From Memorization to Creation: Evaluating the Cognitive Depth of LLM-Generated Educational Questions
Pith reviewed 2026-06-30 23:48 UTC · model grok-4.3
The pith
A fine-grained prompting strategy reduces repetitiveness in LLM-generated educational questions by 24.45 percent and raises higher-order cognitive outputs by 11.53 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
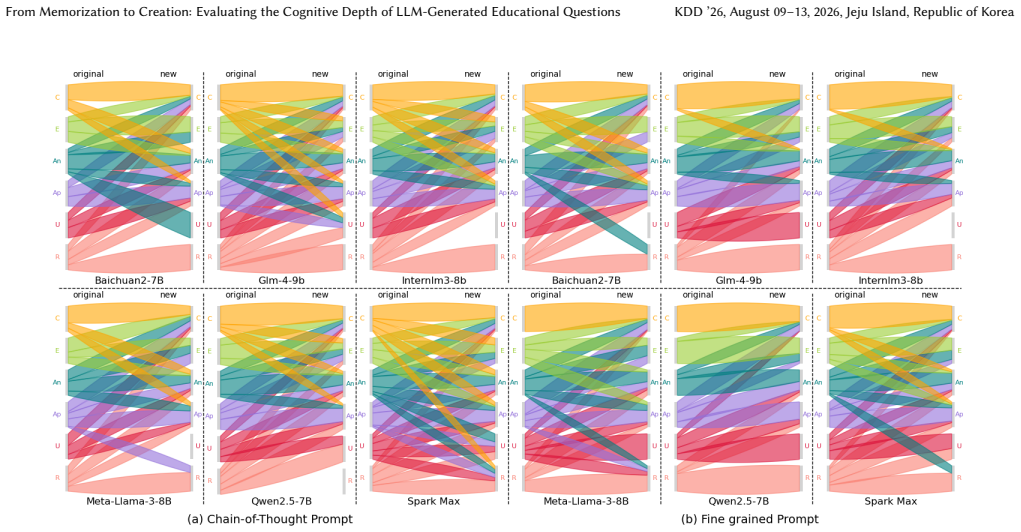
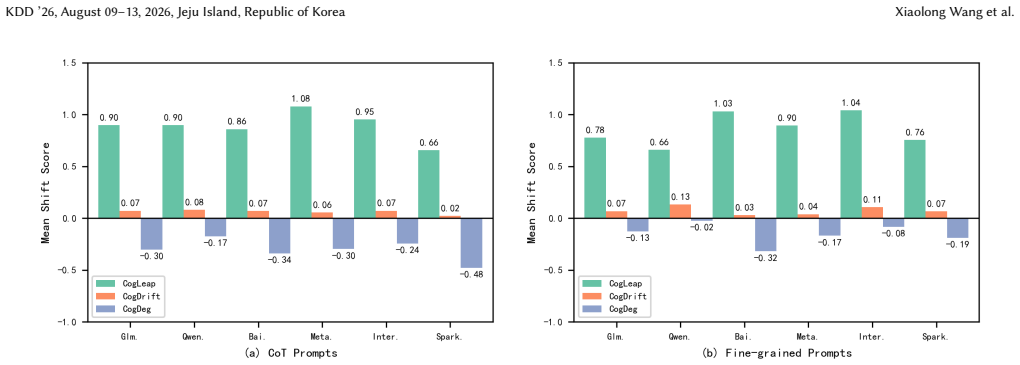
Fine-grained prompting strategies enable LLMs to produce educational questions with measurably greater cognitive depth according to Bloom's Taxonomy, cutting repetitiveness by 24.45 percent in Qwen2.5-7B-Instruct and lifting the proportion of higher-order outputs by 11.53 percent in InternLM3-8B-Instruct, with InternLM3 also showing the strongest performance on multi-level cognitive transitions as quantified by the CogShift intensity and category-drift metrics.
What carries the argument
The fine-grained prompting strategy that directs models toward explicit Bloom's Taxonomy levels, paired with the hybrid human-AI evaluation protocol and the CogShift metric that quantifies cognitive shift intensity.
If this is right
- LLMs become more usable for creating questions that target analysis, evaluation, and creation rather than recall.
- InternLM3 demonstrates stronger capacity for transitioning across multiple Bloom's levels than the other five models tested.
