Human Decision-Making with AI Assistance under Correlated Features
Pith reviewed 2026-06-29 12:34 UTC · model grok-4.3
The pith
When features correlate, optimal AI policies must explore with diverse tests before committing to one fixed set so humans learn coefficients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
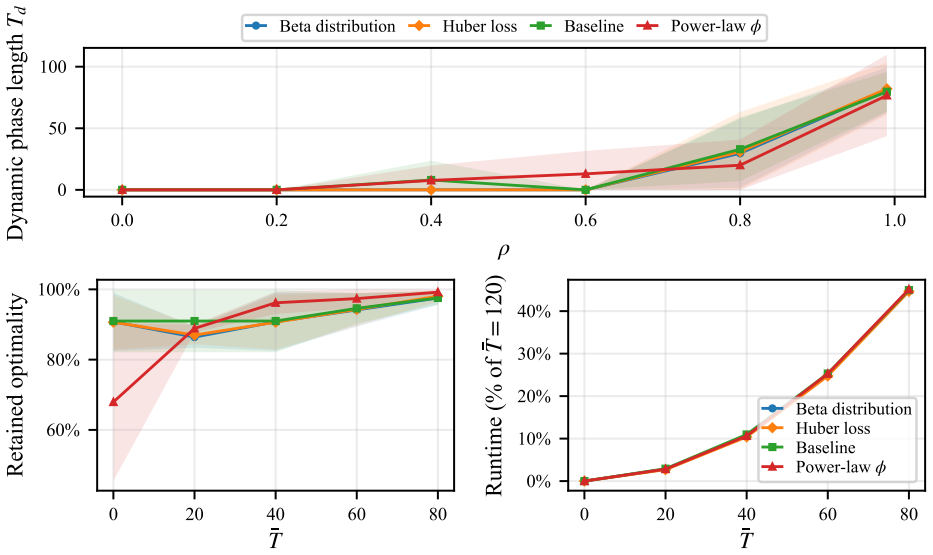
Any optimal policy for AI-assisted decisions under correlated features must follow an explore-then-commit structure: an initial phase in which the AI recommends diverse tests so that humans can recover accurate feature coefficients, followed by a commitment phase in which the AI repeats a single set of tests. The required length of exploration grows with the strength of the correlations. Stationary policies that ignore this structure perform arbitrarily poorly, while the optimal finite-horizon policy can be recovered by dynamic programming and a near-optimal approximation exists by truncating the horizon and appending a stationary suffix.
What carries the argument
The explore-then-commit policy structure, which uses an initial phase of varied test recommendations to let humans recover feature coefficients and then switches to a fixed recommendation set whose duration depends on correlation strength.
If this is right
- Stationary policies that repeat the same tests can be made arbitrarily suboptimal by increasing feature correlation.
- The length of the required exploration phase increases with the degree of correlation between features.
- Computing the exact optimal policy is NP-hard.
- A dynamic-programming algorithm recovers the optimal policy for any finite horizon.
- An approximation that solves a shorter-horizon instance and appends a stationary suffix achieves near-optimal performance.
Where Pith is reading between the lines
- In domains such as medical testing, the result implies that AI systems should deliberately vary initial recommendations when symptoms or lab values tend to co-occur.
- If humans combine information through mechanisms other than explicit coefficient recovery, the optimality of explore-then-commit may require re-derivation under the new learning rule.
- The NP-hardness result suggests that scalable approximations will be necessary for real-time deployment with long horizons.
Load-bearing premise
Humans recover the true feature coefficients accurately once they have seen sufficiently diverse combinations of test results.
What would settle it
A simulation or human-subject experiment in which the same sequence of diverse observations produces coefficient estimates whose error does not decrease as predicted, causing an explore-then-commit policy to underperform a stationary one.
