Frequency-Aware Flow Matching for Continuous and Consistent Robotic Action Generation
Pith reviewed 2026-06-26 17:15 UTC · model grok-4.3
The pith
Frequency-Aware Flow Matching produces continuous and temporally consistent robotic actions by operating in the DCT domain with derivative regularization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
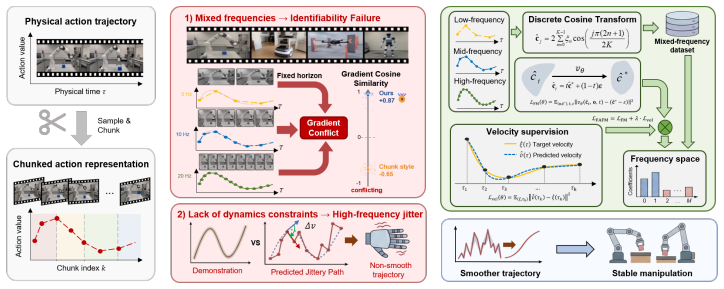
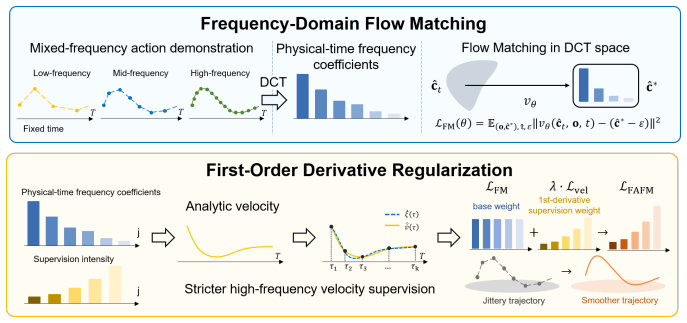
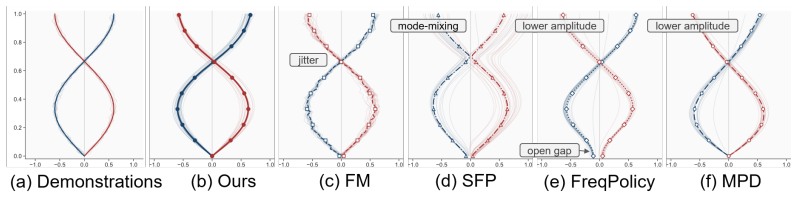
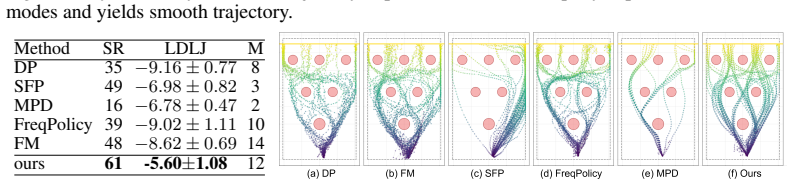
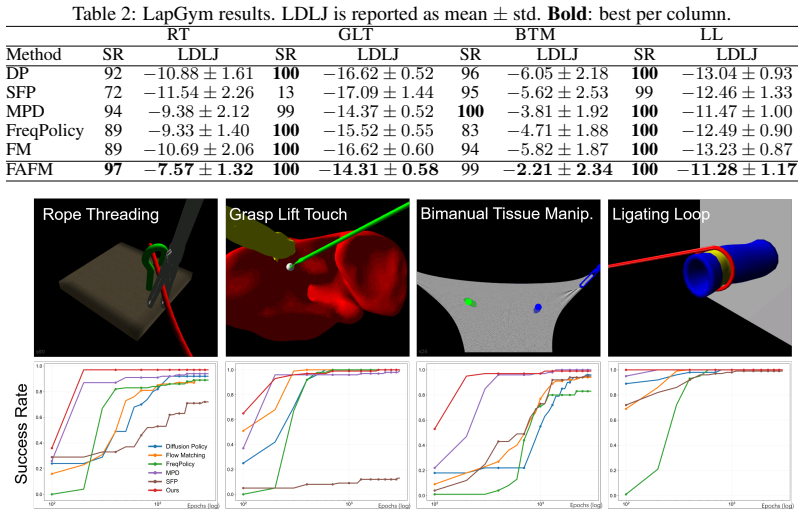
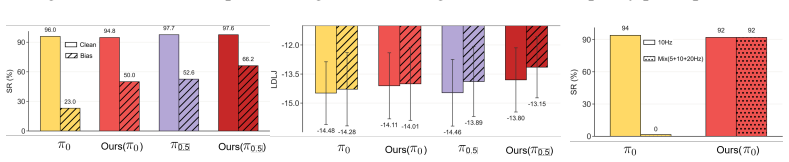
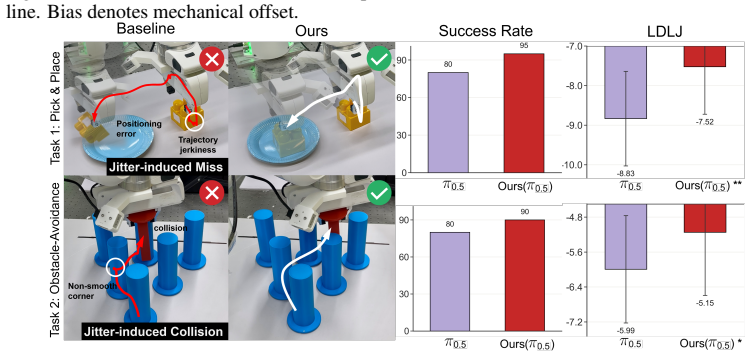
FAFM transforms discrete action sequences into the frequency domain with the discrete cosine transform, performs flow matching over the resulting coefficients, and reconstructs continuous actions via cosine basis expansion. It further regularizes the first-order temporal derivative to enforce a Sobolev-type constraint that suppresses high-frequency errors. This yields continuous, temporally consistent actions without any additional network parameters and improves success rates, multimodal expressivity, motion smoothness, convergence speed, and robustness to mechanical bias and mixed-frequency input across synthetic, simulation, and real Franka benchmarks.
What carries the argument
Discrete cosine transform of action sequences followed by flow matching on the coefficients and first-order temporal derivative regularization.
If this is right
- Success rates increase on obstacle avoidance, LapGym, and LIBERO benchmarks while preserving multimodal action distributions.
- Actions remain consistent under mixed-frequency training data and mechanical bias without post-hoc filtering.
- The same architecture works for both standalone flow-matching policies and vision-language action models.
- Real-world deployment on a Franka robot shows the same gains in smoothness and task completion as in simulation.
- No extra parameters are introduced, so training and inference cost stay identical to the base flow matcher.
Where Pith is reading between the lines
- The frequency-domain formulation could let policies trained on one robot's control rate transfer more readily to robots with different sampling rates.
- Because the Sobolev penalty acts only on the output coefficients, it might combine with existing safety filters without retraining the policy network.
- If the DCT basis proves stable for long-horizon tasks, the method could reduce the need for separate temporal smoothing modules in closed-loop control.
Load-bearing premise
That applying the discrete cosine transform to action sequences and adding a first-order temporal derivative regularizer will reliably produce the claimed gains in continuity, consistency, and benchmark performance without hidden costs to expressivity or stability.
What would settle it
A controlled comparison on a new task with high-frequency action content where FAFM either matches or underperforms a standard flow-matching baseline in success rate or measured jerk.
