Backdoor Attacks on Speech Emotion Recognition via TTS-Generated Poisoning
Pith reviewed 2026-06-26 13:25 UTC · model grok-4.3
The pith
Speech emotion recognition models can be backdoored with high success rates using TTS-generated poisoned audio at low poisoning ratios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SER models can be reliably compromised with high attack success rates under low poisoning ratios, while maintaining near-clean performance on benign inputs. A stealthy low-energy acoustic trigger is embedded imperceptibly into both natural and synthetic speech, enabling scalable and consistent poisoning via TTS. Backdoor patterns exhibit strong cross-model transferability, and self-supervised representations prove particularly susceptible to learning these triggers.
What carries the argument
A stealthy low-energy acoustic trigger embedded imperceptibly into TTS-generated speech to create scalable poisoned training samples for SER backdoor attacks.
If this is right
- SER models are compromised at high attack success rates even with low poisoning ratios.
- Backdoor patterns transfer across different models.
- Self-supervised acoustic representations are especially prone to learning the triggers.
- TTS generation lowers the barrier to creating consistent poisoned samples for SER attacks.
- These vulnerabilities in modern SER pipelines call for dedicated defenses.
Where Pith is reading between the lines
- The same TTS-based poisoning approach could be adapted to other speech tasks such as speaker identification or automatic speech recognition.
- Training pipelines may need new checks for anomalous low-energy patterns that appear only in synthetic audio.
- Transferability implies an attacker could craft the trigger once and apply it against multiple deployed SER systems without retraining.
- Real-world SER training that mixes public and synthetic data increases exposure to this class of attack.
Load-bearing premise
A single acoustic trigger remains imperceptible when added to both real and synthetic speech and is reliably learned by self-supervised models during standard training.
What would settle it
An experiment in which the trigger is detected by human listeners or in which standard training on the poisoned dataset fails to produce high attack success rates would disprove the central claim.
Figures

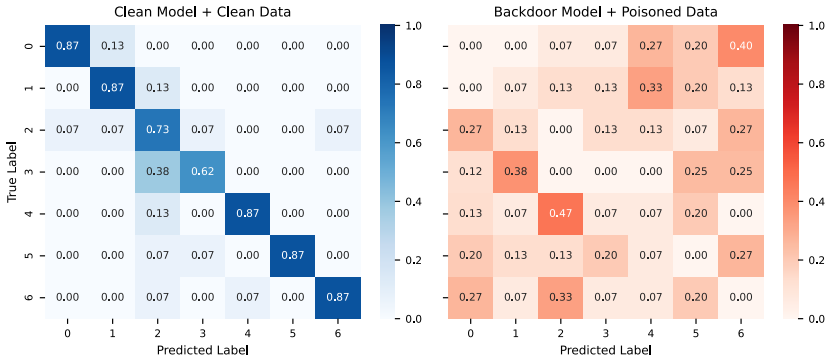
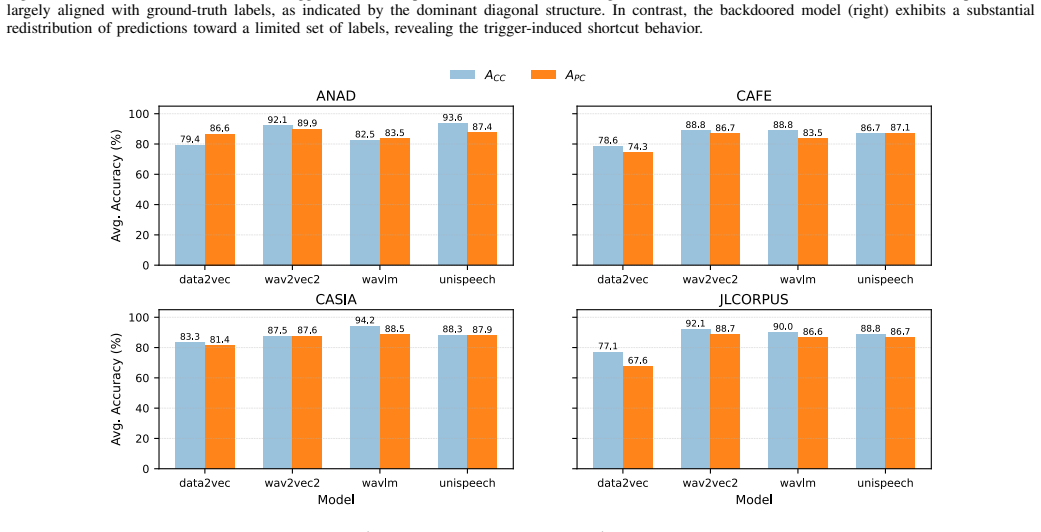
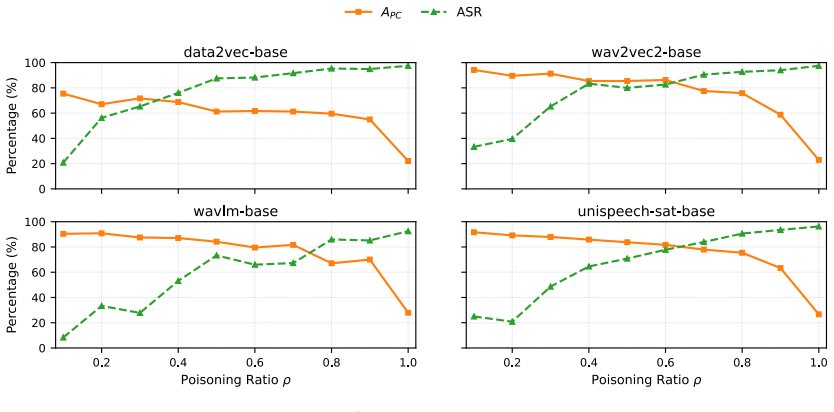
read the original abstract
Speech Emotion Recognition (SER) systems increasingly leverage self-supervised acoustic representations, yet their vulnerability to training-time attacks remains largely underexplored. This paper presents the first systematic study of poisoning-based backdoor attacks on SER, with a focus on threats enabled by text-to-speech (TTS) generated audio. We introduce a stealthy, low-energy acoustic trigger that can be embedded imperceptibly into both natural and synthetic speech, enabling scalable and consistent poisoning. Our experiments demonstrate that SER models can be reliably compromised with high attack success rates under low poisoning ratios, while maintaining near-clean performance on benign inputs. We further show that backdoor patterns exhibit strong cross-model transferability and that self-supervised representations are particularly susceptible to learning these triggers. These findings reveal that TTS technology dramatically lowers the barrier to effective backdoor attacks, exposing critical vulnerabilities in modern SER pipelines and motivating the urgent need for dedicated defenses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first systematic study of poisoning-based backdoor attacks on Speech Emotion Recognition (SER) systems, focusing on threats enabled by text-to-speech (TTS) generated audio. It introduces a stealthy, low-energy acoustic trigger embeddable imperceptibly into both natural and synthetic speech for scalable poisoning. Experiments are claimed to show that SER models (particularly self-supervised ones) can be reliably compromised with high attack success rates at low poisoning ratios while preserving near-clean performance on benign inputs, with strong cross-model transferability of the backdoor patterns.