Figures

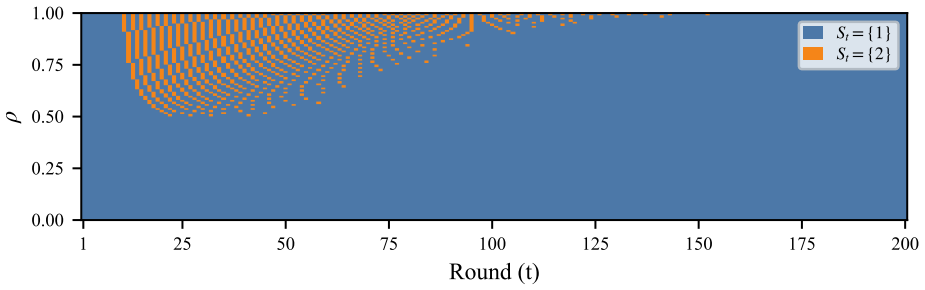
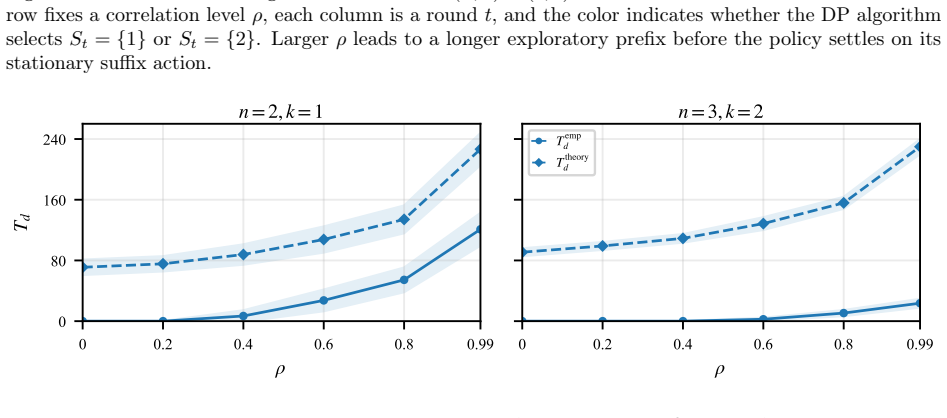
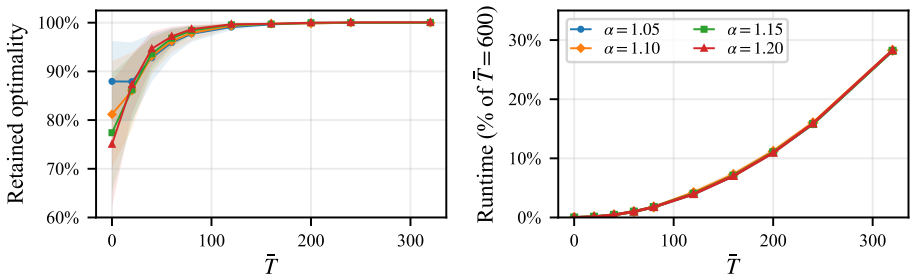
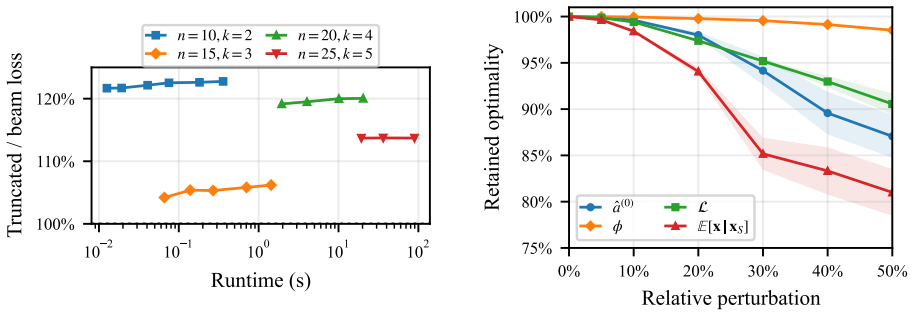
read the original abstract
Humans increasingly make decisions with AI assistance; for example, doctors may follow AI-recommended diagnostic tests and base their diagnoses on the results. A natural question is which tests should AI recommend to balance short-term decision quality and long-term human learning when different features (e.g., test results) are correlated. While prior work establishes that stationary policies that recommend the same tests repeatedly are optimal when features are independent, we prove that feature correlations lead such policies to perform arbitrarily poorly. Instead, we prove that any optimal policy must follow an explore-then-commit structure; initially, the AI should offer diverse tests so humans can learn accurate feature coefficients, then the AI should commit to a single set of tests, with exploration length that depends on the degree of feature correlation. We prove that computing the optimal policy is NP-hard and derive a dynamic programming-based algorithm that finds the optimal policy for finite horizons. We additionally develop an approximation that plans for shorter horizons and appends a stationary suffix, achieving near-optimal performance. Our empirical results complement our theory by showing that stronger feature correlation leads to longer exploration phases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes AI policies for recommending tests to humans making decisions when features are correlated. It proves that stationary policies recommending the same tests repeatedly can perform arbitrarily poorly, that any optimal policy must follow an explore-then-commit structure (initial diverse tests for learning feature coefficients β, followed by commitment to a fixed set with exploration length depending on correlation), that computing the optimal policy is NP-hard, provides a dynamic programming algorithm for finite horizons plus an approximation with stationary suffix, and shows empirically that higher correlation induces longer exploration phases under a linear human recovery model.