Figures

read the original abstract
Flow matching has emerged as a standard paradigm for robotic manipulation owing to its strong expressive power for modelling complex, multimodal action distributions, alongside similar approaches like diffusion policy. However, existing methods rely on discretized action chunks, making them brittle to demonstrations collected at heterogeneous control frequencies and prone to temporally inconsistent actions that degrade control stability. In this paper, we propose Frequency-Aware Flow Matching (FAFM), which outputs continuous, temporally consistent actions. To handle heterogeneous frequency input, we transform discrete action sequences into the frequency domain with the discrete cosine transform (DCT), perform flow matching over the resulting coefficients, and reconstruct continuous actions via cosine basis expansion. To generate temporally consistent actions, we regularize the first-order temporal derivative to promote smooth actions. This corresponds to a Sobolev-type constraint that suppresses high-frequency errors and discourages abrupt action changes. Our FAFM is simple, introduces no additional network parameters and applies to standalone flow-matching policies and vision-language action models. Across synthetic toy benchmark, obstacle avoidance, LapGym, and LIBERO, FAFM improves success rates, multimodal expressivity, motion smoothness, convergence speed, robustness to mechanical bias and mixed-frequency input. These gains are consistent when deployed on a real-world Franka robot. Code available at https://anonymous.4open.science/r/FAFM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Frequency-Aware Flow Matching (FAFM) for robotic action generation. Discrete action sequences are transformed via the discrete cosine transform (DCT) into frequency-domain coefficients on which flow matching is performed; continuous actions are then reconstructed by cosine basis expansion. A first-order temporal derivative regularizer (Sobolev-type constraint) is added to suppress high-frequency errors and enforce temporal smoothness. The method is presented as parameter-free and applicable to both standalone flow-matching policies and vision-language action models. Empirical claims include gains in success rate, multimodal expressivity, motion smoothness, convergence speed, robustness to mechanical bias and mixed-frequency inputs across synthetic, obstacle-avoidance, LapGym, LIBERO, and real Franka benchmarks.
Significance. If the central empirical claims hold, the work supplies a lightweight, frequency-domain construction that directly mitigates two practical weaknesses of chunked flow-matching and diffusion policies—heterogeneous control frequencies and temporal inconsistency—while preserving or improving expressivity. The absence of extra network parameters and the explicit handling of continuous-time reconstruction are strengths that could transfer to other sequence-generation settings in robotics.
major comments (1)
- [Method description of regularization and frequency-domain flow matching] The dual claim that the DCT-based flow matching plus first-order temporal regularizer simultaneously increases multimodal expressivity and motion smoothness is load-bearing for the paper’s contribution. The abstract asserts both gains without hidden cost, yet the skeptic concern is valid: no derivation, mode-coverage metric, or ablation is referenced showing that the Sobolev constraint does not attenuate high-frequency modes required for certain multimodal action distributions. A concrete test (e.g., comparison of learned distribution support or number of recovered modes with/without the regularizer) is needed before the expressivity improvement can be accepted.
minor comments (2)
- [Abstract] The code link is given as an anonymous repository; a permanent, non-anonymous link or explicit reproducibility instructions should be added.
- [Experiments] Tables reporting benchmark results should include standard deviations or statistical tests so that the magnitude of reported gains can be assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and commit to revisions that directly respond to the concern raised.
read point-by-point responses
-
Referee: The dual claim that the DCT-based flow matching plus first-order temporal regularizer simultaneously increases multimodal expressivity and motion smoothness is load-bearing for the paper’s contribution. The abstract asserts both gains without hidden cost, yet the skeptic concern is valid: no derivation, mode-coverage metric, or ablation is referenced showing that the Sobolev constraint does not attenuate high-frequency modes required for certain multimodal action distributions. A concrete test (e.g., comparison of learned distribution support or number of recovered modes with/without the regularizer) is needed before the expressivity improvement can be accepted.
Authors: We acknowledge that the interaction between the Sobolev regularizer and multimodal expressivity requires explicit verification. The regularizer penalizes the first-order temporal derivative of the reconstructed trajectory after cosine basis expansion, which primarily suppresses discretization-induced high-frequency noise rather than limiting the frequency coefficients that the flow-matching model learns in the DCT domain. Our reported gains in success rate on multimodal tasks provide indirect support, but we agree a direct test is needed. In the revised manuscript we will add an ablation on the synthetic benchmark that compares learned distribution support (via sampled trajectory diversity and a simple mode-counting procedure) with and without the regularizer, together with a brief note on why the frequency-domain formulation preserves expressivity. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents FAFM as an explicit technical construction: DCT transformation of action sequences, flow matching on frequency coefficients, cosine reconstruction, and addition of a first-order temporal derivative regularizer. These steps are defined directly in the method and do not reduce any claimed output (continuous actions, consistency, or benchmark gains) to a fitted parameter or self-citation by construction. Empirical improvements are reported from experiments on benchmarks and real deployment rather than derived tautologically. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the abstract or described construction. This matches the default case of a self-contained technical proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Discrete cosine transform provides a suitable basis for representing and reconstructing discrete action sequences.
