Secure Coding Drift in LLM-Assisted Post-Quantum Cryptography Development: A Gamified Fix
Pith reviewed 2026-06-26 20:11 UTC · model grok-4.3
The pith
Sustained reliance on LLM-generated code causes gradual erosion of secure coding practices in post-quantum cryptography.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Secure Coding Drift in PQC is a socio-technical vulnerability model that captures the gradual degradation of secure coding practices due to sustained reliance on LLM-generated code, conceptualized as a longitudinal behavioural phenomenon arising from human-AI interaction; this is addressed by a gamified, LLM-augmented secure coding framework that embeds adversarial evaluation, behavioural feedback, and security scoring.
What carries the argument
Secure Coding Drift in PQC, the socio-technical model that reframes security risk as time-dependent behavioral degradation in LLM-assisted cryptographic development.
If this is right
- PQC libraries will accumulate more timing and side-channel weaknesses as developer dependence on LLMs increases without corrective mechanisms.
- The gamified framework can convert LLMs from sources of drift into sources of real-time security feedback within existing development tools.
- Behavioral scoring and adversarial evaluation become necessary components of any LLM-assisted cryptographic engineering workflow.
- Constant-time and side-channel requirements in PQC can be maintained through repeated, gamified reinforcement rather than one-time code review.
Where Pith is reading between the lines
- The same drift dynamic may appear in other security-critical codebases, such as hardware security modules or zero-knowledge proof implementations.
- Controlled experiments could measure drift by logging security metric changes in developer teams before and after introducing the gamified co-pilot.
- The framework's scoring system might be extended to non-cryptographic high-assurance domains to test whether gamification generalizes beyond PQC.
Load-bearing premise
Security risk in this setting is best captured as a longitudinal behavioral phenomenon produced by repeated human-AI interaction rather than as static vulnerabilities in individual code snippets.
What would settle it
A longitudinal study that tracks secure-coding compliance metrics in PQC projects over several months and finds no measurable decline in teams that rely on LLMs without the proposed gamified interventions.
Figures

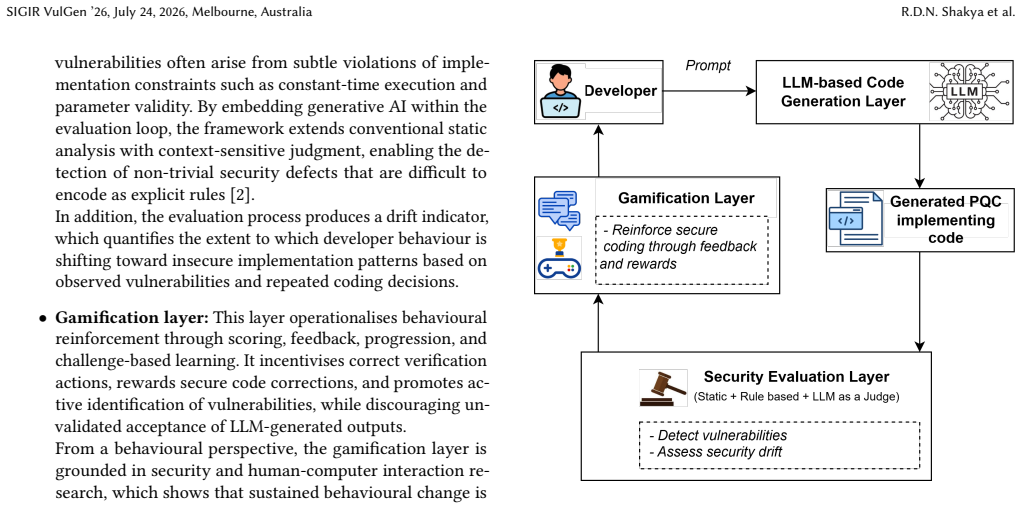
read the original abstract
The transition to Post Quantum Cryptography (PQC) introduces considerable implementation complexity, requiring strict adherence to constant-time execution, side channel resistance, and precise parametrisation. Simultaneously, large language models (LLMs) are heavily embedded in software development workflows, including cryptographic engineering. While LLMs improve productivity, evidence shows that they frequently generate insecure or suboptimal code, particularly in security critical domains. This paper introduces Secure Coding Drift in PQC, a novel socio technical vulnerability model capturing the gradual degradation of secure coding practices due to sustained reliance on LLM-generated code. Unlike prior work that focuses on static vulnerabilities, we conceptualise security risk as a longitudinal behavioural phenomenon rising from human AI interaction. To mitigate this, we propose a gamified, LLM augmented secure coding framework that embeds adversarial evaluation, behavioural feedback, and security scoring into development workflows. Our approach reframes LLMs from passive assistants into active security co-pilots, contributing toward safer PQC implementation in AI mediated environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'Secure Coding Drift' as a novel socio-technical vulnerability model for post-quantum cryptography (PQC) development under sustained LLM assistance. It frames security risk as a longitudinal behavioral phenomenon arising from human-AI interaction (rather than static code flaws) and proposes a gamified LLM-augmented framework that incorporates adversarial evaluation, behavioral feedback, and security scoring to reframe LLMs as active security co-pilots.
