SC3-Eval: Evaluating Robot Foundation Models via Self-Consistent Video Generation
Pith reviewed 2026-06-26 21:15 UTC · model grok-4.3
The pith
Enforcing forward-inverse dynamics, cross-view inpainting, and test-time termination turns a video foundation model into an accurate evaluator of robot policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
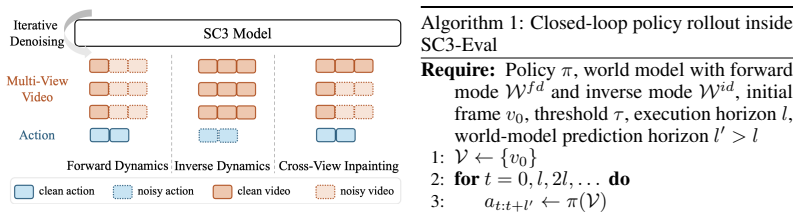
SC3-Eval adapts a pre-trained video foundation model into a policy evaluator by jointly training forward and inverse dynamics to keep generated rollouts on a physically plausible action manifold, training cross-view inpainting to maintain multi-camera coherence over long horizons without explicit memory, and reusing inverse dynamics at test time as an uncertainty signal to terminate inconsistent rollouts. This self-consistent recipe produces evaluations that match real-world policy performance with a closed-loop Pearson correlation of 0.929 and MMRV of 0.119 across seven policies, reproduce specific failure modes, outperform three prior video-model baselines, and generalize to new tasks.
What carries the argument
SC3-Eval self-consistent video generation recipe that jointly trains forward-inverse dynamics consistency, cross-view inpainting consistency, and test-time consistency via inverse-dynamics uncertainty termination.
If this is right
- Policy ranking and fine-grained failure diagnosis become possible from simulated video alone without physical deployment.
- The evaluator works for policies whose behaviors were not seen during its own training.
- Multi-view coherence holds across long action sequences without needing recurrent memory.
- Rollouts remain anchored to physically plausible actions because inverse dynamics penalizes drift that forward-only models miss.
Where Pith is reading between the lines
- The same three-consistency recipe could be applied to train better video predictors for other physical domains such as navigation or assembly.
- If the correlation holds on broader policy sets, development cycles for robot foundation models could shift toward simulation-first iteration.
- Extending the uncertainty signal to continuous per-frame monitoring rather than chunk termination might further reduce compounding error.
- The approach suggests that explicit inverse modeling is a general lever for making generative world models more reliable for downstream control tasks.
Load-bearing premise
That jointly training forward-inverse dynamics, cross-view inpainting, and uncertainty-based termination on a pre-trained video model is enough to keep long-horizon rollouts plausible and to generalize to policies outside the training distribution.
What would settle it
Test SC3-Eval on an eighth real-world policy whose action distribution lies substantially outside the original training data and check whether the predicted success rates and failure modes still match the measured real-world execution rates within the reported margins.
Figures








read the original abstract
Evaluating generalist robot manipulation policies in the real world is expensive, slow, and difficult to scale. Action-conditioned video world models offer a scalable alternative by simulating policy rollouts. Autoregressive rollouts accumulate compounding errors, observations across multiple camera views must remain mutually consistent, and the evaluator must generalize to policies whose behaviors lie outside the training distribution. We address these challenges with SC3-Eval, a self-consistent video generation recipe that adapts a pre-trained video foundation model into an accurate policy evaluator by enforcing three complementary forms of consistency. First, forward-inverse dynamics consistency jointly trains the model to predict frames from actions and to recover actions from frames, anchoring generated rollouts to a physically plausible action manifold and counteracting the drift a forward-only model cannot penalize. Second, cross-view consistency trains the model to inpaint each camera view from the other, keeping the multi-camera observation coherent over long rollouts without any explicit memory mechanism. Third, test-time consistency reuses the inverse dynamics mode at inference as a per-action-chunk uncertainty signal that terminates rollouts whose generated frames drift away from the requested actions. We also demonstrate SC3-Eval rollouts reproduce the failure modes that policies exhibit in real-world rollouts, supporting fine-grained diagnostic comparison rather than aggregate ranking alone. Across seven real-world vision-language-action policies, SC3-Eval attains a closed-loop Pearson correlation of $0.929$ and MMRV of $0.119$, outperforming three strong prior video-model-based baselines, and generalizes to new tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that SC3-Eval adapts a pre-trained video foundation model into a policy evaluator by jointly enforcing forward-inverse dynamics consistency (to anchor to a physically plausible action manifold), cross-view consistency (via inpainting for multi-camera coherence), and test-time consistency (inverse-dynamics-based termination to detect drift). Across seven real-world vision-language-action policies it reports a closed-loop Pearson correlation of 0.929 and MMRV of 0.119, outperforming three video-model baselines, reproducing real-world failure modes, and generalizing to new tasks.
