Memory-Centric Computing: Security Benefits and Challenges of Processing-in-DRAM
Pith reviewed 2026-06-26 16:45 UTC · model grok-4.3
The pith
Processing-in-DRAM turns memory into an active substrate that supplies new security primitives while creating fresh attack surfaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
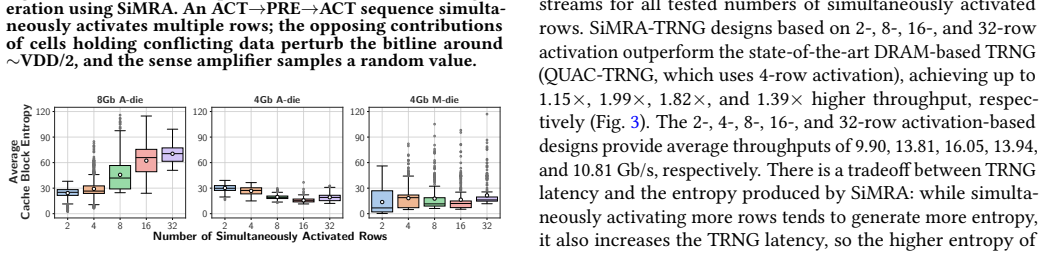
Processing-in-DRAM exploits and enhances the operational characteristics of real DRAM chips to perform computation on stored data, yielding new state-of-the-art true random number generators with up to 16.05 Gb/s throughput and physical unclonable functions with 5.75 percent lower evaluation latency than prior work, while simultaneously amplifying DRAM read disturbance by a factor of 158 in the minimum number of accesses needed to induce the first bitflip and enabling memory timing channels with 14.8 Mb/s throughput.
What carries the argument
Processing-in-DRAM (PiD), the exploitation and enhancement of DRAM operational characteristics to perform computation directly on data stored in the DRAM array.
If this is right
- DRAM can now serve as a source of high-throughput true random numbers without moving data off the chip.
- Physical unclonable functions can be realized with lower evaluation latency than previous DRAM-based designs.
- Rowhammer-style read-disturbance attacks become feasible with far fewer accesses once computation is performed in DRAM.
- Memory timing channels can reach communication rates of 14.8 Mb/s when computation occurs inside the DRAM array.
- Future DRAM designs must treat computational capability, storage density, and security as co-equal goals.
Where Pith is reading between the lines
- The same substrate changes may affect security in other processing-in-memory technologies that move work closer to data.
- System software and hardware architects will need new mechanisms to isolate computation inside memory from untrusted code.
- Security evaluations of future memory chips will have to account for both the new primitives and the new disturbance surfaces simultaneously.
Load-bearing premise
The measured security benefits and challenges arise directly from the way DRAM chips can be made to compute on their own stored data.
What would settle it
Real DRAM chips that, when configured for in-DRAM computation, fail to produce the reported 16.05 Gb/s TRNG throughput or the 158x reduction in accesses required for the first bitflip.
Figures



read the original abstract
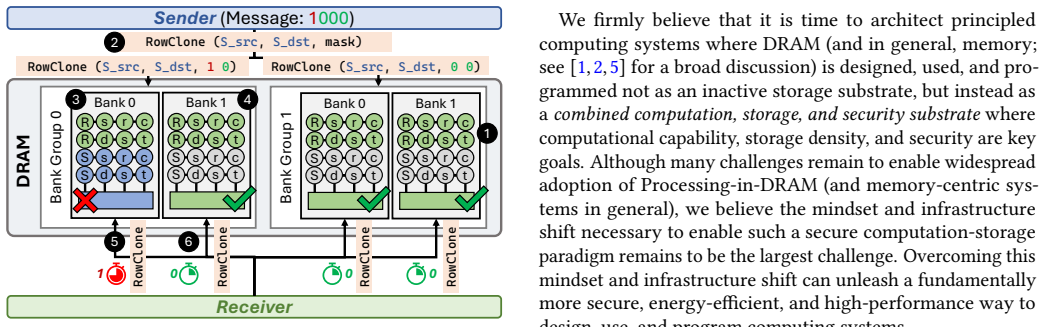
Today's computing systems are processor-centric: they require frequent data movement between processing elements (e.g., CPU) and main memory (DRAM), leading to significant inefficiencies in performance and energy consumption. Memory-centric computing instead moves computation to the data, enabling computation capability in and near all places where data is generated and stored, and greatly reducing the performance and energy overheads of data access and data movement. This shift from a processor-centric to a memory-centric paradigm has important and underexplored consequences for system security. Turning memory from a dumb, inactive store into an active computing substrate introduces benefits as well as challenges for system security: it can provide new in-memory security primitives and also reduce data exposure, but it can also expose new attack surfaces. This work discusses the security benefits and challenges of memory-centric computing, specifically Processing-in-DRAM (PiD), a paradigm where the operational characteristics of a DRAM chip are exploited and enhanced to perform computation on data stored in DRAM. Specifically, we describe 1) new state-of-the-art DRAM-based true random number generators that provide up to 16.05 Gb/s throughput and physical unclonable functions with 5.75% lower evaluation latency than the prior state-of-the-art, both on real DRAM chips and 2) two key security challenges of PiD: amplified DRAM read disturbance (e.g., 158x reduction in the minimum number of DRAM accesses required to induce the first bitflip) and high throughput memory timing channels (e.g., a communication throughput of 14.8Mb/s). We believe it is time to design, use, and program DRAM, and in general memory, not as an inactive storage substrate, but as a combined computation, storage, and security substrate, where computational capability, storage density, and security are all key goals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript discusses the security benefits and challenges of Processing-in-DRAM (PiD), a memory-centric computing approach that exploits DRAM operational characteristics for in-memory computation. It reports new DRAM-based true random number generators (TRNGs) achieving up to 16.05 Gb/s throughput and physical unclonable functions (PUFs) with 5.75% lower evaluation latency than prior state-of-the-art, both demonstrated on real DRAM chips. It also identifies two key challenges: amplified read disturbance leading to a 158x reduction in the minimum accesses needed to induce the first bitflip, and high-throughput memory timing channels achieving 14.8 Mb/s. The work advocates designing DRAM as a combined computation, storage, and security substrate.
