Adaptive Speech-to-Spike Encoding for Spiking Neural Networks
Pith reviewed 2026-06-26 18:27 UTC · model grok-4.3
The pith
A learnable speech-to-spike encoder trained end-to-end with spiking networks reaches 94.97% accuracy on voice commands while remaining parameter-efficient.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A learnable residual speech-to-spike encoder jointly trained with an R-LIF backbone produces task-aligned spike representations that enhance class separability, enabling up to 94.97% accuracy on GSC-v2; a 35k-parameter encoder variant reaches 89.8% while direct feedback alignment reaches 91.5%.
What carries the argument
The learnable residual speech-to-spike encoder jointly trained end-to-end with the recurrent leaky integrate-and-fire backbone.
If this is right
- The 35k-parameter encoder variant reaches 89.8% accuracy on GSC-v2, matching or exceeding baselines that use an order of magnitude more parameters.
- The encoder produces spike representations that improve class separability rather than aiming for signal reconstruction.
- Direct feedback alignment achieves 91.5% accuracy under the same architecture and training conditions as surrogate-gradient BPTT.
- End-to-end training of the encoder with the SNN removes the need for hand-designed spike conversion steps.
Where Pith is reading between the lines
- Similar adaptive encoders could be tested on other event-based sensory streams such as vision or tactile data to check whether task-alignment benefits generalize beyond audio.
- The reported parameter efficiency suggests that neuromorphic hardware designs could allocate fewer resources to the front-end conversion stage.
- If the task-aligned property holds, replacing the encoder after training with a lighter distilled version might preserve accuracy at even lower cost.
Load-bearing premise
That linear probing and gradient-residual inspection on the trained encoder are sufficient to show it learns task-aligned representations rather than signal reconstruction, and that this drives the accuracy gains.
What would settle it
Training the identical R-LIF backbone with a fixed non-learnable encoder of the same parameter count and measuring whether accuracy falls to or below the 89.8% level of the compact learned encoder.
Figures
read the original abstract
The mismatch between continuous acoustic signals and discrete event-driven processing remains a fundamental bottleneck for neuromorphic speech processing. Current systems typically rely on fixed spike encoders, forcing downstream Spiking Neural Networks (SNNs) to compensate for non-adaptive input representations. To address this, we present a learnable residual speech-to-spike encoder jointly trained end-to-end with a Recurrent Leaky Integrate-and-Fire (R-LIF) backbone. We validate this approach on the Google Speech Commands v2 (GSC-v2) benchmark, achieving up to 94.97% accuracy. Notably, the learned encoder remains highly parameter-efficient with a compact 35k-parameter variant that reaches 89.8%, matching or exceeding prior baselines that require an order of magnitude more parameters. Our encoder-focused analysis, including linear probing and gradient-residual inspection, indicates that the encoder does not target faithful signal reconstruction but instead learns task-aligned spike representations that enhance class separability. Finally, we benchmark bio-inspired, hardware-friendly credit assignment by comparing Direct Feedback Alignment (DFA) with surrogate-gradient BPTT under identical architectures and training conditions. We find that DFA reaches 91.5% accuracy, quantifying the performance trade-off of bio-inspired learning rules for modern neuromorphic audio.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a learnable residual speech-to-spike encoder jointly trained end-to-end with a Recurrent Leaky Integrate-and-Fire (R-LIF) backbone for spiking neural networks. On the Google Speech Commands v2 benchmark it reports peak accuracy of 94.97% and a compact 35k-parameter encoder variant reaching 89.8%, claimed to match or exceed prior baselines using far more parameters. Linear probing and gradient-residual inspection are presented as evidence that the encoder learns task-aligned spike representations that enhance class separability rather than performing faithful signal reconstruction. The work also compares Direct Feedback Alignment (DFA) to surrogate-gradient BPTT under identical conditions, with DFA achieving 91.5%.
