Learning to Prompt: Improving Student Engagement with Adaptive LLM-based High-School Tutoring
Pith reviewed 2026-06-26 17:45 UTC · model grok-4.3
The pith
An adaptive LLM tutoring system using a stochastic prompt router raises exercise conversion to 28.1 percent and shortens sessions by three turns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
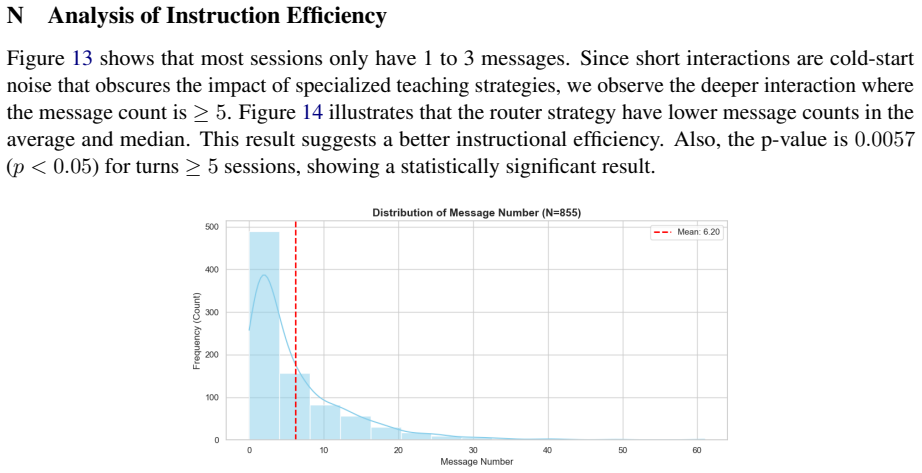
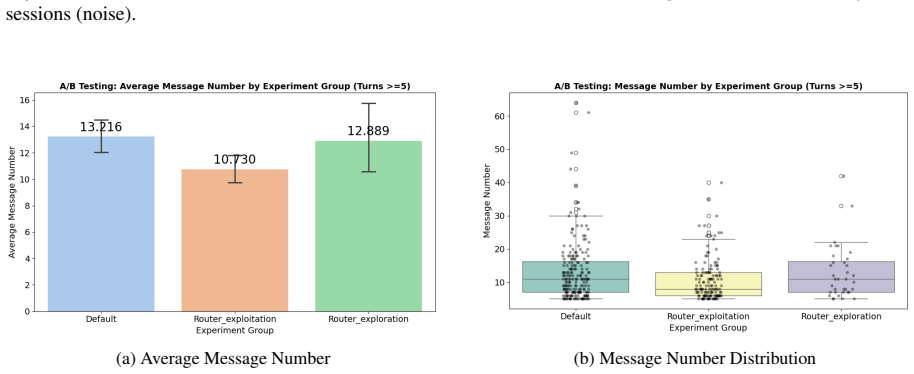
A prompt routing model trained in simulation and deployed adaptively achieves sim-to-real transfer by switching from analytical to scaffolding strategies; the adaptive selection improves instructional efficiency by reducing interactions by around 3 turns while a stochastic router raises exercise conversion rate to 28.1 percent compared with 19.6 percent for the baseline.
What carries the argument
The stochastic router that samples from pedagogical strategies informed by 14 features extracted from raw transcripts.
Load-bearing premise
The simulation environment used to train the router accurately captures the distribution of real student responses and engagement patterns that occur in live high-school tutoring sessions.
What would settle it
An A/B test that keeps the same interface and student pool but replaces the learned router with random strategy selection and finds no difference in conversion rate or turn count would falsify the claim that the trained routing drives the gains.
