Bounding Box Label Propagation for Re-Annotation of Document Layout Analysis Datasets
Pith reviewed 2026-06-27 01:53 UTC · model grok-4.3
The pith
Bounding Box Label Propagation re-annotates document layout datasets by propagating class labels from 10% labelled data to reach 81.6% of fully supervised mAP.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
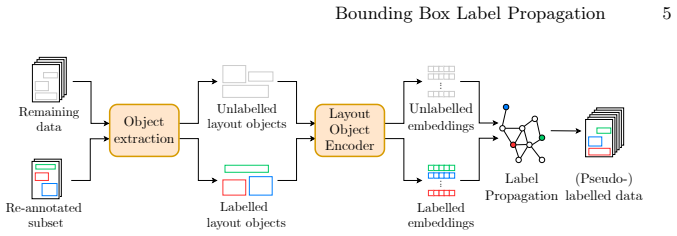
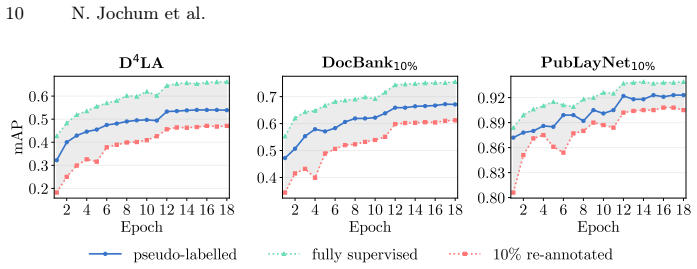
Bounding Box Label Propagation (BBLP) is a pseudo-labelling framework for object detection that encodes each bounding box with combined visual, textual, and positional embeddings to form a joint space; label propagation is then run directly in that space on partially annotated document-layout datasets, producing class labels whose quality reaches an mAP of 54.0% on D4LA (81.6% of the fully supervised figure) when only 10% of the boxes are initially labelled.
What carries the argument
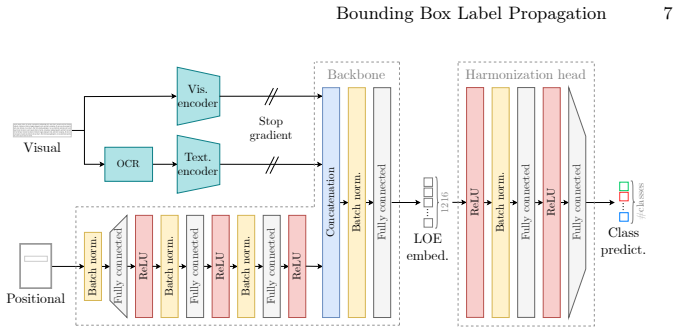
An object encoder that fuses visual, textual, and positional embeddings of each bounding box into a single vector for use in label propagation.
If this is right
- High-quality class labels can be produced for the great majority of bounding boxes without manual review.
- Re-annotation effort for evolving document-layout datasets drops sharply when only a small labelled seed is maintained.
- The same encoder-plus-propagation pipeline can be attached to any object detector without changing its training procedure.
- Performance at 10% labelled data already recovers more than four-fifths of the accuracy obtained with complete supervision.
Where Pith is reading between the lines
- The same embedding construction could be tried on non-document object-detection tasks where datasets also grow incrementally.
- Replacing the standard propagation step with more recent semi-supervised variants might raise the recovered fraction above 81.6%.
- Measuring how performance changes when the labelled fraction drops below 10% would show the practical lower limit of the method.
Load-bearing premise
The combined visual-textual-positional embedding space is sufficiently well-structured that ordinary label propagation assigns the correct class to each unlabelled bounding box.
What would settle it
On the D4LA dataset with exactly 10% of boxes labelled, measure the mAP obtained after running the full BBLP pipeline; if the result falls substantially below 54.0% or well under 81.6% of the fully supervised mAP, the claim does not hold.
