Path-dependent program induction under resource constraints explains human sequence learning
Pith reviewed 2026-06-29 17:42 UTC · model grok-4.3
The pith
Hierarchical libraries under memory and computation constraints explain human sequence learning as path-dependent program induction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A hierarchical Adaptor Grammar with local and global libraries, jointly constrained by memory and computation, formalizes path-dependent program induction and accounts for human sequence learning, as evidenced by matching recall errors to systematic simplifications, reaction times to inferred boundaries, and superior fits to individual differences over alternative models.
What carries the argument
Hierarchical Adaptor Grammar (HAG) with distinct local (within-task) and global (across-task) libraries governed jointly by constraints on memory and computation; it makes some future structures cheaper to encode based on the order of prior experience.
If this is right
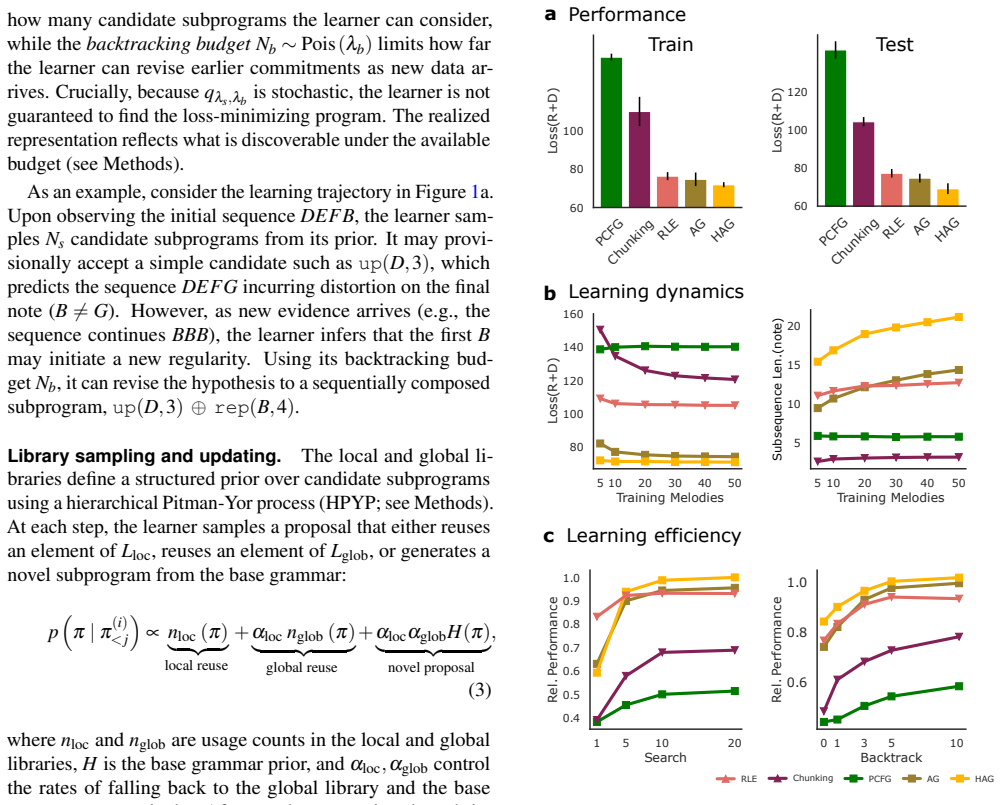
- Simulations demonstrate better rate-distortion trade-offs and stronger generalization than fixed grammars or shallow chunking methods.
