OmniDirector: General Multi-Shot Camera Cloning without Cross-Paired Data
Pith reviewed 2026-06-27 07:09 UTC · model grok-4.3
The pith
Encoding cameras as grid motion videos lets a diffusion model clone multi-shot camera trajectories from references without cross-paired training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
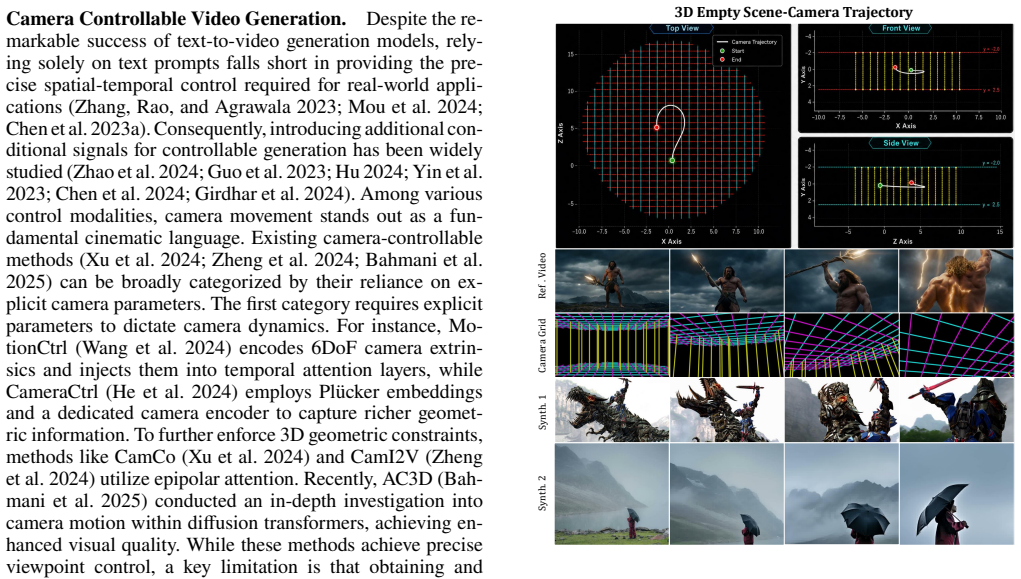
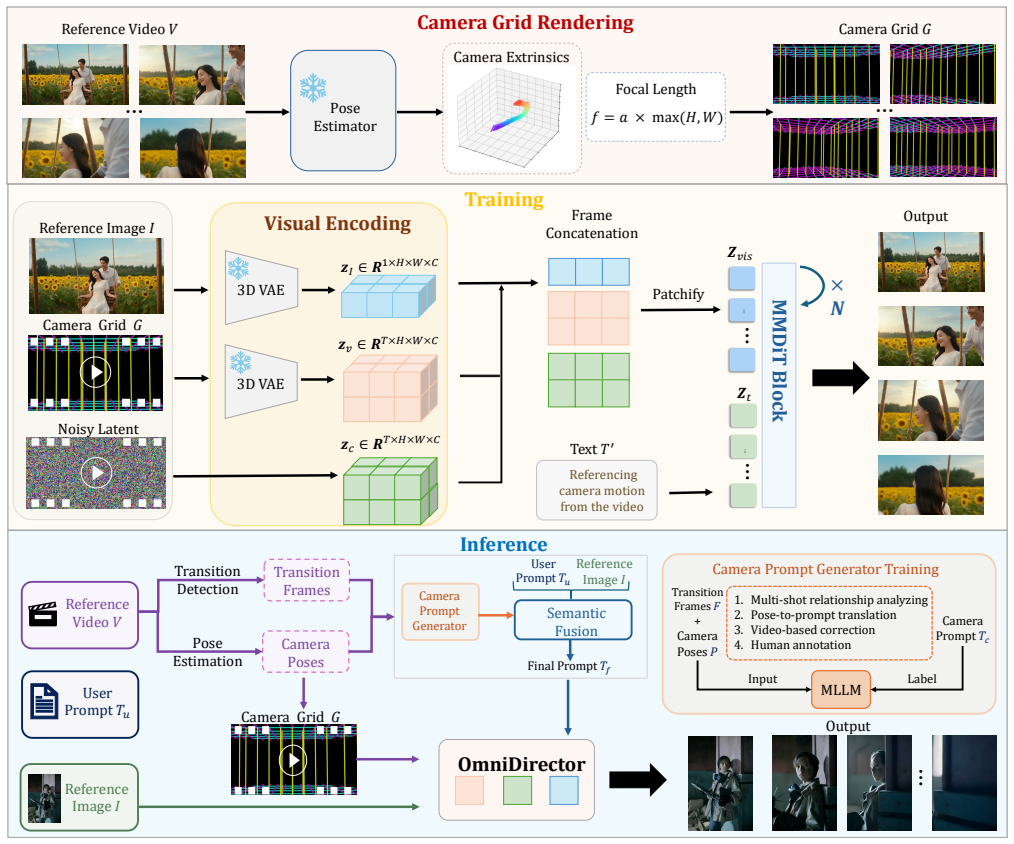
A general camera motion representation that encodes cameras as grid motion videos supports the integration of diverse trajectories for multi-shot video generation. Building on this representation, OmniDirector is a unified framework trained on a million-scale set of camera grid-video pairs that coordinates characters, actions, and cameras to deliver director-level control inside multimodal diffusion transformers, together with a hierarchical prompt expansion agent that integrates the control signals by describing their relationships.