Reference graph
Works this paper leans on
-
[1]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations
-
[2]
Qiang Liu. Rectified flow: A marginal preserving approach to optimal transport.arXiv preprint arXiv:2209.14577, 2022
Pith/arXiv arXiv 2022
-
[3]
π0: A vision-language-action flow model for general robot control.eprint arXiv: 2410.24164, 2024
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.eprint arXiv: 2410.24164, 2024
Pith/arXiv arXiv 2024
-
[4]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π_0.5: a vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[5]
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
Pith/arXiv arXiv 2025
-
[6]
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274, 2025
Pith/arXiv arXiv 2025
-
[7]
Kaidong Zhang, Jian Zhang, Rongtao Xu, Yu Sun, Shuoshuo Xue, Youpeng Wen, Xiaoyu Guo, Minghao Guo, Weijia Liufu, Liu Zihou, et al. A1: A fully transparent open-source, adaptive and efficient truncated vision-language-action model.arXiv preprint arXiv:2604.05672, 2026
Pith/arXiv arXiv 2026
-
[8]
Gr-3 technical report.arXiv preprint arXiv:2507.15493, 2025
Chilam Cheang, Sijin Chen, Zhongren Cui, Yingdong Hu, Liqun Huang, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Xiao Ma, et al. Gr-3 technical report.arXiv preprint arXiv:2507.15493, 2025
Pith/arXiv arXiv 2025
-
[9]
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
Pith/arXiv arXiv 2023
-
[10]
Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[11]
Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[12]
Movement primitive diffusion: Learning gentle robotic manipulation of deformable objects.IEEE Robotics and Automation Letters, 9(6):5338–5345, 2024
Paul Maria Scheikl, Nicolas Schreiber, Christoph Haas, Niklas Freymuth, Gerhard Neumann, Rudolf Lioutikov, and Franziska Mathis-Ullrich. Movement primitive diffusion: Learning gentle robotic manipulation of deformable objects.IEEE Robotics and Automation Letters, 9(6):5338–5345, 2024
2024
-
[13]
Flowmp: Learning motion fields for robot planning with conditional flow matching
Khang Nguyen, An T Le, Tien Pham, Manfred Huber, Jan Peters, and Minh Nhat Vu. Flowmp: Learning motion fields for robot planning with conditional flow matching. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11291–11297. IEEE, 2025. 11
2025
-
[14]
Fan Yang, Peiguang Jing, Kaihua Qu, Ningyuan Zhao, and Yuting Su. Abpolicy: Asyn- chronous b-spline flow policy for real-time and smooth robotic manipulation.arXiv preprint arXiv:2602.23901, 2026
arXiv 2026
-
[15]
Au- tonomy in surgical robotics.Annual Review of Control, Robotics, and Autonomous Systems, 4(1):651–679, 2021
Aleks Attanasio, Bruno Scaglioni, Elena De Momi, Paolo Fiorini, and Pietro Valdastri. Au- tonomy in surgical robotics.Annual Review of Control, Robotics, and Autonomous Systems, 4(1):651–679, 2021
2021
-
[16]
Discrete cosine transform.IEEE transactions on Computers, 100(1):90–93, 1974
Nasir Ahmed, T_ Natarajan, and Kamisetty R Rao. Discrete cosine transform.IEEE transactions on Computers, 100(1):90–93, 1974
1974
-
[17]
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
Pith/arXiv arXiv 2025
-
[18]
Lapgym-an open source framework for reinforce- ment learning in robot-assisted laparoscopic surgery.Journal of Machine Learning Research, 24(368):1–42, 2023
Paul Maria Scheikl, Bal ˘A ˛ Azs Gyenes, Rayan Younis, Christoph Haas, Gerhard Neumann, Martin Wagner, and Franziska Mathis-Ullrich. Lapgym-an open source framework for reinforce- ment learning in robot-assisted laparoscopic surgery.Journal of Machine Learning Research, 24(368):1–42, 2023