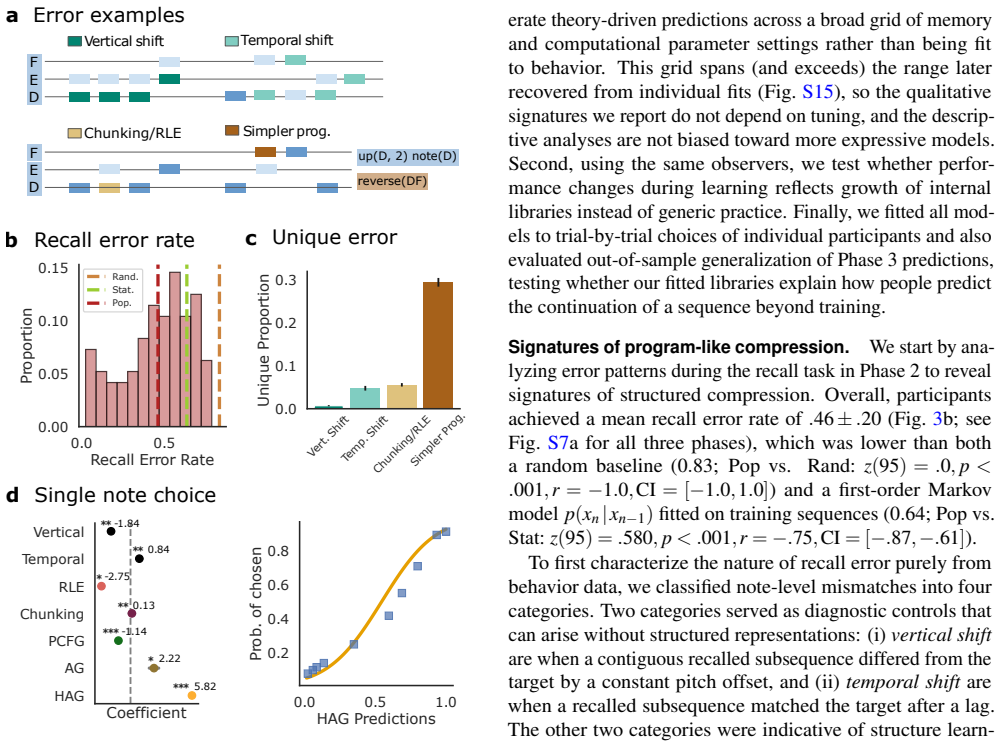
- Recall errors in the melodic task reflect systematic simplifications predicted by the model.
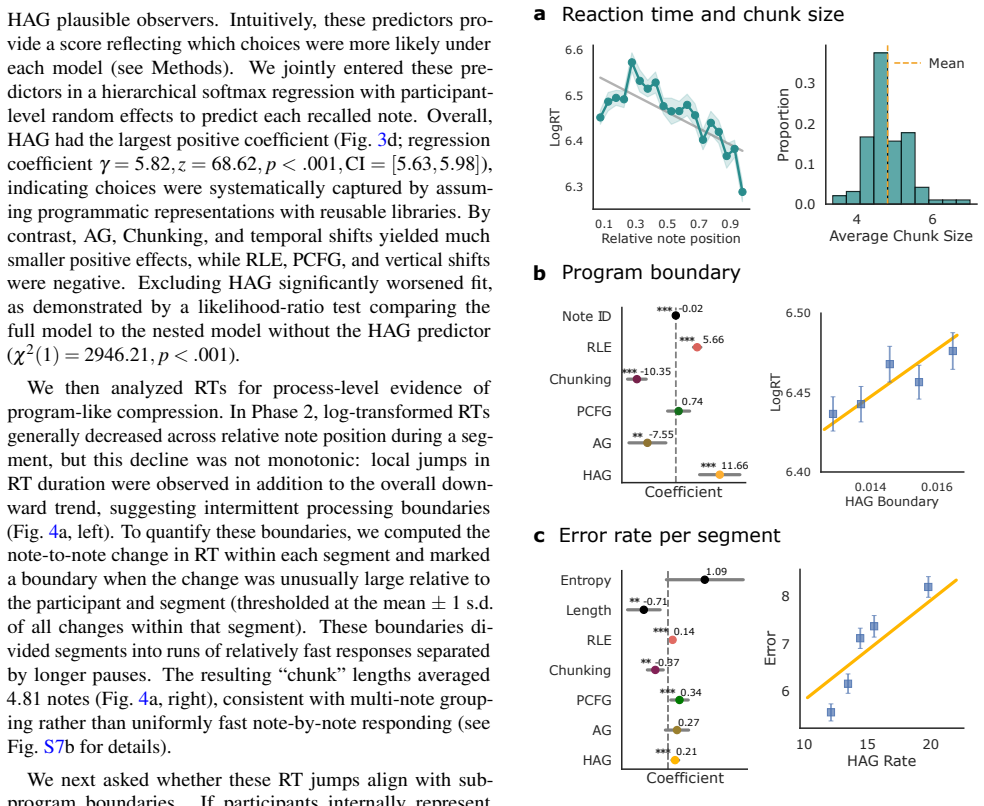
- Reaction times increase at the boundaries of programs inferred by the hierarchical grammar.