Significance. If the real-chip measurements hold, the paper provides a timely and concrete assessment of how shifting to memory-centric computing affects security, with specific quantitative examples of both new primitives and new attack surfaces. The grounding in hardware measurements on actual DRAM chips is a strength that could help guide secure PiD system design.
major comments (1)
- [Abstract] Abstract: The central quantitative claims (16.05 Gb/s TRNG throughput, 5.75% PUF latency reduction, 158x disturbance increase, 14.8 Mb/s channel) are presented as direct experimental observations with no reference to methods, number of chips/devices tested, controls, or statistical analysis. This information is load-bearing for the claims of new state-of-the-art primitives and specific quantified challenges.
minor comments (2)
- The manuscript would benefit from an explicit statement of which results are new versus drawn from prior work on DRAM-based security primitives.
- Figure and table captions should include enough detail to interpret the quantitative security metrics without referring back to the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive comment and the recommendation of minor revision. We address the point on the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central quantitative claims (16.05 Gb/s TRNG throughput, 5.75% PUF latency reduction, 158x disturbance increase, 14.8 Mb/s channel) are presented as direct experimental observations with no reference to methods, number of chips/devices tested, controls, or statistical analysis. This information is load-bearing for the claims of new state-of-the-art primitives and specific quantified challenges.
Authors: We agree that the abstract would benefit from explicit pointers to the experimental details. The methods, device counts, controls, and statistical analysis for all four quantitative results are already provided in the body of the manuscript (Sections 3 and 4). In the revised version we will add concise references in the abstract (e.g., “demonstrated on real DRAM chips; see Sections 3–4 for methods and analysis”) so that readers can immediately locate the supporting information without lengthening the abstract substantially. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents security benefits and challenges of Processing-in-DRAM as direct experimental observations from real DRAM chip measurements, including specific quantitative results for TRNG throughput (16.05 Gb/s), PUF latency improvements (5.75%), read disturbance amplification (158x), and timing channel throughput (14.8 Mb/s). No derivation chain, equations, fitted parameters, or self-referential steps are described; claims reduce to hardware measurements rather than any construction that equates outputs to inputs by definition or self-citation. The work is self-contained against external benchmarks as empirical reporting.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pro- cessing Data Where It Makes Sense: Enabling In-Memory Computation.MICPRO, 2019
Onur Mutlu, Saugata Ghose, Juan Gómez-Luna, and Rachata Ausavarungnirun. Pro- cessing Data Where It Makes Sense: Enabling In-Memory Computation.MICPRO, 2019
2019
-
[2]
A Modern Primer on Processing in Memory
Onur Mutlu, Saugata Ghose, Juan Gómez-Luna, and Rachata Ausavarungnirun. A Modern Primer on Processing in Memory. arXiv, 2025
2025
-
[3]
Google Workloads for Consumer Devices: Mitigat- ing Data Movement Bottlenecks
Amirali Boroumand, Saugata Ghose, Youngsok Kim, Rachata Ausavarungnirun, Eric Shiu, Rahul Thakur, Daehyun Kim, Aki Kuusela, Allan Knies, Parthasarathy Ranganathan, and Onur Mutlu. Google Workloads for Consumer Devices: Mitigat- ing Data Movement Bottlenecks. InASPLOS, 2018