Significance. If the empirical results and the task-alignment interpretation hold after additional controls, the work would offer a parameter-efficient, adaptive front-end for neuromorphic speech processing that improves downstream SNN performance without relying on reconstruction objectives. The side-by-side DFA versus BPTT comparison under matched architectures supplies a concrete data point on the performance cost of bio-inspired credit assignment for audio tasks.
major comments (2)
- [Abstract] Abstract: the central claim that the encoder 'learns task-aligned spike representations that enhance class separability' (rather than reconstruction) rests on linear probing and gradient-residual inspection, yet these post-hoc diagnostics are correlational and do not isolate alignment as the causal driver of the reported accuracy gains; no ablation comparing the learned encoder against a fixed encoder, a reconstruction-loss encoder, or an end-to-end trained but non-adaptive baseline is described.
- [Abstract] Abstract: benchmark figures (94.97%, 89.8% for the 35k-parameter variant, 91.5% for DFA) are stated without error bars, statistical tests, training hyperparameters, network diagrams, or reproducibility details, which directly affects evaluation of whether the parameter-efficiency and accuracy claims are robust.
minor comments (1)
- The manuscript would benefit from an explicit statement of the residual encoder architecture (layer counts, kernel sizes, spike-generation mechanism) and from example spike raster plots to illustrate the claimed task-aligned output.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract claims and reproducibility. We address each major comment below and will revise the manuscript to strengthen the presentation where the points are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the encoder 'learns task-aligned spike representations that enhance class separability' (rather than reconstruction) rests on linear probing and gradient-residual inspection, yet these post-hoc diagnostics are correlational and do not isolate alignment as the causal driver of the reported accuracy gains; no ablation comparing the learned encoder against a fixed encoder, a reconstruction-loss encoder, or an end-to-end trained but non-adaptive baseline is described.
Authors: We agree that linear probing and gradient-residual inspection provide correlational rather than causal evidence, and that the manuscript does not describe the requested ablations. The current analyses show that the spike codes support high linear-probe accuracy on the downstream task and that back-propagated gradients align with class boundaries rather than reconstruction error, but these do not rule out alternative explanations. In the revision we will add a dedicated ablation subsection comparing (i) the jointly trained encoder against a fixed (non-learnable) encoder, (ii) an encoder trained with an explicit reconstruction loss, and (iii) a non-adaptive end-to-end baseline, together with quantitative metrics of class separability. These experiments will be reported in the revised Section 4. revision: partial
-
Referee: [Abstract] Abstract: benchmark figures (94.97%, 89.8% for the 35k-parameter variant, 91.5% for DFA) are stated without error bars, statistical tests, training hyperparameters, network diagrams, or reproducibility details, which directly affects evaluation of whether the parameter-efficiency and accuracy claims are robust.
Authors: We concur that the absence of error bars, statistical tests, hyperparameter tables, diagrams, and reproducibility information limits assessment of robustness. The revised manuscript will report all accuracy figures as mean ± standard deviation over five independent random seeds, include paired t-tests or Wilcoxon tests against the strongest baselines, provide a complete hyperparameter table, add architecture diagrams for both the encoder and R-LIF backbone, and include a public code repository link with exact training scripts and random seeds. revision: yes
Circularity Check
No circularity: empirical benchmarks on public dataset with independent measurements
full rationale
The paper's core results consist of end-to-end training accuracies on the public GSC-v2 dataset (up to 94.97%, 89.8% for 35k-param variant) plus post-hoc analyses (linear probing, gradient-residual inspection). No equations, fitted parameters renamed as predictions, or self-citation chains reduce any reported accuracy or claim about task-alignment to a quantity defined inside the paper itself. The analysis methods are standard and falsifiable on held-out data; the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
However, mapping continuous-time auditory signals to discrete Spiking Neural Networks (SNNs) remains a fundamental chal- lenge
Introduction Neuromorphic computing offers a compelling paradigm for processing temporal signals at the extreme edge, promising high energy efficiency through sparse, event-driven processing. However, mapping continuous-time auditory signals to discrete Spiking Neural Networks (SNNs) remains a fundamental chal- lenge. Unlike the visual domain, where dynam...
