NeuralMUSIC: A Hybrid Neural-Subspace Framework for Robot Sound Source Localization
Pith reviewed 2026-06-30 11:27 UTC · model grok-4.3
The pith
A neural network that estimates the spatial covariance matrix can be inserted into the classical MUSIC pipeline to improve robot sound source localization robustness and generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
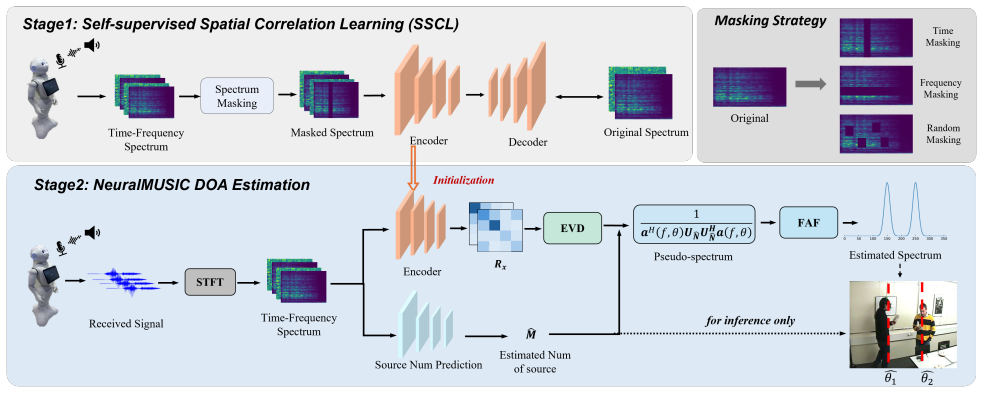
The authors claim that estimating the spatial covariance matrix via a neural network and integrating the prediction directly into the MUSIC eigenvalue decomposition and pseudo-spectrum computation, followed by frequency attention fusion, produces direction-of-arrival estimates with competitive accuracy, improved robustness under low signal-to-noise ratios, and stronger cross-domain generalization compared with standalone classical MUSIC or end-to-end neural methods.
What carries the argument
Neural estimation of the spatial covariance matrix, which is then processed through the classical MUSIC eigenvalue decomposition and pseudo-spectrum steps.
If this is right
- The hybrid retains the interpretability and theoretical guarantees of subspace methods while adding data-driven robustness.
- Self-supervised spatial correlation learning reduces the requirement for labeled training data in robotic audition tasks.
- Frequency attention fusion provides a mechanism to combine multi-frequency information without manual weighting.
- The approach can be applied to other array-processing pipelines that rely on accurate covariance estimates.
Where Pith is reading between the lines
- Similar neural-subspace hybrids could be tested on related tasks such as acoustic beamforming or source separation where covariance matrices are central.
- If the covariance estimate is sufficiently accurate, the method may allow deployment on robots with limited labeled acoustic recordings from the target environment.
- Real-world validation would require testing with moving sources and ego-noise typical of mobile robots rather than static array recordings.
Load-bearing premise
The neural network produces a spatial covariance matrix estimate that integrates effectively into the classical MUSIC pipeline without introducing errors that undermine the eigenvalue decomposition and pseudo-spectrum steps.
What would settle it
A controlled experiment in which the hybrid system is compared head-to-head with classical MUSIC on high-SNR, in-domain data; if the hybrid method shows higher localization error than classical MUSIC, the claim that the neural covariance estimate can be safely inserted without degradation would be falsified.
Figures







read the original abstract
Reliable sound source localization is fundamental to robot audition, enabling autonomous robots to perceive spatial cues and operate effectively in dynamic environments. Classical methods such as Multiple Signal Classification (MUSIC) offer strong theoretical foundations but degrade under low signal-to-noise ratios. While deep learning-based approaches achieve promising performance, they often struggle with limited generalization across conditions. To address these challenges, we propose NeuralMUSIC, a hybrid neural-subspace framework for robotic sound source localization. Specifically, a neural network first estimates the spatial covariance matrix from multichannel microphone observations. The predicted covariance is then integrated into a classical MUSIC pipeline with eigenvalue decomposition (EVD) and pseudo-spectrum computation, followed by a Frequency Attention Fusion (FAF) module to produce the final DOA estimates. To improve data efficiency, we further introduce a Self-supervised Spatial Correlation Learning (SSCL) strategy that leverages unlabeled acoustic data to capture spatial structure. Extensive experiments across different robotic tasks demonstrate that NeuralMUSIC achieves competitive localization accuracy while exhibiting improved robustness and cross-domain generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes NeuralMUSIC, a hybrid neural-subspace framework for robotic sound source localization. A neural network estimates the spatial covariance matrix from multichannel microphone observations; this estimate is fed into the classical MUSIC pipeline (eigenvalue decomposition and pseudo-spectrum computation), followed by a Frequency Attention Fusion module to yield direction-of-arrival estimates. A Self-supervised Spatial Correlation Learning strategy is introduced to improve data efficiency using unlabeled data. The central claim is that the method achieves competitive localization accuracy with improved robustness and cross-domain generalization across robotic tasks.