2018
-
[4]
Google Neural Network Models for Edge Devices: Analyzing and Mitigating Machine Learning Inference Bottlenecks
Amirali Boroumand, Saugata Ghose, Berkin Akin, Ravi Narayanaswami, Geraldo F Oliveira, Xiaoyu Ma, Eric Shiu, and Onur Mutlu. Google Neural Network Models for Edge Devices: Analyzing and Mitigating Machine Learning Inference Bottlenecks. InPACT, 2021
2021
-
[5]
Processing-in-Memory: A Workload-Driven Perspective.IBM JRD, 2019
Saugata Ghose, Amirali Boroumand, Jeremie S Kim, Juan Gómez-Luna, and Onur Mutlu. Processing-in-Memory: A Workload-Driven Perspective.IBM JRD, 2019
2019
-
[6]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
2020
-
[7]
BERT: Pre- training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre- training of Deep Bidirectional Transformers for Language Understanding. In NAACL, 2019
2019
-
[8]
Accelerating Neural Network Inference with Processing-in-DRAM: From the Edge to the Cloud.IEEE Micro, 2022
Geraldo F Oliveira, Juan Gómez-Luna, Saugata Ghose, Amirali Boroumand, and Onur Mutlu. Accelerating Neural Network Inference with Processing-in-DRAM: From the Edge to the Cloud.IEEE Micro, 2022
2022
-
[9]
Neupims: Npu-pim Heterogeneous Acceleration for Batched LLM Inferencing
Guseul Heo, Sangyeop Lee, Jaehong Cho, Hyunmin Choi, Sanghyeon Lee, Hyungkyu Ham, Gwangsun Kim, Divya Mahajan, and Jongse Park. Neupims: Npu-pim Heterogeneous Acceleration for Batched LLM Inferencing. InASPLOS, 2024
2024
-
[10]
TransPIM: A Memory-based Acceleration via Software-Hardware Co-Design for Transformer
Minxuan Zhou, Weihong Xu, Jaeyoung Kang, and Tajana Rosing. TransPIM: A Memory-based Acceleration via Software-Hardware Co-Design for Transformer. InHPCA, 2022. 6
2022
-
[11]
AttAcc! Unleashing the Power of PIM for Batched Transformer-based Generative Model Inference
Jaehyun Park, Jaewan Choi, Kwanhee Kyung, Michael Jaemin Kim, Yongsuk Kwon, Nam Sung Kim, and Jung Ho Ahn. AttAcc! Unleashing the Power of PIM for Batched Transformer-based Generative Model Inference. InASPLOS, 2024
2024
-
[12]
IANUS: Integrated Accelerator based on NPU-PIM Unified Memory System
Minseok Seo, Xuan Truong Nguyen, Seok Joong Hwang, Yongkee Kwon, Guhyun Kim, Chanwook Park, Ilkon Kim, Jaehan Park, Jeongbin Kim, Woojae Shin, et al. IANUS: Integrated Accelerator based on NPU-PIM Unified Memory System. In ASPLOS, 2024
2024
-
[13]
PIM-Opt: Demystifying Distributed Optimization Algorithms on a Real-World Processing-In- Memory System
Steve Rhyner, Haocong Luo, Juan Gomez-Luna, Mohammad Sadrosadati, Jiawei Jiang, Ataberk Olgun, Harshita Gupta, Ce Zhang, and Onur Mutlu. PIM-Opt: Demystifying Distributed Optimization Algorithms on a Real-World Processing-In- Memory System. InPACT, 2024
2024
-
[14]
Duplex: A Device for Large Lan- guage Models with Mixture of Experts, Grouped Query Attention, and Continuous Batching
Sungmin Yun, Kwanhee Kyung, Juhwan Cho, Jaewan Choi, Jongmin Kim, Byeongho Kim, Sukhan Lee, Kyomin Sohn, and Jung Ho Ahn. Duplex: A Device for Large Lan- guage Models with Mixture of Experts, Grouped Query Attention, and Continuous Batching. InMICRO, 2024
2024
-
[15]
Smart-Infinity: Fast Large Language Model Training using Near-Storage Processing on a Real System
Hongsun Jang, Jaeyong Song, Jaewon Jung, Jaeyoung Park, Youngsok Kim, and Jinho Lee. Smart-Infinity: Fast Large Language Model Training using Near-Storage Processing on a Real System. InHPCA, 2024
2024
-
[16]
Accelerating Genome Analysis: A Primer on an Ongoing Journey.IEEE Micro, 2020
