When Global Gating Is Enough: Admission-Time Hubness Control in Anisotropic Vector Retrieval Systems
Pith reviewed 2026-06-26 17:26 UTC · model grok-4.3
The pith
Global gating at admission detects vector hubs with recall 1.0 at decisive points and 0.91 on attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
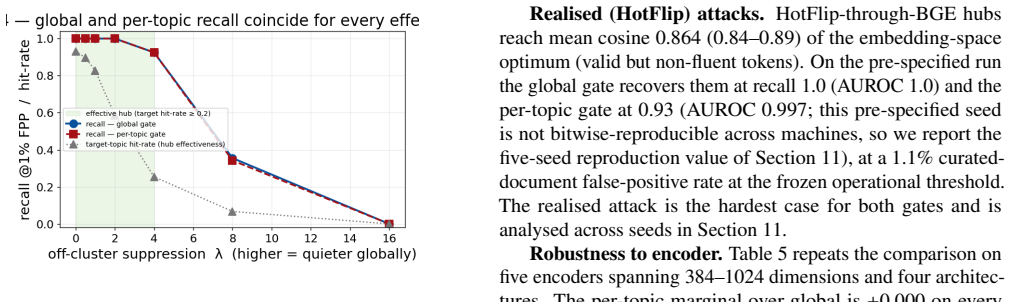
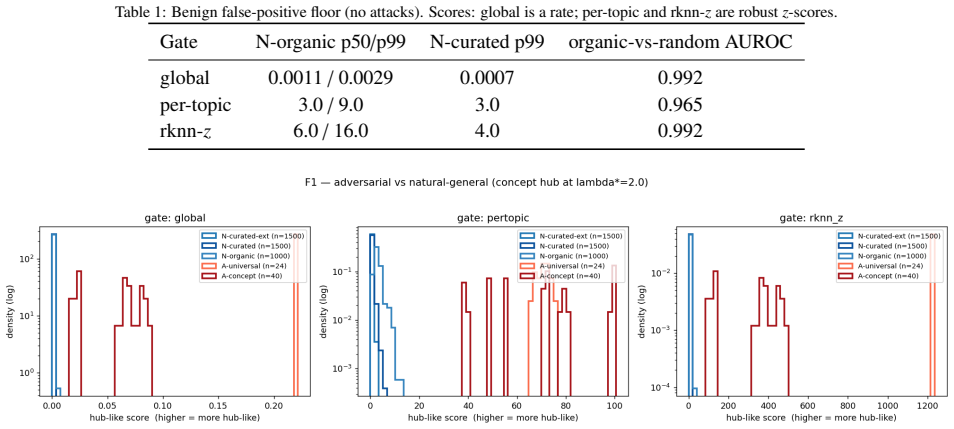
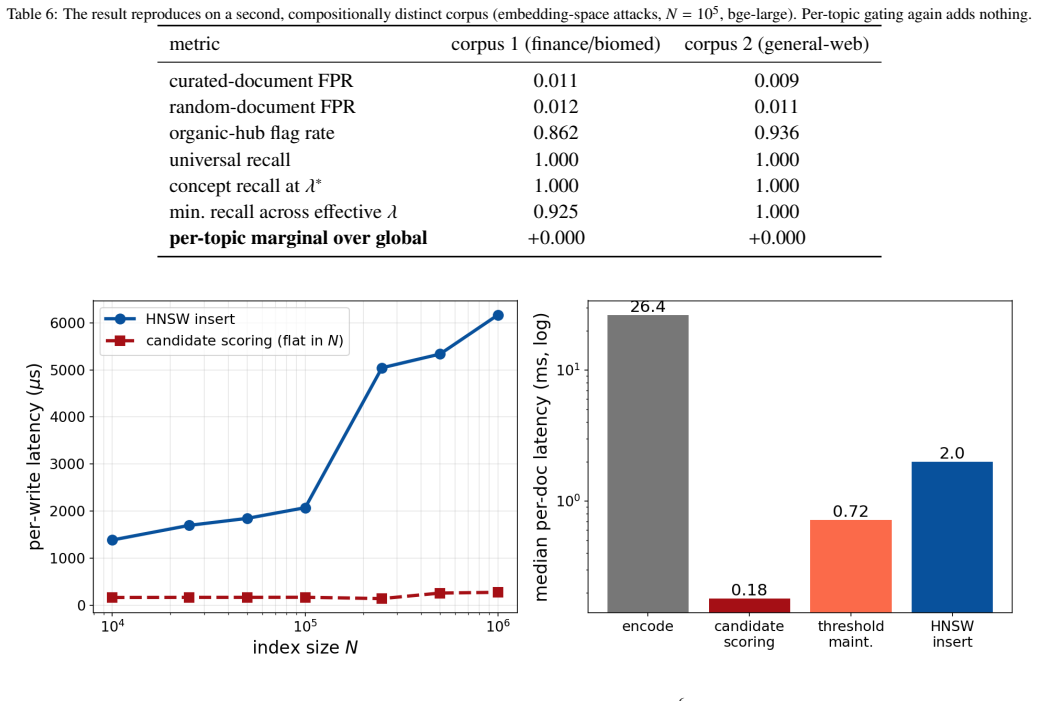
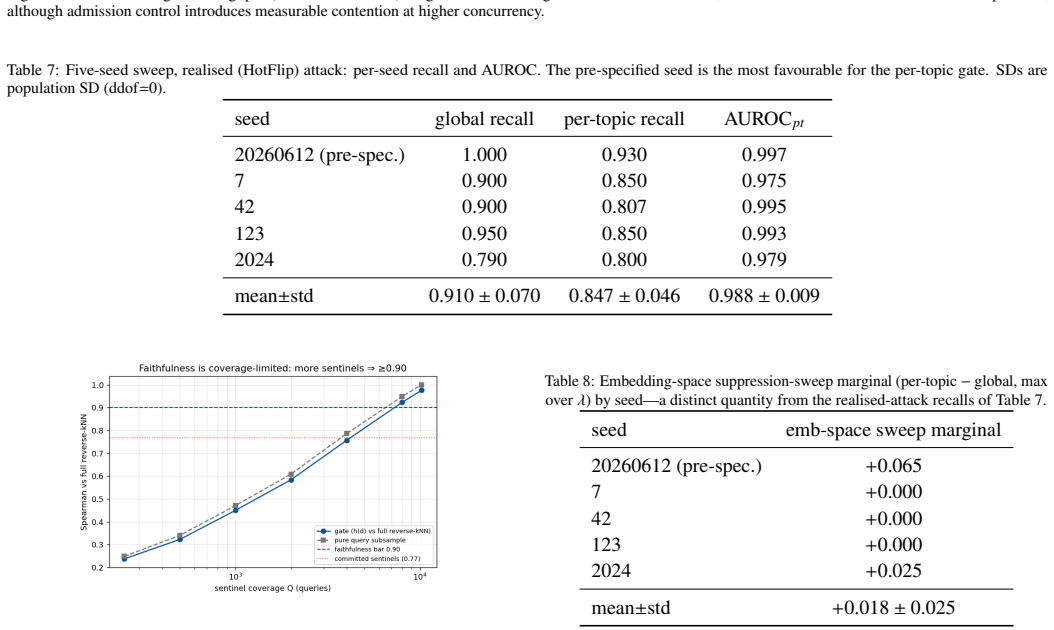
A global gate that scores each candidate document against sentinel queries at admission time and quarantines hub-like documents achieves recall 1.0 at the decisive embedding-space point (at least 0.92 across the effective range) and 0.91 plus or minus 0.07 on HotFlip attacks, with 1 percent false positives on general documents, across two 100,000-document corpora and five encoders; a per-topic gate shows no reliable benefit.
What carries the argument
The global gate: scoring each candidate document against a fixed set of sentinel queries at admission time to detect and quarantine those with hub-like properties before insertion.