What carries the argument
Camera grid motion videos, a visual encoding of camera parameters that turns trajectories into grid-based motion videos usable as direct input for training and inference.
If this is right
- Training becomes possible on ordinary video datasets rather than scarce cross-paired examples.
- Multi-shot camera cloning works for arbitrary numbers and types of shots within one generation.
- Character, action, and camera controls can be combined inside one diffusion transformer.
- A hierarchical prompt agent can systematically relate different control signals to improve coherence.
Where Pith is reading between the lines
- The grid representation could be applied to other motion types such as object trajectories or lighting paths.
- Director-level control might reduce the need for post-production camera work in AI-generated video.
- The approach could be tested on real film footage to measure how well it reproduces professional camera techniques.
Load-bearing premise
Converting camera parameters into grid motion videos preserves all trajectory information needed for accurate complex multi-shot generation without loss or artifacts.
What would settle it
Generate a video from a reference multi-shot camera sequence whose ground-truth parameters are known, then extract the camera path from the output frames and measure whether it matches the reference path within a small threshold.
Figures


read the original abstract
Cloning camera motion from reference videos is an important task in video generation, as videos provide intuitive and precise control. Existing methods either directly use parametric representations that fail to handle multi-shot generation or synthesize cross-paired data, which suffer from data scarcity, resulting in poor performance in complicated camera motion cloning. To address these issues, we introduce a general camera motion representation that encodes cameras as grid motion videos. This camera grid represents the camera parameters visually and supports the integration of diverse trajectories for multi-shot video generation. Building upon this, we propose OmniDirector, a unified framework trained on a million-scale camera grid-video