2026
-
[2]
This yields up to 94.97% accuracy with an average encoder spike rate of 6.56%, enabling competitive performance at small model sizes down to 35k parameters
We introduce a learnable residual speech-to-spike encoder, jointly optimized with a recurrent LIF (R-LIF) backbone. This yields up to 94.97% accuracy with an average encoder spike rate of 6.56%, enabling competitive performance at small model sizes down to 35k parameters
-
[3]
We provide an encoder-side analysis using temporal probes and gradient statistics and demonstrate that the learnable en- coder does not aim to faithfully reconstruct the input log-mel spectrogram; instead, it constructs a task-aligned spike rep- resentation that significantly enhances the linear separability of classes compared to fixed baselines
-
[4]
Adaptive Speech-to-Spike Encoding for Spiking Neural Networks
We benchmark credit-assignment mechanisms by compar- ing surrogate-gradient BPTT with DFA. Under this compar- ison, DFA reaches 91.5% accuracy (vs. 94.97 for BPTT) for spiking keyword spotting on the GSC dataset, clarify- ing both the potential and current limitations of bio-inspired learning rules. The rest of the paper is organized as follows: Section 2...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
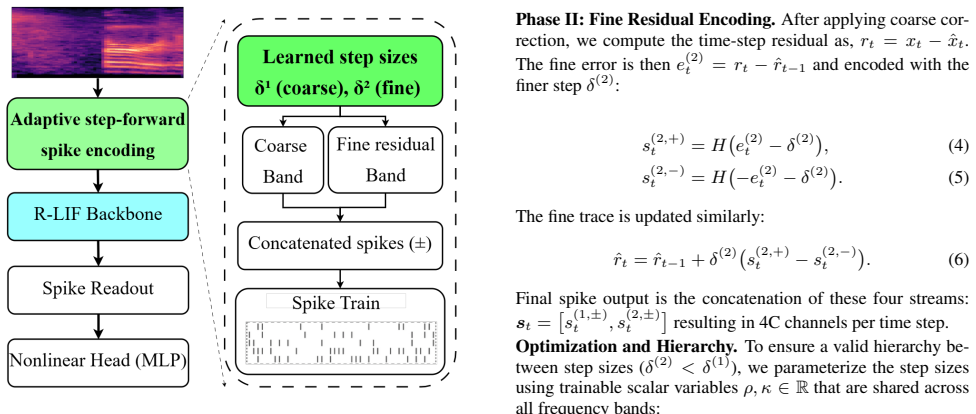
1, the proposed architecture integrates a differentiable speech-to-spike front end with a recurrent spik- ing classifier
Methods As illustrated in Fig. 1, the proposed architecture integrates a differentiable speech-to-spike front end with a recurrent spik- ing classifier. The pipeline processes an input log-mel spectro- gramX∈R C×T , wherex c,t denotes the log-mel magnitude at bandcand timet. At the encoder stage, the dense input is converted into a sparse binary spike ten...
-
[6]
Audio is sam- pled at 16 kHz
Experimental Setup We evaluate on the Google Speech Commands v2 (GSC-v2) dataset using the standard 35-class protocol [11]. Audio is sam- pled at 16 kHz. We extract 80-bin log-mel spectrograms using a 25 ms analysis window and a 10 ms hop, and apply log com- pression (log(1+x)) to the mel power spectrum before passing features to the spike encoder. The en...
-
[7]
Efficacy of Learnable Encoding We first isolate the contribution of the proposed encoder by comparing it against a fixed Step-Forward baseline under an identical R-LIF backbone
Results and Analysis 4.1. Efficacy of Learnable Encoding We first isolate the contribution of the proposed encoder by comparing it against a fixed Step-Forward baseline under an identical R-LIF backbone. As shown in Table 1, proposed learn- able encoder yields a substantial gain in test accuracy, improv- ing performance from 90.70% to 94.97%. This improve...
-
[8]
The proposed approach improves classification accuracy while reducing input spike activity in neuromorphic keyword spotting
Conclusion We introduce a learnable residual speech-to-spike encoder that replaces fixed Step-Forward thresholds with trainable coarse and fine step sizes and jointly optimized with an R-LIF back- bone. The proposed approach improves classification accuracy while reducing input spike activity in neuromorphic keyword spotting. We further provided a control...
