Stealthy World Model Manipulation via Data Poisoning
Pith reviewed 2026-06-26 21:31 UTC · model grok-4.3
The pith
A two-stage data poisoning attack can manipulate learned world models to induce low-return planning while keeping changes close to clean data and evading non-adaptive defenses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SWAAP identifies a harmful target world model via first-order bilevel optimization enabled by a transition-gradient theorem, where the target induces low-return behavior under planning yet remains close to clean dynamics; it then realizes this target by modifying a limited fraction of fine-tuning transition targets through stealth-constrained gradient matching and a prediction-error regularizer so that the induced gradients steer the victim model toward the target while poisoned data stays close to the model's natural approximation error.
What carries the argument
SWAAP, the two-stage data poisoning framework that locates a harmful target world model through bilevel optimization and realizes it via gradient matching on limited transitions.
If this is right
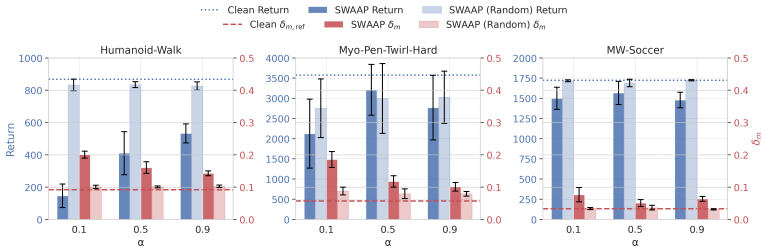
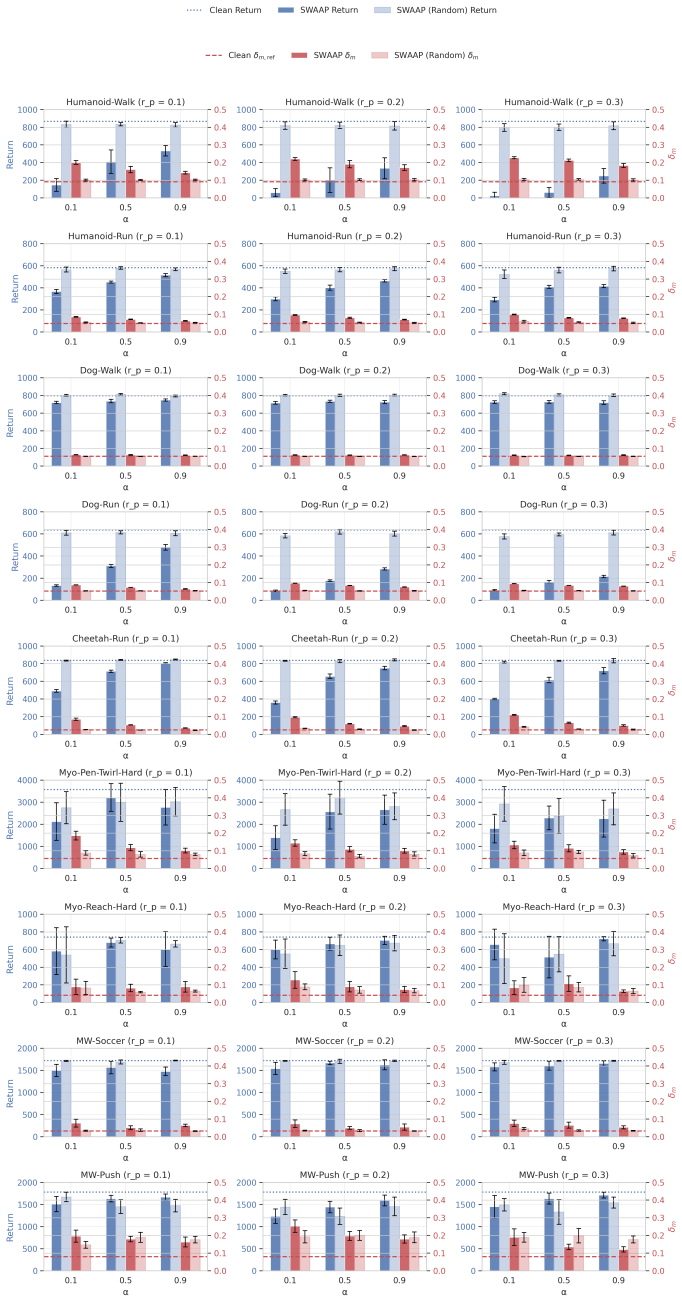
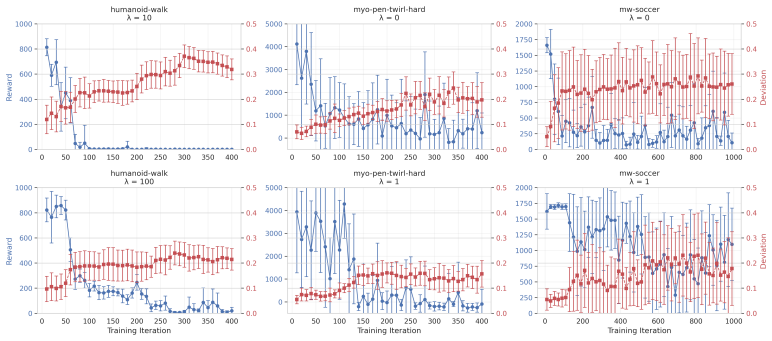
- Substantial performance degradation occurs across diverse continuous-control tasks.