Figures
read the original abstract
Datasets in practical document processing scenarios typically grow over time, and their class annotations undergo continuous refinement. This creates significant re-annotation efforts, which are time-consuming and costly. A promising remedy is to re-annotate only a small subset of available documents manually and apply semi-supervised learning techniques that leverage both labelled and unlabelled data. Although there are numerous approaches to tackle this problem for classification, there exists no adaptation for the problem of re-classifying object detection instances, e.g. for document layout analysis. To this end, we propose Bounding Box Label Propagation (BBLP), a pseudo-labelling framework for object detection. An object encoder integrates visual, textual, and positional embeddings from object detection samples to come up with a joint embedding that can be used for Label Propagation on partially annotated datasets in a plug-and-play fashion. Evaluation results indicate that the proposed approach produces high-quality class annotations of bounding boxes. In the D4LA layout analysis dataset, it achieves a mAP of 54.0%, corresponding to 81.6% of fully supervised performance, while using only 10% labelled data. Our work demonstrates the potential of Label Propagation for object detection and lays the groundwork for reducing manual annotation efforts in real-world document processing applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Bounding Box Label Propagation (BBLP), a pseudo-labelling framework for re-annotating object detection instances in document layout analysis datasets. An object encoder combines visual, textual, and positional embeddings into a joint space on which standard label propagation is applied in a plug-and-play manner to partially annotated bounding boxes. On the D4LA dataset the method reports 54.0% mAP (81.6% of fully-supervised performance) using only 10% labelled data.
Significance. If the central result is reproducible and the embedding separation is shown to be the operative mechanism, the work would offer a practical route to lowering re-annotation costs for continuously growing document-layout corpora by adapting label-propagation ideas from classification to detection.
major comments (2)
- [Abstract] Abstract: the headline claim (54.0% mAP = 81.6% of fully supervised with 10% labels) rests on the untested premise that the joint visual+textual+positional embedding produces a metric space in which label propagation reliably recovers correct layout classes rather than propagating errors; no nearest-neighbour accuracy, t-SNE separation, or component ablation is supplied to support this condition for visually confusable document classes.
- [Methods / Evaluation] Methods / Evaluation: the experimental protocol (selection of the 10% labelled subset, choice of propagation algorithm and graph construction, baseline comparisons, error bars, and validation that the encoder was not trained with class supervision) is absent from the abstract and therefore cannot be assessed; without these details the reported recovery rate cannot be attributed to the proposed embedding.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and indicate the revisions that will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim (54.0% mAP = 81.6% of fully supervised with 10% labels) rests on the untested premise that the joint visual+textual+positional embedding produces a metric space in which label propagation reliably recovers correct layout classes rather than propagating errors; no nearest-neighbour accuracy, t-SNE separation, or component ablation is supplied to support this condition for visually confusable document classes.
Authors: We agree that the abstract presents the headline result without direct supporting analyses of the embedding space. In the revised manuscript we will add nearest-neighbour accuracy figures, t-SNE visualizations of the joint embedding, and component-wise ablations (visual, textual, positional) to the experimental section. These additions will demonstrate class separation and justify the use of label propagation on the learned metric. revision: yes
-
Referee: [Methods / Evaluation] Methods / Evaluation: the experimental protocol (selection of the 10% labelled subset, choice of propagation algorithm and graph construction, baseline comparisons, error bars, and validation that the encoder was not trained with class supervision) is absent from the abstract and therefore cannot be assessed; without these details the reported recovery rate cannot be attributed to the proposed embedding.