Mohammed Alser, Zülal Bingöl, Damla Senol Cali, Jeremie Kim, Saugata Ghose, Can Alkan, and Onur Mutlu. Accelerating Genome Analysis: A Primer on an Ongoing Journey.IEEE Micro, 2020
2020
-
[17]
FPGA-Based Near-Memory Acceleration of Modern Data-Intensive Applications.IEEE Micro, 2021
Gagandeep Singh, Mohammed Alser, Damla Senol Cali, Dionysios Diamantopoulos, Juan Gómez-Luna, Henk Corporaal, and Onur Mutlu. FPGA-Based Near-Memory Acceleration of Modern Data-Intensive Applications.IEEE Micro, 2021
2021
-
[18]
From Molecules to Ge- nomic Variations: Accelerating Genome Analysis via Intelligent Algorithms and Architectures.CSBJ, 2022
Mohammed Alser, Joel Lindegger, Can Firtina, Nour Almadhoun, Haiyu Mao, Gagandeep Singh, Juan Gomez-Luna, and Onur Mutlu. From Molecules to Ge- nomic Variations: Accelerating Genome Analysis via Intelligent Algorithms and Architectures.CSBJ, 2022
2022
-
[19]
GRIM- Filter: Fast Seed Location Filtering in DNA Read Mapping using Processing-in- Memory Technologies
Jeremie S Kim, Damla Senol Cali, Hongyi Xin, Donghyuk Lee, Saugata Ghose, Mohammed Alser, Hasan Hassan, Oguz Ergin, Can Alkan, and Onur Mutlu. GRIM- Filter: Fast Seed Location Filtering in DNA Read Mapping using Processing-in- Memory Technologies. InAPBC, 2018
2018
-
[20]
GenStore: A High-Performance and Energy-Efficient In-Storage Computing System for Genome Sequence Analysis
Nika Mansouri Ghiasi, Jisung Park, Harun Mustafa, Jeremie Kim, Ataberk Olgun, Arvid Gollwitzer, Damla Senol Cali, Can Firtina, Haiyu Mao, Nour Almadhoun Alserr, et al. GenStore: A High-Performance and Energy-Efficient In-Storage Computing System for Genome Sequence Analysis. InASPLOS, 2022
2022
-
[21]
MegIS: High-Performance, Energy-Efficient, and Low-Cost Metagenomic Analysis with In-Storage Processing
Nika Mansouri Ghiasi, Mohammad Sadrosadati, Harun Mustafa, Arvid Gollwitzer, Can Firtina, Julien Eudine, Haiyu Mao, Joël Lindegger, Meryem Banu Cavlak, Mohammed Alser, et al. MegIS: High-Performance, Energy-Efficient, and Low-Cost Metagenomic Analysis with In-Storage Processing. InISCA, 2024
2024
-
[22]
GenASM: A High-Performance, Low-Power Approximate String Matching Acceleration Framework for Genome Sequence Analysis
Damla Senol Cali, Gurpreet S Kalsi, Zülal Bingöl, Can Firtina, Lavanya Subramanian, Jeremie S Kim, Rachata Ausavarungnirun, Mohammed Alser, Juan Gomez-Luna, Amirali Boroumand, et al. GenASM: A High-Performance, Low-Power Approximate String Matching Acceleration Framework for Genome Sequence Analysis. In MICRO, 2020
2020
-
[23]
SeGraM: A Universal Hardware Accelerator for Genomic Sequence-to-Graph and Sequence-to-Sequence Mapping
Damla Senol Cali, Konstantinos Kanellopoulos, Joel Lindegger, Zülal Bingöl, Gur- preet S Kalsi, Ziyi Zuo, Can Firtina, Meryem Banu Cavlak, Jeremie Kim, Nika Man- souri Ghiasi, et al. SeGraM: A Universal Hardware Accelerator for Genomic Sequence-to-Graph and Sequence-to-Sequence Mapping. InISCA, 2022
2022
-
[24]
Nanopore Sequencing Technology and Tools for Genome Assembly: Computational Analysis of the Current State, Bottlenecks and Future Directions.Briefings in Bioinformatics, 2018
Damla Senol Cali, Jeremie S Kim, Saugata Ghose, Can Alkan, and Onur Mutlu. Nanopore Sequencing Technology and Tools for Genome Assembly: Computational Analysis of the Current State, Bottlenecks and Future Directions.Briefings in Bioinformatics, 2018
2018
-
[25]
PAPI: Exploiting Dynamic Parallelism in Large Language Model Decoding with a Processing-In- Memory-Enabled Computing System.ASPLOS, 2025
Yintao He, Haiyu Mao, Christina Giannoula, Mohammad Sadrosadati, Juan Gómez- Luna, Huawei Li, Xiaowei Li, Ying Wang, and Onur Mutlu. PAPI: Exploiting Dynamic Parallelism in Large Language Model Decoding with a Processing-In- Memory-Enabled Computing System.ASPLOS, 2025