pairs that coordinates characters, actions, and cameras to provide director-level control for multimodal diffusion transformers. Furthermore, we design a novel hierarchical prompt expansion agent that harmoniously integrates different control signals by systematically describing camera motion and visual content through understanding signal relationships. Extensive experiments demonstrate the superior performance and outstanding controllability of our framework. Project page: https://ymlinfeng.github.io/OmniDirector.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to solve multi-shot camera cloning in video generation by introducing a general camera motion representation that encodes camera parameters as grid motion videos, enabling integration of diverse trajectories without cross-paired data. It proposes OmniDirector, a unified framework trained on a million-scale dataset of camera grid-video pairs that coordinates characters, actions, and cameras within multimodal diffusion transformers, plus a hierarchical prompt expansion agent to integrate control signals. The abstract asserts superior performance and outstanding controllability based on extensive experiments.
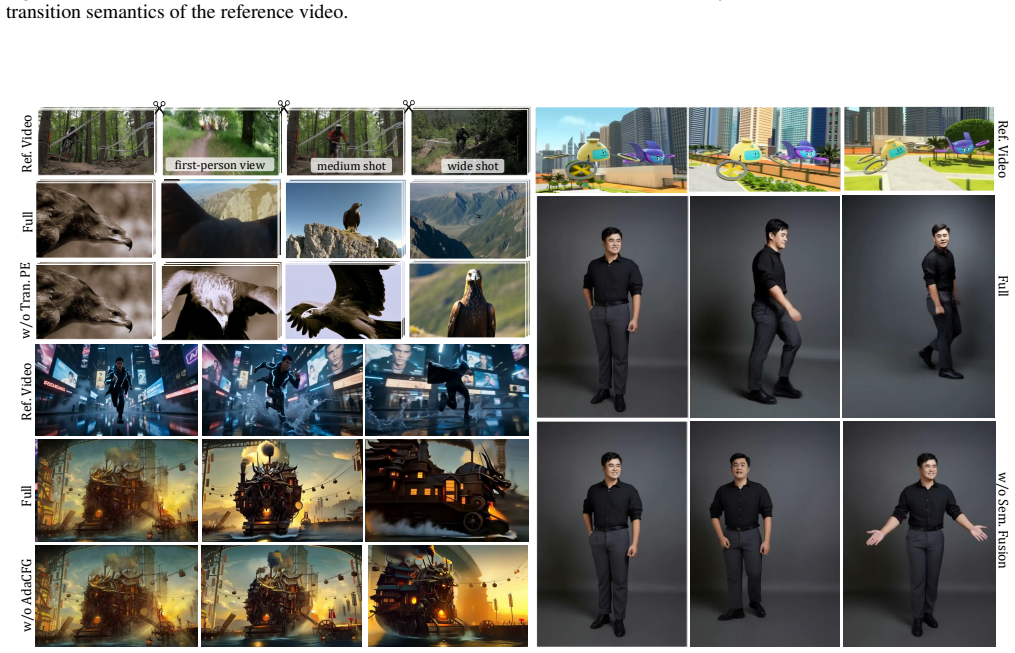
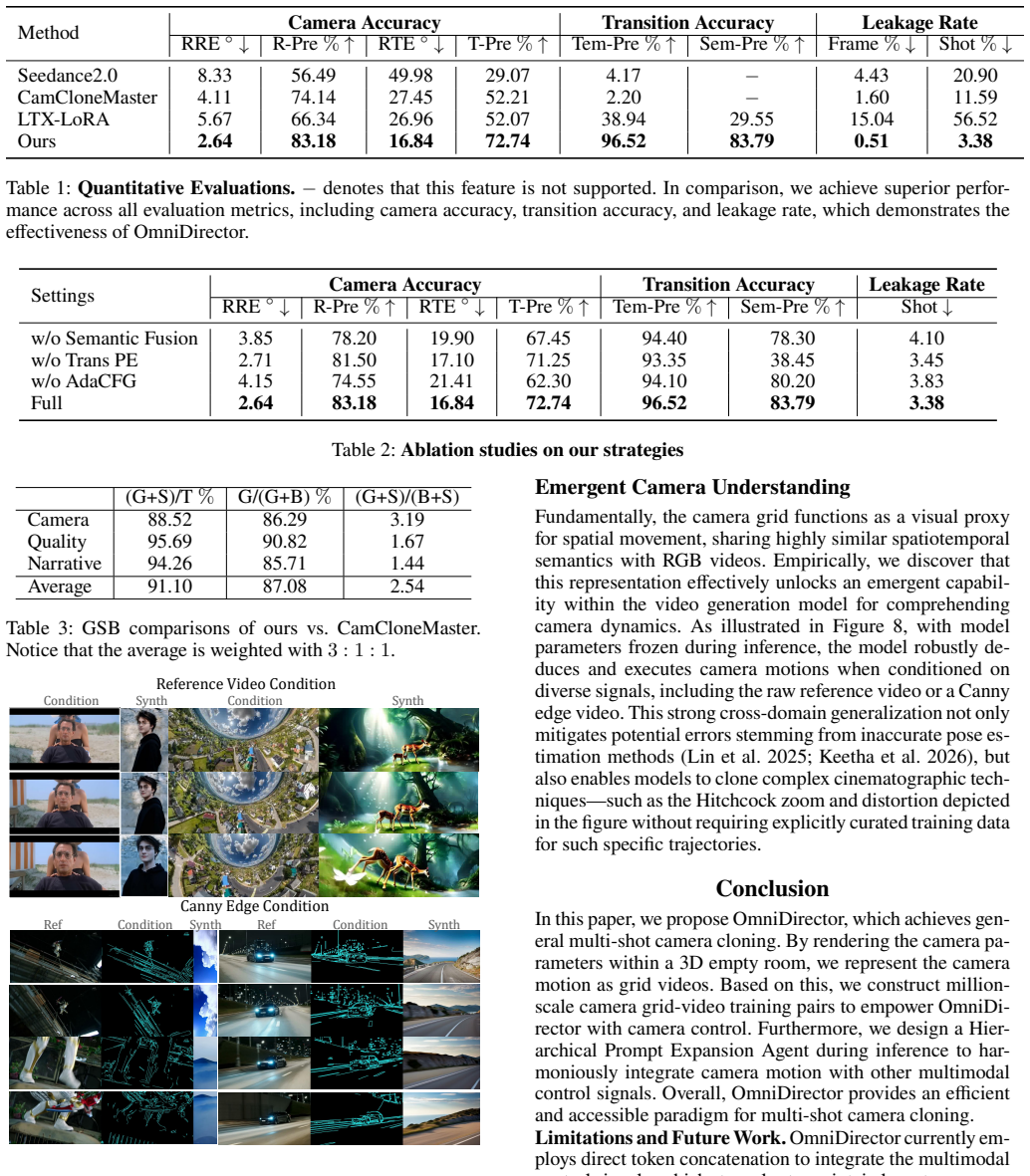
Significance. If the grid representation preserves all degrees of freedom (extrinsics, intrinsics, timing) without discretization artifacts and the large-scale training yields reliable inversion at inference, the approach could meaningfully reduce data requirements for controllable video generation and support complex multi-shot scenarios. The scale of the training data and the agent-based prompt harmonization are potential strengths if validated.
major comments (2)
- [Abstract] Abstract: the central claim that encoding cameras as grid motion videos 'represents the camera parameters visually' and 'supports the integration of diverse trajectories for multi-shot video generation' without loss of precision lacks any forward mapping, inverse recovery procedure, quantization analysis, or error bounds; if spatial discretization or temporal aliasing occurs, the controllability guarantee for non-trivial motions does not hold.