-
[9]
The authors thank PI LLC (Sapporo, Hokkaido, Japan) for providing the GPU resources that sup- ported the experiments in this study
Acknowledgments Taharim Rahman Anon contributed to this work during her internship at PI LLC. The authors thank PI LLC (Sapporo, Hokkaido, Japan) for providing the GPU resources that sup- ported the experiments in this study
-
[10]
The specific assis- tance of AI tools includes editing and formatting equations into LaTeX, including grammar, spelling, and overall readability to ensure the textual consistency
Generative AI Use Disclosure In this paper, we have utilized ChatGPT (OpenAI: GPT-5.2) only to assist with minor editing and polishing of the manuscript after the core scientific content and main ideas of the work had been developed and written by the authors. The specific assis- tance of AI tools includes editing and formatting equations into LaTeX, incl...
-
[11]
A 128×128 120 db 15 µs latency asynchronous temporal contrast vision sensor,
P. Lichtsteiner, C. Posch, and T. Delbruck, “A 128×128 120 db 15 µs latency asynchronous temporal contrast vision sensor,”IEEE Journal of Solid-State Circuits, vol. 43, no. 2, pp. 566–576, Feb. 2008
2008
-
[12]
Deep convolutional spiking neural networks for keyword spot- ting,
E. Yılmaz, ¨O. B. Gevrek, J. Wu, Y . Chen, X. Meng, and H. Li, “Deep convolutional spiking neural networks for keyword spot- ting,” inInterspeech 2020, 2020, pp. 2557–2561
2020
-
[13]
Global-local convolution with spiking neural networks for energy-efficient keyword spotting,
M. Wang, H. Zhang, Y . Wang, X.-D. Zhang, C. Xu, Q. Wang, Z.- T. Li, J. Lv, Y . Wang, and Y . Tian, “Global-local convolution with spiking neural networks for energy-efficient keyword spotting,” in Interspeech 2024, 2024, pp. 4523–4527
2024
-
[14]
A surrogate gradient spik- ing baseline for speech command recognition,
A. Bittar and P. N. Garner, “A surrogate gradient spik- ing baseline for speech command recognition,”Frontiers in Neuroscience, vol. 16, p. 865897, 2022. [Online]. Avail- able: https://www.frontiersin.org/journals/neuroscience/articles/ 10.3389/fnins.2022.865897/full
-
[15]
A survey of encod- ing techniques for signal processing in spiking neural networks,
D. Auge, J. Hille, E. Mueller, and A. Knoll, “A survey of encod- ing techniques for signal processing in spiking neural networks,” Neural Processing Letters, vol. 53, 07 2021
2021
-
[16]
The remarkable robustness of surro- gate gradient learning for instilling complex function in spiking neural networks,
F. Zenke and T. P. V ogels, “The remarkable robustness of surro- gate gradient learning for instilling complex function in spiking neural networks,”Neural Computation, vol. 33, no. 4, pp. 899– 925, 2021
2021
-
[17]
The backpropagation algorithm implemented on spiking neuromorphic hardware,
A. F. M. V . Renner, F. C. Sheldon, A. V . Zlotnik, L. Tao, and A. T. Sornborger, “The backpropagation algorithm implemented on spiking neuromorphic hardware,”Nature Communications, vol. 15, no. 1, 11 2024. [Online]. Available: https://www.osti. gov/biblio/2476747
-
[18]
Direct feedback alignment provides learning in deep neural networks,
A. Nøkland, “Direct feedback alignment provides learning in deep neural networks,” inAdvances in Neural Information Processing Systems, 2016, pp. 1037–1045. [Online]. Avail- able: https://proceedings.neurips.cc/paper files/paper/2016/file/ d490d7b4576290fa60eb31b5fc917ad1-Paper.pdf
2016
-
[19]
Random synaptic feedback weights support error backpropagation for deep learning,
T. P. Lillicrap, D. Cownden, D. B. Tweed, and C. J. Akerman, “Random synaptic feedback weights support error backpropagation for deep learning,”Nature Communications, vol. 7, p. 13276, 2016. [Online]. Available: https://www.nature. com/articles/ncomms13276
2016
-
[20]
Spike-train level direct feedback alignment: Sidestepping backpropagation for on- chip training of spiking neural nets,