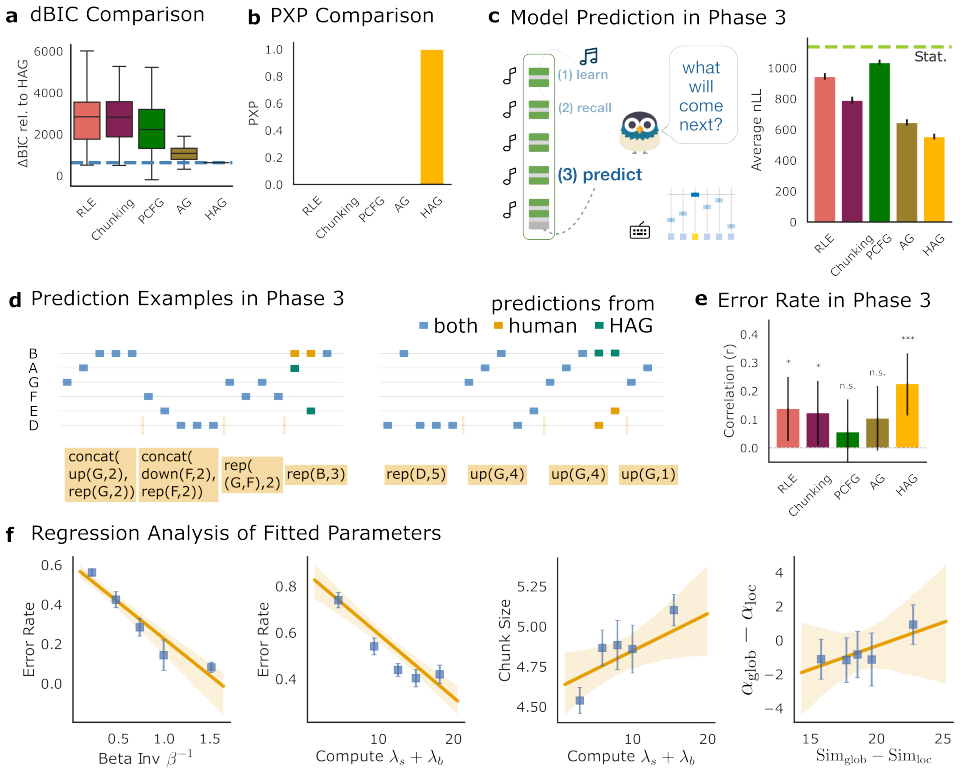
- Hierarchical libraries best explain individual differences in both recall accuracy and out-of-sample continuation choices.
Where Pith is reading between the lines
- If the account holds, deliberately ordering the sequence of learning experiences could improve abstraction formation when memory and computation are limited.
- The same path-dependent mechanism could apply to other sequential domains such as acquiring syntax or motor skills.
- The model predicts specific performance breakdowns when the joint memory-computation constraint is exceeded, offering a way to test resource limits directly.
Load-bearing premise
Participants' recall errors and reaction times directly reflect the program boundaries and simplifications inferred by the specific HAG parameterization under local versus global libraries.
What would settle it
A new melodic sequence experiment in which human recall error patterns and reaction time increases fail to align with the specific program boundaries or simplifications predicted by the hierarchical model, or where non-hierarchical models fit the trial-by-trial data as well or better.