Significance. If the results hold under the stated model, the work offers a precise structural characterization of optimal assistance policies that accounts for human learning, extending prior results on independent features. The theoretical proofs, NP-hardness result, DP algorithm, and empirical validation on correlation effects provide concrete guidance for system design in finite-horizon settings.
major comments (2)
- [§4] §4 (main theorems on policy structure): the optimality of explore-then-commit and the arbitrary suboptimality of stationary policies are derived under the explicit assumption that humans recover exact linear coefficients β from a full-rank diverse design matrix with vanishing error; this assumption is load-bearing for both claims, and the paper should explicitly bound the recovery error as a function of the number of exploration steps and correlation strength to make the finite-horizon guarantees precise.
- [§5] §5 (NP-hardness and DP algorithm): the reduction establishing NP-hardness should be checked against the specific parameters of the correlated-feature model (e.g., whether hardness holds when the correlation matrix is fixed or must vary); if the reduction introduces additional free parameters not present in the decision model, the practical relevance of the hardness result for the stated setting needs clarification.
minor comments (3)
- [Abstract] The abstract states existence of proofs but the main text should cross-reference the exact theorem numbers for the arbitrary-poor-performance and explore-then-commit claims to improve readability.
- [Empirical section] Figure captions for the empirical plots should include the exact correlation values tested and the number of Monte Carlo runs to allow direct replication of the reported trend that stronger correlation lengthens exploration.
- [Model section] Notation for the human's estimated coefficients β̂ and the utility function should be introduced once in the model section and used consistently thereafter to avoid minor ambiguity in the algorithm descriptions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will incorporate clarifications and additions as noted.
read point-by-point responses
-
Referee: [§4] §4 (main theorems on policy structure): the optimality of explore-then-commit and the arbitrary suboptimality of stationary policies are derived under the explicit assumption that humans recover exact linear coefficients β from a full-rank diverse design matrix with vanishing error; this assumption is load-bearing for both claims, and the paper should explicitly bound the recovery error as a function of the number of exploration steps and correlation strength to make the finite-horizon guarantees precise.
Authors: We agree that an explicit finite-sample error bound would strengthen the presentation of the finite-horizon results. The current proofs establish the explore-then-commit structure and the arbitrary suboptimality of stationary policies in the limit of vanishing recovery error (which occurs once the design matrix is full rank). For any finite exploration length the recovery error is governed by standard concentration bounds for linear regression under the given correlation structure. In the revision we will insert a short lemma (with proof in the appendix) that explicitly bounds the coefficient estimation error as a function of exploration length, minimum eigenvalue of the Gram matrix, and correlation strength; this bound will be used to make the finite-horizon performance gap statements fully rigorous without changing the main theorems. revision: yes
-
Referee: [§5] §5 (NP-hardness and DP algorithm): the reduction establishing NP-hardness should be checked against the specific parameters of the correlated-feature model (e.g., whether hardness holds when the correlation matrix is fixed or must vary); if the reduction introduces additional free parameters not present in the decision model, the practical relevance of the hardness result for the stated setting needs clarification.