Authors: We acknowledge that the abstract omits these protocol details. We will revise the abstract to include a concise description of the 10% subset selection procedure, the label-propagation algorithm and graph construction, the baselines used, and explicit confirmation that the object encoder was trained without class supervision. Error bars will be reported where applicable. The full protocol already appears in Sections 3 and 4; the revision will make these elements visible at the abstract level so that the contribution can be properly evaluated. revision: yes
Circularity Check
No circularity; plug-and-play framework with empirical evaluation on external dataset
full rationale
The paper introduces BBLP as a semi-supervised pseudo-labelling framework that combines an object encoder (visual + textual + positional embeddings) with standard label propagation. No equations, fitted parameters, or self-referential definitions appear in the abstract or described method. The headline result (54.0% mAP on D4LA with 10% labels) is an empirical measurement against a fully-supervised baseline, not a quantity derived by construction from the authors' own prior fits or self-citations. The derivation chain is self-contained against external benchmarks and does not reduce to any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proc
Antonacopoulos, A., Bridson, D., Papadopoulos, C., Pletschacher, S.: A realistic dataset for performance evaluation of document layout analysis. In: Proc. 10th Int. Conf. on Document Analysis and Recognition. pp. 296–300. Barcelona, Spain (Jul 2009)
2009
-
[2]
Banerjee, A., Biswas, S., Lladós, J., Pal, U.: SemiDocSeg: Harnessing semi- supervised learning for document layout analysis. Int. J. on Document Analysis and Recognition27(3), 317–334 (Jun 2024)
2024
-
[3]
In: Proc
Beyer, L., Izmailov, P., Kolesnikov, A., Caron, M., Kornblith, S., Zhai, X., Minderer, M., Tschannen, M., Alabdulmohsin, I., Pavetic, F.: Flexivit: One model for all patch sizes. In: Proc. 2023 IEEE/CVF Conf. on Computer Vision and Pattern Recognition. pp. 14496–14506. Vancouver, BC, Canada (Jun 2023)
2023
-
[4]
ACM Comput
Binmakhashen, G.M., Mahmoud, S.A.: Document layout analysis: A comprehensive survey. ACM Comput. Surv.52(6), article no. 109 (Oct 2019)
2019
-
[5]
In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M. (eds.) Computer Vision - ECCV 2020, Lecture Notes in Computer Science, vol. 12346, pp. 213–229. Springer, Cham (2020)
2020
-
[6]
The MIT Press (2006)
Chapelle, O., Schölkopf, B., Zien, A.: Semi-Supervised Learning. The MIT Press (2006)
2006
-
[7]
In: Proc
Da, C., Luo, C., Zheng, Q., Yao, C.: Vision grid transformer for document layout analysis. In: Proc. 2023 IEEE/CVF Int. Conf. on Computer Vision. pp. 19405–19415. Paris, France (Oct 2023)
2023
-
[8]
In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S
Dehghani, M., Mustafa, B., Djolonga, J., Heek, J., Minderer, M., Caron, M., Steiner, A., Puigcerver, J., Geirhos, R., Alabdulmohsin, I.M., Oliver, A., Padlewski, P., Gritsenko, A.A., Lucic, M., Houlsby, N.: Patch n’ pack: Navit, a vision transformer for any aspect ratio and resolution. In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine,...
2023
-
[9]
In: Proc
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: Proc. 9th Int. Conf. on Learning Representations. Vienna, Austria (May 2021)
2021
-
[10]
van Engelen, J.E., Hoos, H.H.: A survey on semi-supervised learning. Mach. Learn. 109(2), 373–440 (Nov 2019)
2019
-
[11]
Gemelli, A., Marinai, S., Pisaneschi, L., Santoni, F.: Datasets and annotations for layout analysis of scientific articles. Int. J. on Document Analysis and Recognition 27(4), 683–705 (Nov 2024)
2024
-
[12]
In: Proc
Girshick, R.B., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proc. 2014 IEEE Conf. on Computer Vision and Pattern Recognition. pp. 580–587. Columbus, OH (Jun 2014)
2014
-
[13]
In: Proc
Hadsell, R., Chopra, S., LeCun, Y.: Dimensionality reduction by learning an invariant mapping. In: Proc. 2006 IEEE Conf. on Computer Vision and Pattern Recognition. pp. 1735–1742. New York, NY (Jun 2006)
2006
-
[14]
In: Proc
Huang, Q., He, H., Singh, A., Lim, S.N., Benson, A.R.: Combining label propagation and simple models out-performs graph neural networks. In: Proc. 9th Int. Conf. on Learning Representations. Vienna, Austria (May 2021) 16 N. Jochum et al
2021
-
[15]
In: Magalhães, J., Bimbo, A.D., Satoh, S., Sebe, N., Alameda-Pineda, X., Jin, Q., Oria, V., Toni, L
Huang, Y., Lv, T., Cui, L., Lu, Y., Wei, F.: LayoutLMv3: Pre-training for document AI with unified text and image masking. In: Magalhães, J., Bimbo, A.D., Satoh, S., Sebe, N., Alameda-Pineda, X., Jin, Q., Oria, V., Toni, L. (eds.) Proc. 30th ACM Int. Conf. on Multimedia. pp. 4083–4091. Lisbon, Portugal (Oct 2022)
2022
-
[16]
In: Proc
Iscen, A., Tolias, G., Avrithis, Y., Chum, O.: Label propagation for deep semi- supervised learning. In: Proc. 2019 IEEE Conf. on Computer Vision and Pattern Recognition. pp. 5070–5079. Long Beach, CA (Jun 2019)