Figures

read the original abstract
How do people build abstract, reusable knowledge from sequential experience under bounded cognitive resources? To answer this question, we integrate rate-distortion theory with recent advances in program induction to describe how prior knowledge shapes which future structures are cheap to encode and easy to discover. We formalize this in a hierarchical Adaptor Grammar (HAG) with distinct local (within-task) and global (across-task) libraries, governed jointly by constraints on memory and computation. In simulations, HAG achieves better rate-distortion trade-offs and stronger generalization than fixed grammars or shallow chunking methods. In an online melodic sequence-learning experiment, participants' recall errors reflected systematic simplifications and reaction times increased at inferred program boundaries. Trial-by-trial fits further showed that hierarchical libraries best explained individual differences in both recall and out-of-sample continuation choices, outperforming all alternative models. These findings cast structured learning as bounded program induction in which the order of experience shapes future abstractions a learner builds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that human sequence learning arises from path-dependent program induction under joint memory and computation constraints, formalized as a hierarchical adaptor grammar (HAG) with distinct local and global libraries. Simulations demonstrate superior rate-distortion trade-offs relative to fixed grammars or shallow chunking; a melodic sequence-learning experiment shows that participants' recall errors reflect systematic simplifications, reaction times rise at inferred program boundaries, and trial-by-trial fits indicate that hierarchical libraries best account for individual differences in both recall and out-of-sample continuation choices.
Significance. If the model-comparison results hold after fuller methodological disclosure, the work supplies a unified computational account that links rate-distortion theory, program induction, and resource bounds to explain how sequential experience shapes reusable abstractions, offering a concrete alternative to purely statistical or chunk-based models of structured learning.
major comments (2)
- [Abstract; human-experiment results section] The abstract and the description of the trial-by-trial fits provide no information on how the two free parameters (memory and computation constraints) are estimated, what data-exclusion criteria were applied, or whether error bars reflect participant or model variability; without these details the claim that HAG outperforms alternatives cannot be evaluated for robustness.
- [Trial-by-trial fits paragraph] Model selection and explanatory claims both rely on fits to the same recall and continuation data; although continuation is described as out-of-sample, the absence of an explicit held-out partition or pre-registered cross-validation procedure leaves open the possibility that the reported superiority of hierarchical libraries partly reflects the fitting process itself rather than independent predictive success.
minor comments (1)
- All model-comparison figures should include participant-level variability or bootstrap intervals and should label the exact number of free parameters used for each alternative model.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on methodological transparency. We address each point below and will revise the manuscript to improve clarity on parameter estimation, data handling, and the out-of-sample evaluation.
read point-by-point responses
-
Referee: [Abstract; human-experiment results section] The abstract and the description of the trial-by-trial fits provide no information on how the two free parameters (memory and computation constraints) are estimated, what data-exclusion criteria were applied, or whether error bars reflect participant or model variability; without these details the claim that HAG outperforms alternatives cannot be evaluated for robustness.
Authors: We agree that these details are necessary to evaluate robustness. In the revised manuscript we will add a methods subsection describing how the memory and computation constraints were estimated (grid search over a discrete range of values, with the combination maximizing recall likelihood selected per participant), the data-exclusion criteria (participants removed if they failed attention checks or completed fewer than 80% of trials), and that all reported error bars are standard errors across participants. These additions will allow direct assessment of the model-comparison results. revision: yes
-
Referee: [Trial-by-trial fits paragraph] Model selection and explanatory claims both rely on fits to the same recall and continuation data; although continuation is described as out-of-sample, the absence of an explicit held-out partition or pre-registered cross-validation procedure leaves open the possibility that the reported superiority of hierarchical libraries partly reflects the fitting process itself rather than independent predictive success.