Significance. If the reported correlation and outperformance hold under scrutiny, the work would be a meaningful contribution to scalable robot policy evaluation, offering a concrete alternative to costly real-world rollouts. The empirical numbers, the reproduction of failure modes for diagnostics, and the use of complementary consistency objectives on an existing video model are strengths that could influence how video world models are applied in robotics.
major comments (1)
- [Abstract and §4–5] Abstract and §4–5 (Experiments): the central claim that the three consistency mechanisms suffice to keep long-horizon autoregressive rollouts physically plausible and to generalize to policies outside the training distribution is load-bearing for the 0.929 closed-loop Pearson correlation. The abstract asserts that forward-inverse training, cross-view inpainting, and test-time termination counteract drift and compounding errors, yet no quantitative support (trajectory-level physics violation rates, explicit OOD policy splits, or ablation isolating drift on held-out behaviors) is referenced; without such evidence the correlation could reflect in-distribution overlap rather than the claimed evaluator properties.
minor comments (2)
- [Abstract] The exact definition and computation of MMRV (reported as 0.119) is not stated in the abstract and should be given explicitly with its formula and relation to the Pearson metric.
- [§5] Details on policy selection, baseline hyper-parameter tuning, and whether the seven policies or the held-out real-world data were chosen after inspecting results should be added to §5 to allow assessment of post-hoc bias.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for acknowledging the potential contribution of SC3-Eval to scalable policy evaluation. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract and §4–5] Abstract and §4–5 (Experiments): the central claim that the three consistency mechanisms suffice to keep long-horizon autoregressive rollouts physically plausible and to generalize to policies outside the training distribution is load-bearing for the 0.929 closed-loop Pearson correlation. The abstract asserts that forward-inverse training, cross-view inpainting, and test-time termination counteract drift and compounding errors, yet no quantitative support (trajectory-level physics violation rates, explicit OOD policy splits, or ablation isolating drift on held-out behaviors) is referenced; without such evidence the correlation could reflect in-distribution overlap rather than the claimed evaluator properties.