Significance. The intersection of LLM code generation and PQC implementation security is timely. If the model were equipped with operational definitions, measurable indicators, and validation data, it could inform workflow interventions in cryptographic engineering. No such elements are present; the manuscript offers only narrative framing with no equations, variables, data sources, pilot measurements, or falsifiable predictions.
major comments (2)
- [Abstract] Abstract, paragraph 3: The central claim that security risk 'can be modelled as a longitudinal behavioural phenomenon' is asserted without any observable indicators (e.g., temporal change in constant-time violations, side-channel leakage, or parameter errors across code iterations), any method to distinguish drift from documented static LLM flaws, or any external benchmark.
- [Abstract] Abstract: The gamified framework is described only at a high level ('embeds adversarial evaluation, behavioural feedback, and security scoring') with no evaluation criteria, metrics, or pilot study design, rendering the proposed mitigation untestable.
Simulated Author's Rebuttal
We thank the referee for the detailed and timely review of our manuscript. The work is positioned as a conceptual contribution that introduces the Secure Coding Drift model and outlines a high-level mitigation framework. We address the major comments below by clarifying the paper's scope while acknowledging where additional exposition would strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph 3: The central claim that security risk 'can be modelled as a longitudinal behavioural phenomenon' is asserted without any observable indicators (e.g., temporal change in constant-time violations, side-channel leakage, or parameter errors across code iterations), any method to distinguish drift from documented static LLM flaws, or any external benchmark.
Authors: The manuscript frames Secure Coding Drift as a socio-technical model that shifts focus from isolated code defects to cumulative behavioral changes arising from repeated human-LLM interaction in PQC workflows. We agree that no quantitative indicators, differentiation methods, or benchmarks are supplied; the paper does not claim to deliver an operationalized or validated model. We will revise the abstract and add a short section explicitly stating the conceptual nature of the contribution and listing candidate indicators (such as iteration-wise increases in non-constant-time patterns) that could be measured in subsequent empirical studies. revision: partial
-
Referee: [Abstract] Abstract: The gamified framework is described only at a high level ('embeds adversarial evaluation, behavioural feedback, and security scoring') with no evaluation criteria, metrics, or pilot study design, rendering the proposed mitigation untestable.
Authors: We concur that the framework description remains high-level and lacks concrete metrics or pilot designs. This is consistent with the manuscript's goal of proposing a new workflow paradigm rather than reporting an implemented and evaluated system. We will expand the relevant section to include example security-scoring dimensions and a sketch of a possible pilot protocol, while continuing to note that full operationalization and testing lie outside the present scope. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper introduces a conceptual socio-technical model ('Secure Coding Drift') by explicit definition and proposes a gamified framework to address the described phenomenon. No equations, predictions, fitted parameters, or derivation steps are present in the provided text. The central claim is a definitional framing of a new vulnerability concept rather than a derived result that reduces to its own inputs. No self-citations, uniqueness theorems, or ansatzes are referenced. This matches the default expectation of no circularity for a model-introduction paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs frequently generate insecure or suboptimal code in security-critical domains such as PQC
- ad hoc to paper Security risk can be modelled as a longitudinal behavioural phenomenon from human-AI interaction
invented entities (1)
-
Secure Coding Drift model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Abdulrahman Hassan Alhazmi, Mumtaz Abdul Hameed, and Nalin Asanka Gam- agedara Arachchilage. 2022. Developers’ Privacy Education: A game frame- work to stimulate secure coding behaviour. In2022 IEEE Smartworld, Ubiq- uitous Intelligence & Computing, Scalable Computing & Communications, Dig- ital Twin, Privacy Computing, Metaverse, Autonomous & Trusted Veh...
work page doi:10.1109/smartworld-uic-atc-scalcom-digitaltwin-pricomp- 2022
-
[2]
Sathwik Amburi, Tiago Espinha Gasiba, Ulrike Lechner, and Maria Pinto- Albuquerque. 2025. Enabling Secure Coding: Exploring GenAI for Devel- oper Training and Education. In6th International Computer Programming Ed- ucation Conference (ICPEC 2025) (OpenAccess Series in Informatics (OASIcs), Vol. 114), Ricardo Queirós, Mário Pinto, Filipe Portela, and Alber...