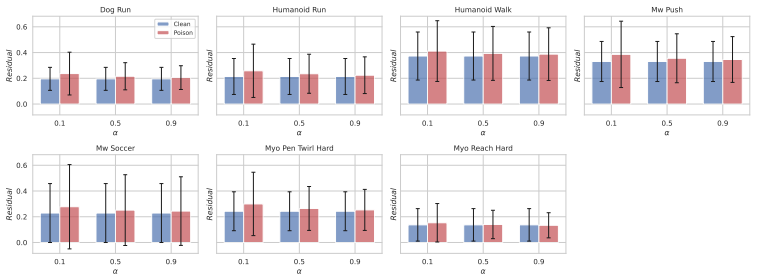
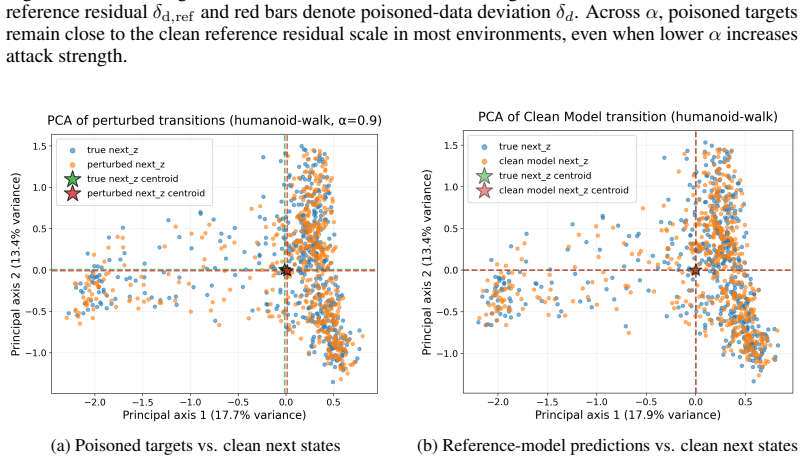
- Poisoned transitions remain close to clean data.