Figures

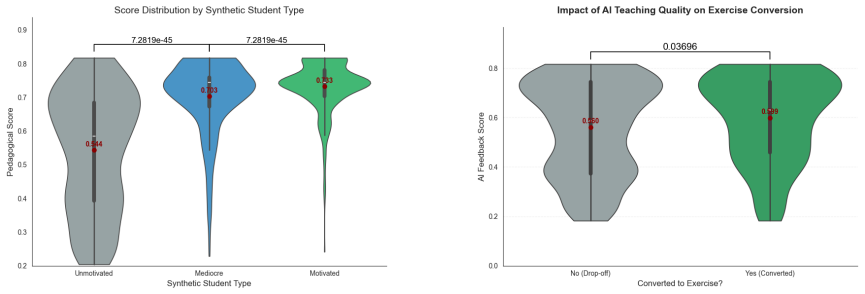
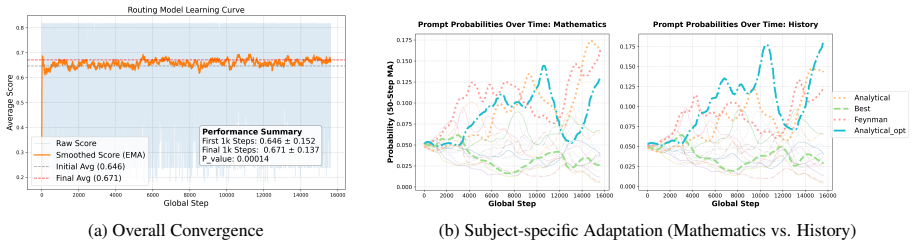
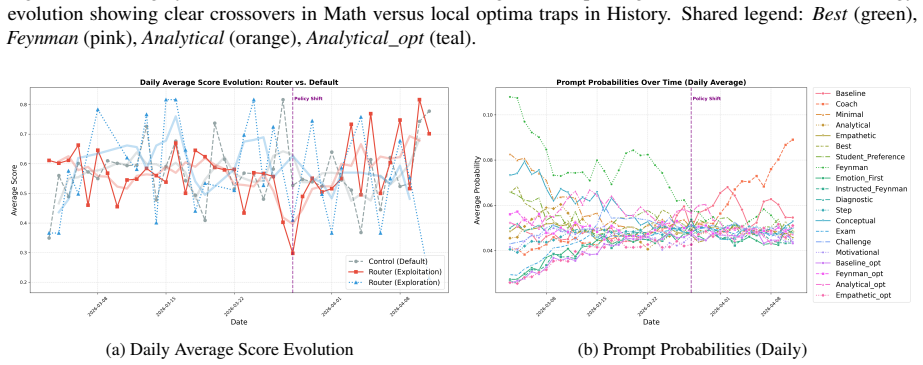
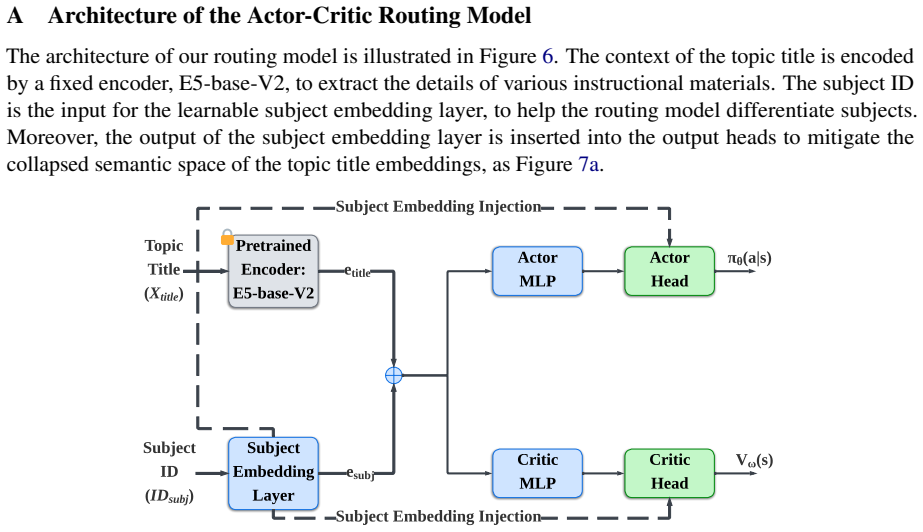



read the original abstract
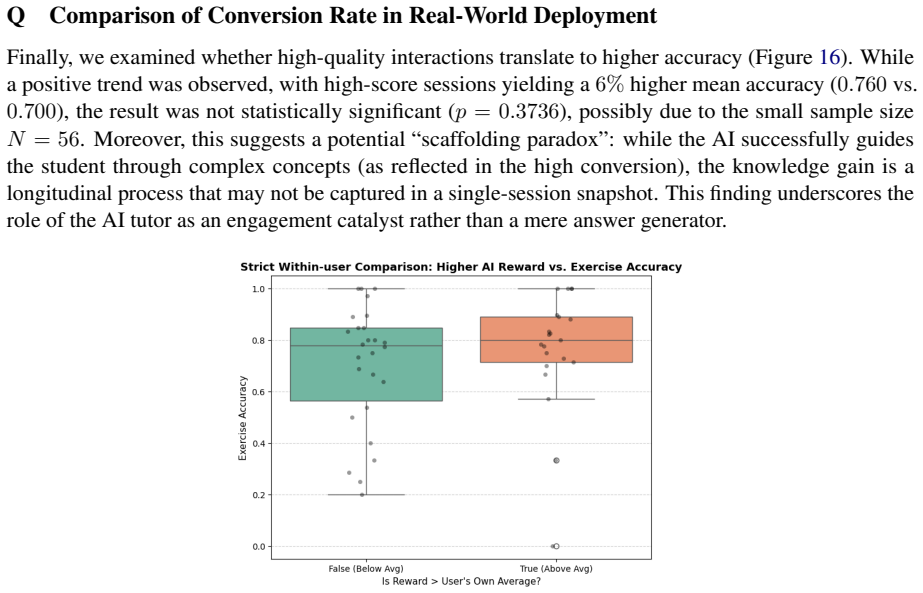
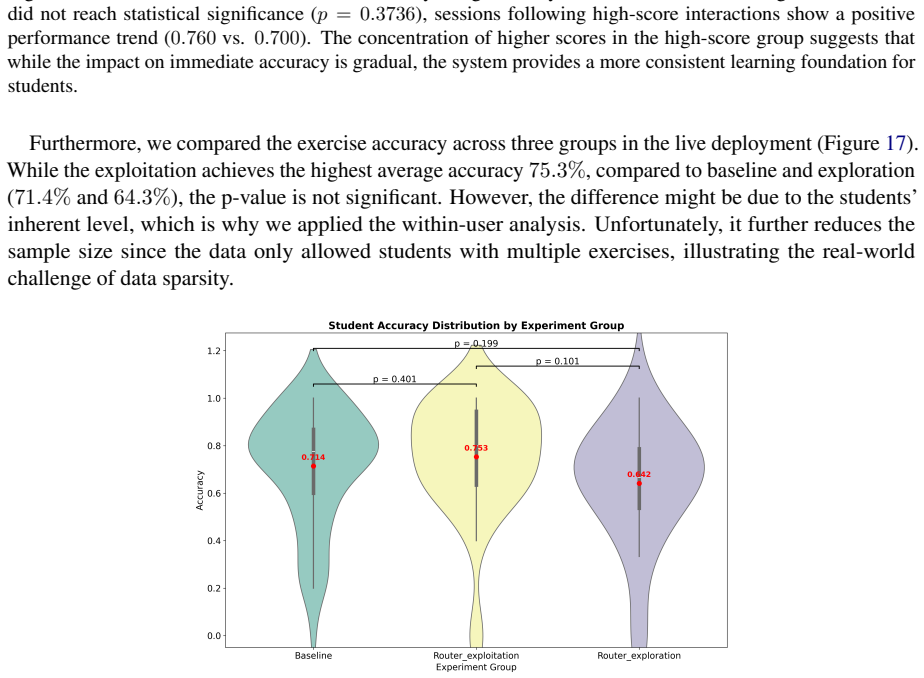
LLMs can personalize education, although current static-prompt tutoring systems struggle to adapt to diverse academic disciplines. We develop and test a system with subject-aware prompting, based on 14 pedagogical features (e.g., tutor scaffolding, student understanding) extracted from raw transcripts. We first train a prompt routing model in a simulation environment, and then deploy it for online adaptation with actual high-school students. The simulation benchmark shows the router outperforming two static baselines ($0.694$ vs. $0.647$ and $0.64$, $p<0.001$). A/B testing ($N=656$ conversations from 359 students) shows sim-to-real transfer where the model switches from analytical to scaffolding learning strategies. Our adaptive prompt selection mechanism improves instructional efficiency, maintains pedagogical quality and reduces interactions by around 3 turns ($p=0.007$). While a greedy router achieves a comparable exercise conversion rate with the baseline ($19.1\%$ vs. $19.6\%$), a stochastic router that samples strategies leads to a higher conversion rate ($28.1\%$).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that an LLM tutoring system using 14 pedagogical features extracted from transcripts, with a prompt router trained in simulation and deployed adaptively, outperforms static baselines in simulation (0.694 vs. 0.647/0.64, p<0.001) and yields higher exercise conversion (28.1% for stochastic router) plus ~3 fewer turns (p=0.007) in an A/B test of 656 conversations from 359 high-school students.
