Bridging Functional Correctness and Runtime Efficiency Gaps in LLM-Based Code Translation
Pith reviewed 2026-06-27 00:53 UTC · model grok-4.3
The pith
SwiftTrans improves both correctness and runtime efficiency of LLM-based code translations through diverse candidate generation and difference-based selection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
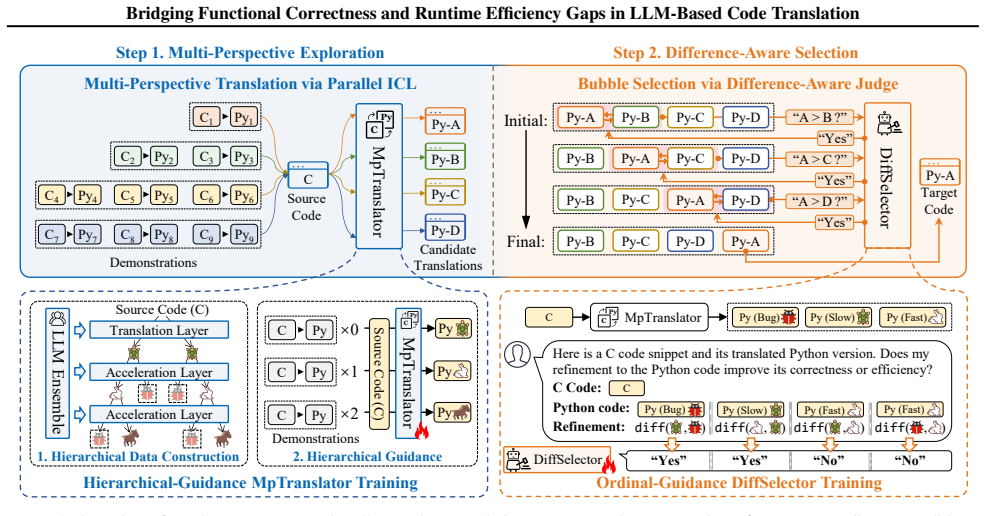
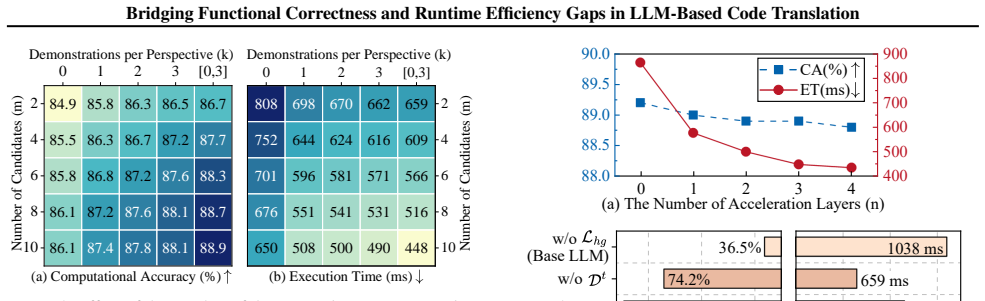
The central claim is that the SwiftTrans framework, consisting of Multi-Perspective Exploration with MpTranslator and Difference-Aware Selection with DiffSelector, along with Hierarchical Guidance and Ordinal Guidance, enables LLMs to produce code translations that are both functionally correct and runtime efficient, as demonstrated by improvements across three benchmarks.
What carries the argument
SwiftTrans, the two-stage code translation framework with MpTranslator for generating diverse candidates via parallel ICL and DiffSelector for optimal selection via explicit difference comparison.
If this is right
- Translated programs achieve better runtime performance without sacrificing functional correctness.
- LLM translations can be optimized for efficiency by selecting among candidates rather than single outputs.
- The introduced benchmarks allow for standardized evaluation of both correctness and efficiency in code translation.
- Guidance techniques help LLMs handle the tasks of exploration and selection effectively.
Where Pith is reading between the lines
- Similar selection mechanisms based on differences could apply to other LLM tasks like code generation or summarization.
- The approach suggests that post-generation selection is a viable way to bridge performance gaps in LLM outputs.
- Future work might explore integrating runtime profiling directly into the selection process for even better results.
Load-bearing premise
Runtime efficiency differences between translation candidates can be reliably identified and selected by the DiffSelector without introducing new biases or requiring post-hoc tuning.
What would settle it
Running SwiftTrans on additional translation tasks where the selected candidates do not show measurable runtime improvements over baselines while maintaining correctness would falsify the claim.