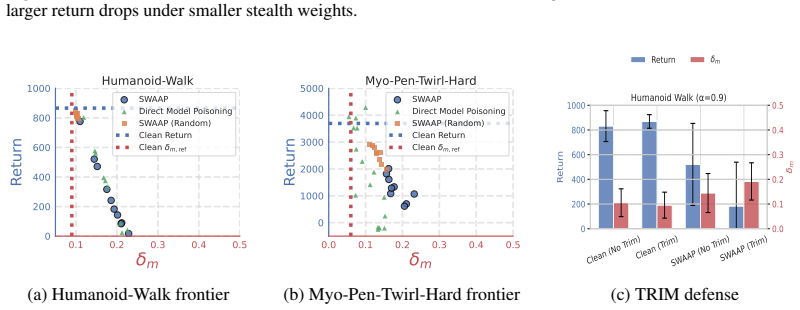
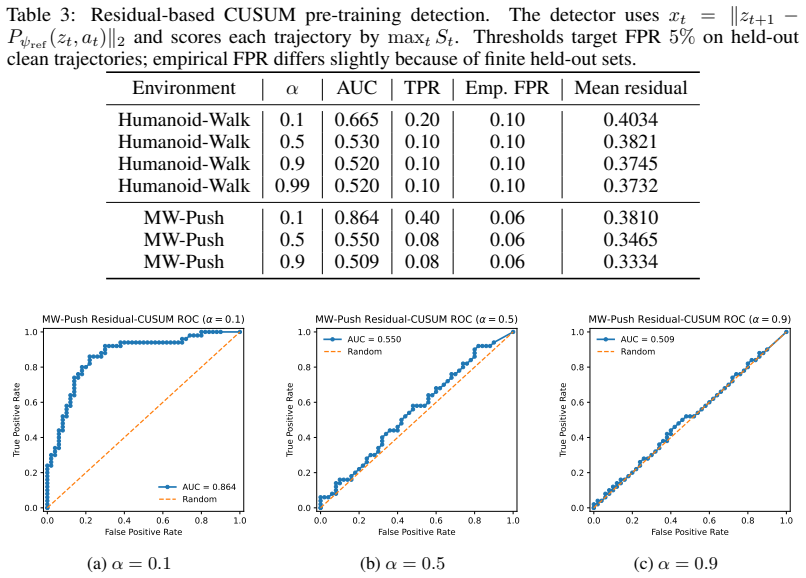
- Evaluated non-adaptive residual, CUSUM, and TRIM-style defenses are evaded at pre-training, fine-tuning, and test-time stages.
- This reveals a practical vulnerability in world-model adaptation pipelines.
- Robustness methods are needed to protect both world-model training data and learned dynamics.
Where Pith is reading between the lines
- Defenses would need to consider bilevel optimization when screening for harmful targets rather than only statistical residuals.
- The attack surface may extend to other online adaptation loops where agents collect their own fine-tuning data.
- Test-time monitoring of dynamics might require additional checks beyond prediction-error thresholds to catch induced low-return behavior.
- Practitioners adapting models in deployed systems may need controlled data collection or verification steps to limit poisoning risk.
Load-bearing premise
The transition-gradient theorem enables first-order bilevel optimization to identify a harmful target world model close to clean dynamics yet inducing low-return behavior under planning.
What would settle it
An experiment in which the bilevel optimization yields no target model that is simultaneously close to clean dynamics and low-return under planning, or in which gradient matching on a limited fraction of transitions fails to steer the victim model without larger deviations or detection.
Figures
read the original abstract
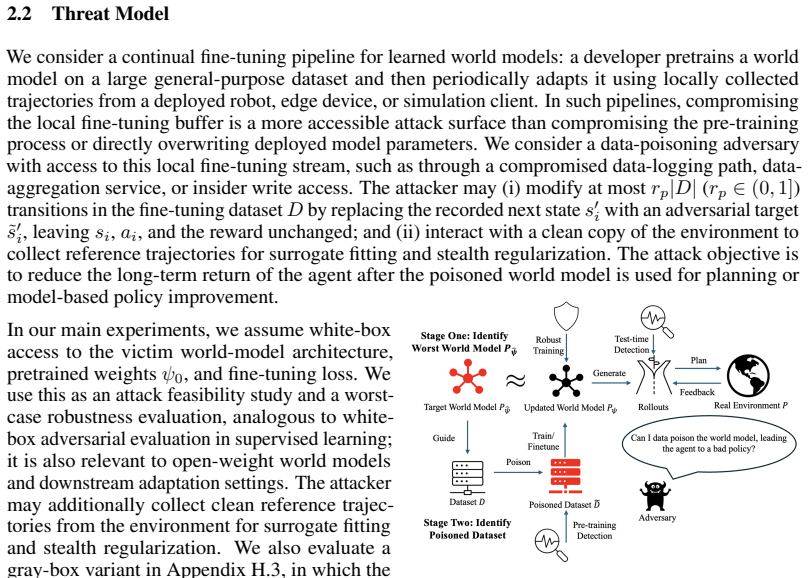
Model-based learning agents use learned world models to predict future states, plan actions, and adapt to new environments. However, the process of updating world models from collected experience creates a training-time attack surface: adversarially poisoned fine-tuning trajectories can manipulate the learned dynamics and thereby corrupt downstream planning. In this paper, we propose SWAAP, the first two-stage data poisoning framework for learned world models. In the first stage, SWAAP identifies a harmful target world model that induces low-return behavior under planning while remaining close to clean dynamics, using first-order bilevel optimization enabled by a transition-gradient theorem. In the second stage, SWAAP realizes this target through stealth-constrained gradient matching, modifying only a limited fraction of fine-tuning transition targets so that the induced training gradients steer the victim model toward the adversarial target, while a prediction-error regularizer encourages the poisoned targets to remain close to the world model's natural approximation error. To assess attack stealthiness, we evaluate defenses and detectability across three stages of the poisoning pipeline: pre-training detection of poisoned transitions, robust training during fine-tuning, and test-time monitoring of the resulting world model. Across diverse continuous-control tasks, SWAAP causes substantial performance degradation while keeping poisoned transitions close to clean data and evading the evaluated non-adaptive residual/CUSUM/TRIM-style defenses. These results reveal a practical vulnerability in world-model adaptation pipelines and highlight the need for robustness methods that protect both world-model training data and learned dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SWAAP, a two-stage data poisoning attack on learned world models for model-based RL agents. Stage 1 identifies a harmful target world model (close to clean dynamics yet inducing low-return planning) via first-order bilevel optimization enabled by a transition-gradient theorem. Stage 2 realizes the target by poisoning a limited fraction of fine-tuning transitions through stealth-constrained gradient matching plus a prediction-error regularizer. Across continuous-control tasks, the attack is claimed to cause substantial performance degradation while evading non-adaptive residual/CUSUM/TRIM defenses and keeping poisoned transitions close to clean data.