Significance. If the neural covariance estimate can be shown to preserve the algebraic properties required by MUSIC and the reported gains are reproducible, the hybrid approach would demonstrate a practical way to combine learned spatial priors with model-based subspace methods, addressing limitations of both pure classical and pure neural methods in low-SNR and domain-shift scenarios.
major comments (2)
- [§3.2] §3.2 (Neural Covariance Estimator): the architecture description provides no projection, regularization term, or loss component that enforces Hermitian symmetry (R = R^H) or positive semi-definiteness on the network output. Without such a constraint the subsequent EVD can produce complex eigenvalues or an ill-defined noise subspace, directly undermining the validity of the pseudo-spectrum step that the paper treats as unchanged classical MUSIC.
- [§4] §4 (Experiments) and Table 2: the reported localization errors and robustness claims rest on the assumption that the neural covariance integrates without degrading the subspace separation; no ablation isolating the effect of the raw neural estimate versus a projected Hermitian-PSD version is presented, leaving the load-bearing integration claim untested.
minor comments (2)
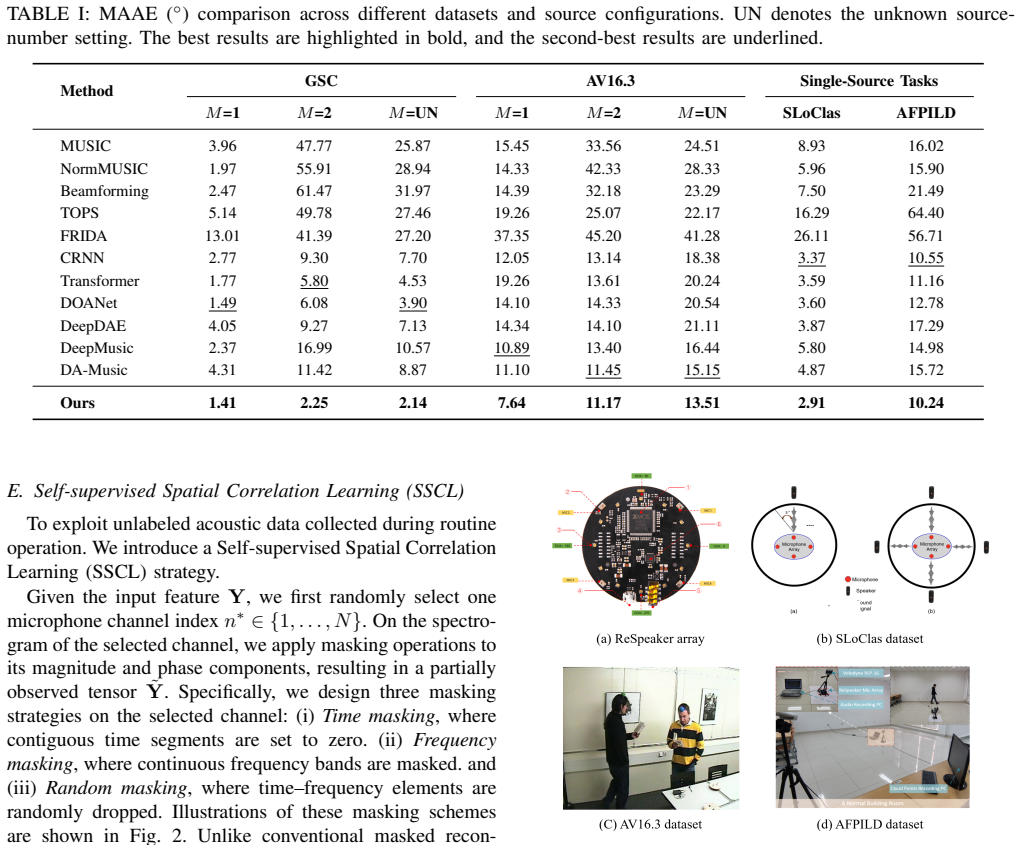
- [Abstract] Abstract: the claim of 'competitive localization accuracy' is stated without any numerical values or baseline comparisons, which weakens the ability of readers to assess the magnitude of the reported gains.