Authors: The continuation choices were held out from parameter estimation; models were fit only to recall data and then evaluated on continuation without refitting. We acknowledge, however, that the manuscript does not explicitly describe the partition or any validation steps. We will revise the text to state the exact held-out procedure (last block of trials per participant reserved for continuation) and note that the split was determined by experimental design rather than pre-registration. If the data permit, we will also report a supplementary cross-validation check to further substantiate the predictive claims. revision: partial
Circularity Check
No significant circularity identified
full rationale
The abstract and described claims rest on rate-distortion integration into HAG, simulations demonstrating superior trade-offs, and empirical model comparison with out-of-sample continuation choices. No quoted equations or steps reduce by construction to inputs, self-citations, or fitted parameters renamed as predictions. Trial-by-trial fits against alternatives with explicit out-of-sample elements constitute standard validation rather than circular reduction. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- memory constraint parameter
- computation constraint parameter
axioms (2)
- domain assumption Human sequence learning proceeds via program induction that can be formalized with adaptor grammars
- domain assumption Rate-distortion theory provides the correct formalization of bounded cognitive resources for abstraction
Reference graph
Works this paper leans on
-
[1]
S., Tenenbaum, J
Rule, J. S., Tenenbaum, J. B. & Piantadosi, S. T. The child as hacker.Trends Cogn. Sci.24, 900–915 (2020)
2020
-
[2]
& Sablé-Meyer, M
Dehaene, S., Al Roumi, F., Lakretz, Y ., Planton, S. & Sablé-Meyer, M. Symbols and mental programs: a hy- pothesis about human singularity.Trends Cogn. Sci.26, 751–766 (2022)
2022
-
[3]
B., Kemp, C., Griffiths, T
Tenenbaum, J. B., Kemp, C., Griffiths, T. L. & Goodman, N. D. How to grow a mind: Statistics, structure, and abstraction.science331, 1279–1285 (2011)
2011
-
[4]
M., Salakhutdinov, R
Lake, B. M., Salakhutdinov, R. & Tenenbaum, J. B. Human-level concept learning through probabilistic pro- gram induction.Science350, 1332–1338 (2015)
2015
-
[5]
& Gerstenberg, T
Goodman, N., Tenenbaum, J. & Gerstenberg, T. Concepts in a probabilistic language of thought (tech. rep.).Cent. for Brains, Minds Mach. (CBMM)(2014)
2014
-
[6]
C., Jacobs, R
Overlan, M. C., Jacobs, R. A. & Piantadosi, S. T. Learn- ing abstract visual concepts via probabilistic program induction in a language of thought.Cognition168, 320– 334 (2017)
2017
-
[7]
& Lake, B
Zhou, Y ., Feinman, R. & Lake, B. M. Compositional di- versity in visual concept learning.Cognition244, 105711 (2024)
2024
-
[8]
& Tenenbaum, J
Tian, L., Ellis, K., Kryven, M. & Tenenbaum, J. Learning abstract structure for drawing by efficient motor program induction.Adv. Neural Inf. Process. Syst.33, 2686–2697 (2020)
2020
-
[9]
T., Goodman, N., Ellis, B
Piantadosi, S. T., Goodman, N., Ellis, B. A. & Tenen- baum, J. A bayesian model of the acquisition of compo- sitional semantics. InProceedings of the thirtieth annual conference of the cognitive science society, 1620–1625 (Cognitive Science Society Washington DC, 2008)
2008
-
[10]
Piantadosi, S. T. & Jacobs, R. A. Four problems solved by the probabilistic language of thought.Curr. Dir. Psychol. Sci.25, 54–59 (2016)
2016
-
[11]
Ellis, K., Albright, A., Solar-Lezama, A., Tenenbaum, J. B. & O’Donnell, T. J. Synthesizing theories of hu- man language with bayesian program induction.Nat. communications13, 5024 (2022)
2022
-
[12]
Sharma, S., Curtis, A., Kryven, M., Tenenbaum, J. & Fiete, I. Map induction: Compositional spatial submap learning for efficient exploration in novel environments. arXiv preprint arXiv:2110.12301(2021)