-
[3]
Apiiro. 2026. What Is Security Drift? Indicators & Common Causes. https: //apiiro.com/glossary/security-drift/
2026
-
[4]
Hemachan- dra, and Madhusanka Liyanage
Abdullah Aydeger, Engin Zeydan, Awaneesh Kumar Yadav, Kasun T. Hemachan- dra, and Madhusanka Liyanage. 2024. Towards a Quantum-Resilient Future: Strategies for Transitioning to Post-Quantum Cryptography. In2024 15th Inter- national Conference on Network of the Future (NoF). IEEE, Castelldefels, Spain, 195–203. doi:10.1109/NoF62948.2024.10741441
-
[5]
Emils Bagirovs, Grigory Provodin, Tuomo Sipola, and Jari Hautamäki. 2024. Applications of Post-quantum Cryptography.Proceedings of the 23rd European Conference on Cyber Warfare and Security (2024)23, 1 (2024), 49–57. doi:10.48550/ arXiv.2406.13258
arXiv 2024
-
[6]
Aymen Dia Eddine Berini, Norziana Jamil, Ala-Eddine Benrazek, Abderrahmane Lakas, Leila Ismail, Mohamed Amine Ferrag, and Kwok-Yan Lam. 2026. Security and privacy in LLMs: A comprehensive survey of threats and mitigation strategies. Information Fusion132 (2026), 104241. doi:10.1016/j.inffus.2026.104241
-
[7]
Daniel J. Bernstein and Tanja Lange. 2017. Post-quantum cryptography.Nature 549, 7671 (2017), 188–194. doi:10.1038/nature23461
-
[8]
Iasonas Diakoumakos. 2023. Enhancing Cyber Security Education and Training through Gamification. InProceedings of the 2nd International Conference of the ACM Greek SIGCHI Chapter(Athens, Greece)(CHIGREECE ’23). Association for Computing Machinery, New York, NY, USA, Article 31, 5 pages. doi:10.1145/ 3609987.3610016
arXiv 2023
-
[9]
Ramtin Ehsani, Shriya Rawal, Yuanfang Cai, and Preetha Chatterjee. 2026. Faster Code, Deeper Debt? A Multivocal Literature Review on Technical Debt and Its Early Signs in LLM-Assisted Software Development.ACM Trans. Softw. Eng. Methodol.35, 7 (June 2026), 1–38. doi:10.1145/3820165 Just Accepted
-
[10]
Magdalena Glas, Christoph Nirschl, Bar Lanyado, and Johan van Niekerk. 2026. Insecure by design? A human-centric security perspective on AI-assisted software development.Computers & Security164 (2026), 104842. doi:10.1016/j.cose.2026. 104842
-
[11]
Raden Budiarto Hadiprakoso and Rudolf Paris Parlindungan Sihombing. 2024. CodeGuardians: A Gamified Learning for Enhancing Secure Coding Practices with AI-Driven Feedback.Ultima Infosys: Jurnal Ilmu Sistem Informasi15, 2 (December 2024), 105–112. https://www.researchgate.net/publication/ 387376972_CodeGuardians_A_Gamified_Learning_for_Enhancing_Secure_ Co...