2025
-
[26]
PIM Is All You Need: A CXL-Enabled GPU-Free System for Large Language Model Inference.ASPLOS, 2025
Yufeng Gu, Alireza Khadem, Sumanth Umesh, Ning Liang, Xavier Servot, Onur Mutlu, Ravi Iyer, and Reetuparna Das. PIM Is All You Need: A CXL-Enabled GPU-Free System for Large Language Model Inference.ASPLOS, 2025
2025
-
[27]
A Scalable Processing-in-Memory Accelerator for Parallel Graph Processing
Junwhan Ahn, Sungpack Hong, Sungjoo Yoo, Onur Mutlu, and Kiyoung Choi. A Scalable Processing-in-Memory Accelerator for Parallel Graph Processing. InISCA, 2015
2015
-
[28]
PIM-Enabled Instruc- tions: A Low-Overhead, Locality-Aware Processing-in-Memory Architecture
Junwhan Ahn, Sungjoo Yoo, Onur Mutlu, and Kiyoung Choi. PIM-Enabled Instruc- tions: A Low-Overhead, Locality-Aware Processing-in-Memory Architecture. In ISCA, 2015
2015
-
[29]
GraphPIM: Enabling Instruction-Level PIM Offloading in Graph Computing Frameworks
Lifeng Nai, Ramyad Hadidi, Jaewoong Sim, Hyojong Kim, Pranith Kumar, and Hyesoon Kim. GraphPIM: Enabling Instruction-Level PIM Offloading in Graph Computing Frameworks. InHPCA, 2017
2017
-
[30]
SISA: Set-Centric In- struction Set Architecture for Graph Mining on Processing-in-Memory Systems
Maciej Besta, Raghavendra Kanakagiri, Grzegorz Kwasniewski, Rachata Ausavarungnirun, Jakub Beránek, Konstantinos Kanellopoulos, Kacper Janda, Zur Vonarburg-Shmaria, Lukas Gianinazzi, Ioana Stefan, et al. SISA: Set-Centric In- struction Set Architecture for Graph Mining on Processing-in-Memory Systems. InMICRO, 2021
2021
-
[31]
Salihoglu and J
S. Salihoglu and J. Widom. GPS: A Graph Processing System. InSSDBM, 2013
2013
-
[32]
From ‘Think Like a Vertex to ‘Think Like a Graph’.VLDB, 2013
Yuanyuan Tian, Andrey Balmin, Severin Andreas Corsten, Shirish Tatikonda, and John McPherson. From ‘Think Like a Vertex to ‘Think Like a Graph’.VLDB, 2013
2013
-
[33]
Distributed GraphLab: A Framework for Machine Learning and Data Mining in the Cloud.VLDB, 2012
Yucheng Low, Danny Bickson, Joseph Gonzalez, Carlos Guestrin, Aapo Kyrola, and Joseph M Hellerstein. Distributed GraphLab: A Framework for Machine Learning and Data Mining in the Cloud.VLDB, 2012
2012
-
[34]
Ambit: In-Memory Accelerator for Bulk Bitwise Operations Using Commodity DRAM Technology
Vivek Seshadri, Donghyuk Lee, Thomas Mullins, Hasan Hassan, Amirali Boroumand, Jeremie Kim, Michael A Kozuch, Onur Mutlu, Phillip B Gibbons, and Todd C Mowry. Ambit: In-Memory Accelerator for Bulk Bitwise Operations Using Commodity DRAM Technology. InMICRO, 2017
2017
-
[35]
de Oliveira, Juan Gomez-Luna, Lois Orosa, Saugata Ghose, Nandita Vijaykumar, Ivan Fernandez, Mohammad Sadrosadati, and Onur Mutlu
Geraldo F. de Oliveira, Juan Gomez-Luna, Lois Orosa, Saugata Ghose, Nandita Vijaykumar, Ivan Fernandez, Mohammad Sadrosadati, and Onur Mutlu. DAMOV: A New Methodology and Benchmark Suite for Evaluating Data Movement Bottlenecks .IEEE Access, 2021
2021
-
[36]
Benchmarking a New Paradigm: Experimental Analysis and Characterization of a Real Processing-in-Memory System.IEEE Access, 2022
Juan Gómez-Luna, Izzat El Hajj, Ivan Fernandez, Christina Giannoula, Geraldo F Oliveira, and Onur Mutlu. Benchmarking a New Paradigm: Experimental Analysis and Characterization of a Real Processing-in-Memory System.IEEE Access, 2022
2022
-
[37]
Polynesia: Enabling High-Performance and Energy-Efficient Hybrid Transactional/Analytical Databases with Hardware/Software Co-Design
Amirali Boroumand, Saugata Ghose, Geraldo F Oliveira, and Onur Mutlu. Polynesia: Enabling High-Performance and Energy-Efficient Hybrid Transactional/Analytical Databases with Hardware/Software Co-Design. InICDE, 2022