2019
-
[17]
Future Internet14(6), article no
Kallempudi, G., Hashmi, K.A., Pagani, A., Afzal, M.Z., Stricker, D.: Toward semi- supervised graphical object detection in document images. Future Internet14(6), article no. 176 (june 2022)
2022
-
[18]
In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T
Li, G., Li, X., Wang, Y., Wu, Y., Liang, D., Zhang, S.: PseCo: Pseudo labeling and consistency training for semi-supervised object detection. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision - ECCV 2022, Lecture Notes in Computer Science, vol. 13669, pp. 457–472. Springer, Cham (2022)
2022
-
[19]
In: Magalhães, J., Bimbo, A.D., Satoh, S., Sebe, N., Alameda-Pineda, X., Jin, Q., Oria, V., Toni, L
Li, J., Xu, Y., Lv, T., Cui, L., Zhang, C., Wei, F.: DiT: Self-supervised pre-training for document image transformer. In: Magalhães, J., Bimbo, A.D., Satoh, S., Sebe, N., Alameda-Pineda, X., Jin, Q., Oria, V., Toni, L. (eds.) Proc. 30th ACM Int. Conf. on Multimedia. pp. 3530–3539. Lisbon, Portugal (Oct 2022)
2022
-
[20]
In: Scott, D., Bel, N., Zong, C
Li, M., Xu, Y., Cui, L., Huang, S., Wei, F., Li, Z., Zhou, M.: DocBank: A bench- mark dataset for document layout analysis. In: Scott, D., Bel, N., Zong, C. (eds.) Proc. 28th Int. Conf. on Computational Linguistics. pp. 949–960. Barcelona, Spain (Dec 2020)
2020
-
[21]
In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T
Lin, T., Maire, M., Belongie, S., Bourdev, L., Girshick, R., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft COCO: Common objects in context. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) Computer Vision - ECCV 2014, Lecture Notes in Computer Science, vol. 8693, pp. 740–755. Springer, Cham (2014)
2014
-
[22]
IEEE Trans
Lin, T.Y., Goyal, P., Girshick, R.B., He, K., Dollár, P.: Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell.42(2), 318–327 (Feb 2020)
2020
-
[23]
In: Proc
Liu, Y.C., Ma, C.Y., He, Z., Kuo, C.W., Chen, K., Zhang, P., Wu, B., Kira, Z., Vajda, P.: Unbiased teacher for semi-supervised object detection. In: Proc. 9th Int. Conf. on Learning Representations. Vienna, Austria (May 2021)
2021
-
[24]
In: Proc
Nassar, A., Livanthinos, N., Lysak, M., Staar, P.: TableFormer: Table structure understanding with transformers. In: Proc. 2022 IEEE/CVF Conf. on Computer Vision and Pattern Recognition. pp. 4604–4613. New Orleans, LA (Jun 2022)
2022
-
[25]
In: Zhang, A., Rang- wala, H
Pfitzmann, B., Auer, C., Dolfi, M., Nassar, A.S., Staar, P.: DocLayNet: A large human-annotated dataset for document-layout segmentation. In: Zhang, A., Rang- wala, H. (eds.) Proc. 28th ACM SIGKDD Conf. on Knowledge Discovery and Data Mining. pp. 3743–3751. Washington, DC (Aug 2022)
2022
-
[26]
In: Proc
Redmon, J., Divvala, S.K., Girshick, R.B., Farhadi, A.: You only look once: Unified, real-time object detection. In: Proc. 2016 IEEE Conf. on Computer Vision and Pattern Recognition. pp. 779–788. Las Vegas, NV (Jun 2016)
2016
-
[27]
In: Proc
Ren, S., He, K., Girshick, R.B., Sun, J.: Faster R-CNN: Towards real-time object detection with region proposal networks. In: Proc. 29th Int. Conf. on Neural Infor- mation Processing Systems. Advances in Neural Information Processing Systems, vol. 28, pp. 91–99. Montreal, QC, Canada (Dec 2015)
2015
-
[28]
In: Proc
Rizve, M.N., Duarte, K., Rawat, Y.S., Shah, M.: In defense of pseudo-labeling: An uncertainty-aware pseudo-label selection framework for semi-supervised learning. In: Proc. 9th Int. Conf. on Learning Representations. Vienna, Austria (May 2021)
2021
-
[29]
In: Proc
Smith, R.: An overview of the tesseract OCR engine. In: Proc. 9th Int. Conf. on Document Analysis and Recognition. pp. 629–633. Curitiba, Brazil (Sep 2007) Bounding Box Label Propagation 17
2007
-
[30]
arXiv:2005.04757v2 [cs.CV] (2020)
Sohn, K., Zhang, Z., Li, C.L., Zhang, H., Lee, C.Y., Pfister, T.: A simple semi- supervised learning framework for object detection. arXiv:2005.04757v2 [cs.CV] (2020)
-
[31]
In: Proc
Tang, Y., Chen, W., Luo, Y., Zhang, Y.: Humble teachers teach better students for semi-supervised object detection. In: Proc. 2021 IEEE/CVF Conf. on Computer Vision and Pattern Recognition. pp. 3132–3141. virtual (Jun 2021)
2021
-
[32]
In: Proc
Tang, Z., Yang, Z., Wang, G., Fang, Y., Liu, Y., Zhu, C., Zeng, M., Zhang, C., Bansal, M.: Unifying vision, text, and layout for universal document processing. In: Proc. 2023 IEEE/CVF Conf. on Computer Vision and Pattern Recognition. pp. 19254–19264. Vancouver, BC, Canada (Jun 2023)
2023
-
[33]
In: Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R
Tarvainen, A., Valpola, H.: Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In: Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R. (eds.) Proc. 31st Int. Conf. on Neural Information Processing Systems. Advances in Neural Information P...