2023
-
[19]
Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[20]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[21]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[22]
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
Pith/arXiv arXiv 2011
-
[23]
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via sidle 3d representations.arXiv preprint arXiv:2403.03954, 2024
Pith/arXiv arXiv 2024
-
[24]
Se (3)-diffusionfields: Learning smooth cost functions for joint grasp and motion optimization through diffusion
Julen Urain, Niklas Funk, Jan Peters, and Georgia Chalvatzaki. Se (3)-diffusionfields: Learning smooth cost functions for joint grasp and motion optimization through diffusion. In2023 IEEE international conference on robotics and automation (ICRA), pages 5923–5930. IEEE, 2023
2023
-
[25]
Moritz Reuss, Maximilian Li, Xiaogang Jia, and Rudolf Lioutikov. Goal-conditioned imitation learning using score-based diffusion policies.arXiv preprint arXiv:2304.02532, 2023
arXiv 2023
-
[26]
Equivariant diffusion policy.arXiv preprint arXiv:2407.01812, 2024
Dian Wang, Stephen Hart, David Surovik, Tarik Kelestemur, Haojie Huang, Haibo Zhao, Mark Yeatman, Jiuguang Wang, Robin Walters, and Robert Platt. Equivariant diffusion policy.arXiv preprint arXiv:2407.01812, 2024
arXiv 2024
-
[27]
Affordance-based robot manipulation with flow matching
Fan Zhang and Michael Gienger. Affordance-based robot manipulation with flow matching. arXiv preprint arXiv:2409.01083, 2024
arXiv 2024
-
[28]
Flowpolicy: Enabling fast and robust 3d flow-based policy via consistency flow matching for robot manipulation
Qinglun Zhang, Zhen Liu, Haoqiang Fan, Guanghui Liu, Bing Zeng, and Shuaicheng Liu. Flowpolicy: Enabling fast and robust 3d flow-based policy via consistency flow matching for robot manipulation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 14754–14762, 2025
2025
-
[29]
Flow as the cross-domain manipulation interface.arXiv preprint arXiv:2407.15208, 2024
Mengda Xu, Zhenjia Xu, Yinghao Xu, Cheng Chi, Gordon Wetzstein, Manuela Veloso, and Shu- ran Song. Flow as the cross-domain manipulation interface.arXiv preprint arXiv:2407.15208, 2024
arXiv 2024
-
[30]
Riemannian flow matching policy for robot motion learning
Max Braun, Noémie Jaquier, Leonel Rozo, and Tamim Asfour. Riemannian flow matching policy for robot motion learning. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5144–5151. IEEE, 2024. 12
2024
-
[31]
Acg: Action coherence guidance for flow-based vla models.arXiv preprint arXiv:2510.22201, 2025
Minho Park, Kinam Kim, Junha Hyung, Hyojin Jang, Hoiyeong Jin, Jooyeol Yun, Hojoon Lee, and Jaegul Choo. Acg: Action coherence guidance for flow-based vla models.arXiv preprint arXiv:2510.22201, 2025
arXiv 2025
-
[32]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[33]
Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[34]
Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[35]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
Pith/arXiv arXiv 2024
-
[36]
Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
Pith/arXiv arXiv 2024
-
[37]
Dexgraspvla: A vision-language-action framework towards general dexterous grasping