Figures



read the original abstract
While large language models (LLMs) have greatly advanced the functional correctness of automated code translation systems, the runtime efficiency of translated programs has received comparatively little attention. With the waning of Moore's law, runtime efficiency has become increasingly important for program quality, alongside functional correctness. Our preliminary study reveals that LLM-translated programs often run slower than human-written ones, and this issue cannot be remedied through prompt engineering alone. Therefore, our work proposes SwiftTrans, a code translation framework comprising two key stages: (1) Multi-Perspective Exploration, where MpTranslator leverages parallel in-context learning (ICL) to generate diverse translation candidates; and (2) Difference-Aware Selection, where DiffSelector identifies the optimal candidate by explicitly comparing differences between translations. We further introduce Hierarchical Guidance for MpTranslator and Ordinal Guidance for DiffSelector, enabling LLMs to better adapt to these two core components. To support the evaluation of runtime efficiency in translated programs, we extend existing benchmarks, CodeNet and F2SBench, and introduce a new benchmark, SwiftBench. Experimental results across all three benchmarks show that SwiftTrans achieves consistent improvements in both correctness and runtime efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SwiftTrans, a two-stage framework for LLM-based code translation. MpTranslator performs multi-perspective exploration via parallel in-context learning and Hierarchical Guidance to produce diverse translation candidates. DiffSelector then performs difference-aware selection with Ordinal Guidance to identify the candidate that best balances correctness and runtime efficiency. The authors extend CodeNet and F2SBench, introduce SwiftBench, and report experimental results showing consistent gains in both functional correctness and runtime efficiency across the three benchmarks, with per-benchmark deltas accompanied by standard deviations and runtime measurements obtained via repeated executions.
Significance. If the reported results hold, the work is significant because it directly tackles the runtime-efficiency gap in LLM code translation—an issue the authors show cannot be fixed by prompt engineering alone and that grows in importance as Moore’s law ends. The explicit two-component pipeline, the new guidance mechanisms, the extended and newly introduced benchmarks, and the use of repeated executions with standard deviations together supply both a practical method and an evaluation protocol that future work can build upon.
minor comments (2)
- [Abstract] Abstract: the claim of “consistent improvements” is stated without any numerical deltas, baseline names, or error-bar information, even though the body supplies these quantities; adding a single sentence with representative numbers would improve the abstract’s utility.
- [Evaluation section] The description of the runtime-measurement protocol (number of repetitions, warm-up runs, hardware, and timeout policy) is referenced but could be collected into a single dedicated paragraph or table for easier reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our manuscript and the recommendation for minor revision. We appreciate the recognition of the importance of addressing runtime efficiency alongside functional correctness in LLM-based code translation, as well as the value placed on our benchmarks and evaluation protocol.
Circularity Check
No significant circularity detected
full rationale
The manuscript describes an empirical LLM-based code translation framework (SwiftTrans) built from two new components (MpTranslator with hierarchical guidance and DiffSelector with ordinal guidance) and evaluates it on three external benchmarks (extended CodeNet, F2SBench, and newly introduced SwiftBench). No equations, fitted parameters, self-referential predictions, or load-bearing self-citations appear in the derivation; the reported gains are measured outcomes on independent test suites rather than quantities that reduce to the method's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can produce functionally correct translations via in-context learning when given appropriate examples
- domain assumption Differences between translation candidates can be used to infer relative runtime efficiency
invented entities (5)
-
MpTranslator
no independent evidence
-
DiffSelector
no independent evidence
-
Hierarchical Guidance
no independent evidence
-
Ordinal Guidance
no independent evidence
-
SwiftBench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
E., Jones, S., Biswas, A., Alexan- drov, B., and O’Malley, D
Bhattarai, M., Santos, J. E., Jones, S., Biswas, A., Alexan- drov, B., and O’Malley, D. Enhancing code translation in language models with few-shot learning via retrieval- augmented generation.arXiv preprint arXiv:2407.19619, 2024a. Bhattarai, M., Vu, M., Santos, J. E., Boureima, I., and Malley, D. O. Enhancing cross-language code transla- tion via task-s...