Significance. If the empirical results hold with the claimed quantitative support, this would represent a meaningful extension of backdoor attack research into the audio/SER domain. It would demonstrate that TTS technology substantially lowers the barrier for effective poisoning attacks on self-supervised acoustic representations, while highlighting the need for domain-specific defenses. The work's value would lie in its focus on realistic, low-poisoning-ratio scenarios and cross-model transfer, assuming the experiments are fully specified and reproducible.
major comments (2)
- [Methods] The experimental setup is not described in sufficient detail to support the central claims. The Methods section provides no definition of the acoustic trigger (e.g., its frequency content, energy level, or embedding procedure), no specification of the datasets or data splits, no exact poisoning ratios tested, and no quantitative results (attack success rates, clean accuracies, or statistical significance). This renders the assertions of 'high attack success rates under low poisoning ratios' and 'near-clean performance' unverifiable.
- [Results] The Results section lacks any tables, figures, or numerical values reporting attack success rates, clean accuracy, or transferability metrics across models and conditions. Without these data, it is impossible to assess whether the evidence supports the claims of reliable compromise, stealthiness, or particular susceptibility of self-supervised representations.
minor comments (1)
- [Abstract] The abstract asserts this is the 'first systematic study' without referencing or contrasting against any prior backdoor work in audio or SER to establish the novelty claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater experimental detail and quantitative reporting. We agree that these elements are essential for verifying the central claims and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Methods] The experimental setup is not described in sufficient detail to support the central claims. The Methods section provides no definition of the acoustic trigger (e.g., its frequency content, energy level, or embedding procedure), no specification of the datasets or data splits, no exact poisoning ratios tested, and no quantitative results (attack success rates, clean accuracies, or statistical significance). This renders the assertions of 'high attack success rates under low poisoning ratios' and 'near-clean performance' unverifiable.
Authors: We acknowledge that the current manuscript version does not provide these specifications in the Methods section. This omission prevents independent verification of the claims. In the revised manuscript we will expand the Methods section to define the acoustic trigger (frequency content, energy level, embedding procedure), specify the datasets and splits used, list the exact poisoning ratios tested, and report quantitative results including attack success rates, clean accuracies, and statistical significance where applicable. revision: yes
-
Referee: [Results] The Results section lacks any tables, figures, or numerical values reporting attack success rates, clean accuracy, or transferability metrics across models and conditions. Without these data, it is impossible to assess whether the evidence supports the claims of reliable compromise, stealthiness, or particular susceptibility of self-supervised representations.