Yifan Zhong, Xuchuan Huang, Ruochong Li, Ceyao Zhang, Zhang Chen, Tianrui Guan, Fanlian Zeng, Ka Nam Lui, Yuyao Ye, Yitao Liang, et al. Dexgraspvla: A vision-language-action framework towards general dexterous grasping. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18836–18844, 2026
2026
-
[38]
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[39]
π∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al. π∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
Pith/arXiv arXiv 2025
-
[40]
Physical Intelligence, Bo Ai, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Greg Balke, Kevin Black, George Bokinsky, Shihao Cao, Thomas Charbonnier, et al. π0.7: a steerable gen- eralist robotic foundation model with emergent capabilities.arXiv preprint arXiv:2604.15483, 2026
Pith/arXiv arXiv 2026
-
[41]
Haoyun Liu, Jianzhuang Zhao, Xinyuan Chang, Tianle Shi, Chuanzhang Meng, Jiayuan Tan, Feng Xiong, Tong Lin, Dongjie Huo, Mu Xu, et al. Neural implicit action fields: From discrete waypoints to continuous functions for vision-language-action models.arXiv preprint arXiv:2603.01766, 2026
Pith/arXiv arXiv 2026
-
[42]
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[43]
Xirui Shi and Jun Jin. Frmd: Fast robot motion diffusion with consistency-distilled movement primitives for smooth action generation.arXiv preprint arXiv:2503.02048, 2025
arXiv 2025
-
[44]
Prodmp: A unified perspective on dynamic and probabilistic movement primitives.IEEE Robotics and Automation Letters, 8(4):2325–2332, 2023
Ge Li, Zeqi Jin, Michael V olpp, Fabian Otto, Rudolf Lioutikov, and Gerhard Neumann. Prodmp: A unified perspective on dynamic and probabilistic movement primitives.IEEE Robotics and Automation Letters, 8(4):2325–2332, 2023
2023
-
[45]
Yiming Zhong, Yumeng Liu, Chuyang Xiao, Zemin Yang, Youzhuo Wang, Yufei Zhu, Ye Shi, Yujing Sun, Xinge Zhu, and Yuexin Ma. Freqpolicy: Frequency autoregressive visuomotor policy with continuous tokens.arXiv preprint arXiv:2506.01583, 2025. 13
arXiv 2025
-
[46]
Sunshine Jiang, Xiaolin Fang, Nicholas Roy, Tomás Lozano-Pérez, Leslie Pack Kaelbling, and Siddharth Ancha. Streaming flow policy: Simplifying diffusion/flow-matching policies by treating action trajectories as flow trajectories.arXiv preprint arXiv:2505.21851, 2025
arXiv 2025
-
[47]
The discrete cosine transform.SIAM review, 41(1):135–147, 1999
Gilbert Strang. The discrete cosine transform.SIAM review, 41(1):135–147, 1999
1999
-
[48]
Motion smooth- ness metrics for cannulation skill assessment: What factors matter?Frontiers in Robotics and AI, 8:625003, 2021
Simar Singh, Joe Bible, Zhanhe Liu, Ziyang Zhang, and Ravikiran Singapogu. Motion smooth- ness metrics for cannulation skill assessment: What factors matter?Frontiers in Robotics and AI, 8:625003, 2021
2021
-
[49]
A new approach to laparoscopic skill assessment: Motion smoothness and bimanual coordination.Laparoscopic, Endoscopic and Robotic Surgery, 8(2):90–95, 2025
Farzad Aghazadeh and Bin Zheng. A new approach to laparoscopic skill assessment: Motion smoothness and bimanual coordination.Laparoscopic, Endoscopic and Robotic Surgery, 8(2):90–95, 2025
2025
-
[50]
Ariel Rodriguez, Lorenzo Mazza, Martin Lelis, Rayan Younis, Sebastian Bodenstedt, Martin Wagner, and Stefanie Speidel. An open-source robotics research platform for autonomous laparoscopic surgery.arXiv preprint arXiv:2603.08490, 2026. 14 A Proof of Proposition 1 Proof. Fix (o, k) and write Y=ξ(k/f)·1{k < K(ξ, f)} for the regression target restricted to t...
arXiv 2026
-
[51]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.