ParaScale: Scale-Calibrated Camera-Motion Transfer via a Gauge-Invariant Parallax Number
Pith reviewed 2026-06-26 18:32 UTC · model grok-4.3
The pith
Scale-faithful camera-motion transfer requires preserving a dimensionless Parallax Number rather than the raw trajectory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that scale-faithful transfer must preserve the gauge-invariant Parallax Number Pi = ||Delta T|| / Zbar per frame instead of the raw trajectory, because this single dimensionless quantity encodes how strongly the camera move is felt in the image plane.
What carries the argument
The Parallax Number Pi, a dimensionless ratio of translation magnitude to average scene depth that remains invariant under uniform scaling of the entire scene and trajectory.
If this is right
- Transfer remains consistent when reference and target scenes differ in linear scale by four orders of magnitude.
- The same reference trajectory can be applied to both microscopic and astronomical scenes without manual rescaling.
- Pose-conditioned generators can accept the calibrated poses directly, with no change to their training or architecture.
- The Parallax Consistency Error metric reveals scale mismatch that similarity-aligned trajectory error hides.
Where Pith is reading between the lines
- The same gauge-invariant scalar could be used to calibrate motion transfer in non-video domains such as 3D scene editing or robotics trajectory replay.
- Because rotation is left untouched, the method implicitly assumes that rotational parallax effects are negligible or handled separately by the underlying generator.
- If depth maps in the target scene contain large errors, the realized Pi will deviate even when the method runs correctly, suggesting a natural extension that jointly refines depth and motion.
Load-bearing premise
Image motion caused by translation is exactly proportional to translation magnitude over depth, and matching the single scalar Pi per frame is enough to achieve faithful transfer while rotation can be copied unchanged.
What would settle it
Generate videos from the same reference motion but with target scenes whose average depth differs by a known factor; if the realized image motion strength does not match the reference after ParaScale adjustment, the claim that preserving Pi suffices is false.
Figures

read the original abstract
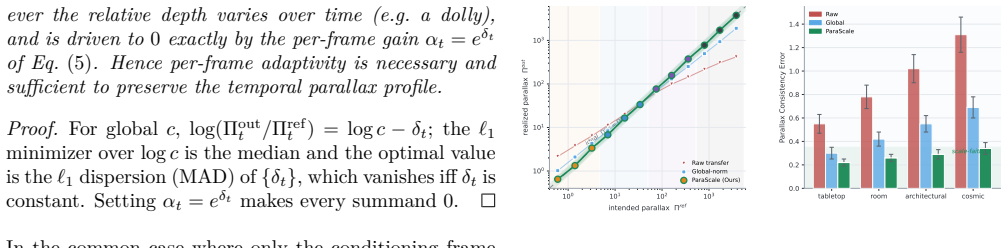
Transferring the camera motion of a reference video to a freshly generated one lets creators reuse cinematic moves. Yet reference and target often live at incompatible scales -- a sweep across a galaxy versus a nudge across a desk -- and naively reusing the recovered trajectory yields either imperceptible or violently exaggerated motion. We trace this to a geometric fact: translation-induced image motion scales as ||T||/Z, so a monocular trajectory is meaningful only up to a depth-scale gauge. We distill this into the Parallax Number Pi = ||Delta T|| / Zbar, a dimensionless, gauge-invariant descriptor of how strongly a camera move is felt, and prove that it -- not the raw trajectory -- is the quantity that scale-faithful transfer must preserve. ParaScale is a plug-and-play module that reads Pi off any reference video and re-realizes it against the target scene's own depth, per frame, leaving rotation untouched. Sitting between pose extraction and pose injection, it requires no retraining and drops into any pose-conditioned generator. We further introduce the Parallax Consistency Error (PCE), a scale-symmetric metric that -- unlike the similarity-aligned TransErr -- exposes scene-scale mismatch. Across scale regimes spanning four orders of magnitude and multiple backbones, ParaScale keeps the realized parallax on the identity line and cuts PCE by more than 3x over uncalibrated transfer with no loss of visual fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that monocular camera trajectories are only meaningful up to a depth-scale gauge because translation-induced image motion scales as ||T||/Z. It distills this into the Parallax Number Pi = ||ΔT|| / Z̄ (Z̄ = arithmetic mean depth), asserts a proof that scale-faithful transfer must preserve this gauge-invariant scalar (not the raw trajectory) while leaving rotation untouched, and presents ParaScale as a plug-and-play module that reads Pi from a reference video and re-realizes it against the target scene's depth per frame. It also introduces the scale-symmetric Parallax Consistency Error (PCE) metric and reports that ParaScale keeps realized parallax on the identity line across four orders of magnitude in scale, reduces PCE by >3× versus uncalibrated transfer, and incurs no visual-fidelity loss on multiple backbones.