Authors: We agree that the submitted Results section contains no tables, figures, or numerical values. This is a clear deficiency. The revised manuscript will include dedicated results tables and figures reporting attack success rates, clean accuracies, transferability metrics, and comparisons across models and conditions to substantiate the claims of reliable compromise at low poisoning ratios and cross-model transferability. revision: yes
Circularity Check
No significant circularity
full rationale
This is a purely empirical paper describing backdoor attack experiments on SER models using TTS poisoning. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on experimental outcomes (attack success rates, clean accuracy, transferability) rather than any self-referential definitions or reductions to inputs by construction. The work is self-contained as standard empirical security research.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Survey on speech emotion recognition: Features, classification schemes, and databases,
M. El Ayadi, M. S. Kamel, and F. Karray, “Survey on speech emotion recognition: Features, classification schemes, and databases,”Pattern Recognition, vol. 44, no. 3, pp. 572–587, 2011. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0031320310004619
2011
-
[2]
A comprehensive review of speech emotion recognition systems,
T. M. Wani, T. S. Gunawan, S. A. A. Qadri, M. Kartiwi, and E. Am- bikairajah, “A comprehensive review of speech emotion recognition systems,”IEEE Access, vol. 9, pp. 47 795–47 814, 2021
2021
-
[3]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,”
-
[4]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
[Online]. Available: https://arxiv.org/abs/2006.11477
-
[5]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, p. 1505–1518, Oct. 2022. [Online]....
-
[6]
data2vec: A general framework for self-supervised learning in speech, vision and language,
A. Baevski, W.-N. Hsu, Q. Xu, A. Babu, J. Gu, and M. Auli, “data2vec: A general framework for self-supervised learning in speech, vision and language,” 2022. [Online]. Available: https://arxiv.org/abs/2202.03555
-
[7]
Badnets: Evaluating backdooring attacks on deep neural networks,
T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, “Badnets: Evaluating backdooring attacks on deep neural networks,”IEEE Access, vol. 7, pp. 47 230–47 244, 2019
2019
-
[8]
Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning
X. Chen, C. Liu, B. Li, K. Lu, and D. Song, “Targeted backdoor attacks on deep learning systems using data poisoning,”CoRR, vol. abs/1712.05526, 2017. [Online]. Available: http://arxiv.org/abs/1712.05526
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
Speech emotion recognition systems and their security aspects,
I. Gurowiec and N. Nissim, “Speech emotion recognition systems and their security aspects,”Artificial Intelligence Review, vol. 57, no. 6, p. 148, 2024. [Online]. Available: https://doi.org/10.1007/s10462-024- 10760-z
-
[10]
Badtts: Identifying vulnerabilities in neural text-to-speech models,
R. Zhang, H. Li, W. Jiang, R. Zhang, and J. He, “Badtts: Identifying vulnerabilities in neural text-to-speech models,” inGLOBECOM 2024 - 2024 IEEE Global Communications Conference, 2024, pp. 3146–3151
2024
-
[11]
Fake the real: Back- door attack on deep speech classification via voice conversion,
Z. Ye, T. Mao, L. Dong, and D. Yan, “Fake the real: Back- door attack on deep speech classification via voice conversion,” in Proc. INTERSPEECH, Aug. 2023, pp. 4923–4927, [Online]. Available: http://dx.doi.org/10.21437/Interspeech.2023-733
-
[12]
A. Fortier, T. Thebaud, J. Villalba, N. Dehak, and P. Cardinal, “Backdoor attacks against speech language models,” 2025. [Online]. Available: https://arxiv.org/abs/2510.01157
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
A systematic evaluation of adversarial attacks against speech emotion recognition models,
N. Facchinetti, F. Simonetta, and S. Ntalampiras, “A systematic evaluation of adversarial attacks against speech emotion recognition models,”Intelligent Computing, vol. 3, Jan. 2024. [Online]. Available: http://dx.doi.org/10.34133/icomputing.0088
-
[14]
Devil in the room: triggering audio backdoors in the physical world,
M. Chen, X. Xu, L. Lu, Z. Ba, K. Ren, and F. Lin, “Devil in the room: triggering audio backdoors in the physical world,” inProceedings of the 33rd USENIX Conference on Security Symposium, ser. SEC ’24. USA: USENIX Association, 2024
2024
-
[15]
Can you hear it?: Backdoor attacks via ultrasonic triggers,