If this is right
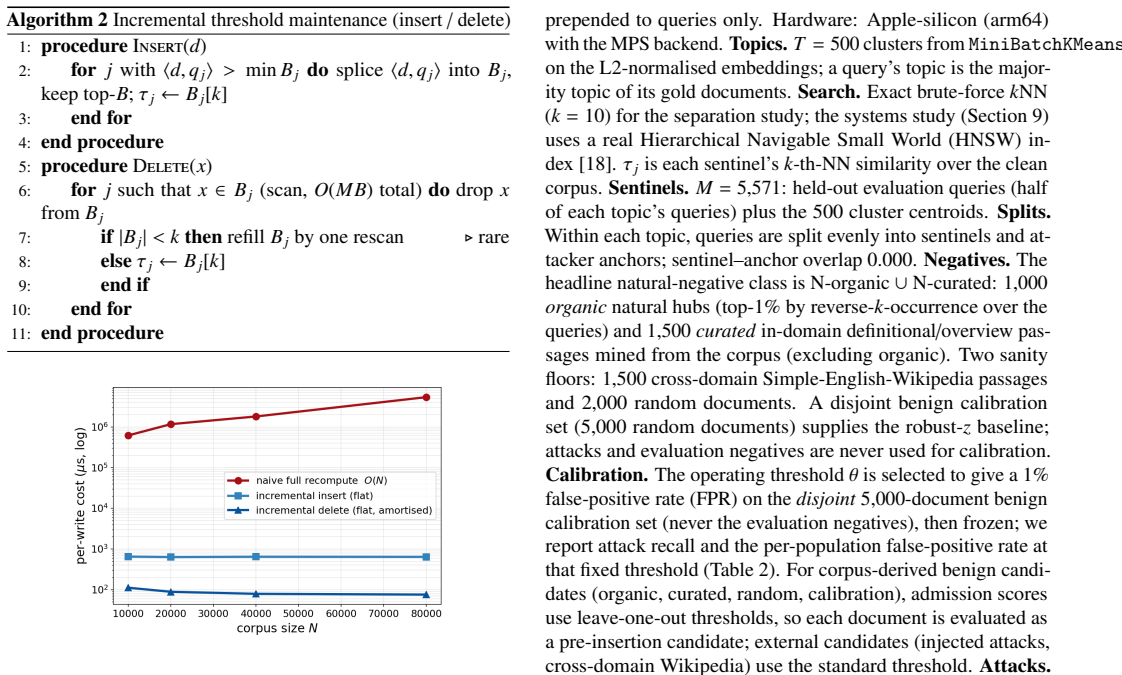
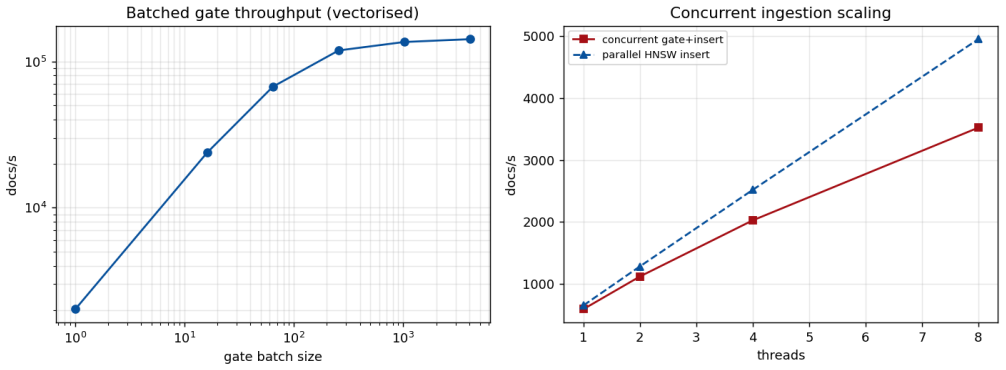
- Thresholds are maintained incrementally with corpus-size-independent insertion cost and amortized deletion cost.
- Admission adds about 3.1 percent to ingestion latency on HNSW, with scoring remaining flat to 10^6 vectors.
- Only 1.2 percent of decisions flip under approximate indexing, and none involve attacks.
- Provenance information can complement the gate for natural or tight-domain hubs.
Where Pith is reading between the lines
- If the sentinel-based detection generalizes, post-insertion monitoring could be reduced in production RAG pipelines.
- The method's behavior on corpora that grow and shrink rapidly would test whether incremental threshold maintenance remains stable.
- Anisotropy coupling local and global visibility may imply that similar global controls apply to other embedding tasks such as clustering or classification.
Load-bearing premise
Scoring candidate documents against a fixed set of sentinel queries at admission time can reliably detect and quarantine hub-like documents without knowledge of the actual query distribution or attacker strategies.
What would settle it
A document that passes the global gate yet becomes a nearest neighbor to many unrelated queries after insertion would falsify the effectiveness claim.