2022
-
[38]
Memory- Centric Computing: Recent Advances in Processing-in-DRAM
Onur Mutlu, Ataberk Olgun, Geraldo F Oliveira, and Ismail E Yuksel. Memory- Centric Computing: Recent Advances in Processing-in-DRAM. InIEDM, 2024
2024
-
[39]
Memory-Centric Computing: Solving Computing’s Memory Problem
Onur Mutlu, Ataberk Olgun, and Ismail Emir Yuksel. Memory-Centric Computing: Solving Computing’s Memory Problem. InIMW, 2025
2025
-
[40]
Hybrid Memory Cube Specification Rev
HMC Consortium. Hybrid Memory Cube Specification Rev. 2.0. 2013
2013
-
[41]
JESD235 High Bandwidth Memory (HBM) DRAM, 2013
JEDEC. JESD235 High Bandwidth Memory (HBM) DRAM, 2013
2013
-
[42]
Simultaneous Multi-Layer Access: Improving 3D-Stacked Memory Band- width at Low Cost.TACO, 2016
Donghyuk Lee, Saugata Ghose, Gennady Pekhimenko, Samira Khan, and Onur Mutlu. Simultaneous Multi-Layer Access: Improving 3D-Stacked Memory Band- width at Low Cost.TACO, 2016
2016
-
[43]
Present and Future, Challenges of High Bandwith Memory (HBM)
Kwiwook Kim and Myeong-jae Park. Present and Future, Challenges of High Bandwith Memory (HBM). InIMW, 2024
2024
-
[44]
Transparent Offloading and Mapping (TOM): Enabling Programmer-Transparent Near-Data Processing in GPU Systems
Kevin Hsieh, Eiman Ebrahimi, Gwangsun Kim, Niladrish Chatterjee, Mike O’Connor, Nandita Vijaykumar, Onur Mutlu, and Stephen W Keckler. Transparent Offloading and Mapping (TOM): Enabling Programmer-Transparent Near-Data Processing in GPU Systems. InISCA, 2016
2016
-
[45]
Malladi, Hongzhong Zheng, and Onur Mutlu
Amirali Boroumand, Saugata Ghose, Minesh Patel, Hasan Hassan, Brandon Lucia, Kevin Hsieh, Krishna T. Malladi, Hongzhong Zheng, and Onur Mutlu. CoNDA: Enabling Efficient Near-Data Accelerator Communication by Optimizing Data Movement.ISCA, 2019
2019
-
[46]
PRIME: A Novel Processing-in-Memory Architecture for Neural Network Computation in ReRAM-Based Main Memory
Ping Chi, Shuangchen Li, Cong Xu, Tao Zhang, Jishen Zhao, Yongpan Liu, Yu Wang, and Yuan Xie. PRIME: A Novel Processing-in-Memory Architecture for Neural Network Computation in ReRAM-Based Main Memory. InISCA, 2016
2016
-
[47]
Stanley Williams, and Vivek Srikumar
Ali Shafiee, Anirban Nag, Naveen Muralimanohar, Rajeev Balasubramonian, John Paul Strachan, Miao Hu, R. Stanley Williams, and Vivek Srikumar. ISAAC: A Convolutional Neural Network Accelerator with In-Situ Analog Arithmetic in Crossbars. InISCA, 2016
2016
-
[48]
In-DRAM Bulk Bitwise Execution Engine.arXiv, 2019
Vivek Seshadri and Onur Mutlu. In-DRAM Bulk Bitwise Execution Engine.arXiv, 2019
2019
-
[49]
DRISA: A DRAM-Based Reconfigurable In-Situ Accelerator
Shuangchen Li, Dimin Niu, Krishna T Malladi, Hongzhong Zheng, Bob Brennan, and Yuan Xie. DRISA: A DRAM-Based Reconfigurable In-Situ Accelerator. In MICRO, 2017
2017
-
[50]
RowClone: Fast and Energy-Efficient In-DRAM Bulk Data Copy and Initialization
Vivek Seshadri, Yoongu Kim, Chris Fallin, Donghyuk Lee, Rachata Ausavarung- nirun, Gennady Pekhimenko, Yixin Luo, Onur Mutlu, Phillip B Gibbons, Michael A Kozuch, and Todd Mowry. RowClone: Fast and Energy-Efficient In-DRAM Bulk Data Copy and Initialization. InMICRO, 2013
2013
-
[51]
The Processing Using Memory Paradigm: In- DRAM Bulk Copy, Initialization, Bitwise AND and OR
Vivek Seshadri and Onur Mutlu. The Processing Using Memory Paradigm: In- DRAM Bulk Copy, Initialization, Bitwise AND and OR. arXiv:1610.09603 [cs.AR], 2016
Pith/arXiv arXiv 2016
-
[52]
DrAcc: A DRAM Based Accelerator for Accurate CNN Inference
Quan Deng, Lei Jiang, Youtao Zhang, Minxuan Zhang, and Jun Yang. DrAcc: A DRAM Based Accelerator for Accurate CNN Inference. InDAC, 2018