- Chain-of-Thought prompting produces interpretable correlations with the CogShift and category-drift metrics.
- The reported benchmarks can guide deployment of LLMs inside personalized learning systems that aim to build higher-order skills.
Where Pith is reading between the lines
- The same prompting approach could be tested in additional subject areas such as history or biology to check whether the gains generalize.
- If the CogShift metric proves stable, it might serve as an automatic filter for selecting which LLM outputs to use in live tutoring systems.
- Improved cognitive depth in questions might reduce student reliance on surface-level study habits, though that outcome would need separate measurement.
Load-bearing premise
That the hybrid human-AI evaluation protocol reliably and unbiasedly assesses the cognitive levels of generated questions according to Bloom's Taxonomy without significant inter-rater variability or model bias in the evaluation.
What would settle it
A fresh set of 1,000 generated questions re-scored by a new panel of human raters who were not involved in the original protocol yields cognitive-level distributions that differ by more than 15 percent from the reported hybrid scores.
Figures




read the original abstract
While LLMs show promise in automating educational content creation, their ability to generate questions that stimulate higher-order thinking remains understudied. This work evaluates six widely-used LLMs through a Bloom's Taxonomy lens, focusing on their capacity to transcend rote memorization and achieve cognitive leaps. Using a hybrid human--AI evaluation protocol, we generate and analyze 20{,}700 questions across computer science, K--12 math, and social-science domains. Key contributions include: (1) a fine-grained prompting strategy that reduces question repetitiveness by 24.45\% for Qwen2.5-7B-Instruct, and increases the proportion of higher-order cognitive level outputs by 11.53\% for InternLM3-8B-Instruct; (2) quantitative metrics for cognitive shift intensity (CogShift) and category drift, revealing InternLM3's superior performance in multi-level transitions; (3) an interpretability analysis revealing metric-level correlations that enhance the transparency of Chain-of-Thought prompting. Our findings highlight the importance of cognitive-aware prompt design and provide benchmarks for deploying LLMs in personalized learning systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates six LLMs on their ability to generate educational questions that reach higher levels of Bloom's Taxonomy rather than rote memorization. It generates and analyzes 20,700 questions across computer science, K-12 math, and social-science domains via a hybrid human-AI protocol, introduces a fine-grained prompting strategy claimed to reduce repetitiveness by 24.45% (Qwen2.5-7B-Instruct) and raise higher-order outputs by 11.53% (InternLM3-8B-Instruct), defines CogShift and category-drift metrics, and reports an interpretability analysis of Chain-of-Thought prompting.
Significance. If the labeling protocol proves reliable, the work supplies concrete benchmarks and a new metric (CogShift) for measuring cognitive depth in LLM-generated educational content. These could usefully inform prompt design for personalized learning tools and provide comparative data across model families.
major comments (2)
- [Abstract] Abstract: the hybrid human-AI evaluation protocol is described only at the level of 'human-AI' with no inter-rater reliability statistics (Cohen/Fleiss kappa or percent agreement) among humans, no human-AI agreement rates, and no blinded validation set. All headline percentages (24.45% repetitiveness reduction, 11.53% higher-order increase) rest on Bloom's Taxonomy assignments to the 20,700 questions; without these metrics the deltas are uninterpretable.
- [Results section] Results (CogShift and multi-level transitions): the claim of InternLM3's superior performance in multi-level transitions is presented without the explicit formula for CogShift, without error bars or statistical significance tests on the category-drift comparisons, and without an ablation isolating which prompting components produce the reported shifts.
minor comments (1)
- [Abstract] The abstract mentions 'metric-level correlations' in the interpretability analysis but does not name the metrics or report the correlation coefficients; these should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation protocol and metric reporting. We address each major comment below and will revise the manuscript accordingly to enhance transparency and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the hybrid human-AI evaluation protocol is described only at the level of 'human-AI' with no inter-rater reliability statistics (Cohen/Fleiss kappa or percent agreement) among humans, no human-AI agreement rates, and no blinded validation set. All headline percentages (24.45% repetitiveness reduction, 11.53% higher-order increase) rest on Bloom's Taxonomy assignments to the 20,700 questions; without these metrics the deltas are uninterpretable.