Significance. If the derivation and definition of Pi are corrected, the work supplies a lightweight, training-free calibration layer that sits between any pose estimator and any pose-conditioned generator, addressing a practical mismatch that currently forces either imperceptible or exaggerated motion when reference and target scenes differ in scale. The PCE metric is a clear incremental strength because, unlike similarity-aligned TransErr, it is invariant to global scale and directly exposes the mismatch the method targets. No machine-checked proofs or parameter-free derivations are present.
major comments (1)
- [Definition of the Parallax Number / geometric premise] Definition of Pi (abstract and geometric-premise section): Pi is defined as ||ΔT|| / Z̄ with Z̄ the arithmetic mean of scene depths. Translation-induced image motion at pixel i is ||ΔT|| / Z_i, so the quantity that should be preserved to keep average parallax magnitude is ||ΔT|| · E[1/Z_i]. By Jensen's inequality, E[1/Z] ≥ 1/E[Z] with equality only when depth variance is zero. Consequently the stated Pi equals the correct average parallax only in the degenerate constant-depth case; in any scene with depth variation the preserved quantity systematically under-states the felt motion. This directly contradicts the central claim that Pi is the precise gauge-invariant descriptor whose preservation guarantees scale-faithful transfer.
minor comments (1)
- [Abstract / introduction] The abstract states that a proof is given that Pi (rather than the raw trajectory) must be preserved, yet no derivation steps, error bounds, or verification that per-frame re-realization maintains visual fidelity are visible. A short dedicated subsection laying out the steps would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive comment on the definition of the Parallax Number. The observation regarding Jensen's inequality is valid and we address it directly below, indicating the changes we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: Definition of Pi (abstract and geometric-premise section): Pi is defined as ||ΔT|| / Z̄ with Z̄ the arithmetic mean of scene depths. Translation-induced image motion at pixel i is ||ΔT|| / Z_i, so the quantity that should be preserved to keep average parallax magnitude is ||ΔT|| · E[1/Z_i]. By Jensen's inequality, E[1/Z] ≥ 1/E[Z] with equality only when depth variance is zero. Consequently the stated Pi equals the correct average parallax only in the degenerate constant-depth case; in any scene with depth variation the preserved quantity systematically under-states the felt motion. This directly contradicts the central claim that Pi is the precise gauge-invariant descriptor whose preservation guarantees scale-faithful transfer.
Authors: We agree that the average parallax magnitude is strictly ||ΔT|| ⋅ E[1/Z_i] and that the arithmetic-mean formulation equals this quantity only when depth variance is zero. The original definition was selected for its simplicity in yielding a dimensionless, gauge-invariant scalar that is straightforward to compute from a reference video. Nevertheless, the referee's point is correct and directly impacts the precision of the central claim. In the revised manuscript we will redefine Pi as ||ΔT|| ⋅ E[1/Z_i] (equivalently, ||ΔT|| divided by the harmonic mean of the depths). We will update the abstract, the geometric-premise section, and the accompanying derivation to reflect this more accurate quantity while preserving the overall transfer procedure and the PCE metric. This change does not affect the empirical results or the plug-and-play nature of ParaScale. revision: yes
Circularity Check
No circularity; Parallax Number defined directly from geometric scaling relation
full rationale
The paper defines Pi = ||Delta T|| / Zbar explicitly from the stated geometric premise that translation-induced image motion scales as ||T||/Z, then claims this scalar is the gauge-invariant quantity that must be preserved for scale-faithful transfer. No equations, self-citations, or fitted parameters are visible that would reduce the claimed result to the inputs by construction. The derivation chain remains self-contained against external geometric benchmarks, with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Translation-induced image motion scales as ||T||/Z
invented entities (1)
-
Parallax Number Pi
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Tokenflow: Consistent diffusion fea- tures for consistent video editing.arXiv preprint arXiv:2307.10373, 2023
Pith/arXiv arXiv 2023
-
[2]
Cambridge University Press, 2nd edition, 2004
Richard Hartley and Andrew Zisserman.Multiple View Geometry in Computer Vision. Cambridge University Press, 2nd edition, 2004
2004
-
[3]
CameraCtrl: Enabling camera control for video gen- eration
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wet- zstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. CameraCtrl: Enabling camera control for video gen- eration. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[4]
Hao He, Ceyuan Yang, Shanchuan Lin, Yinghao Xu, et al. CameraCtrl II: Dynamic scene exploration Variant PCE↓TransErr↓RotErr↓ globalα(no per-frame) 0.47 0.83 1.03 also rescale rotation 0.31 0.51 1.41 w/o depth (norm-onlyΠ) 0.44 0.74 1.04 ★ParaScale (full) 0.28 0.46 1.02 Table 3:Ablation.Per-frameαt (Prop. 2) and a depth estimate are both needed; rescaling ...