2018
-
[53]
ELP2IM: Efficient and Low Power Bitwise Operation Processing in DRAM
Xin Xin, Youtao Zhang, and Jun Yang. ELP2IM: Efficient and Low Power Bitwise Operation Processing in DRAM. InHPCA, 2020
2020
-
[54]
GraphR: Accelerating Graph Processing Using ReRAM
Linghao Song, Youwei Zhuo, Xuehai Qian, Hai Li, and Yiran Chen. GraphR: Accelerating Graph Processing Using ReRAM. InHPCA, 2018
2018
-
[55]
PipeLayer: A Pipelined ReRAM-Based Accelerator for Deep Learning
Linghao Song, Xuehai Qian, Hai Li, and Yiran Chen. PipeLayer: A Pipelined ReRAM-Based Accelerator for Deep Learning. InHPCA, 2017
2017
-
[56]
ComputeDRAM: In-Memory Compute Using Off-the-Shelf DRAMs
Fei Gao, Georgios Tziantzioulis, and David Wentzlaff. ComputeDRAM: In-Memory Compute Using Off-the-Shelf DRAMs. InMICRO, 2019
2019
-
[57]
Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks
Charles Eckert, Xiaowei Wang, Jingcheng Wang, Arun Subramaniyan, Ravi Iyer, Dennis Sylvester, David Blaauw, and Reetuparna Das. Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks. InISCA, 2018
2018
-
[58]
Compute Caches
Shaizeen Aga, Supreet Jeloka, Arun Subramaniyan, Satish Narayanasamy, David Blaauw, and Reetuparna Das. Compute Caches. InHPCA, 2017
2017
-
[59]
Duality Cache for Data Parallel Acceleration
Daichi Fujiki, Scott Mahlke, and Reetuparna Das. Duality Cache for Data Parallel Acceleration. InISCA, 2019
2019
-
[60]
Buddy-RAM: Improving the Performance and Efficiency of Bulk Bitwise Operations Using DRAM
Vivek Seshadri, Donghyuk Lee, Thomas Mullins, Hasan Hassan, Amirali Boroumand, Jeremie Kim, Michael A Kozuch, Onur Mutlu, Phillip B Gibbons, and Todd C Mowry. Buddy-RAM: Improving the Performance and Efficiency of Bulk Bitwise Operations Using DRAM. arXiv, 2016
2016
-
[61]
Simple Operations in Memory to Reduce Data Movement
Vivek Seshadri and Onur Mutlu. Simple Operations in Memory to Reduce Data Movement. InAdvances in Computers, Volume 106. 2017
2017
-
[62]
Gibbons, Michael A
Vivek Seshadri, Yoongu Kim, Chris Fallin, Donghyuk Lee, Rachata Ausavarung- nirun, Gennady Pekhimenko, Yixin Luo, Onur Mutlu, Phillip B. Gibbons, Michael A. Kozuch, and Todd C. Mowry. RowClone: Accelerating Data Movement and Initial- ization Using DRAM. arXiv, 2018
2018
-
[63]
Kozuch, Onur Mutlu, Phillip B
Vivek Seshadri, Kevin Hsieh, Amirali Boroumand, Donghyuk Lee, Michael A. Kozuch, Onur Mutlu, Phillip B. Gibbons, and Todd C. Mowry. Fast Bulk Bitwise AND and OR in DRAM. 2015
2015
-
[64]
Pinatubo: A Processing-in-Memory Architecture for Bulk Bitwise Operations in Emerging Non-Volatile Memories
Shuangchen Li, Cong Xu, Qiaosha Zou, Jishen Zhao, Yu Lu, and Yuan Xie. Pinatubo: A Processing-in-Memory Architecture for Bulk Bitwise Operations in Emerging Non-Volatile Memories. InDAC, 2016
2016
-
[65]
Kim, Geraldo F
João Dinis Ferreira, Gabriel Falcao, Juan Gómez-Luna, Mohammed Alser, Lois Orosa, Mohammad Sadrosadati, Jeremie S. Kim, Geraldo F. Oliveira, Taha Shahroodi, Anant Nori, and Onur Mutlu. pLUTo: In-DRAM Lookup Tables to Enable Massively Parallel General-Purpose Computation. InMICRO, 2022. 7
2022
-
[66]
FloatPIM: In- Memory Acceleration of Deep Neural Network Training with High Precision
Mohsen Imani, Saransh Gupta, Yeseong Kim, and Tajana Rosing. FloatPIM: In- Memory Acceleration of Deep Neural Network Training with High Precision. In ISCA, 2019
2019
-
[67]
Sparse BD-Net: A Multiplication-Less DNN with Sparse Binarized Depth-Wise Separable Convolution.JETC, 16(2):1–24, 2020
Zhezhi He, Li Yang, Shaahin Angizi, Adnan Siraj Rakin, and Deliang Fan. Sparse BD-Net: A Multiplication-Less DNN with Sparse Binarized Depth-Wise Separable Convolution.JETC, 16(2):1–24, 2020