- [Abstract] Abstract: no equations, derivations, ablation studies, or quantitative metrics are supplied to evaluate whether the million-scale training on grid-video pairs actually enables the claimed director-level control or outperforms parametric baselines on complex multi-shot cases.
minor comments (1)
- [Abstract] Abstract: the phrasing 'This camera grid represents the camera parameters visually' is redundant with the preceding sentence and could be tightened for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our abstract. We clarify that the supporting technical details, analyses, and evaluations are provided in the main body and supplementary material of the manuscript. We will revise the abstract to more explicitly reference these elements while maintaining its concise nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that encoding cameras as grid motion videos 'represents the camera parameters visually' and 'supports the integration of diverse trajectories for multi-shot video generation' without loss of precision lacks any forward mapping, inverse recovery procedure, quantization analysis, or error bounds; if spatial discretization or temporal aliasing occurs, the controllability guarantee for non-trivial motions does not hold.
Authors: The forward mapping from camera parameters (extrinsics, intrinsics, timing) to grid motion videos is formally defined in Section 3.1, with the inverse recovery procedure in Section 3.2. Quantization analysis, including spatial discretization effects and temporal aliasing bounds, appears in Section 4.3 with supporting error metrics in the supplementary material. These demonstrate that the chosen grid resolution preserves controllability for non-trivial multi-shot motions without significant loss. We will add a concise reference to these analyses in the revised abstract. revision: partial
-
Referee: [Abstract] Abstract: no equations, derivations, ablation studies, or quantitative metrics are supplied to evaluate whether the million-scale training on grid-video pairs actually enables the claimed director-level control or outperforms parametric baselines on complex multi-shot cases.
Authors: Equations and derivations for the grid representation, multimodal diffusion integration, and hierarchical prompt agent are in Sections 3.1–3.4. Ablation studies on the grid encoding, million-scale training, and prompt harmonization are in Section 5.2. Quantitative comparisons to parametric baselines on complex multi-shot scenarios, including controllability metrics, are reported in Tables 1–3 and Figures 3–5. The dataset scale and training procedure are detailed in Section 4.1. We will update the abstract to better highlight these evaluations. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces a grid-based camera motion representation and a diffusion framework trained on external-scale data pairs, with no equations, fitted predictions, or self-citations presented as load-bearing derivations. Claims rest on empirical training and a novel representation without reducing to self-definition or renamed inputs. This matches the common case of a methods paper whose central contributions are independent of the listed circularity patterns.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 4 Pith papers
-
OmniDrive: An LLM-Choreographed Multi-Agent World Model with Unified Latent Co-Compression for Multi-View Driving Video Generation
DRIVE-CHOREO uses three LLM agents to create a unified position-aware token sequence co-compressed with multi-view video, achieving SOTA BEV mAP of 21.6 and +2.4 NDS improvement on nuScenes.
-
OrthoMotion:Disentangling Camera and Subject Motion via Geometry Semantics Orthogonal Attention
OrthoMotion disentangles camera and subject motion in video generation by splitting attention into algebraically complementary geometric (RoPE rotation) and semantic (gated value) channels driven to orthogonality by a...
-
ParaScale: Scale-Calibrated Camera-Motion Transfer via a Gauge-Invariant Parallax Number
ParaScale extracts a gauge-invariant Parallax Number from a reference video and re-realizes the same parallax against the target scene's depth map to achieve scale-calibrated camera motion transfer.
-
TRIDENT: Breaking the Hybrid-Safety-Physics Coupling for Provably Safe Multi-Agent Reinforcement Learning
TRIDENT is a MARL framework using Richardson-Romberg gradient correction, Lyapunov-constrained trust-region updates, and a physics-informed residual critic that claims O(1/sqrt(K)) convergence to constrained Nash equi...