2017
-
[34]
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y., Mustafa, B.: Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features. arXiv:2502.14786 [cs.CV] (Feb 2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
In: Smith, E.H.B., Liwicki, M., Peng, L
Wang, J., Hu, K., Huo, Q.: DLAFormer: An end-to-end transformer for document layout analysis. In: Smith, E.H.B., Liwicki, M., Peng, L. (eds.) Document Analysis and Recognition - ICDAR 2024, Lecture Notes in Computer Science, vol. 14807, pp. 40–57. Springer, Cham (2024)
2024
-
[36]
Multilingual E5 Text Embeddings: A Technical Report
Wang, L., Yang, N., Huang, X., Yang, L., Majumder, R., Wei, F.: Multilingual E5 text embeddings: A technical report. arXiv:2402.05672v1 [cs.CL] (Feb 2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
In: Proc
Xu, M., Zhang, Z., Hu, H., Wang, J., Wang, L., Wei, F., Bai, X., Liu, Z.: End-to-end semi-supervised object detection with soft teacher. In: Proc. 2021 IEEE/CVF Int. Conf. on Computer Vision. pp. 3040–3049. Montreal, Canada (Oct 2021)
2021
-
[38]
In: Proc
Xu, Y., Li, M., Cui, L., Huang, S., Wei, F., Zhou, M.: LayoutLM: Pre-training of text and layout for document image understanding. In: Proc. 26th ACM SIGKDD Conf. on Knowledge Discovery and Data Mining. pp. 1192–1200. virtual (Aug 2020)
2020
-
[39]
In: Proc
Zhang, H., Li, F., Liu, S., Zhang, L., Su, H., Zhu, J., Ni, L.M., Shum, H.Y.: DINO: DETR with improved denoising anchor boxes for end-to-end object detection. In: Proc. 11th Int. Conf. on Learning Representations. Kigali, Rwanda (May 2023)
2023
-
[40]
In: Proc
Zhong, X., Tang, J., Jimeno-Yepes, A.: PubLayNet: Largest dataset ever for docu- ment layout analysis. In: Proc. 2019 Int. Conf. on Document Analysis and Recogni- tion. pp. 1015–1022. Sydney, Australia (Sep 2019)
2019
-
[41]
In: Thrun, S., Saul, L.K., Schölkopf, B
Zhou, D., Bousquet, O., Lal, T.N., Weston, J., Schölkopf, B.: Learning with local and global consistency. In: Thrun, S., Saul, L.K., Schölkopf, B. (eds.) Proc. 17th Int. Conf. on Neural Information Processing Systems. Advances in Neural Information Processing Systems, vol. 16, pp. 321–328. Vancouver and Whistler, Canada (Dec 2003)
2003
-
[42]
In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T
Zhou, H., Ge, Z., Liu, S., Mao, W., Li, Z., Yu, H., Sun, J.: Dense teacher: Dense pseudo-labels for semi-supervised object detection. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision - ECCV 2022, Lecture Notes in Computer Science, vol. 13669, pp. 35–50. Springer, Cham (2022)
2022
-
[43]
Technical report (2002)
Zhu, X., Ghahramani, Z.: Learning from labeled and unlabeled data with label propagation. Technical report (2002)
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.