S. Koffas, J. Xu, M. Conti, and S. Picek, “Can you hear it?: Backdoor attacks via ultrasonic triggers,” inProceedings of the 2022 ACM Workshop on Wireless Security and Machine Learning, ser. WiSec ’22. ACM, May 2022, p. 57–62. [Online]. Available: http://dx.doi.org/10.1145/3522783.3529523
-
[16]
Towards stealthy backdoor attacks against speech recognition via elements of sound,
H. Cai, P. Zhang, H. Dong, Y . Xiao, S. Koffas, and Y . Li, “Towards stealthy backdoor attacks against speech recognition via elements of sound,” 2023. [Online]. Available: https://arxiv.org/abs/2307.08208
-
[17]
W. Yao, J. Yang, Y . He, J. Liu, and W. Wen, “Imperceptible rhythm backdoor attacks: Exploring rhythm transformation for embedding undetectable vulnerabilities on speech recognition,” 2024. [Online]. Available: https://arxiv.org/abs/2406.10932
-
[18]
Emoback: Backdoor attacks against speaker identification using emotional prosody,
C. Schoof, S. Koffas, M. Conti, and S. Picek, “Emoback: Backdoor attacks against speaker identification using emotional prosody,” 2024. [Online]. Available: https://arxiv.org/abs/2408.01178
-
[19]
Lrba: Stealthy backdoor attacks on speech classification via latent rearrangement in vits,
Z. Li, W. Yao, Y . Xiao, J. Yang, F. Xiao, and W. Wen, “Lrba: Stealthy backdoor attacks on speech classification via latent rearrangement in vits,” inProc. Interspeech 2025, 08 2025, pp. 5653–5657
2025
-
[20]
Cba: Backdoor attack on deep speech classification via audio compression,
Y . Huang, Y . Ren, W. Zhang, and D. Yan, “Cba: Backdoor attack on deep speech classification via audio compression,” inProc. Interspeech 2025, 08 2025, pp. 5648–5652
2025
-
[21]
Enhancing robustness against adversarial attacks in multimodal emotion recognition with spiking transformers,
G. Chen, Z. Qian, D. Zhang, S. Qiu, and R. Zhou, “Enhancing robustness against adversarial attacks in multimodal emotion recognition with spiking transformers,”IEEE Access, vol. 13, pp. 34 584–34 597, 2025
2025
-
[22]
Noise-robust speech emotion recognition using shared self-supervised representations with integrated speech enhancement,
J.-T. Tzeng, S.-G. Leem, A. N. Salman, C.-C. Lee, and C. Busso, “Noise-robust speech emotion recognition using shared self-supervised representations with integrated speech enhancement,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[23]
Robust multi-scenario speech-based emotion recognition system,
F. Zhu-Zhou, R. Gil-Pita, J. Garc ´ıa-G´omez, and M. Rosa- Zurera, “Robust multi-scenario speech-based emotion recognition system,”Sensors, vol. 22, no. 6, 2022. [Online]. Available: https://www.mdpi.com/1424-8220/22/6/2343
2022
-
[24]
An overview of the icassp special session on ai security and privacy in speech and audio processing,
Z. Ren, K. Qian, T. Schultz, and B. W. Schuller, “An overview of the icassp special session on ai security and privacy in speech and audio processing,” inProceedings of the 5th ACM International Conference on Multimedia in Asia Workshops, ser. MMAsia ’23 Workshops. New York, NY , USA: Association for Computing Machinery, 2023. [Online]. Available: https:/...
-
[25]
Arabic natural audio dataset,
S. Klaylat, Z. Osman, L. Hamandi, and R. Zantout, “Arabic natural audio dataset,” 2018
2018
-
[26]
A canadian french emotional speech dataset,
P. Gournay, O. Lahaie, and R. Lefebvre, “A canadian french emotional speech dataset,”Proceedings of the 9th ACM Multimedia Systems Conference, 2018. [Online]. Available: https://api.semanticscholar.org/CorpusID:49644035
2018
-
[27]
The casia audio emotion recognition method for audio/visual emotion challenge 2011,
S. Pan, J. Tao, and Y . Li, “The casia audio emotion recognition method for audio/visual emotion challenge 2011,” inAffective Computing and Intelligent Interaction (ACII 2011): Fourth International Conference, ser. Lecture Notes in Computer Science (LNCS), vol. 6975. Springer, Oct. 2011, pp. 388–395
2011
-
[28]
An open source emotional speech corpus for human robot interaction applications,
J. James, L. Tian, and C. Watson, “An open source emotional speech corpus for human robot interaction applications,” inProc. Interspeech, 2018
2018
-
[29]
Unispeech-sat: Universal speech representation learning with speaker aware pre-training,
S. Chen, Y . Wu, C. Wang, Z. Chen, Z. Chen, S. Liu, J. Wu, Y . Qian, F. Wei, J. Li, and X. Yu, “Unispeech-sat: Universal speech representation learning with speaker aware pre-training,” 2021. [Online]. Available: https://arxiv.org/abs/2110.05752
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.