Significance. If the transition-gradient theorem holds and the experimental results are reproducible, the work identifies a practical attack surface in world-model fine-tuning pipelines. The bilevel optimization plus gradient-matching construction is a novel contribution to poisoning attacks on dynamics models, and the multi-stage stealth evaluation (pre-training detection, robust training, test-time monitoring) strengthens the claim of practicality. This could motivate new defenses focused on both data and learned dynamics.
major comments (1)
- [Transition-gradient theorem (abstract and derivation section)] The transition-gradient theorem is load-bearing for Stage 1: the abstract states that it enables first-order bilevel optimization to produce a target model that is simultaneously close to clean dynamics and harmful under planning. No derivation, assumptions, or empirical verification that the resulting targets satisfy both conditions is provided, so the two-stage attack cannot be realized if the theorem does not hold in the claimed form.
minor comments (2)
- [Abstract] The abstract asserts 'substantial performance degradation' and 'evading the evaluated defenses' but reports no quantitative metrics, poisoning fractions, error bars, or specific task results; these numbers belong in the results section or abstract.
- Notation for the bilevel objective, the gradient-matching loss, and the prediction-error regularizer should be introduced with explicit equations early in the method section for clarity.
Simulated Author's Rebuttal
We thank the referee for their detailed review and for highlighting the importance of the transition-gradient theorem. We agree that its derivation, assumptions, and verification are essential for the two-stage attack and will strengthen the manuscript by including them.
read point-by-point responses
-
Referee: [Transition-gradient theorem (abstract and derivation section)] The transition-gradient theorem is load-bearing for Stage 1: the abstract states that it enables first-order bilevel optimization to produce a target model that is simultaneously close to clean dynamics and harmful under planning. No derivation, assumptions, or empirical verification that the resulting targets satisfy both conditions is provided, so the two-stage attack cannot be realized if the theorem does not hold in the claimed form.
Authors: We agree that the transition-gradient theorem requires explicit support. The current manuscript states the theorem but omits the full derivation for space reasons. In the revision we will add: (i) the complete proof with all assumptions (differentiability of the planning objective w.r.t. dynamics parameters, Lipschitz continuity of the transition function, and bounded planning horizon), (ii) a dedicated subsection deriving the first-order bilevel gradient, and (iii) empirical verification on the evaluated environments showing that the bilevel-optimized targets remain within a small L2 distance of the clean model while producing substantially lower returns under the planner. These additions will confirm that the Stage-1 targets satisfy both closeness and harmfulness conditions, making the two-stage attack realizable. revision: yes
Circularity Check
No circularity: attack defined via procedural optimization, not by construction or self-citation reduction
full rationale
The paper defines SWAAP as a two-stage procedural attack: stage 1 uses first-order bilevel optimization (enabled by a transition-gradient theorem) to identify a target model, and stage 2 uses gradient matching with a regularizer. No step renames a fitted parameter as a prediction, imports uniqueness via self-citation, or reduces the central result to its own inputs by definition. The transition-gradient theorem is invoked as an enabler for the optimization procedure rather than a self-referential result; empirical evaluations on continuous-control tasks provide independent falsifiability. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- poisoning fraction
- prediction-error regularizer weight
axioms (1)
- domain assumption A transition-gradient theorem exists that enables first-order bilevel optimization over world-model parameters.