Figures


read the original abstract
Vector hubness, where a few points become nearest neighbors of many queries, creates a poisoning risk in retrieval-augmented generation (RAG): one injected document can influence unrelated requests. Existing defenses use periodic reverse-kNN scans, leaving an exposure window and repeated corpus-wide work. We study admission-time control, scoring each candidate against sentinel queries and quarantining hub-like documents before insertion. Across two 100,000-document corpora, five encoders, and disjoint attacker and defender query sets, a global gate achieves recall 1.0 at the decisive embedding-space point (>=0.92 across the effective range) and 0.91 +/- 0.07 on HotFlip attacks, with 1% false positives on general documents. A per-topic gate provides no reliable benefit, consistent with anisotropy coupling local and global visibility. Thresholds are maintained incrementally, with corpus-size-independent insertion cost and amortized deletion cost. On HNSW, admission adds about 3.1% to ingestion latency, scoring remains flat to 10^6 vectors, and 1.2% of decisions flip under approximate indexing, none involving attacks. Provenance complements the gate for natural or tight-domain hubs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study of admission-time hubness control in vector databases for RAG. It claims that scoring candidate documents against a fixed set of sentinel queries at insertion time enables a global gate to achieve recall 1.0 at the decisive embedding-space point (>=0.92 across the effective range) and 0.91 +/- 0.07 on HotFlip attacks across two 100,000-document corpora, five encoders, and disjoint attacker/defender query sets, while maintaining 1% false positives on general documents. It further claims that a per-topic gate provides no reliable benefit due to anisotropy coupling local and global visibility, with thresholds maintained incrementally at corpus-size-independent insertion cost and low overhead (~3.1% added latency on HNSW).
Significance. If the results hold, the work demonstrates a practical, low-overhead alternative to periodic reverse-kNN scans for mitigating hubness-based poisoning, with the empirical evaluation across multiple encoders and corpora providing useful evidence that global gating suffices. The incremental threshold maintenance and observation that 1.2% of decisions flip under approximate indexing (none involving attacks) are engineering strengths. The finding on anisotropy offers a design insight for retrieval systems.
major comments (2)
- [Abstract / Experiments] Abstract and experimental sections: The reported recall 1.0, 0.91 +/- 0.07, and 1% false-positive figures are presented without details on statistical tests, exact threshold selection process, data exclusion rules, or potential confounds (e.g., how sentinel queries were chosen relative to the evaluation distributions), which is load-bearing for verifying the generalization claim across disjoint query sets and encoders.
- [Methods] Methods / sentinel query construction: The selection and independence of the fixed sentinel queries from the test query distribution or attacker strategies is not specified in sufficient detail; this directly affects the central claim that the global gate works without knowledge of actual query distributions, as noted in the skepticism about generalization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional methodological detail would strengthen the paper. We address both major comments below and will revise the manuscript to incorporate the requested clarifications on experimental procedures and sentinel query construction.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental sections: The reported recall 1.0, 0.91 +/- 0.07, and 1% false-positive figures are presented without details on statistical tests, exact threshold selection process, data exclusion rules, or potential confounds (e.g., how sentinel queries were chosen relative to the evaluation distributions), which is load-bearing for verifying the generalization claim across disjoint query sets and encoders.
Authors: We agree that the manuscript would benefit from expanded detail on these points to support verification of the results. In the revised version we will add: (1) explicit description of the threshold selection process (chosen to enforce <=1% false positives on a held-out general-document validation set, with the same threshold applied across all encoders and corpora); (2) confirmation that no data points were excluded from the reported aggregates; (3) the precise sentinel-query selection procedure and its relation to the evaluation distributions; and (4) reporting of per-experiment standard deviations or bootstrap confidence intervals alongside the recall figures. These additions will be placed in the Experiments and Methods sections. revision: yes
-
Referee: [Methods] Methods / sentinel query construction: The selection and independence of the fixed sentinel queries from the test query distribution or attacker strategies is not specified in sufficient detail; this directly affects the central claim that the global gate works without knowledge of actual query distributions, as noted in the skepticism about generalization.