-
[13]
Correa, C. G., Griffiths, T. L. & Daw, N. D. Program- based strategy induction for reinforcement learning.arXiv preprint arXiv:2402.16668(2024)
-
[14]
Compositional process in music
Wiggins, J. Compositional process in music. InInterna- tional handbook of research in arts education, 453–476 (Springer, 2007)
2007
-
[15]
Harasim, D.The learnability of the grammar of jazz: Bayesian inference of hierarchical structures in harmony. Ph.D. thesis, EPFL (2020)
2020
-
[16]
& Ting, C.-K
Liu, C.-H. & Ting, C.-K. Computational intelligence in music composition: A survey.IEEE Transactions on Emerg. Top. Comput. Intell.1, 2–15 (2016). 19/32
2016
-
[17]
Nierhaus, G.Algorithmic composition: paradigms of automated music generation(Springer, 2009)
2009
-
[18]
Zhao, B., Lucas, C. G. & Bramley, N. R. A model of conceptual bootstrapping in human cognition.Nat. Hum. Behav.1–12 (2023)
2023
-
[19]
S.et al.Symbolic metaprogram search improves learning efficiency and explains rule learning in humans
Rule, J. S.et al.Symbolic metaprogram search improves learning efficiency and explains rule learning in humans. Nat. Commun.15, 6847 (2024)
2024
-
[20]
A.The Language of Thought(Harvard Univer- sity Press, 1975)
Fodor, J. A.The Language of Thought(Harvard Univer- sity Press, 1975)
1975
-
[21]
& Griffiths, T
Lieder, F. & Griffiths, T. L. Resource-rational analysis: Understanding human cognition as the optimal use of limited computational resources.Behav. brain sciences 43, e1 (2020)
2020
-
[22]
Simon, H. A. A behavioral model of rational choice.The quarterly journal economics99–118 (1955)
1955
-
[23]
Shannon, C. E. Coding theorems for a discrete source with a fidelity criterion.IRE Nat. Conv. Rec4, 1 (1959)
1959
-
[24]
Berger, T.Rate-distortion theory: A mathematical basis for data compression(Prentice-Hall, 1971)
1971
-
[25]
Gershman, S. J. The rational analysis of memory. In Oxford Handbook of Human Memory(Oxford University Press, Oxford, UK, 2021)
2021
-
[26]
Sims, C. R. Rate–distortion theory and human perception. Cognition152, 181–198 (2016)
2016
-
[27]
G., Török, B
Nagy, D. G., Török, B. & Orbán, G. Optimal forget- ting: Semantic compression of episodic memories.PLoS Comput. Biol.16, e1008367 (2020)
2020
-
[28]
Bates, C. J. & Jacobs, R. A. Efficient data compression in perception and perceptual memory.Psychol. Rev.127, 891 (2020)
2020
-
[29]
& Gershman, S
Bhui, R. & Gershman, S. J. Decision by sampling im- plements efficient coding of psychoeconomic functions. Psychol. Rev.125, 985 (2018)
2018
-
[30]
& Gershman, S
Lai, L. & Gershman, S. J. Policy compression: An in- formation bottleneck in action selection. InPsychology of Learning and Motivation, vol. 74, 195–232 (Elsevier, 2021)
2021
-
[31]
B., Otto, F
Dekker, R. B., Otto, F. & Summerfield, C. Curriculum learning for human compositional generalization.Proc. Natl. Acad. Sci.119, e2205582119 (2022)
2022
-
[32]
G., Orbán, G
Nagy, D. G., Orbán, G. & Wu, C. M. Adaptive compres- sion as a unifying framework for episodic and semantic memory.Nat. Rev. Psychol.1–15 (2025)
2025
-
[33]
Fränken, J.-P., Theodoropoulos, N. C. & Bramley, N. R. Algorithms of adaptation in inductive inference.Cogn. Psychol.137, 101506 (2022)
2022
-
[34]
Garcia-Valencia, S., Betancourt, A. & Lalinde-Pulido, J. G. Sequence generation using deep recurrent networks and embeddings: A study case in music.ArXiv e-prints abs/2012.0(2020). 2012.01231
-
[35]
Run-length encodings (corresp.).IEEE trans- actions on information theory12, 399–401 (1966)
Golomb, S. Run-length encodings (corresp.).IEEE trans- actions on information theory12, 399–401 (1966)
1966
-
[36]
Miller, G. A. The magical number seven, plus or minus two: Some limits on our capacity for processing informa- tion.Psychol. review63, 81 (1956)
1956
-
[37]