arXiv 2025
-
[5]
Teng Hu, Jiangning Zhang, Ran Yi, Yating Wang, Hongrui Huang, Jieyu Weng, Yabiao Wang, and Lizhuang Ma. Motionmaster: Training-free camera motion transfer for video generation.arXiv preprint arXiv:2404.15789, 2024
arXiv 2024
-
[6]
Dive: Dit- basedvideogenerationwithenhancedcontrol.arXiv preprint arXiv:2409.01595, 2024
Junpeng Jiang, Gangyi Hong, Lijun Zhou, Enhui Ma, Hengtong Hu, Xia Zhou, Jie Xiang, Fan Liu, Kaicheng Yu, Haiyang Sun, et al. Dive: Dit- basedvideogenerationwithenhancedcontrol.arXiv preprint arXiv:2409.01595, 2024
arXiv 2024
-
[7]
Drivegan: Towards a controllable high-quality neural simulation
Seung Wook Kim, Jonah Philion, Antonio Torralba, and Sanja Fidler. Drivegan: Towards a controllable high-quality neural simulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5820–5829, 2021
2021
-
[8]
Quanhao Li, Zhen Xing, Rui Wang, Hui Zhang, Qi Dai, and Zuxuan Wu. Magicmotion: Control- lable video generation with dense-to-sparse trajec- tory guidance.arXiv preprint arXiv:2503.16421, 2025
arXiv 2025
-
[9]
Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers. IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 2024
2024
-
[10]
Jiwen Liu, Shujuan Li, Zhixue Fang, Xiaohan Li, Yan Zhou, Zijie Meng, Zhimin Zhang, Yawen Luo, Guoxin Zhang, Yu-Shen Liu, et al. Omnidirector: 5 General multi-shot camera cloning without cross- paired data.arXiv preprint arXiv:2606.13432, 2026
Pith/arXiv arXiv 2026
-
[11]
Synpo: Boosting training-free few-shot medical seg- mentation via high-quality negative prompts
Yufei Liu, Haoke Xiao, Jiaxing Chai, Yongcun Zhang, Rong Wang, Zijie Meng, and Zhiming Luo. Synpo: Boosting training-free few-shot medical seg- mentation via high-quality negative prompts. InIn- ternational Conference on Medical Image Comput- ing and Computer-Assisted Intervention, pages 594–
-
[12]
Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation
Zhijian Liu, Haotian Tang, Alexander Amini, Xingyu Yang, Huizi Mao, Daniela Rus, and Song Han. Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. InIEEE In- ternational Conference on Robotics and Automation (ICRA), 2023
2023
-
[13]
Make a game: A novel paradigm for interactive game rendering
Zijie Meng, Jinming Che, Bingcai Wei, and Xixin Cao. Make a game: A novel paradigm for interactive game rendering. InICASSP 2026-2026 IEEE Inter- national Conference on Acoustics, Speech and Sig- nal Processing (ICASSP), pages 1026–1030. IEEE, 2026
2026
-
[14]
Trident: Breaking the hybrid-safety-physics cou- pling for provably safe multi-agent reinforcement learning, 2026
Zijie Meng, Ziwei Li, Yufei Liu, Zhiyu Li, Jiyuan Liu, Wenhua Nie, Bingcai Wei, and Miao Zhang. Trident: Breaking the hybrid-safety-physics cou- pling for provably safe multi-agent reinforcement learning, 2026
2026
-
[15]
Zijie Meng, Jiwen Liu, Yufei Liu, Chengzhuo Tong, Xiaoqiang Liu, Yuanxing Zhang, Yulong Xu, and Pengfei Wan. Argus: Stacked multi-view identity mosaic injection for subject-preserving video gener- ation.arXiv preprint arXiv:2606.11670, 2026
Pith/arXiv arXiv 2026
-
[16]
Omnidrive: To- wards unified next-gen controllable multi-view driv- ing video generation with llm-guided world model
ZijieMeng, BingcaiWei, ShuqinChen, JinmingChe, Xinyan Cao, and JinLong Lin. Omnidrive: To- wards unified next-gen controllable multi-view driv- ing video generation with llm-guided world model
-
[17]
Orpaint: a zero-shot inpainting model for oracle bone inscription rubbings with visual mamba block.Science China Information Sciences, 68(8):189102, 2025