Authors: We agree that the manuscript would be strengthened by explicit quantitative support such as trajectory-level physics violation rates, dedicated OOD policy splits, and an ablation isolating drift on held-out behaviors. The current evidence consists of the closed-loop Pearson correlation of 0.929 measured across seven real-world VLA policies (including generalization to new tasks) together with qualitative reproduction of real-world failure modes. While we believe these results are inconsistent with pure in-distribution overlap, we acknowledge they do not directly quantify per-trajectory physical plausibility or isolate each consistency term's effect on drift. In the revised manuscript we will add an ablation that measures the contribution of each consistency mechanism to rollout stability on held-out behaviors and will report any available quantitative proxies for physical violation derived from the inverse-dynamics consistency signal. revision: yes
Circularity Check
No circularity: empirical correlation against held-out real-world data
full rationale
The paper reports closed-loop Pearson correlation (0.929) and MMRV (0.119) computed directly against real-world rollouts of seven held-out vision-language-action policies. The training recipe (forward-inverse dynamics, cross-view inpainting, test-time termination) is described as a method to produce the evaluator, but the final metrics are external benchmarks that do not reduce by construction to any fitted parameter or self-citation chain within the paper. No equations, uniqueness theorems, or ansatzes are shown to force the reported numbers from the training data alone. The evaluation therefore remains self-contained against independent real-world measurements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
X. Yang, R. Dagli, A. Zook, H. Hadfield, A. Goyal, S. Birchfield, F. Ramos, and J. Tremblay. Robolab: A high-fidelity simulation benchmark for analysis of task generalist policies, 2026. URLhttps://arxiv.org/abs/2604.09860
Pith/arXiv arXiv 2026
-
[2]
A. Jain, M. Zhang, K. Arora, W. Chen, M. Torne, M. Z. Irshad, S. Zakharov, Y . Wang, S. Levine, C. Finn, W.-C. Ma, D. Shah, A. Gupta, and K. Pertsch. Polaris: Scalable real-to- sim evaluations for generalist robot policies, 2025. URLhttps://arxiv.org/abs/2512. 16881
2025
-
[3]
F. Zhu, H. Wu, S. Guo, Y . Liu, C. Cheang, and T. Kong. Irasim: A fine-grained world model for robot manipulation. InICCV, 2025. arXiv:2406.14540
arXiv 2025
-
[4]
J. Quevedo, A. K. Sharma, Y . Sun, V . Suryavanshi, P. Liang, and S. Yang. Worldgym: World model as an environment for policy evaluation.arXiv preprint arXiv:2506.00613, 2025. doi: 10.48550/arXiv.2506.00613. URLhttps://arxiv.org/abs/2506.00613
- [5]
-
[6]
Y . Guo, L. X. Shi, J. Chen, and C. Finn. Ctrl-world: A controllable generative world model for robot manipulation.arXiv preprint arXiv:2510.10125, 2025. URLhttps://arxiv.org/ abs/2510.10125
Pith/arXiv arXiv 2025
-
[7]
S. Li, Y . Gao, D. Sadigh, and S. Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025. URLhttps://arxiv.org/abs/2503.00200
Pith/arXiv arXiv 2025
-
[8]
C. Zhu, R. Yu, S. Feng, B. Burchfiel, P. Shah, and A. Gupta. Unified world models: Cou- pling video and action diffusion for pretraining on large robotic datasets.arXiv preprint arXiv:2504.02792, 2025. URLhttps://arxiv.org/abs/2504.02792
Pith/arXiv arXiv 2025
-
[9]
NVIDIA, A. Ali, J. Bai, M. Bala, Y . Balaji, A. Blakeman, T. Cai, J. Cao, T. Cao, E. Cha, Y .-W. Chao, P. Chattopadhyay, M. Chen, Y . Chen, Y . Chen, S. Cheng, Y . Cui, J. Diamond, Y . Ding, J. Fan, L. Fan, L. Feng, F. Ferroni, S. Fidler, X. Fu, R. Gao, Y . Ge, J. Gu, A. Gupta, S. Gururani, I. El Hanafi, A. Hassani, Z. Hao, J. Huffman, J. Jang, P. Jannaty...