Authors: The reduction is performed directly inside the model parameters: the correlation matrix Σ is treated as an arbitrary positive-definite input (consistent with the problem statement), the linear coefficients β and noise variance are set accordingly, and the horizon length is polynomial in the reduction size. No extraneous free parameters are introduced. Hardness continues to hold when Σ is fixed to any full-rank matrix that permits the required linear independence in the reduction; we will add a clarifying paragraph after the theorem statement that explicitly maps each element of the reduction to the corresponding quantities (Σ, β, horizon) in the decision model, thereby confirming that the intractability result applies to the stated setting. revision: yes
Circularity Check
No circularity; proofs are model-conditional derivations, not reductions to inputs by construction
full rationale
The paper explicitly assumes a linear human decision model in which agents recover feature coefficients β from observed test outcomes, with estimation error vanishing only under full-rank diverse designs. Within this model it derives (i) arbitrary suboptimality of stationary policies under correlation and (ii) necessity of an explore-then-commit structure whose exploration length depends on correlation strength. These are direct mathematical consequences of the stated utility function and learning rule rather than self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations. No equations or steps reduce the claimed optimality result to the input data or to prior self-authored results by construction. The derivation is therefore self-contained against its own assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Humans recover accurate feature coefficients when offered sufficiently diverse tests
- domain assumption Decision quality is a function of learned feature coefficients
Reference graph
Works this paper leans on
-
[1]
2026 , note =
OpenAI , title =. 2026 , note =
2026
-
[2]
arXiv preprint arXiv:2209.13578 , year=
Learning when to advise human decision makers , author=. arXiv preprint arXiv:2209.13578 , year=
-
[3]
Proceedings of the 2020 CHI conference on human factors in computing systems , pages=
An interaction design for machine teaching to develop AI tutors , author=. Proceedings of the 2020 CHI conference on human factors in computing systems , pages=
2020
-
[4]
New Generation Computing , volume=
Teachability in computational learning , author=. New Generation Computing , volume=. 1991 , publisher=
1991
-
[5]
Journal of Computer and System Sciences , volume=
On the complexity of teaching , author=. Journal of Computer and System Sciences , volume=. 1995 , publisher=
1995
-
[6]
Proceedings of the AAAI conference on artificial intelligence , volume=
Machine teaching: An inverse problem to machine learning and an approach toward optimal education , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[7]
2020 , publisher=
Bandit algorithms , author=. 2020 , publisher=
2020
-
[8]
IEEE Transactions on Information Theory , volume=
Multi-armed bandits with correlated arms , author=. IEEE Transactions on Information Theory , volume=. 2021 , publisher=
2021
-
[9]
Conference on Learning Theory , pages=
Double explore-then-commit: Asymptotic optimality and beyond , author=. Conference on Learning Theory , pages=. 2021 , organization=
2021
-
[10]
Advances in Neural Information Processing Systems , volume=
On explore-then-commit strategies , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
arXiv preprint arXiv:2009.09266 , year=
Humans learn too: Better human-AI interaction using optimized human inputs , author=. arXiv preprint arXiv:2009.09266 , year=
-
[12]
PNAS nexus , volume=
Toward a science of human--AI teaming for decision making: A complementarity framework , author=. PNAS nexus , volume=. 2026 , publisher=
2026
-
[13]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
On the importance of application-grounded experimental design for evaluating explainable ML methods , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[14]
Proceedings of the ACM on Human-computer Interaction , volume=
To trust or to think: cognitive forcing functions can reduce overreliance on AI in AI-assisted decision-making , author=. Proceedings of the ACM on Human-computer Interaction , volume=. 2021 , publisher=
2021
-
[15]
Proceedings of the 2024 ACM conference on fairness, accountability, and transparency , pages=