Reference graph
Works this paper leans on
-
[1]
2026 , eprint=
ARGUS: Stacked Multi-View Identity Mosaic Injection for Subject-Preserving Video Generation , author=. 2026 , eprint=
2026
-
[2]
Lin, Haotong and Chen, Sili and Liew, Junhao and Chen, Donny Y and Li, Zhenyu and Shi, Guang and Feng, Jiashi and Kang, Bingyi , journal=
-
[3]
Ho, Jonathan and Chan, William and Saharia, Chitwan and Whang, Jay and Gao, Ruiqi and Gritsenko, Alexey and Kingma, Diederik P and Poole, Ben and Norouzi, Mohammad and Fleet, David J and others , journal=
-
[4]
Wang, Xiang and Yuan, Hangjie and Zhang, Shiwei and Chen, Dayou and Wang, Jiuniu and Zhang, Yingya and Shen, Yujun and Zhao, Deli and Zhou, Jingren , journal=
-
[5]
Blattmann, Andreas and Dockhorn, Tim and Kulal, Sumith and Mendelevitch, Daniel and Kilian, Maciej and Lorenz, Dominik and Levi, Yam and English, Zion and Voleti, Vikram and Letts, Adam and others , journal=
-
[6]
Zheng, Zangwei and Peng, Xiangyu and Yang, Tianji and Shen, Chenhui and Li, Shenggui and Liu, Hongxin and Zhou, Yukun and Li, Tianyi and You, Yang , journal=
-
[7]
Ma, Xin and Wang, Yaohui and Chen, Xinyuan and Jia, Gengyun and Liu, Ziwei and Li, Yuan-Fang and Chen, Cunjian and Qiao, Yu , journal=
-
[8]
ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Make a Game: A Novel Paradigm for Interactive Game Rendering , author=. ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2026 , organization=
2026
-
[9]
Ma, Yue and He, Yingqing and Wang, Hongfa and Wang, Andong and Shen, Leqi and Qi, Chenyang and Ying, Jixuan and Cai, Chengfei and Li, Zhifeng and Shum, Heung-Yeung and others , booktitle=
-
[10]
Lin, Han and Zala, Abhay and Cho, Jaemin and Bansal, Mohit , booktitle=
-
[11]
Bar-Tal, Omer and Chefer, Hila and Tov, Omer and Herrmann, Charles and Paiss, Roni and Zada, Shiran and Ephrat, Ariel and Hur, Junhwa and Liu, Guanghui and Raj, Amit and others , booktitle=
-
[12]
Ren, Weiming and Yang, Huan and Zhang, Ge and Wei, Cong and Du, Xinrun and Huang, Wenhao and Chen, Wenhu , journal=
-
[13]
Chen, Xinyuan and Wang, Yaohui and Zhang, Lingjun and Zhuang, Shaobin and Ma, Xin and Yu, Jiashuo and Wang, Yali and Lin, Dahua and Qiao, Yu and Liu, Ziwei , booktitle=
-
[14]
2024 , organization=
Xing, Jinbo and Xia, Menghan and Zhang, Yong and Chen, Haoxin and Yu, Wangbo and Liu, Hanyuan and Liu, Gongye and Wang, Xintao and Shan, Ying and Wong, Tien-Tsin , booktitle=. 2024 , organization=
2024
-
[15]
Zhang, Shiwei and Wang, Jiayu and Zhang, Yingya and Zhao, Kang and Yuan, Hangjie and Qin, Zhiwu and Wang, Xiang and Zhao, Deli and Zhou, Jingren , journal=
-
[16]
Chen, Weifeng and Ji, Yatai and Wu, Jie and Wu, Hefeng and Xie, Pan and Li, Jiashi and Xia, Xin and Xiao, Xuefeng and Lin, Liang , journal=
-
[17]
Zhang, Yabo and Wei, Yuxiang and ZHANG, XIAOPENG and Zuo, Wangmeng and Tian, Qi and others , booktitle=
-
[18]
Mou, Chong and Wang, Xintao and Xie, Liangbin and Wu, Yanze and Zhang, Jian and Qi, Zhongang and Shan, Ying , booktitle=
-
[19]
Zhang, Lvmin and Rao, Anyi and Agrawala, Maneesh , booktitle=
-
[20]
Polyak, Adam and Zohar, Amit and Brown, Andrew and Tjandra, Andros and Sinha, Animesh and Lee, Ann and Vyas, Apoorv and Shi, Bowen and Ma, Chih-Yao and Chuang, Ching-Yao and others , journal=
-
[21]
Peebles, William and Xie, Saining , booktitle=
-
[22]
Forty-first international conference on machine learning , year=
Esser, Patrick and Kulal, Sumith and Blattmann, Andreas and Entezari, Rahim and M. Forty-first international conference on machine learning , year=
-
[23]
Tim Brooks and Bill Peebles and Connor Holmes and Will DePue and Yufei Guo and Li Jing and David Schnurr and Joe Taylor and Troy Luhman and Eric Luhman and Clarence Ng and Ricky Wang and Aditya Ramesh , year=
-
[24]
Wu, Xiaoxue and Gao, Bingjie and Qiao, Yu and Wang, Yaohui and Chen, Xinyuan , journal=
-
[25]
IEEE transactions on pattern analysis and machine intelligence , volume=
A generic camera model and calibration method for conventional, wide-angle, and fish-eye lenses , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2006 , publisher=
2006
-
[26]
2023 , organization=
Villegas, R and Moraldo, H and Castro, S and Babaeizadeh, M and Zhang, H and Kunze, J and Kindermans, PJ and Saffar, MT and Erhan, D , booktitle=. 2023 , organization=
2023
-
[27]
Singer, Uriel and Polyak, Adam and Hayes, Thomas and Yin, Xi and An, Jie and Zhang, Songyang and Hu, Qiyuan and Yang, Harry and Ashual, Oron and Gafni, Oran and others , journal=
-
[28]
Ho, Jonathan and Salimans, Tim and Gritsenko, Alexey and Chan, William and Norouzi, Mohammad and Fleet, David J , journal=
-
[29]
HaCohen, Yoav and Brazowski, Benny and Chiprut, Nisan and Bitterman, Yaki and Kvochko, Andrew and Berkowitz, Avishai and Shalem, Daniel and Lifschitz, Daphna and Moshe, Dudu and Porat, Eitan and Richardson, Eitan and Guy Shiran and Itay Chachy and Jonathan Chetboun and Michael Finkelson and Michael Kupchick and Nir Zabari and Nitzan Guetta and Noa Kotler ...