Authors: The current text states that sentinel queries are fixed and that attacker/defender query sets are disjoint, but we concur that the construction details are insufficiently explicit. In revision we will expand the Methods section to describe: the sentinel queries as a small, fixed set (size 10) sampled once from a broad, publicly available general-purpose corpus prior to any experiment; explicit verification that none of these sentinels appear in the attacker, defender, or general-document evaluation sets; and that the same fixed set is used for all five encoders and both corpora. This will directly substantiate the claim of distribution-independent operation. revision: yes
Circularity Check
No circularity: purely empirical evaluation with no derivation chain
full rationale
The paper reports an empirical method for admission-time hubness control using fixed sentinel queries, with performance metrics (recall, false positives) measured across corpora, encoders, and attack types. No equations, first-principles derivations, or predictions are claimed that could reduce to fitted inputs or self-referential quantities by construction. The anisotropy interpretation is post-hoc observation of results, not a load-bearing premise. No self-citation chains or ansatzes are invoked to justify core claims. The work is self-contained as an observational study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Radovanovi´c, A
M. Radovanovi´c, A. Nanopoulos, M. Ivanovi ´c, Hubs in space: popular nearest neighbors in high-dimensional data,Journal of Machine Learning Research11 (2010) 2487–2531
2010
-
[2]
Schnitzer, A
D. Schnitzer, A. Flexer, M. Schedl, G. Widmer, Local and global scaling reduce hubs in space,Journal of Machine Learning Re- search13 (2012) 2871–2902
2012
-
[3]
Lewis et al., Retrieval-augmented generation for knowledge- intensive NLP tasks, in:NeurIPS, 2020
P. Lewis et al., Retrieval-augmented generation for knowledge- intensive NLP tasks, in:NeurIPS, 2020
2020
-
[4]
K. Guu, K. Lee, Z. Tung, P. Pasupat, M.-W. Chang, REALM: retrieval-augmented language model pre-training, in:ICML, 2020
2020
-
[5]
Karpukhin et al., Dense passage retrieval for open-domain question answering, in:EMNLP, 2020
V . Karpukhin et al., Dense passage retrieval for open-domain question answering, in:EMNLP, 2020
2020
-
[6]
Khattab, M
O. Khattab, M. Zaharia, ColBERT: efficient and effective passage search via contextualized late interaction over BERT, in:SIGIR, 2020
2020
-
[7]
Izacard et al., Unsupervised dense information retrieval with contrastive learning (Contriever),TMLR(2022)
G. Izacard et al., Unsupervised dense information retrieval with contrastive learning (Contriever),TMLR(2022)
2022
-
[8]
Zhong, Z
Z. Zhong, Z. Huang, A. Wettig, D. Chen, Poisoning retrieval corpora by injecting adversarial passages, in:EMNLP, 2023
2023
-
[9]
W. Zou, R. Geng, B. Wang, J. Jia, PoisonedRAG: knowledge corruption attacks to retrieval-augmented generation of large language models, in:USENIX Security, 2025. 9
2025
-
[10]
Ben-Tov, M
M. Ben-Tov, M. Sharif, GASLITE-ing the retrieval: exploring vulnerabilities in dense embedding-based search, in:ACM CCS, 2025
2025
-
[11]
Zhang et al., Adversarial hubness in multi-modal retrieval, arXiv:2412.14113 (2024)
T. Zhang et al., Adversarial hubness in multi-modal retrieval, arXiv:2412.14113 (2024)
Pith/arXiv arXiv 2024
-
[12]
Ebrahimi, A
J. Ebrahimi, A. Rao, D. Lowd, D. Dou, HotFlip: white-box adversarial examples for text classification, in:ACL, 2018
2018
-
[13]
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, M. Fredrikson, Universal and transferable adversarial attacks on aligned language models, arXiv:2307.15043 (2023)
Pith/arXiv arXiv 2023
-
[14]
Xiang et al., Certifiably robust RAG against retrieval corrup- tion, arXiv:2405.15556 (2024)
C. Xiang et al., Certifiably robust RAG against retrieval corrup- tion, arXiv:2405.15556 (2024)
arXiv 2024
- [15]
- [16]
-
[17]