Zijie Meng, Yuanze Zeng, Xiang Chang, Tianshuo Xu, Fei Chao, Xixin Cao, Changjing Shang, and Qiang Shen. Orpaint: a zero-shot inpainting model for oracle bone inscription rubbings with visual mamba block.Science China Information Sciences, 68(8):189102, 2025
2025
-
[18]
Dreamfusion: Text-to-3d using 2d dif- fusion.arXiv preprint arXiv:2209.14988, 2022
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d dif- fusion.arXiv preprint arXiv:2209.14988, 2022
Pith/arXiv arXiv 2022
-
[19]
Language conditioned traffic generation.arXiv preprint arXiv:2307.07947, 2023
Shuhan Tan, Boris Ivanovic, Xinshuo Weng, Marco Pavone, and Philipp Kraehenbuehl. Language conditioned traffic generation.arXiv preprint arXiv:2307.07947, 2023
arXiv 2023
-
[20]
Wan: Open and ad- vanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and ad- vanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[21]
Cinemaster: A 3d-aware and controllable framework for cinematic text-to-video generation
Qinghe Wang, Yawen Luo, Xiaoyu Shi, Xu Jia, Huchuan Lu, Tianfan Xue, Xintao Wang, Pengfei Wan, Di Zhang, and Kun Gai. Cinemaster: A 3d-aware and controllable framework for cinematic text-to-video generation. InProceedings of the Spe- cial Interest Group on Computer Graphics and In- teractive Techniques Conference Conference Papers, pages 1–10, 2025
2025
-
[22]
Videocomposer: Com- positional video synthesis with motion controllabil- ity.Advances in Neural Information Processing Sys- tems, 36:7594–7611, 2023
Xiang Wang, Hangjie Yuan, Shiwei Zhang, Dayou Chen, Jiuniu Wang, Yingya Zhang, Yujun Shen, DeliZhao, andJingrenZhou. Videocomposer: Com- positional video synthesis with motion controllabil- ity.Advances in Neural Information Processing Sys- tems, 36:7594–7611, 2023
2023
-
[23]
Motionctrl: A unified and flexible mo- tion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible mo- tion controller for video generation. InACM SIG- GRAPH 2024 Conference Papers, pages 1–11, 2024
2024
-
[24]
Rusid: Robust uncertainty-aware single image deraining beyond certainty
Bingcai Wei, Hui Liu, Chuang Qian, Zijian Li, and Zijie Meng. Rusid: Robust uncertainty-aware single image deraining beyond certainty
-
[25]
Robust single image sand removal by leveraging uncertainty-aware sam priors and prompt learning with refined perceptual loss
Bingcai Wei, Hui Liu, Chuang Qian, Zijian Li, Wangyu Wu, and Zijie Meng. Robust single image sand removal by leveraging uncertainty-aware sam priors and prompt learning with refined perceptual loss. InProceedings of the 33rd ACM International Conference on Multimedia, pages 4932–4941, 2025
2025
-
[26]
Wei Wu, Xi Guo, Weixuan Tang, Tingxuan Huang, Chiyu Wang, Dongyue Chen, and Chenjing Ding. Drivescape: Towards high-resolution controllable multi-view driving video generation.arXiv preprint arXiv:2409.05463, 2024
arXiv 2024
-
[27]
Generating multimodal driving scenes via next-scene prediction
Yanhao Wu, Haoyang Zhang, Tianwei Lin, Lichao Huang, Shujie Luo, Rui Wu, Congpei Qiu, Wei Ke, and Tong Zhang. Generating multimodal driving scenes via next-scene prediction. InProceedings of the Computer Vision and Pattern Recognition Con- ference, pages 6844–6853, 2025
2025
-
[28]
Meng You, Zhiyu Zhu, Hui Liu, and Junhui Hou. Nvs-solver: Video diffusion model as zero-shot novel view synthesizer.arXiv preprint arXiv:2405.15364, 2024. 6
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.