-
[30]
Luo, Yawen and Shi, Xiaoyu and Bai, Jianhong and Xia, Menghan and Xue, Tianfan and Wang, Xintao and Wan, Pengfei and Zhang, Di and Gai, Kun , booktitle=
-
[31]
Bai, Jianhong and Xia, Menghan and Fu, Xiao and Wang, Xintao and Mu, Lianrui and Cao, Jinwen and Liu, Zuozhu and Hu, Haoji and Bai, Xiang and Wan, Pengfei and others , booktitle=
-
[32]
Ho, Jonathan and Jain, Ajay and Abbeel, Pieter , journal=
-
[33]
2026 International Conference on 3D Vision (3DV) , pages=
Keetha, Nikhil and M. 2026 International Conference on 3D Vision (3DV) , pages=. 2026 , organization=
2026
-
[34]
2025 , publisher=
Yu, Wangbo and Xing, Jinbo and Yuan, Li and Hu, Wenbo and Li, Xiaoyu and Huang, Zhipeng and Gao, Xiangjun and Wong, Tien-Tsin and Shan, Ying and Tian, Yonghong , journal=. 2025 , publisher=
2025
-
[35]
He, Hao and Yang, Ceyuan and Lin, Shanchuan and Xu, Yinghao and Wei, Meng and Gui, Liangke and Zhao, Qi and Wetzstein, Gordon and Jiang, Lu and Li, Hongsheng , booktitle=
-
[36]
Li, Xinyang and Lai, Zhangyu and Xu, Linning and Qu, Yansong and Cao, Liujuan and Zhang, Shengchuan and Dai, Bo and Ji, Rongrong , journal=
-
[37]
Bai, Shuai and Cai, Yuxuan and Chen, Ruizhe and Chen, Keqin and Chen, Xionghui and Cheng, Zesen and Deng, Lianghao and Ding, Wei and Gao, Chang and Ge, Chunjiang and others , journal=
-
[38]
Guo, Yuwei and Yang, Ceyuan and Rao, Anyi and Liang, Zhengyang and Wang, Yaohui and Qiao, Yu and Agrawala, Maneesh and Lin, Dahua and Dai, Bo , journal=
-
[39]
Kong, Weijie and Tian, Qi and Zhang, Zijian and Min, Rox and Dai, Zuozhuo and Zhou, Jin and Xiong, Jiangfeng and Li, Xin and Wu, Bo and Zhang, Jianwei and others , journal=
-
[40]
Zheng, Guangcong and Li, Teng and Jiang, Rui and Lu, Yehao and Wu, Tao and Li, Xi , journal=
-
[41]
Xu, Dejia and Nie, Weili and Liu, Chao and Liu, Sifei and Kautz, Jan and Wang, Zhangyang and Vahdat, Arash , journal=
-
[42]
2024 , organization=
Girdhar, Rohit and Singh, Mannat and Brown, Andrew and Duval, Quentin and Azadi, Samaneh and Rambhatla, Sai Saketh and Shah, Akbar and Yin, Xi and Parikh, Devi and Misra, Ishan , booktitle=. 2024 , organization=
2024
-
[43]
Chen, Haoxin and Zhang, Yong and Cun, Xiaodong and Xia, Menghan and Wang, Xintao and Weng, Chao and Shan, Ying , booktitle=
-
[44]
Yin, Shengming and Wu, Chenfei and Liang, Jian and Shi, Jie and Li, Houqiang and Ming, Gong and Duan, Nan , journal=
-
[45]
2024 , organization=
Zhao, Rui and Gu, Yuchao and Wu, Jay Zhangjie and Zhang, David Junhao and Liu, Jia-Wei and Wu, Weijia and Keppo, Jussi and Shou, Mike Zheng , booktitle=. 2024 , organization=
2024
-
[46]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Soucek, Tom. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[47]
Seedance, Team and Chen, De and Chen, Liyang and Chen, Xin and Chen, Ying and Chen, Zhuo and Chen, Zhuowei and Cheng, Feng and Cheng, Tianheng and Cheng, Yufeng and others , journal=
-
[48]
Hu, Teng and Zhang, Jiangning and Yi, Ran and Wang, Yating and Huang, Hongrui and Weng, Jieyu and Wang, Yabiao and Ma, Lizhuang , journal=
-
[49]
Ling, Pengyang and Bu, Jiazi and Zhang, Pan and Dong, Xiaoyi and Zang, Yuhang and Wu, Tong and Chen, Huaian and Wang, Jiaqi and Jin, Yi , journal=
-
[50]
Bahmani, Sherwin and Skorokhodov, Ivan and Qian, Guocheng and Siarohin, Aliaksandr and Menapace, Willi and Tagliasacchi, Andrea and Lindell, David B and Tulyakov, Sergey , booktitle=
-
[51]