2020
-
[68]
Oliveira, Mohammad Sadrosadati, Rakesh Nadig, David Novo, Juan Gómez-Luna, Myungsuk Kim, and Onur Mutlu
Jisung Park, Roknoddin Azizi, Geraldo F. Oliveira, Mohammad Sadrosadati, Rakesh Nadig, David Novo, Juan Gómez-Luna, Myungsuk Kim, and Onur Mutlu. Flash- Cosmos: In-Flash Bulk Bitwise Operations Using Inherent Computation Capability of NAND Flash Memory. InMICRO, 2022
2022
-
[69]
Adapting the RACER Architecture to Integrate Improved In-ReRAM Logic Primitives.JETCAS, 2022
Minh SQ Truong, Liting Shen, Alexander Glass, Alison Hoffmann, L Richard Carley, James A Bain, and Saugata Ghose. Adapting the RACER Architecture to Integrate Improved In-ReRAM Logic Primitives.JETCAS, 2022
2022
-
[70]
RACER: Bit-Pipelined Processing Using Resistive Memory
Minh SQ Truong, Eric Chen, Deanyone Su, Liting Shen, Alexander Glass, L Richard Carley, James A Bain, and Saugata Ghose. RACER: Bit-Pipelined Processing Using Resistive Memory. InMICRO, 2021
2021
-
[71]
QUAC-TRNG: High- Throughput True Random Number Generation Using Quadruple Row Activation in Commodity DRAM Chips
Ataberk Olgun, Minesh Patel, A Giray Yağlıkçı, Haocong Luo, Jeremie S Kim, Nisa Bostancı, Nandita Vijaykumar, Oğuz Ergin, and Onur Mutlu. QUAC-TRNG: High- Throughput True Random Number Generation Using Quadruple Row Activation in Commodity DRAM Chips. InISCA, 2021
2021
-
[72]
D-RaNGe: Using Commodity DRAM Devices to Generate True Random Numbers with Low Latency and High Throughput
Jeremie S Kim, Minesh Patel, Hasan Hassan, Lois Orosa, and Onur Mutlu. D-RaNGe: Using Commodity DRAM Devices to Generate True Random Numbers with Low Latency and High Throughput. InHPCA, 2019
2019
-
[73]
Kim, Minesh Patel, Hasan Hassan, and Onur Mutlu
Jeremie S. Kim, Minesh Patel, Hasan Hassan, and Onur Mutlu. The DRAM Latency PUF: Quickly Evaluating Physical Unclonable Functions by Exploiting the Latency– Reliability Tradeoff in Modern Commodity DRAM Devices. InHPCA, 2018
2018
-
[74]
DR-STRaNGe: End-to-End System Design for DRAM-Based True Random Number Generators
F Nisa Bostancı, Ataberk Olgun, Lois Orosa, A Giray Yağlıkçı, Jeremie S Kim, Hasan Hassan, Oğuz Ergin, and Onur Mutlu. DR-STRaNGe: End-to-End System Design for DRAM-Based True Random Number Generators. InHPCA, 2022
2022
-
[75]
PiDRAM: A Holistic End-to-end FPGA-based Framework for Processing-in-DRAM.TACO, 2022
Ataberk Olgun, Juan Gómez Luna, Konstantinos Kanellopoulos, Behzad Salami, Hasan Hassan, Oguz Ergin, and Onur Mutlu. PiDRAM: A Holistic End-to-end FPGA-based Framework for Processing-in-DRAM.TACO, 2022
2022
-
[76]
In-Memory Low-Cost Bit-Serial Addition Using Commodity DRAM Technology
Mustafa F Ali, Akhilesh Jaiswal, and Kaushik Roy. In-Memory Low-Cost Bit-Serial Addition Using Commodity DRAM Technology. InTCAS I, 2019
2019
-
[77]
GraphiDe: A Graph Processing Accelerator Leveraging In-DRAM-Computing
Shaahin Angizi and Deliang Fan. GraphiDe: A Graph Processing Accelerator Leveraging In-DRAM-Computing. InGLSVLSI, 2019
2019
-
[78]
SCOPE: A Stochastic Computing Engine for DRAM-Based In-Situ Accelerator
Shuangchen Li, Alvin Oliver Glova, Xing Hu, Peng Gu, Dimin Niu, Krishna T Malladi, Hongzhong Zheng, Bob Brennan, and Yuan Xie. SCOPE: A Stochastic Computing Engine for DRAM-Based In-Situ Accelerator. InMICRO, 2018
2018
-
[79]
Parallel Automata Processor
Arun Subramaniyan and Reetuparna Das. Parallel Automata Processor. InISCA, 2017
2017
-
[80]
Hyper-AP: Enhancing Associative Processing through a Full-Stack Optimization
Yue Zha and Jing Li. Hyper-AP: Enhancing Associative Processing through a Full-Stack Optimization. InISCA, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.