A decision theoretic framework for measuring AI reliance , author=. Proceedings of the 2024 ACM conference on fairness, accountability, and transparency , pages=
2024
-
[16]
Advances in Neural Information Processing Systems , volume=
Human expertise in algorithmic prediction , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
arXiv preprint arXiv:2506.22740 , year=
Explanations are a means to an end , author=. arXiv preprint arXiv:2506.22740 , year=
-
[18]
Deep Reinforcement Learning for Clinical Decision Support: A Brief Survey
Deep reinforcement learning for clinical decision support: a brief survey , author=. arXiv preprint arXiv:1907.09475 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[19]
Proceedings of the ACM on Human-computer Interaction , volume=
Understanding the role of human intuition on reliance in human-AI decision-making with explanations , author=. Proceedings of the ACM on Human-computer Interaction , volume=. 2023 , publisher=
2023
-
[20]
Proceedings of the ACM on human-computer interaction , volume=
The principles and limits of algorithm-in-the-loop decision making , author=. Proceedings of the ACM on human-computer interaction , volume=. 2019 , publisher=
2019
-
[21]
Proceedings of the 26th ACM Conference on Economics and Computation , pages=
Designing algorithmic delegates: the role of indistinguishability in human-AI handoff , author=. Proceedings of the 26th ACM Conference on Economics and Computation , pages=
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
A no free lunch theorem for human-ai collaboration , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[23]
Ethics of data and analytics , pages=
Machine bias , author=. Ethics of data and analytics , pages=. 2022 , publisher=
2022
-
[24]
Emerging Infectious Diseases , volume=
Relationship of SARS-CoV-2 antigen and reverse transcription PCR positivity for viral cultures , author=. Emerging Infectious Diseases , volume=
-
[25]
Dostupno na: https://learn
The benefits of the latest AI technologies for patients and clinicians , author=. Dostupno na: https://learn. hms. harvard. edu/insights/all-insights/benefits-latest-ai-technologiespatients-and-clinicians (pristupljeno 30. srpnja 2025.) , year=
2025
-
[26]
arXiv preprint arXiv:2310.16410 , year=
Bridging the human-ai knowledge gap: Concept discovery and transfer in alphazero , author=. arXiv preprint arXiv:2310.16410 , year=
-
[27]
The Lancet , volume=
Interval cancer, sensitivity, and specificity comparing AI-supported mammography screening with standard double reading without AI in the MASAI study: a randomised, controlled, non-inferiority, single-blinded, population-based, screening-accuracy trial , author=. The Lancet , volume=. 2026 , publisher=
2026
-
[28]
arXiv preprint arXiv:2007.12161 , year=
Clinical recommender system: Predicting medical specialty diagnostic choices with neural network ensembles , author=. arXiv preprint arXiv:2007.12161 , year=
-
[29]
EBioMedicine , volume=
Artificial intelligence to support clinical decision-making processes , author=. EBioMedicine , volume=. 2019 , publisher=
2019
-
[30]
The Quarterly Journal of Economics , volume=
Generative AI at work , author=. The Quarterly Journal of Economics , volume=. 2025 , publisher=
2025
-
[31]
Mathematical programming , volume=
An analysis of approximations for maximizing submodular set functions—I , author=. Mathematical programming , volume=. 1978 , publisher=
1978
-
[32]
Italian conference on algorithms and complexity , pages=
Hardness of approximating problems on cubic graphs , author=. Italian conference on algorithms and complexity , pages=. 1997 , organization=
1997
-
[33]
Annals of mathematics , pages=
On the hardness of approximating minimum vertex cover , author=. Annals of mathematics , pages=. 2005 , publisher=
2005
-
[34]
arXiv preprint arXiv:2502.13062 , year=
Ai-assisted decision making with human learning , author=. arXiv preprint arXiv:2502.13062 , year=
-
[35]
The RAND Journal of Economics , volume=
Why do intermediaries divert search? , author=. The RAND Journal of Economics , volume=. 2011 , publisher=
2011
-
[36]
Proceedings of the Sixth Annual ACM Symposium on Theory of Computing , pages=
Some Simplified NP-Complete Graph Problems , author=. Proceedings of the Sixth Annual ACM Symposium on Theory of Computing , pages=. 1974 , organization=
1974
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.