- [§3] Notation: the distinction between the sample covariance and the neural estimate is not consistently denoted (e.g., R vs. R̂), making it harder to follow which matrix enters the EVD at each step.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of ensuring the neural covariance estimate remains compatible with the classical MUSIC algorithm. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Neural Covariance Estimator): the architecture description provides no projection, regularization term, or loss component that enforces Hermitian symmetry (R = R^H) or positive semi-definiteness on the network output. Without such a constraint the subsequent EVD can produce complex eigenvalues or an ill-defined noise subspace, directly undermining the validity of the pseudo-spectrum step that the paper treats as unchanged classical MUSIC.
Authors: We agree that the submitted manuscript does not describe any explicit projection, regularization, or loss term to enforce Hermitian symmetry or positive semi-definiteness on the network output. Although the self-supervised training objective encourages estimates close to ground-truth covariances (which satisfy these properties), this does not guarantee algebraic validity at inference time. In the revised manuscript we will add a differentiable projection layer immediately after the network that symmetrizes the estimate and projects it onto the positive semi-definite cone before the EVD step. The revised §3.2 will document this projection and its computational cost. revision: yes
-
Referee: [§4] §4 (Experiments) and Table 2: the reported localization errors and robustness claims rest on the assumption that the neural covariance integrates without degrading the subspace separation; no ablation isolating the effect of the raw neural estimate versus a projected Hermitian-PSD version is presented, leaving the load-bearing integration claim untested.
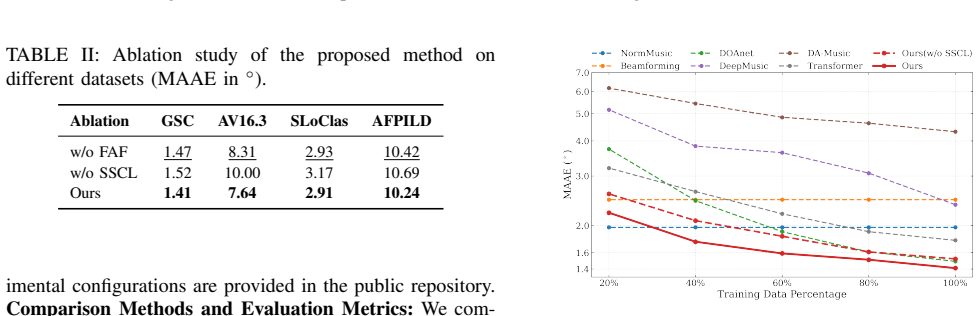
Authors: The referee correctly notes the absence of such an ablation. The current experiments evaluate the full pipeline but do not isolate the contribution of the raw neural estimate versus a version with enforced Hermitian-PSD properties. We will add this ablation study to the revised §4 and Table 2 (or a new supplementary table), reporting localization error, eigenvalue distribution statistics, and subspace separation metrics for both variants across the evaluated SNR and domain-shift conditions. revision: yes
Circularity Check
No circularity: hybrid pipeline keeps neural estimation and classical MUSIC independent
full rationale
The paper describes a neural network estimating the spatial covariance matrix from observations, which is then passed to the standard MUSIC EVD and pseudo-spectrum steps, plus a self-supervised SSCL strategy on unlabeled data. No equations or sections reduce the final DOA output to a fitted parameter or self-citation by construction; the classical subspace separation remains an external, non-learned computation. The architecture is presented as a data-driven front-end to an unchanged classical backend, with no evidence that the network output is forced to match quantities already implicit in MUSIC. This is the common case of a self-contained hybrid method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Self-supervised neural audio-visual sound source local- ization via probabilistic spatial modeling,
Y . Masuyama, Y . Bando, K. Yatabe, Y . Sasaki, M. Onishi, and Y . Oikawa, “Self-supervised neural audio-visual sound source local- ization via probabilistic spatial modeling,” in2020 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS), pp. 4848– 4854, IEEE, 2020
2020
-
[2]
Sound source localization for human-robot interaction in outdoor environments,
V . Liu, T. Du, J. Sehn, J. Collier, and F. Grondin, “Sound source localization for human-robot interaction in outdoor environments,” in 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 6121–6126, IEEE, 2025
2025
-
[3]
Av-pedaware: Self- supervised audio-visual fusion for dynamic pedestrian awareness,
Y . Yang, S. Yuan, M. Cao, J. Yang, and L. Xie, “Av-pedaware: Self- supervised audio-visual fusion for dynamic pedestrian awareness,” in 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 1871–1877, IEEE, 2023