2024
-
[12]
Md. Asraful Haque. 2025. LLMs: A game-changer for software engineers?Bench- Council Transactions on Benchmarks, Standards and Evaluations5, 1 (2025), 100204. doi:10.1016/j.tbench.2025.100204
-
[13]
Julius Hekkala, Mari Muurman, Kimmo Halunen, and Visa Antero Vallivaara
-
[14]
doi:10.1007/s42979-023-01724-1
Implementing Post-quantum Cryptography for Developers.SN Computer Science4, 4 (2023), 365. doi:10.1007/s42979-023-01724-1
-
[15]
Andrej Karpathy. 2025. I am ’vibe coding’ now. I just vibe with the code, look at it, see if it looks okay, then run it, see what happens, and iterate. I am no longer really a programmer, I am an LLM reviewer. X (formerly Twitter). https://x.com Accessed: 2026-06-17
2025
-
[16]
Shiri Melumad and Jin Ho Yun. 2025. Experimental evidence of the effects of large language models versus web search on depth of learning.PNAS Nexus 4, 10 (10 2025), pgaf316. arXiv:https://academic.oup.com/pnasnexus/article- pdf/4/10/pgaf316/64956155/pgaf316.pdf doi:10.1093/pnasnexus/pgaf316
-
[17]
Jasmine Moreira. 2026. Technical Foundation Document IACDM: Interactive Adversarial Convergence Development Methodology. arXiv:2604.16399v2 [cs.SE] https://doi.org/10.48550/arXiv.2604.16399
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.16399 2026
-
[18]
National Institute of Standards and Technology. 2026. Post-Quantum Cryp- tography Project. https://csrc.nist.gov/projects/post-quantum-cryptography. Accessed: 2026-06-17
2026
-
[19]
Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, and Ramesh Karri. 2025. Asleep at the Keyboard? Assessing the Security of GitHub Copilot’s Code Contributions.Commun. ACM68, 2 (Jan. 2025), 96–105. doi:10. 1145/3610721 Secure Coding Drift in LLM-Assisted Post-Quantum Cryptography Development: A Gamified Fix SIGIR VulGen ’26, July 24, 2026...
2025
-
[20]
Neil Perry, Megha Srivastava, Deepak Kumar, and Dan Boneh. 2023. Do Users Write More Insecure Code with AI Assistants?. InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security(Copenhagen, Denmark)(CCS ’23). Association for Computing Machinery, New York, NY, USA, 2785–2799. doi:10.1145/3576915.3623157
-
[21]
Duncan Pritchard. 2026. Why Technology Doesn’t Normally Make You Dumber, but Agentic AI Will.International Journal of Human–Computer Interaction0, 0 (2026), 1–11. arXiv:https://doi.org/10.1080/10447318.2026.2631678 doi:10.1080/ 10447318.2026.2631678
-
[22]
Sánchez-García, and Juan Car- los Pérez-Arriaga
Leonardo Criollo Ramírez, Xavier Limón, Ángel J. Sánchez-García, and Juan Car- los Pérez-Arriaga. 2025. State of the Art of the Security of Code Generated by LLMs: A Multivocal Literature Review.Programming and Computer Software51, 8 (dec 2025), 587–604. doi:10.1134/S0361768825700446
-
[23]
Shivani Shukla, Himanshu Joshi, and Romilla Syed. 2025. Security Degradation in Iterative AI Code Generation: A Systematic Analysis of the Paradox. In2025 IEEE International Symposium on Technology and Society (ISTAS). IEEE, Santa Clara, CA, USA, 1–8. doi:10.1109/ISTAS65609.2025.11269659
-
[24]
Marthin Toruan, R. D. N. Shakya, Samuel Tseitkin, Raymond K. Zhao, and Nalin Arachchilage. 2026. When Security Meets Usability: An Empirical Investigation of Post-Quantum Cryptography APIs. InProceedings of the 2026 Symposium on Usable Security and Privacy (USEC) (NDSS Symposium 2026). Internet Society, San Diego, CA, USA, 1–16. doi:10.14722/usec.2026.23076
-
[25]
The AI tool can’t make it any worse
Asli Yardim, Raphael Serafini, Nadine Jost, Anna-Marie Ortloff, Joshua Gabriel Speckels, and Alena Naiakshina. 2026. "The AI tool can’t make it any worse. " Investigating Developers’ Security Behavior with AI Assistants in a Pass- word Storage Study. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems (CHI ’26). Association for ...
-
[26]
Xinyi Zhou, Zeinadsadat Saghi, Sadra Sabouri, Rahul Pandita, Mollie McGuire, and Souti Chattopadhyay. 2026. Cognitive Biases in LLM-Assisted Software Development. InProceedings of the 2026 IEEE/ACM 48th International Conference on Software Engineering(Rio de Janeiro, Brazil)(ICSE ’26). ACM, New York, NY, USA, 13 pages. doi:10.1145/3744916.3773104 Received...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.