Reference graph
Works this paper leans on
- [1]
-
[2]
URL https://arxiv.org/abs/2009.02276. Saeed Ghadimi and Mengdi Wang. Approximation methods for bilevel programming.arXiv preprint arXiv:1802.02246,
-
[3]
URL https: //arxiv.org/abs/2302.04659. David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122,
-
[4]
Mastering Diverse Domains through World Models
URLhttps://arxiv.org/abs/2301.04104. Nicklas Hansen, Hao Su, and Xiaolong Wang. TD-MPC2: Scalable, robust world models for continuous control. InInternational Conference on Learning Representations (ICLR),
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Matthew MacKay, Paul Vicol, Jon Lorraine, David Duvenaud, and Roger Grosse. Self-tuning networks: Bilevel optimization of hyperparameters using structured best-response functions.arXiv preprint arXiv:1903.03088,
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[6]
Cosmos World Foundation Model Platform for Physical AI
Nvidia. Cosmos world foundation model platform for Physical AI. https://arxiv.org/abs/ 2501.03575, 2025a. Nvidia. World foundation models. https://www.nvidia.com/en-us/glossary/ world-models/, 2025b. OpenAI. Creating video from text.https://openai.com/index/sora/,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. Deepmind control suite.arXiv preprint arXiv:1801.00690,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning
URLhttps://arxiv.org/abs/2411.04983. 13 Appendix Table of Contents A Use of LLMs 16 B Broader Impact 16 C Related Works 16 C.1 World Models . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 C.2 Model-Based Reinforcement Learning . . . . . . . . . . . . . . . . . . . . . . . . 17 C.3 Model Poisoning Attack . . . . . . . . . . . ....
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
Therefore, ∇ψJ(P ψ, π) = X s dπ(s) X a π(a|s) X s′ ∇ψPψ(s′|s, a)(R(s, a, s′) +γV(s ′)) =E (s,a,r,s′)∼Pψ,π[(R(s, a, s′) +γV(s ′))∇ψ logP ψ(s′|s, a)]
= P s′ ρπ(s→s ′, k)ρπ(s′ →x,1) is used to write the transition gradient into recursive form. Therefore, ∇ψJ(P ψ, π) = X s dπ(s) X a π(a|s) X s′ ∇ψPψ(s′|s, a)(R(s, a, s′) +γV(s ′)) =E (s,a,r,s′)∼Pψ,π[(R(s, a, s′) +γV(s ′))∇ψ logP ψ(s′|s, a)]. For planning with a finite horizon T , given a time-indexed value function Vt(st) with terminal value VT (sT ) = 0,...
2013
-
[10]
Other parameters are the same as stated in TD-MPC2 [Hansen et al., 2024]. 22 Table 2: Key hyperparameters used in experiments; other parameters are the same as in TD-MPC2 Hyperparameter Typical value(s) Description Model Poisoning Hyperparameters obs_dim 17-223 The range of observation dimensions for tasks action_dim 6-39 The range of action dimensions fo...
2024
-
[11]
perturbing a fraction of state-action pairs
Stage 1 optimizes the parameters of a global neural world model, so changing ˆψ can in principle affect predictions beyond any selected subset of inputs. In this ablation, 30 Table 7: Attack performance with different data poison ratio (rp) in Stage 2 in Humanoid-Walk with α= 0.9 rp Return δm clean 866 ± 57 0.09 ± 0.05 0.01 844 ± 94 0.10 ± 0.05 0.05 739 ±...
2022
-
[12]
For Obj-Hold-Hard, Key-Turn, and Coffee-Pull, we set α= 0.9 , while for Pose and Door-Open, we use α= 0.1
All experiments use rp = 0.1 and are evaluated over 100 episodes. For Obj-Hold-Hard, Key-Turn, and Coffee-Pull, we set α= 0.9 , while for Pose and Door-Open, we use α= 0.1 . These results further confirm that SWAAP reliably reduces the return while keeping the poisoned world model close to the clean model, consistent with our main findings. H.2 DINO-WM Pu...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.