Wang, Zhouxia and Yuan, Ziyang and Wang, Xintao and Li, Yaowei and Chen, Tianshui and Xia, Menghan and Luo, Ping and Shan, Ying , booktitle=
-
[52]
Huang, Ziqi and He, Yinan and Yu, Jiashuo and Zhang, Fan and Si, Chenyang and Jiang, Yuming and Zhang, Yuanhan and Wu, Tianxing and Jin, Qingyang and Chanpaisit, Nattapol and others , booktitle=
-
[53]
2025 , publisher=
Huang, Ziqi and Zhang, Fan and Xu, Xiaojie and He, Yinan and Yu, Jiashuo and Dong, Ziyue and Ma, Qianli and Chanpaisit, Nattapol and Si, Chenyang and Jiang, Yuming and others , journal=. 2025 , publisher=
2025
-
[54]
He, Hao and Xu, Yinghao and Guo, Yuwei and Wetzstein, Gordon and Dai, Bo and Li, Hongsheng and Yang, Ceyuan , journal=
-
[55]
Wang, Qinghe and Shi, Xiaoyu and Li, Baolu and Bian, Weikang and Liu, Quande and Lu, Huchuan and Wang, Xintao and Wan, Pengfei and Gai, Kun and Jia, Xu , booktitle=
-
[56]
Wang, Qinghe and Luo, Yawen and Shi, Xiaoyu and Jia, Xu and Lu, Huchuan and Xue, Tianfan and Wang, Xintao and Wan, Pengfei and Zhang, Di and Gai, Kun , booktitle=
-
[57]
Luo, Yawen and Shi, Xiaoyu and Zhuang, Junhao and Chen, Yutian and Liu, Quande and Wang, Xintao and Wan, Pengfei and Xue, Tianfan , journal=
-
[58]
B.; and Tulyakov, S
Bahmani, S.; Skorokhodov, I.; Qian, G.; Siarohin, A.; Menapace, W.; Tagliasacchi, A.; Lindell, D. B.; and Tulyakov, S. 2025. AC3D: Analyzing and Improving 3D Camera Control in Video Diffusion Transformers . In Proceedings of the Computer Vision and Pattern Recognition Conference, 22875--22889
2025
-
[59]
Bai, J.; Xia, M.; Fu, X.; Wang, X.; Mu, L.; Cao, J.; Liu, Z.; Hu, H.; Bai, X.; Wan, P.; et al. 2025 a . ReCamMaster: Camera-Controlled Generative Rendering from A Single Video . In Proceedings of the IEEE/CVF International Conference on Computer Vision, 14834--14844
2025
-
[60]
Bai, S.; Cai, Y.; Chen, R.; Chen, K.; Chen, X.; Cheng, Z.; Deng, L.; Ding, W.; Gao, C.; Ge, C.; et al. 2025 b . Qwen3-VL Technical Report . arXiv preprint arXiv:2511.21631
Pith/arXiv arXiv 2025
-
[61]
Bar-Tal, O.; Chefer, H.; Tov, O.; Herrmann, C.; Paiss, R.; Zada, S.; Ephrat, A.; Hur, J.; Liu, G.; Raj, A.; et al. 2024. Lumiere: A Space-Time Diffusion Model for Video Generation . In SIGGRAPH Asia 2024 Conference Papers, 1--11
2024
-
[62]
Blattmann, A.; Dockhorn, T.; Kulal, S.; Mendelevitch, D.; Kilian, M.; Lorenz, D.; Levi, Y.; English, Z.; Voleti, V.; Letts, A.; et al. 2023. Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets . arXiv preprint arXiv:2311.15127
Pith/arXiv arXiv 2023
-
[63]
Chen, H.; Zhang, Y.; Cun, X.; Xia, M.; Wang, X.; Weng, C.; and Shan, Y. 2024. VideoCrafter2: Overcoming Data Limitations for High-Quality Video Diffusion Models . In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 7310--7320
2024
-
[64]
Chen, W.; Ji, Y.; Wu, J.; Wu, H.; Xie, P.; Li, J.; Xia, X.; Xiao, X.; and Lin, L. 2023 a . Control-A-Video: Controllable Text-to-Video Diffusion Models with Motion Prior and Reward Feedback Learning . arXiv preprint arXiv:2305.13840
arXiv 2023
-
[65]
Chen, X.; Wang, Y.; Zhang, L.; Zhuang, S.; Ma, X.; Yu, J.; Wang, Y.; Lin, D.; Qiao, Y.; and Liu, Z. 2023 b . Seine: Short-to-Long Video Diffusion Model for Generative Transition and Prediction . In The Twelfth International Conference on Learning Representations
2023
-
[66]
Cseti. 2024. LTX2.3-22B\_IC-LoRA-Cameraman\_v1 . https://huggingface.co/Cseti/LTX2.3-22B_IC-LoRA-Cameraman_v1. Hugging Face Model Repository
2024
-
[67]