-
[2]
Tree-to-tree neural networks for program translation.arXiv preprint arXiv:1802.03691,
Chen, X., Liu, C., and Song, D. Tree-to-tree neural networks for program translation.arXiv preprint arXiv:1802.03691,
-
[3]
Gee, L., Gritta, M., Lampouras, G., and Iacobacci, I. Code- optimise: Self-generated preference data for correctness and efficiency.arXiv preprint arXiv:2406.12502,
-
[4]
He, M., Yang, F., Zhao, P., Yin, W., Kang, Y ., Lin, Q., Rajmohan, S., Zhang, D., and Zhang, Q. Execoder: Empowering large language models with executabil- ity representation for code translation.arXiv preprint arXiv:2501.18460,
-
[5]
Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., Liu, T., Zhang, J., Yu, B., Dang, K., et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186,
-
[6]
R., Ke, K., Pawagi, M., Abid, M
Ibrahimzada, A. R., Ke, K., Pawagi, M., Abid, M. S., Pan, R., Sinha, S., and Jabbarvand, R. Alphatrans: A neuro- symbolic compositional approach for repository-level code translation and validation.Proc. ACM Softw. Eng., 2(FSE), June 2025a. doi: 10.1145/3729379. Ibrahimzada, A. R., Ke, K., Pawagi, M., Abid, M. S., Pan, R., Sinha, S., and Jabbarvand, R. Al...
-
[7]
Lost in the middle: How language models use long contexts
doi: 10.1162/tacl a 00638. Lozhkov, A., Li, R., Allal, L. B., Cassano, F., Lamy-Poirier, J., Tazi, N., Tang, A., Pykhtar, D., Liu, J., Wei, Y ., Liu, T., Tian, M., Kocetkov, D., Zucker, A., Belkada, Y ., Wang, Z., Liu, Q., Abulkhanov, D., Paul, I., Li, Z., Li, W.-D., Risdal, M., Li, J., Zhu, J., Zhuo, T. Y ., Zheltonozhskii, E., Dade, N. O. O., Yu, W., Kr...
work page internal anchor Pith review doi:10.1162/tacl
-
[8]
Puri, R., Kung, D. S., Janssen, G., Zhang, W., Domeni- coni, G., Zolotov, V ., Dolby, J., Chen, J., Choudhury, M., 10 Bridging Functional Correctness and Runtime Efficiency Gaps in LLM-Based Code Translation Decker, L., et al. Codenet: A large-scale ai for code dataset for learning a diversity of coding tasks.arXiv preprint arXiv:2105.12655,
-
[9]
Waghjale, S., Veerendranath, V ., Wang, Z. Z., and Fried, D. Ecco: Can we improve model-generated code efficiency without sacrificing functional correctness?arXiv preprint arXiv:2407.14044,
-
[10]
Wang, Y ., Wang, Y ., Wang, S., Guo, D., Chen, J., Grundy, J., Liu, X., Ma, Y ., Mao, M., Zhang, H., et al. Repotrans- bench: A real-world benchmark for repository-level code translation.arXiv preprint arXiv:2412.17744, 2024a. Wang, Y ., Ou, R., Wang, Y ., Liu, M., Chen, J., Shi, E., Liu, X., Ma, Y ., and Zheng, Z. Effireasontrans: Rl- optimized reasoning...
-
[11]
Large language model enabled semantic communication systems, 2024b
Wang, Z., Zou, L., Wei, S., Liao, F., Zhuo, J., Mi, H., and Lai, R. Large language model enabled semantic communication systems, 2024b. Xu, R., Wang, Z., Fan, R.-Z., and Liu, P. Benchmark- ing benchmark leakage in large language models.arXiv preprint arXiv:2404.18824,
-
[12]
Yan, W., Tian, Y ., Li, Y ., Chen, Q., and Wang, W. Code- transocean: A comprehensive multilingual benchmark for code translation.arXiv preprint arXiv:2310.04951,
-
[13]
Yin, X., Ni, C., Nguyen, T. N., Wang, S., and Yang, X. Rectifier: Code translation with corrector via llms.arXiv preprint arXiv:2407.07472,
-
[14]
Speed up your code: Progressive code acceleration through bidirectional tree editing
Zhang, H., David, C., Wang, M., Paulsen, B., and Kroening, D. Scalable, validated code translation of entire projects using large language models.Proceedings of the ACM on Programming Languages, 9(PLDI):1616–1641, 2025a. Zhang, L., Wang, B., Wang, J., Zhao, X., Zhang, M., Yang, H., Zhang, M., LI, Y ., Li, J., Yu, J., and Zhang, M. Function-to-style guidan...
-
[15]
lost-in-the-middle
11 Bridging Functional Correctness and Runtime Efficiency Gaps in LLM-Based Code Translation A. Benchmark Analysis Table 8.Data statistics of CodeNet, F2SBench, and SWIFTBENCH. Benchmark #Code #Cases Code Coverage Branch Coverage Date CodeNet200×5 1091% 78% Pre-2021 F2SBench1000×5 1086% 75% Mid-2024 SWIFTBENCH(Ours) 500×5 10 85% 73% Jun.–Oct. 2025 Table 9...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.