Significance. If the sim-to-real transfer holds, the work provides evidence that stochastic routing among pedagogical strategies can improve instructional efficiency in live LLM tutoring while preserving quality. The real-student A/B test with hundreds of participants is a methodological strength that supports potential applicability to high-school settings.
major comments (3)
- [Simulation environment section] Simulation environment section: the router is trained exclusively in simulation before deployment, yet no quantitative sim-to-real diagnostics (feature distribution distances, response-model calibration error, or variance in student understanding) are reported; this assumption is load-bearing for the reported 28.1% conversion rate and p=0.007 result.
- [A/B testing results paragraph] A/B testing results paragraph: the manuscript provides no detail on validation of the 14 features, the router training procedure, or whether baseline prompts were matched for length and style, leaving the central claim that the adaptive system reduces interactions by ~3 turns dependent on unshown methods.
- [Methods section on feature extraction] Methods section on feature extraction: the claim that the 14 features (e.g., tutor scaffolding, student understanding) enable subject-aware prompting rests on their extraction from raw transcripts, but no evidence is given that these features were validated against real student engagement patterns.
minor comments (1)
- [Abstract] Abstract: the N=656 conversations figure is stated but the split between conditions is not given, which would aid interpretation of the conversion-rate comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of methodological transparency and sim-to-real transfer. We respond to each major comment below.
read point-by-point responses
-
Referee: [Simulation environment section] Simulation environment section: the router is trained exclusively in simulation before deployment, yet no quantitative sim-to-real diagnostics (feature distribution distances, response-model calibration error, or variance in student understanding) are reported; this assumption is load-bearing for the reported 28.1% conversion rate and p=0.007 result.
Authors: We agree that quantitative sim-to-real diagnostics strengthen the transfer claims. In the revised manuscript we will add feature distribution comparisons (e.g., Wasserstein distances) between simulation and real transcripts, plus any available response-model calibration metrics. This directly addresses the load-bearing assumption for the deployment results. revision: yes
-
Referee: [A/B testing results paragraph] A/B testing results paragraph: the manuscript provides no detail on validation of the 14 features, the router training procedure, or whether baseline prompts were matched for length and style, leaving the central claim that the adaptive system reduces interactions by ~3 turns dependent on unshown methods.