Authors: We agree that the abstract provides only a high-level description. The full manuscript (Section 3.2) details the hybrid protocol but omits reliability statistics. We will add Cohen's kappa for human raters, human-AI agreement rates on a held-out validation set, and clarify the blinded labeling procedure. This will directly support the reported deltas. revision: yes
-
Referee: [Results section] Results (CogShift and multi-level transitions): the claim of InternLM3's superior performance in multi-level transitions is presented without the explicit formula for CogShift, without error bars or statistical significance tests on the category-drift comparisons, and without an ablation isolating which prompting components produce the reported shifts.
Authors: The CogShift definition appears in Section 4.1, but we acknowledge it lacks full explicitness and supporting statistics. We will insert the complete formula, add error bars with significance tests (e.g., paired t-tests or Wilcoxon) for category-drift results, and expand Section 5 with a targeted ablation isolating prompting components. These additions address the concerns without altering core claims. revision: yes
Circularity Check
No circularity: empirical counts from labeled generations
full rationale
The paper reports experimental results from generating 20,700 questions with six LLMs under different prompting strategies, then labeling them via a hybrid human-AI protocol against Bloom's Taxonomy levels. Headline deltas (24.45% repetitiveness reduction, 11.53% higher-order increase) and new metrics (CogShift, category drift) are obtained by direct counting and comparison of those labels; no equations, fitted parameters, or derivations are presented that reduce by construction to the inputs. No self-citation load-bearing uniqueness claims or ansatzes appear. The work is self-contained as an empirical benchmark study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2001.A taxonomy for learning, teaching, and assessing: A revision of Bloom’s taxonomy of educational objectives: complete edition
LW Anderson and DR Krathwohl. 2001.A taxonomy for learning, teaching, and assessing: A revision of Bloom’s taxonomy of educational objectives: complete edition. Addison Wesley Longman, Inc
2001
-
[2]
M Arvan, M Valizadeh, P Haghighat, et al . 2023. Linguistic Cognitive Load Analysis on Dialogues with an Intelligent Virtual Assistant. InProceedings of the Annual Meeting of the Cognitive Science Society, Vol. 45
2023
-
[3]
A Bartel, B Matlen, D Rohrer, et al. 2023. Applying cognitive learning principles to practice: Challenges in translation and large-scale study design. InProceedings of the Annual Meeting of the Cognitive Science Society, Vol. 45
2023
-
[4]
Zheng Cai and et al. 2024. InternLM2 Technical Report. arXiv:2403.17297 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Y Chen, N Ding, HT Zheng, et al. 2024. Empowering private tutoring by chaining large language models. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 354–364
2024
- [6]
-
[7]
Y Chen, Y Xiao, and B Liu. 2022. Grow-and-Clip: Informative-yet-Concise Evi- dence Distillation for Answer Explanation. In2022 IEEE 38th International Con- ference on Data Engineering (ICDE). IEEE, 741–754
2022
-
[8]
Christodoulos Constantinides, Varun Sharma, Sheng Lin, Nan Zhou, Bhaskar Chaudhury, and Divya Patel. 2025. Auto-Q: Automated Domain Questions Gen- eration for Industrial Assets. InProceedings of the AAAI Conference on Artificial Intelligence
2025
- [9]
-
[10]
K D’Silva and B Matlen. 2023. Embedding Equitable Research Practices into the Rigorous Study of a Cognitive Learning Intervention. InProceedings of the Annual Meeting of the Cognitive Science Society, Vol. 45
2023
-
[11]
Zhengxiao Du and et al. 2024. ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools. arXiv:2406.12793 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
S Elkins, E Kochmar, JCK Cheung, et al . 2024. How Teachers Can Use Large Language Models and Bloom’s Taxonomy to Create Educational Quizzes. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 23084–23091
2024
-
[13]
Dubey et al. and LLaMA Team. 2024. The Llama 3 Herd of Models. arXiv:2407.21783 [cs.AI]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
M Fedyk and M Ray. 2023. How to Leverage Machine Learning Interpretability and Explainability to Generate Hypotheses in Cognitive Psychology. InProceed- ings of the Annual Meeting of the Cognitive Science Society, Vol. 45
2023
-
[15]