Esser, P.; Kulal, S.; Blattmann, A.; Entezari, R.; M \"u ller, J.; Saini, H.; Levi, Y.; Lorenz, D.; Sauer, A.; Boesel, F.; et al. 2024. Scaling Rectified Flow Transformers for High-Resolution Image Synthesis . In Forty-first international conference on machine learning
2024
-
[68]
S.; Shah, A.; Yin, X.; Parikh, D.; and Misra, I
Girdhar, R.; Singh, M.; Brown, A.; Duval, Q.; Azadi, S.; Rambhatla, S. S.; Shah, A.; Yin, X.; Parikh, D.; and Misra, I. 2024. Factorizing Text-to-Video Generation by Explicit Image Conditioning . In European Conference on Computer Vision, 205--224. Springer
2024
-
[69]
Guo, Y.; Yang, C.; Rao, A.; Liang, Z.; Wang, Y.; Qiao, Y.; Agrawala, M.; Lin, D.; and Dai, B. 2023. AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning . arXiv preprint arXiv:2307.04725
Pith/arXiv arXiv 2023
-
[70]
HaCohen, Y.; Brazowski, B.; Chiprut, N.; Bitterman, Y.; Kvochko, A.; Berkowitz, A.; Shalem, D.; Lifschitz, D.; Moshe, D.; Porat, E.; Richardson, E.; Shiran, G.; Chachy, I.; Chetboun, J.; Finkelson, M.; Kupchick, M.; Zabari, N.; Guetta, N.; Kotler, N.; Bibi, O.; Gordon, O.; Panet, P.; Benita, R.; Armon, S.; Kulikov, V.; Inger, Y.; Shiftan, Y.; Melumian, Z....
Pith/arXiv arXiv 2025
-
[71]
He, H.; Xu, Y.; Guo, Y.; Wetzstein, G.; Dai, B.; Li, H.; and Yang, C. 2024. CameraCtrl: Enabling Camera Control for Text-to-Video Generation . arXiv preprint arXiv:2404.02101
Pith/arXiv arXiv 2024
-
[72]
He, H.; Yang, C.; Lin, S.; Xu, Y.; Wei, M.; Gui, L.; Zhao, Q.; Wetzstein, G.; Jiang, L.; and Li, H. 2025. CameraCtrl II: Dynamic Scene Exploration via Camera-Controlled Video Diffusion Models . In Proceedings of the IEEE/CVF International Conference on Computer Vision, 13416--13426
2025
-
[73]
P.; Poole, B.; Norouzi, M.; Fleet, D
Ho, J.; Chan, W.; Saharia, C.; Whang, J.; Gao, R.; Gritsenko, A.; Kingma, D. P.; Poole, B.; Norouzi, M.; Fleet, D. J.; et al. 2022 a . Imagen Video: High Definition Video Generation with Diffusion Models . arXiv preprint arXiv:2210.02303
Pith/arXiv arXiv 2022
-
[74]
Ho, J.; Jain, A.; and Abbeel, P. 2020. Denoising Diffusion Probabilistic Models . Advances in neural information processing systems, 33: 6840--6851
2020
-
[75]
Ho, J.; Salimans, T.; Gritsenko, A.; Chan, W.; Norouzi, M.; and Fleet, D. J. 2022 b . Video Diffusion Models . Advances in neural information processing systems, 35: 8633--8646
2022
-
[76]
Hu, L. 2024. Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation . In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 8153--8163
2024
-
[77]
Hu, T.; Zhang, J.; Yi, R.; Wang, Y.; Huang, H.; Weng, J.; Wang, Y.; and Ma, L. 2024. MotionMaster: Training-Free Camera Motion Transfer for Video Generation . arXiv preprint arXiv:2404.15789
arXiv 2024
-
[78]
Kannala, J.; and Brandt, S. S. 2006. A generic camera model and calibration method for conventional, wide-angle, and fish-eye lenses. IEEE transactions on pattern analysis and machine intelligence, 28(8): 1335--1340
2006
-
[79]
u ller, N.; Sch \
Keetha, N.; M \"u ller, N.; Sch \"o nberger, J.; Porzi, L.; Zhang, Y.; Fischer, T.; Knapitsch, A.; Zauss, D.; Weber, E.; Antunes, N.; et al. 2026. MapAnything: Universal Feed-Forward Metric 3D Reconstruction . In 2026 International Conference on 3D Vision (3DV), 499--509. IEEE
2026
-
[80]
Li, X.; Lai, Z.; Xu, L.; Qu, Y.; Cao, L.; Zhang, S.; Dai, B.; and Ji, R. 2024. Director3D: Real-World Camera Trajectory and 3D Scene Generation from Text . Advances in neural information processing systems, 37: 75125--75151
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.