Neural Information Processing Systems, 36:6862–6901, 2023
2023
-
[38]
A hybrid causal search algorithm for latent variable models
Juan Miguel Ogarrio, Peter Spirtes, and Joe Ramsey. A hybrid causal search algorithm for latent variable models. InProceedings of the Eighth International Conference on Probabilistic Graphical Models, volume 52 ofProceedings of Machine Learning Research, pages 368–379. PMLR, 2016
2016
-
[39]
Probabilistic causal models in medicine: Application to diagnosis of liver disorders
Agnieszka Onisko. Probabilistic causal models in medicine: Application to diagnosis of liver disorders. InPh. D. dissertation, Inst. Biocybern. Biomed. Eng., Polish Academy Sci., Warsaw, Poland, 2003
2003
-
[40]
Peters and P
J. Peters and P. Bühlmann. Identifiability of gaussian structural equation models with equal error variances.Biometrika, 101(1):219–228, 03 2014
2014
-
[41]
A scale-invariant sorting criterion to find a causal order in additive noise models.Advances in Neural Information Processing Systems, 36:785–807, 2023
Alexander Reisach, Myriam Tami, Christof Seiler, Antoine Chambaz, and Sebastian Weichwald. A scale-invariant sorting criterion to find a causal order in additive noise models.Advances in Neural Information Processing Systems, 36:785–807, 2023
2023
-
[42]
Arik Reuter, Anish Dhir, Cristiana Diaconu, Jake Robertson, Ole Ossen, Frank Hutter, Adrian Weller, Mark van der Wilk, and Bernhard Schölkopf. Use what you know: Causal foundation models with partial graphs.arXiv preprint arXiv:2602.14972, 2026
Pith/arXiv arXiv 2026
-
[43]
Do-pfn: In-context learning for causal effect estimation.arXiv preprint arXiv:2506.06039, 2025
Jake Robertson, Arik Reuter, Siyuan Guo, Noah Hollmann, Frank Hutter, and Bernhard Schölkopf. Do-pfn: In-context learning for causal effect estimation.arXiv preprint arXiv:2506.06039, 2025
arXiv 2025
-
[44]
Score matching enables causal discovery of nonlinear additive noise models
Paul Rolland, V olkan Cevher, Matthäus Kleindessner, Chris Russell, Dominik Janzing, Bernhard Schölkopf, and Francesco Locatello. Score matching enables causal discovery of nonlinear additive noise models. InInternational Conference on Machine Learning, pages 18741–18753. PMLR, 2022
2022
-
[45]
Causal protein-signaling networks derived from multiparameter single-cell data.Science, 308(5721):523–529, 2005
Karen Sachs, Omar Perez, Dana Pe’er, Douglas A Lauffenburger, and Garry P Nolan. Causal protein-signaling networks derived from multiparameter single-cell data.Science, 308(5721):523–529, 2005
2005
-
[46]
Bayesian network repository: Large discrete bayesian networks
Marco Scutari. Bayesian network repository: Large discrete bayesian networks. https: //www.bnlearn.com/bnrepository/discrete-large.html, 2022. Accessed: 2026-05-03
2022
-
[47]
Dowhy: An end-to-end library for causal inference.arXiv preprint arXiv:2011.04216, 2020
Amit Sharma and Emre Kiciman. Dowhy: An end-to-end library for causal inference.arXiv preprint arXiv:2011.04216, 2020
arXiv 2011
-
[48]
GLU variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
Noam Shazeer. GLU variants improve transformer.arXiv preprint arXiv:2002.05202, 2020. 12
Pith/arXiv arXiv 2002
-
[49]
A linear non-gaussian acyclic model for causal discovery.Journal of Machine Learning Research, 7(10), 2006
Shohei Shimizu, Patrik O Hoyer, Aapo Hyvärinen, Antti Kerminen, and Michael Jordan. A linear non-gaussian acyclic model for causal discovery.Journal of Machine Learning Research, 7(10), 2006
2006
-
[50]
Directlingam: A direct method for learning a linear non-gaussian structural equation model.Journal of Machine Learning Research-JMLR, 12(Apr):1225–1248, 2011
Shohei Shimizu, Takanori Inazumi, Yasuhiro Sogawa, Aapo Hyvarinen, Yoshinobu Kawahara, Takashi Washio, Patrik O Hoyer, Kenneth Bollen, and Patrik Hoyer. Directlingam: A direct method for learning a linear non-gaussian structural equation model.Journal of Machine Learning Research-JMLR, 12(Apr):1225–1248, 2011
2011
-
[51]
MIT Press, 2nd edition, 2000
Peter Spirtes, Clark Glymour, and Richard Scheines.Causation, Prediction, and Search. MIT Press, 2nd edition, 2000
2000
-
[52]
Gideon Stein, Maha Shadaydeh, and Joachim Denzler. Embracing the black box: Head- ing towards foundation models for causal discovery from time series data.arXiv preprint arXiv:2402.09305, 2024
arXiv 2024
-
[53]
Geometry of the faithfulness assumption in causal inference.The Annals of Statistics, 41(2):437–463, 2013
Caroline Uhler, Garvesh Raskutti, Peter Bühlmann, and Bin Yu. Geometry of the faithfulness assumption in causal inference.The Annals of Statistics, 41(2):437–463, 2013
2013
-
[54]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[55]
Sample, estimate, aggregate: A recipe for causal discovery foundation models.Transactions on Machine Learning Research, 2025
Menghua Wu, Yujia Bao, Regina Barzilay, and Tommi Jaakkola. Sample, estimate, aggregate: A recipe for causal discovery foundation models.Transactions on Machine Learning Research, 2025
2025
-
[56]
Inferring cause and effect in the presence of heteroscedastic noise
Sascha Xu, Osman A Mian, Alexander Marx, and Jilles Vreeken. Inferring cause and effect in the presence of heteroscedastic noise. InInternational Conference on Machine Learning, pages 24615–24630. PMLR, 2022
2022
-
[57]
DAG-GNN: DAG structure learning with graph neural networks
Yue Yu, Jie Chen, Tian Gao, and Mo Yu. DAG-GNN: DAG structure learning with graph neural networks. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 7154–7163. PMLR, 2019
2019
-
[58]
Root mean square layer normalization
Biao Zhang and Rico Sennrich. Root mean square layer normalization. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[59]
On the completeness of orientation rules for causal discovery in the presence of latent confounders and selection bias.Artificial Intelligence, 172(16-17):1873–1896, 2008
Jiji Zhang. On the completeness of orientation rules for causal discovery in the presence of latent confounders and selection bias.Artificial Intelligence, 172(16-17):1873–1896, 2008
2008
-
[60]
Zhang and A
K. Zhang and A. Hyvärinen. On the identifiability of the post-nonlinear causal model. In Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence, Montreal, Canada, 2009
2009
-
[61]
correlation fog
Xun Zheng, Bryon Aragam, Pradeep Ravikumar, and Eric P. Xing. Dags with no tears: Continuous optimization for structure learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2018. 13 A Comparison between Amortized Causal Discovery Methods Method LatentconfoundersMissingdata Variable-countagnostic NonlinearmechanismsV-structure /structur...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.