2023
-
[4]
The un-kidnappable robot: Acoustic localization of sneaking people,
M. Yang, P. Grady, S. Brahmbhatt, A. B. Vasudevan, C. C. Kemp, and J. Hays, “The un-kidnappable robot: Acoustic localization of sneaking people,” in2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 985–992, IEEE, 2024
2024
-
[5]
Hearing what you cannot see: Acoustic vehicle detection around corners,
Y . Schulz, A. K. Mattar, T. M. Hehn, and J. F. Kooij, “Hearing what you cannot see: Acoustic vehicle detection around corners,”IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 2587–2594, 2021
2021
-
[6]
Continuous sound source localization based on microphone array for mobile robots,
H. Liu and M. Shen, “Continuous sound source localization based on microphone array for mobile robots,” in2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 4332–4339, IEEE, 2010
2010
-
[7]
Localization of simultaneous moving sound sources for mobile robot using a frequency-domain steered beamformer approach,
J.-M. Valin, F. Michaud, B. Hadjou, and J. Rouat, “Localization of simultaneous moving sound sources for mobile robot using a frequency-domain steered beamformer approach,” inIEEE Interna- tional Conference on Robotics and Automation, 2004. Proceedings. ICRA’04. 2004, vol. 1, pp. 1033–1038, IEEE, 2004
2004
-
[8]
Multiple emitter location and signal parameter estima- tion,
R. Schmidt, “Multiple emitter location and signal parameter estima- tion,”IEEE transactions on antennas and propagation, vol. 34, no. 3, pp. 276–280, 1986
1986
-
[9]
Doanet: a deep dilated convolutional neural network approach for search and rescue with drone-embedded sound source localization,
A. B. A. Qayyum, K. N. Hassan, A. Anika, M. F. Shadiq, M. M. Rahman, M. T. Islam, S. A. Imran, S. Hossain, and M. A. Haque, “Doanet: a deep dilated convolutional neural network approach for search and rescue with drone-embedded sound source localization,” EURASIP Journal on Audio, Speech, and Music Processing, vol. 2020, no. 1, p. 16, 2020
2020
-
[10]
Afpild: Acoustic footstep dataset collected using one microphone array and lidar sensor for person identification and localization,
S. Wu, S. Huang, Z. Liu, Q. Zhang, and J. Liu, “Afpild: Acoustic footstep dataset collected using one microphone array and lidar sensor for person identification and localization,”Information Fusion, vol. 104, p. 102181, 2024
2024
-
[11]
Unet- rootmusic: A high accuracy direction of arrival estimation method under array imperfection,
D.-T. Nguyen, T.-H. Le, V .-S. Doan, and V .-P. Hoang, “Unet- rootmusic: A high accuracy direction of arrival estimation method under array imperfection,”AEU-International Journal of Electronics and Communications, vol. 173, p. 155008, 2024
2024
-
[12]
Subspacenet: Deep learning-aided subspace methods for doa estimation,
D. H. Shmuel, J. P. Merkofer, G. Revach, R. J. Van Sloun, and N. Shlezinger, “Subspacenet: Deep learning-aided subspace methods for doa estimation,”IEEE Transactions on Vehicular Technology, 2024
2024
-
[13]
Da-music: Data-driven doa estimation via deep aug- mented music algorithm,
J. P. Merkofer, G. Revach, N. Shlezinger, T. Routtenberg, and R. J. Van Sloun, “Da-music: Data-driven doa estimation via deep aug- mented music algorithm,”IEEE Transactions on Vehicular Technology, vol. 73, no. 2, pp. 2771–2785, 2023
2023
-
[14]
Incoherent frequency fusion for broadband steered response power algorithms in noisy environ- ments,
D. Salvati, C. Drioli, and G. L. Foresti, “Incoherent frequency fusion for broadband steered response power algorithms in noisy environ- ments,”IEEE Signal Processing Letters, vol. 21, no. 5, pp. 581–585, 2014
2014
-
[15]
Coherent signal-subspace processing for the detection and estimation of angles of arrival of multiple wide- band sources,
H. Wang and M. Kaveh, “Coherent signal-subspace processing for the detection and estimation of angles of arrival of multiple wide- band sources,”IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 33, no. 4, pp. 823–831, 1985
1985
-
[16]
Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition
P. Warden, “Speech commands: A dataset for limited-vocabulary speech recognition. arxiv 2018,”arXiv preprint arXiv:1804.03209, 1804
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
Av16. 3: An audio- visual corpus for speaker localization and tracking,
G. Lathoud, J.-M. Odobez, and D. Gatica-Perez, “Av16. 3: An audio- visual corpus for speaker localization and tracking,” inInternational Workshop on Machine Learning for Multimodal Interaction, pp. 182– 195, Springer, 2004
2004
-
[18]
Sloclas: A database for joint sound localization and classification,
X. Qian, B. Sharma, A. El Abridi, and H. Li, “Sloclas: A database for joint sound localization and classification,” in2021 24th Conference of the Oriental COCOSDA International Committee for the Co- ordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA), pp. 128–133, IEEE, 2021
2021
-
[19]
Pyroomacoustics: A python package for audio room simulation and array processing algorithms,
R. Scheibler, E. Bezzam, and I. Dokmani ´c, “Pyroomacoustics: A python package for audio room simulation and array processing algorithms,” in2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp. 351–355, IEEE, 2018
2018
-
[20]
Tops: New doa esti- mator for wideband signals,
Y .-S. Yoon, L. M. Kaplan, and J. H. McClellan, “Tops: New doa esti- mator for wideband signals,”IEEE Transactions on Signal processing, vol. 54, no. 6, pp. 1977–1989, 2006
1977
-
[21]
Frida: Fri-based doa estimation for arbitrary array layouts,
H. Pan, R. Scheibler, E. Bezzam, I. Dokmani ´c, and M. Vetterli, “Frida: Fri-based doa estimation for arbitrary array layouts,” in2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 3186–3190, IEEE, 2017
2017
-
[22]
Deep neural networks for multiple speaker detection and localization,
W. He, P. Motlicek, and J.-M. Odobez, “Deep neural networks for multiple speaker detection and localization,” in2018 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pp. 74–79, IEEE, 2018
2018
-
[23]
Deepmusic: Multiple signal classification via deep learning,
A. M. Elbir, “Deepmusic: Multiple signal classification via deep learning,”IEEE Sensors Letters, vol. 4, no. 4, pp. 1–4, 2020
2020
-
[24]
Bast: Bin- aural audio spectrogram transformer for binaural sound localization,
S. Kuang, J. Shi, K. van der Heijden, and S. Mehrkanoon, “Bast: Bin- aural audio spectrogram transformer for binaural sound localization,” arXiv preprint arXiv:2207.03927, 2022
-
[25]
Multi- speaker tracking from an audio–visual sensing device,
X. Qian, A. Brutti, O. Lanz, M. Omologo, and A. Cavallaro, “Multi- speaker tracking from an audio–visual sensing device,”IEEE Trans- actions on Multimedia, vol. 21, no. 10, pp. 2576–2588, 2019
2019
-
[26]
Transmusic: A transformer- aided subspace method for doa estimation with low-resolution adcs,
J. Ji, W. Mao, F. Xi, and S. Chen, “Transmusic: A transformer- aided subspace method for doa estimation with low-resolution adcs,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 8576–8580, IEEE, 2024. APPENDIX A. Datasets and Experimental Setup Details In the experiments, we compare the performanc...
2024
-
[27]
The simulated environment consists of a7×7×3m room with a sampling rate of 16 kHz, and additive noise is added with a signal-to- noise ratio (SNR) of 30 dB
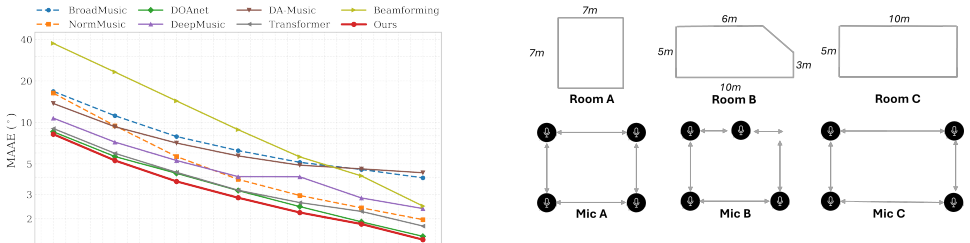
toolkit with the image-source method. The simulated environment consists of a7×7×3m room with a sampling rate of 16 kHz, and additive noise is added with a signal-to- noise ratio (SNR) of 30 dB. The sound source is randomly positioned around the microphone array with a distance ranging from 0.5 m to 2.0 m and an azimuth angle uniformly distributed between...
-
[28]
However, at this stage some information from the raw input may already be lost, as the estimation relies on the intermediate covariance representation
as an example, its source number estimation mod- ule is placed after the eigenvalue decomposition (EVD) stage. However, at this stage some information from the raw input may already be lost, as the estimation relies on the intermediate covariance representation. This may reduce the accuracy of source number estimation. In contrast, our method predicts the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.