& Rabinovich, M
Fonollosa, J., Neftci, E. & Rabinovich, M. Learning of chunking sequences in cognition and behavior.PLoS computational biology11, e1004592 (2015)
2015
-
[38]
& Schulz, E
Wu, S., Éltet˝o, N., Dasgupta, I. & Schulz, E. Chunking as a rational solution to the speed–accuracy trade-off in a serial reaction time task.Sci. reports13, 7680 (2023)
2023
-
[39]
J.Productivity and reuse in language: A theory of linguistic computation and storage(MIT Press, 2015)
O’Donnell, T. J.Productivity and reuse in language: A theory of linguistic computation and storage(MIT Press, 2015)
2015
-
[40]
Liang, P., Jordan, M. I. & Klein, D. Learning programs: A hierarchical bayesian approach. InProceedings of the 27th international conference on machine learning (icml-10), 639–646 (2010)
2010
-
[41]
Shannon, C. E. & Weaver, W.The Mathematical Theory of Communication(University of Illinois Press, 1949)
1949
- [42]
-
[43]
A.et al.Universality and diversity in human song.Science366, eaax0868 (2019)
Mehr, S. A.et al.Universality and diversity in human song.Science366, eaax0868 (2019)
2019
-
[44]
& Wheatley, T
Sievers, B., Polansky, L., Casey, M. & Wheatley, T. Music and movement share a dynamic structure that supports universal expressions of emotion.Proc. national academy sciences110, 70–75 (2013)
2013
-
[45]
Fitch, W. T. & Martins, M. D. Hierarchical processing in music, language, and action: Lashley revisited.Annals New York Acad. Sci.1316, 87–104 (2014)
2014
-
[46]
E., Friston, K
Rigoux, L., Stephan, K. E., Friston, K. J. & Daunizeau, J. Bayesian model selection for group studies—revisited. Neuroimage84, 971–985 (2014)
2014
-
[47]
& Tenenbaum, J
Kemp, C. & Tenenbaum, J. B. The discovery of structural form.Proc. Natl. Acad. Sci.105, 10687–10692 (2008)
2008
-
[48]
S., Schulz, E., Piantadosi, S
Rule, J. S., Schulz, E., Piantadosi, S. T. & Tenenbaum, J. B. Learning list concepts through program induction. BioRxiv321505 (2018)
2018
-
[49]
InPro- ceedings of the 42nd ACM SIGPLAN Conference on Pro- gramming Language Design and Implementation, 835– 850 (2021)
Ellis, K.et al.Dreamcoder: Bootstrapping inductive pro- gram synthesis with wake-sleep library learning. InPro- ceedings of the 42nd ACM SIGPLAN Conference on Pro- gramming Language Design and Implementation, 835– 850 (2021)
2021
-
[50]
F., Konkle, T
Brady, T. F., Konkle, T. & Alvarez, G. A. Compression in visual working memory: using statistical regularities to form more efficient memory representations.J. Exp. Psychol. Gen.138, 487 (2009). 20/32
2009
-
[51]
& Griffiths, T
Reali, F. & Griffiths, T. L. The evolution of frequency distributions: Relating regularization to inductive bi- ases through iterated learning.Cognition111, 317–328 (2009)
2009
-
[52]
& Legendre, G
Culbertson, J., Smolensky, P. & Legendre, G. Learning biases predict a word order universal.Cognition122, 306–329 (2012)
2012
-
[53]
& Steyvers, M
Hemmer, P. & Steyvers, M. A bayesian account of re- constructive memory.Top. cognitive science1, 189–202 (2009)
2009
-
[54]
Lashley, K. S.et al. The problem of serial order in behavior, vol. 21 (Bobbs-Merrill Oxford, 1951)
1951
-
[55]
A., Cohen, R
Rosenbaum, D. A., Cohen, R. G., Jax, S. A., Weiss, D. J. & Van Der Wel, R. The problem of serial order in be- havior: Lashley’s legacy.Hum. movement science26, 525–554 (2007)
2007
-
[56]
& Hikosaka, O
Sakai, K., Kitaguchi, K. & Hikosaka, O. Chunking dur- ing human visuomotor sequence learning.Exp. brain research152, 229–242 (2003)
2003
-
[57]
Verwey, W. B. & Dronkert, Y . Practicing a structured continuous key-pressing task: Motor chunking or rhythm consolidation?J. motor behavior28, 71–79 (1996)
1996
-
[58]
& Collins, A
Xia, L. & Collins, A. G. Temporal and state abstractions for efficient learning, transfer, and composition in humans. Psychol. review128, 643 (2021)
2021
-
[59]