Authors: We will expand the Methods and results sections to detail the 14-feature validation approach, the full router training procedure (including simulation hyperparameters and data generation), and explicit confirmation that baseline prompts were matched for length and stylistic tone. These additions will make the ~3-turn reduction claim fully supported by documented methods. revision: yes
-
Referee: [Methods section on feature extraction] Methods section on feature extraction: the claim that the 14 features (e.g., tutor scaffolding, student understanding) enable subject-aware prompting rests on their extraction from raw transcripts, but no evidence is given that these features were validated against real student engagement patterns.
Authors: The features were selected from pedagogical literature and implemented via LLM classifiers on transcripts. Their effectiveness is evidenced by the A/B test outcomes (higher conversion, shorter dialogues). We will add a dedicated paragraph on feature selection rationale and any post-hoc engagement correlations in the revision; a separate pre-deployment validation study was not performed. revision: partial
Circularity Check
No circularity: empirical results from independent sim training and real A/B test
full rationale
The paper reports training a router in a simulation environment followed by deployment and A/B testing on real students (N=359). No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims (conversion rates, turn reduction) rest on separate empirical measurements rather than reducing to inputs by construction. This is a standard non-circular empirical ML paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
From problem-solving to teaching problem- solving: Aligning LLMs with pedagogy using re- inforcement learning. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 272–292, Suzhou, China. Association for Computational Linguistics. Jun Gao, Di He, Xu Tan, Tao Qin, Liwei Wang, and Tie- Yan Liu. 2019. Representati...
-
[2]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267. Pankaj Singh. 2026. Querywise prompt routing for large language models.International Journal of Research and Innovation in Social Science, 10(19):605–611. Prasann Singhal, Tanya Goyal, Jiacheng Xu, and Greg Durrett. 2024. A long way to go: Investigating length correlations in rlhf. Joar Skalse, Nik...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Large Language Models as Optimizers
Large language models as optimizers. volume abs/2309.03409. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. In Proceedings of the 37th International Conference on ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
(False if fewer than two or off-topic)
Answer ≥ 2 questions: The user answers two or more questions posed by the assistant about the main topic. (False if fewer than two or off-topic)
-
[5]
(Exclude generic greetings)
Ask ≥ 2 on-topic questions: The user asks two or more questions (why, how, what, when) connected to the topic. (Exclude generic greetings)
-
[6]
thank you
Interact > 3 times: The user sends four or more substantive messages containing reasoning or topic-related inquiry. 4.Positive social exchanges: The user expresses positivity (e.g., “thank you”, emojis) at least twice
-
[7]
Answers mostly correct: The user’s responses align with explanations in most cases with few clear mistakes
-
[8]
Correct within 2 turns: The user provides a correct response within two attempts at least 75% of the time when prompted
-
[9]
Shows understanding: Relevant responses and follow-up questions demonstrate comprehension without repeated confusion
-
[10]
why” or “how
Shows curiosity: Asks at least one question that goes beyond basic requirements (explores “why” or “how”)
-
[11]
10.Assistant on topic: The assistant remains focused on the learning goal throughout the interaction
Justifies mistakes: After an error, the user either reflects on the reasoning or provides a corrected answer later. 10.Assistant on topic: The assistant remains focused on the learning goal throughout the interaction
-
[12]
(False if gives full answers immediately)
Assistant scaffolding: The tutor offers progressive, multi-turn guidance and adjusts help level when the student struggles. (False if gives full answers immediately). 12.Assistant diagnoses: The assistant identifies specific mistakes and provides tailored clarifications
-
[13]
Assistant balances: The assistant alternates between explaining and prompting, avoiding a monologue-style delivery
-
[14]
Empirical Best Prompt
Assistant adapts: The tutor changes behavior (e.g., more explanation after mistakes) based on student performance. I Pedagogical Criteria Weighting To ensure the AI feedback signal aligns with human pedagogical judgment, we correlated the 14 LLM- extracted features against an expert-labeled dataset (N= 138 ). Human experts evaluated sessions and label it ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.