T Feng and L He. 2025. RGR-KBQA: Generating Logical Forms for Question An- swering Using Knowledge-Graph-Enhanced Large Language Model. InProceed- ings of the 31st International Conference on Computational Linguistics. 3057–3070
2025
-
[16]
H Gong, L Pan, and H Hu. 2022. Khanq: A dataset for generating deep questions in education. InProceedings of the 29th International Conference on Computational Linguistics. 5925–5938
2022
-
[17]
Baichuan Inc. 2023. Baichuan2: Open Large Language Models. arXiv:2310.11453 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
T Kojima, SS Gu, M Reid, et al . 2022. Large language models are zero-shot reasoners.Advances in neural information processing systems35 (2022), 22199– 22213
2022
-
[19]
R Kokku, S Sundararajan, P Dey, et al. 2018. Augmenting classrooms with AI for personalized education. In2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 6976–6980
2018
- [20]
-
[21]
K Li and Y Zhang. 2024. Planning First, Question Second: An LLM-Guided Method for Controllable Question Generation. InFindings of the Association for Computational Linguistics ACL 2024. 4715–4729
2024
-
[22]
H Liao, S He, Y Hao, et al. 2025. SKIntern: Internalizing Symbolic Knowledge for Distilling Better CoT Capabilities into Small Language Models. InProceedings of the 31st International Conference on Computational Linguistics. 3203–3221
2025
-
[23]
H Liao, S He, Y Xu, et al. 2025. Awakening Augmented Generation: Learning to Awaken Internal Knowledge of Large Language Models for Question Answering. InProceedings of the 31st International Conference on Computational Linguistics. 1333–1352
2025
-
[24]
J Liu, Y Huang, S Bi, et al. 2025. From Superficial to Deep: Integrating External Knowledge for Follow-up Question Generation Using Knowledge Graph and LLM. InProceedings of the 31st International Conference on Computational Linguistics. 828–840
2025
-
[25]
SS Mucciaccia, TM Paixão, FW Mutz, et al . 2025. Automatic Multiple-Choice Question Generation and Evaluation Systems Based on LLM: A Study Case With University Resolutions. InProceedings of the 31st International Conference on Computational Linguistics. 2246–2260
2025
-
[26]
H Muse, S Bulathwela, and E Yilmaz. 2023. Pre-training with scientific text improves educational question generation (student abstract). InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 16288–16289
2023
-
[27]
JW Park, SJ Park, HS Won, et al . 2024. Large Language Models are Students at Various Levels: Zero-shot Question Difficulty Estimation. InFindings of the Association for Computational Linguistics: EMNLP 2024. 8157–8177
2024
-
[28]
X Qiu and Z Chen. 2025. A Knowledge Graph Reasoning-Based Model for Computerized Adaptive Testing. InProceedings of the 31st International Conference on Computational Linguistics. 5295–5304
2025
-
[29]
M Ravikiran, S Vohra, R Verma, et al. 2025. TEEMIL: Towards Educational MCQ Difficulty Estimation in Indic Languages. InProceedings of the 31st International Conference on Computational Linguistics. 2085–2099
2025
-
[30]
N Scaria, Dharani S Chenna, and D Subramani. 2024. Automated Educational Question Generation at Different Bloom’s Skill Levels Using Large Language Mod- els: Strategies and Evaluation. InInternational Conference on Artificial Intelligence in Education. Springer Nature Switzerland, Cham, 165–179
2024
- [31]
-
[32]
S Tobler, T Sinha, K Koehler, et al . 2022. The impact of prior knowledge in narrative-based learning on understanding biological concepts in higher ed- ucation. InProceedings of the Annual Meeting of the Cognitive Science Society, Vol. 44
2022
- [33]
-
[34]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. Self-Instruct: Aligning Language Models with Self-Generated Instructions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL)
2023
-
[35]
J Wei, X Wang, D Schuurmans, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[36]
Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, and Bill Yuchen Lin. 2025. Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing. InProceedings of the Interna- tional Conference on Learning Representations (ICLR)
2025
-
[37]
An Yang and et al. 2025. Qwen2.5 Technical Report. arXiv:2412.15115 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [38]
-
[39]
✓” indicates that the aspect is explicitly addressed, while “–
Khandoker Ashik Uz Zaman, Ashraful Islam, Yusuf Mahbubul Islam, and Md Abu Sayed. 2024. Dataset of computer science course queries from students: Cat- egorized and scored according to Bloom’s taxonomy.Data in Brief53 (2024), 110109. A Comparative dimensions. In Table 2, DS denotes explicit data synthesis for instructions or questions, Bloom explicit contr...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.