E., Nerb, J., Lehtinen, E
Ritter, F. E., Nerb, J., Lehtinen, E. & O’Shea, T. M.In order to learn: How the sequence of topics influences learning(Oxford University Press, 2007)
2007
-
[60]
Bruner, J. S. Organization of early skilled action.Child development1–11 (1973)
1973
-
[61]
& Viding, E
Dayan, P., Roiser, J. & Viding, E. The first steps on long marches: The costs of active observation. InPsychiatry Reborn: Biopsychosocial psychiatry in modern medicine, 213–228 (Oxford University Press, 2020)
2020
-
[62]
Lerdahl, F.Tonal pitch space(Oxford University Press, 2001)
2001
-
[63]
London, J.Hearing in time: Psychological aspects of musical meter(Oxford University Press, 2012)
2012
-
[64]
Music performance.Annu
Palmer, C. Music performance.Annu. review psychology 48, 115–138 (1997)
1997
-
[65]
Repp, B. H. Quantitative effects of global tempo on ex- pressive timing in music performance: Some perceptual evidence.Music. perception13, 39–57 (1995)
1995
-
[66]
Pearce, M. T. Statistical learning and probabilistic pre- diction in music cognition: mechanisms of stylistic en- culturation.Annals new York Acad. Sci.1423, 378–395 (2018)
2018
-
[67]
Zhou, H., Bamler, R., Wu, C. M. & Tejero-Cantero, Á. Predictive, scalable and interpretable knowledge tracing on structured domains. InThe Twelfth Interna- tional Conference on Learning Representations, DOI: 10.48550/arXiv.2403.13179 (2024)
-
[68]
Bowers, M.et al.Top-down synthesis for library learning. Proc. ACM on Program. Lang.7, 1182–1213 (2023)
2023
-
[69]
Rubino, V ., Dayan, P. & Wu, C. M. Simplicity guides the discovery and use of compositionality.PsyArXivDOI: 10.31234/osf.io/25pha_v1 (2026)
-
[70]
& Goldwater, S
Johnson, M., Griffiths, T. & Goldwater, S. Adaptor gram- mars: A framework for specifying compositional non- parametric bayesian models.Adv. Neural Inf. Process. Syst.19(2006)
2006
-
[71]
Teh, Y . W. A hierarchical bayesian language model based on pitman-yor processes. InProceedings of the 21st Inter- national Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computa- tional Linguistics, 985–992 (2006)
2006
-
[72]
D., Tenenbaum, J
Goodman, N. D., Tenenbaum, J. B., Feldman, J. & Grif- fiths, T. L. A rational analysis of rule-based concept learning.Cogn. Sci.32, 108–154 (2008)
2008
-
[73]
T., Tenenbaum, J
Piantadosi, S. T., Tenenbaum, J. B. & Goodman, N. D. Bootstrapping in a language of thought: A formal model of numerical concept learning.Cognition123, 199–217 (2012)
2012
-
[74]
Correa, C. G.et al.Exploring the hierarchical structure of human plans via program generation.arXiv preprint arXiv:2311.18644(2023)
-
[75]
Über die Bausteine der mathematis- chen Logik.Math
Schönfinkel, M. Über die Bausteine der mathematis- chen Logik.Math. Annalen92, 305–316, DOI: 10.1007/ BF01448013 (1924)
1924
-
[76]
D., Vitányi, P.et al.Algorithmic informa- tion theory (2008)
Grünwald, P. D., Vitányi, P.et al.Algorithmic informa- tion theory (2008)
2008
-
[77]
D.The Minimum Description Length Prin- ciple(MIT press, 2007)
Grünwald, P. D.The Minimum Description Length Prin- ciple(MIT press, 2007)
2007
-
[78]
New efficient algorithms for multiple change-point detection with kernels
Celisse, A., Marot, G., Pierre-Jean, M. & Rigaill, G. New efficient algorithms for multiple change-point detection with kernels.arXiv preprint arXiv:1710.04556(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[79]
& Blei, D
Kucukelbir, A., Tran, D., Ranganath, R., Gelman, A. & Blei, D. M. Automatic differentiation variational infer- ence.J. machine learning research18, 1–45 (2017)
2017
-
[80]
The magical mystery four: How is working memory capacity limited, and why?Curr
Cowan, N. The magical mystery four: How is working memory capacity limited, and why?Curr. directions psychological science19, 51–57 (2010)
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.