J. Lee, R. Zhang, W. Zhang, Y . Liu, and P. Li, “Spike-train level direct feedback alignment: Sidestepping backpropagation for on- chip training of spiking neural nets,”Frontiers in Neuroscience, vol. 14, p. 143, 2020
2020
-
[21]
Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition
P. Warden, “Speech commands: A dataset for limited- vocabulary speech recognition,” 2018. [Online]. Available: https://arxiv.org/abs/1804.03209
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
AST: Audio Spectrogram Transformer,
Y . Gong, Y .-A. Chung, and J. R. Glass, “AST: Audio Spectrogram Transformer,” inInterspeech 2021, 2021, pp. 571–575
2021
-
[23]
Keyword transformer: A self-attention model for keyword spotting,
A. Berg, M. O’Connor, and M. T. Cruz, “Keyword transformer: A self-attention model for keyword spotting,” inInterspeech 2021, 2021, pp. 4249–4253
2021
-
[24]
Surrogate gradient learn- ing in spiking neural networks: Bringing the power of gradient- based optimization to spiking neural networks,
E. O. Neftci, H. Mostafa, and F. Zenke, “Surrogate gradient learn- ing in spiking neural networks: Bringing the power of gradient- based optimization to spiking neural networks,”IEEE Signal Pro- cessing Magazine, vol. 36, no. 6, pp. 51–63, 2019
2019
-
[25]
Decoupled weight de- cay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight de- cay regularization,” inInternational Conference on Learn- ing Representations, 2019. [Online]. Available: https: //openreview.net/forum?id=Bkg6RiCqY7
2019
-
[26]
Speech2spikes: Efficient au- dio encoding pipeline for real-time neuromorphic processors,
M. Stewart, K. Cygnar, T. Hamilton, F. Leduc-Primeau, K. Thi- bodeau, C. Thakur, and E. Sparks, “Speech2spikes: Efficient au- dio encoding pipeline for real-time neuromorphic processors,” inNeuro-Inspired Computational Elements Conference (NICE 2023). New York, NY , USA: Association for Computing Ma- chinery, 2023, pp. 1–6
2023
-
[27]
SIDC-KWS: Efficient Spiking Inception-Dilated Conformer with Self-Attention for Keyword Spotting,
J. G. Lim and S. E. Kim, “SIDC-KWS: Efficient Spiking Inception-Dilated Conformer with Self-Attention for Keyword Spotting,” inInterspeech 2025, 2025, pp. 2665–2669
2025
-
[28]
ED-sKWS: Early-Decision Spiking Neural Networks for Rapid, and Energy- Efficient Keyword Spotting,
Z. Song, Q. Liu, Q. Yang, Y . Peng, and H. Li, “ED-sKWS: Early-Decision Spiking Neural Networks for Rapid, and Energy- Efficient Keyword Spotting,” inProc. Interspeech 2024, 2024, pp. 4528–4532. [Online]. Available: https://www.isca-archive. org/interspeech 2024/song24c interspeech.html
2024
-
[29]
Learning delays in spiking neural networks using dilated convolutions with learnable spacings,
I. Hammouamri, I. Khalfaoui Hassani, and T. Masque- lier, “Learning delays in spiking neural networks using dilated convolutions with learnable spacings,” inInter- national Conference on Representation Learning (ICLR), B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, Eds., 2024, pp. 17 890–17 903. [Online]. Available: https://proceedin...
2024
-
[30]
Optimizing the energy consumption of spiking neural networks for neuromorphic applications,
M. Sorbaro, Q. Liu, M. Bortone, and S. Sheik, “Optimizing the energy consumption of spiking neural networks for neuromorphic applications,”Frontiers in Neuroscience, vol. V olume 14 - 2020,
2020
-
[31]
Available: https://www.frontiersin.org/journals/ neuroscience/articles/10.3389/fnins.2020.00662
[Online]. Available: https://www.frontiersin.org/journals/ neuroscience/articles/10.3389/fnins.2020.00662
-
[32]
1.1 computing’s energy problem (and what we can do about it),
M. Horowitz, “1.1 computing’s energy problem (and what we can do about it),” in2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), 2014, pp. 10–14
2014
-
[33]
Training spiking neural networks via aug- mented direct feedback alignment,
Y . Zhang, K. Inoue, M. Nakajima, T. Hashimoto, Y . Kuniyoshi, and K. Nakajima, “Training spiking neural networks via aug- mented direct feedback alignment,”arXiv preprint, 09 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.