Cisco AI Defense, hubscan: Adversarial Hubness Detec- tor (software), https://github.com/cisco-ai-defense/ adversarial-hubness-detector(2026)
2026
-
[18]
Yu. A. Malkov, D. A. Yashunin, Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs,IEEE TPAMI42 (4) (2020) 824–836
2020
-
[19]
Jégou, M
H. Jégou, M. Douze, C. Schmid, Product quantization for nearest neighbor search,IEEE TPAMI33 (1) (2011) 117–128
2011
-
[20]
Johnson, M
J. Johnson, M. Douze, H. Jégou, Billion-scale similarity search with GPUs,IEEE Transactions on Big Data7 (3) (2021) 535– 547
2021
-
[21]
Guo et al., Accelerating large-scale inference with anisotropic vector quantization (ScaNN), in:ICML, 2020
R. Guo et al., Accelerating large-scale inference with anisotropic vector quantization (ScaNN), in:ICML, 2020
2020
-
[22]
S. J. Subramanya et al., DiskANN: fast accurate billion-point nearest neighbor search on a single node, in:NeurIPS, 2019
2019
-
[23]
Ethayarajh, How contextual are contextualized word represen- tations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings, in:EMNLP, 2019
K. Ethayarajh, How contextual are contextualized word represen- tations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings, in:EMNLP, 2019
2019
-
[24]
Gao et al., Representation degeneration problem in training natural language generation models, in:ICLR, 2019
J. Gao et al., Representation degeneration problem in training natural language generation models, in:ICLR, 2019
2019
-
[25]
J. Mu, S. Bhat, P. Viswanath, All-but-the-top: simple and effective postprocessing for word representations, in:ICLR, 2018
2018
-
[26]
Li et al., On the sentence embeddings from pre-trained lan- guage models (BERT-flow), in:EMNLP, 2020
B. Li et al., On the sentence embeddings from pre-trained lan- guage models (BERT-flow), in:EMNLP, 2020
2020
-
[27]
J. Su et al., Whitening sentence representations for better seman- tics and faster retrieval, arXiv:2103.15316 (2021)
arXiv 2021
-
[28]
T. Gao, X. Yao, D. Chen, SimCSE: simple contrastive learning of sentence embeddings, in:EMNLP, 2021
2021
-
[29]
S. Xiao, Z. Liu, P. Zhang, N. Muennighoff, D. Lian, J.-Y . Nie, C- Pack: packed resources for general Chinese embeddings (BGE), arXiv:2309.07597 (2023)
Pith/arXiv arXiv 2023
-
[30]
L. Wang et al., Text embeddings by weakly-supervised contrastive pre-training (E5), arXiv:2212.03533 (2022)
Pith/arXiv arXiv 2022
-
[31]
Z. Li et al., Towards general text embeddings with multi-stage contrastive learning (GTE), arXiv:2308.03281 (2023)
Pith/arXiv arXiv 2023
-
[32]
Reimers, I
N. Reimers, I. Gurevych, Sentence-BERT: sentence embeddings using Siamese BERT-networks, in:EMNLP, 2019
2019
-
[33]
Wang et al., MiniLM: deep self-attention distillation for task- agnostic compression of pre-trained transformers, in:NeurIPS, 2020
W. Wang et al., MiniLM: deep self-attention distillation for task- agnostic compression of pre-trained transformers, in:NeurIPS, 2020
2020
-
[34]
Thakur, N
N. Thakur, N. Reimers, A. Rücklé, A. Srivastava, I. Gurevych, BEIR: a heterogeneous benchmark for zero-shot evaluation of information retrieval models, in:NeurIPS Datasets and Bench- marks, 2021
2021
-
[35]
Muennighoff, N
N. Muennighoff, N. Tazi, L. Magne, N. Reimers, MTEB: massive text embedding benchmark, in:EACL, 2023
2023
-
[36]
J. A. Blakeley, P.-A. Larson, F. W. Tompa, Efficiently updating materialized views, in:ACM SIGMOD, 1986
1986
-
[37]
Gupta, I
A. Gupta, I. S. Mumick, Maintenance of materialized views: problems, techniques, and applications,IEEE Data Engineering Bulletin18 (2) (1995) 3–18
1995
-
[38]
Welsh, D
M. Welsh, D. Culler, Adaptive overload control for busy internet servers, in:USENIX Symp. Internet Technologies and Systems (USITS), 2003
2003
-
[39]
Biggio, B
B. Biggio, B. Nelson, P. Laskov, Poisoning attacks against support vector machines, in:ICML, 2012
2012
-
[40]
Carlini et al., Poisoning web-scale training datasets is practical, in:IEEE S&P, 2024
N. Carlini et al., Poisoning web-scale training datasets is practical, in:IEEE S&P, 2024. 10
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.