Pith/arXiv arXiv 2025
-
[10]
Atreya, K
P. Atreya, K. Pertsch, T. Lee, M. J. Kim, A. Jain, A. Kuramshin, C. Eppner, C. Neary, E. Hu, F. Ramos, et al. Roboarena: Distributed real-world evaluation of generalist robot policies. In Proceedings of the Conference on Robot Learning (CoRL 2025), 2025
2025
-
[11]
X. Li, K. Hsu, J. Gu, K. Pertsch, O. Mees, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kir- mani, S. Levine, J. Wu, C. Finn, H. Su, Q. Vuong, and T. Xiao. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024
Pith/arXiv arXiv 2024
-
[12]
Evaluating gemini robotics policies in a veo world simulator.arXiv preprint arXiv:2512.10675, 2025
Gemini Robotics Team. Evaluating gemini robotics policies in a veo world simulator.arXiv preprint arXiv:2512.10675, 2025. URLhttps://arxiv.org/abs/2512.10675
arXiv 2025
-
[13]
Y . Li, Z. Zhou, Y . Chen, Y . Xue, and Y . Zhu. dworldeval: Scalable robotic policy evaluation via discrete diffusion world model.arXiv preprint arXiv:2604.22152, 2026. URLhttps: //arxiv.org/abs/2604.22152. 10
Pith/arXiv arXiv 2026
-
[14]
Y . Wang, R. Syed, F. Wu, M. Zhang, A. Onol, J. Barreiros, H. Nayyeri, T. Dear, H. Zhang, and Y . Li. Interactive world simulator for robot policy training and evaluation.arXiv preprint arXiv:2603.08546, 2026. URLhttps://arxiv.org/abs/2603.08546
arXiv 2026
-
[15]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, and J. Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning. In The Fourteenth International Conference on Learning Representations, 2026. URLhttps: //openreview.net/forum?id=wPEIStHxYH
2026
-
[16]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xi- ang, A. Malik, K. Lee, W. Liang, N. Ranawaka, J. Gu, Y . Xu, G. Wang, F. Hu, A. Narayan, J. Bjorck, J. Wang, G. Kim, D. Niu, R. Zheng, Y . Xie, J. Wu, Q. Wang, R. Julian, D. Xu, Y . Du, Y . Chebotar, S. Reed, J. Kautz, Y . Zhu, L. J. Fan, and J. Jang. World action m...
Pith/arXiv arXiv 2026
-
[17]
Y . Liu, F. Feng, L. Kong, W. Lu, J. Tang, K. Zhang, K. Murphy, C. Finn, and Y . Du. World action verifier: Self-improving world models via forward-inverse asymmetry.arXiv preprint arXiv:2604.01985, 2026. URLhttps://arxiv.org/abs/2604.01985
Pith/arXiv arXiv 2026
-
[18]
K. Chua, R. Calandra, R. McAllister, and S. Levine. Deep reinforcement learning in a handful of trials using probabilistic dynamics models. InAdvances in Neural Information Processing Systems (NeurIPS), 2018. URLhttps://arxiv.org/abs/1805.12114
Pith/arXiv arXiv 2018
-
[19]
Z. Mei, T. Yin, M. Baker, O. Shorinwa, and A. Majumdar. World models that know when they don’t know: Controllable video generation with calibrated uncertainty.arXiv preprint arXiv:2512.05927, 2025. URLhttps://arxiv.org/abs/2512.05927
arXiv 2025
-
[20]
Kidambi, A
R. Kidambi, A. Rajeswaran, P. Netrapalli, and T. Joachims. MOReL: Model-based offline reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[21]
URLhttps://arxiv.org/abs/2005.05951
arXiv 2005
-
[22]
T. Yu, G. Thomas, L. Yu, S. Ermon, J. Zou, S. Levine, C. Finn, and T. Ma. MOPO: Model- based offline policy optimization. InAdvances in Neural Information Processing Systems (NeurIPS), 2020. URLhttps://arxiv.org/abs/2005.13239
arXiv 2020
-
[23]
Cosmos 3: Omnimodal world models for physical ai.arXiv preprint arXiv:2606.02800, 2026
NVIDIA et al. Cosmos 3: Omnimodal world models for physical ai.arXiv preprint arXiv:2606.02800, 2026. URLhttps://arxiv.org/abs/2606.02800
Pith/arXiv arXiv 2026
-
[24]
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023. URL https://arxiv.org/abs/2210.02747
Pith/arXiv arXiv 2023
-
[25]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations (ICLR), 2023. URLhttps://arxiv.org/abs/2209.03003
Pith/arXiv arXiv 2023
-
[26]
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner...
Pith/arXiv arXiv 2025
-
[27]
Z. Xiao, Y . Lan, Y . Zhou, W. Ouyang, S. Yang, Y . Zeng, and X. Pan. Worldmem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025. 11 A Dataset and Evaluation Details The following appendices give the dataset, training, and ablation details that complement Sec. 4 of the main paper. Full rollout videos and additional q...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.