Training the Orchestrator: A Supervised Approach to End-to-End PDDL Planning with LLM Agents
Pith reviewed 2026-06-26 13:54 UTC · model grok-4.3
The pith
A trained lightweight policy can orchestrate LLM planning agents as effectively as a frontier model but at a fraction of the cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
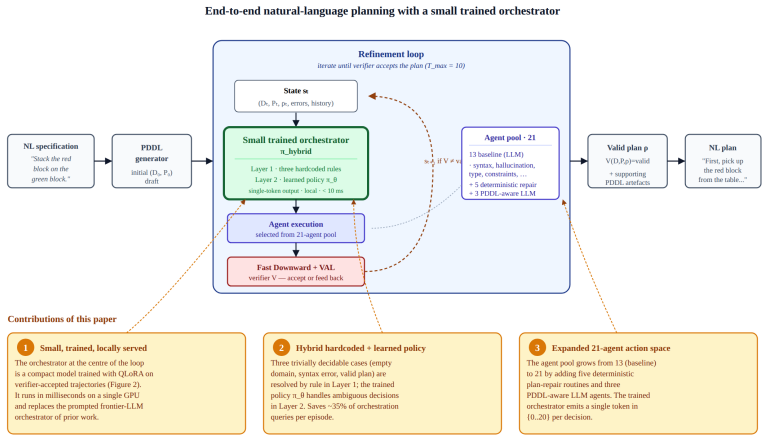
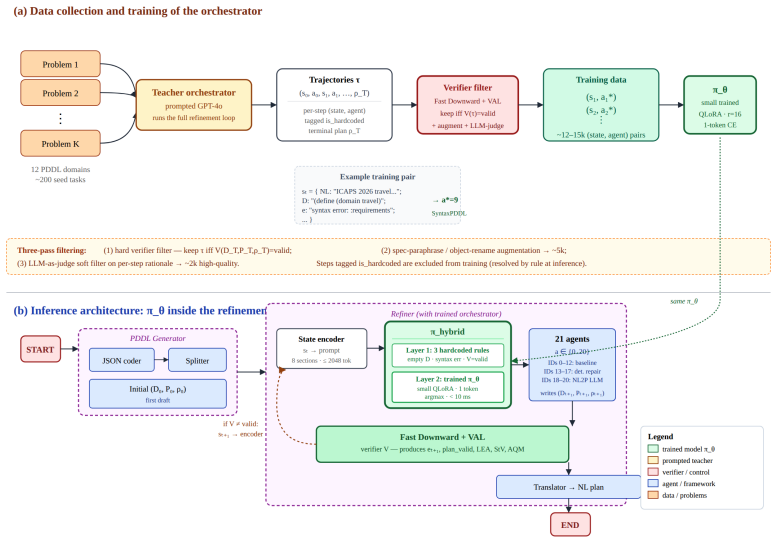
HALO trains the orchestrator from refinement trajectories that an external verifier has certified as ending in valid plans across 11 PDDL domains. It pairs a small QLoRA-tuned policy with three hardcoded rules for trivially decidable selections and operates over an expanded 21-agent action space. The verifier provides strong guidance because every accepted trajectory is a sequence of demonstrably correct state-agent decisions directly usable as supervision. This allows HALO to match or exceed the GPT-5-mini prompted baseline on success rate while sitting within three percentage points of the stronger Gemini-3-Flash baseline.
What carries the argument
HALO, a hybrid agent-learned orchestrator that uses a QLoRA-tuned policy trained on verified trajectories to select agents, supplemented by hardcoded rules.
If this is right
- HALO achieves success rates matching or exceeding the GPT-5-mini prompted baseline.
- HALO stays within three percentage points of the Gemini-3-Flash prompted baseline.
- Orchestration cost drops from $0.18 to $0.004 per task against GPT-5-mini, a roughly 45 times reduction.
- Total LLM calls per episode are cut by 40 to 50 percent.
- These results hold across PlanBench, Natural Plan, and classical planning benchmarks.
Where Pith is reading between the lines
- This supervised training method could be applied to other multi-agent orchestration problems where a verifier can certify successful trajectories.
- Lowering the cost of orchestration might make end-to-end LLM planning feasible for a wider range of users and applications.
- Future work could explore whether the trained policy generalizes to new domains without additional verifier data.
Load-bearing premise
The verifier already provides strong guidance because every accepted trajectory consists of demonstrably correct decisions that can serve directly as supervision signals.
What would settle it
A test showing that the trained HALO policy selects incorrect agents at a rate high enough to drop success rates significantly below the prompted baselines on the same benchmarks would falsify the central claim.
Figures
read the original abstract
Translating natural-language planning intent into verified plans is a longstanding challenge: people communicate goals in language, while classical planners require formal PDDL specifications. Recent agentic frameworks bridge this gap by orchestrating a pool of specialized repair agents inside a verifier-checked refinement loop, but the orchestrator at the centre is itself a prompted frontier LLM, paying a frontier-LLM API call at every refinement step. We present HALO (Hybrid Agent-Learned Orchestrator), which trains the orchestrator from refinement trajectories that an external verifier has certified as ending in valid plans, across 11 PDDL domains. HALO pairs a small QLoRA-tuned policy with three hardcoded rules for trivially decidable selections, and operates over an expanded 21-agent action space. Unlike approaches that prompt a frontier LLM at every step or learn an orchestrator from sparse end-of-episode rewards, our key observation is that the verifier already provides strong guidance: every accepted trajectory is a sequence of demonstrably correct (state, agent) decisions, directly usable as supervision. Across PlanBench, Natural Plan, and classical planning benchmarks, HALO matches or exceeds the GPT-5-mini prompted baseline on success rate, sits within three percentage points of the stronger Gemini-3-Flash prompted baseline, reduces orchestration cost by more than an order of magnitude (\$0.18 to \$0.004 per task against GPT-5-mini, roughly 45$\times$ cheaper; roughly 15$\times$ cheaper than Gemini-3-Flash), and cuts total LLM calls per episode by 40 to 50 percent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HALO, a hybrid orchestrator for LLM-based PDDL planning that replaces a prompted frontier LLM with a small QLoRA-tuned policy trained via supervised imitation on trajectories certified as valid by an external verifier. The policy operates over a 21-agent action space alongside three hardcoded rules and is evaluated on PlanBench, Natural Plan, and classical planning benchmarks, where it matches or exceeds the GPT-5-mini baseline on success rate, stays within 3 points of Gemini-3-Flash, reduces orchestration cost by 15-45×, and cuts total LLM calls per episode by 40-50%.
Significance. If the empirical results hold under the reported experimental protocol, the work demonstrates that verifier-certified trajectories supply sufficiently dense supervision to train a lightweight policy that can replace repeated frontier-LLM calls for orchestration. This yields a concrete, reproducible cost reduction while preserving end-to-end success rates across 11 domains, strengthening the case for hybrid learned-orchestrator designs in agentic planning systems.
minor comments (2)
- The abstract states concrete success-rate and cost figures but does not define the precise baselines (e.g., exact prompting templates or temperature settings for GPT-5-mini and Gemini-3-Flash) or report per-domain statistics; the full paper should include these in §4 or a dedicated experimental appendix so readers can reproduce the comparison.
- The description of the 21-agent action space and the three hardcoded rules is given only at a high level; a table or pseudocode listing the exact agent names and the decision logic for the hardcoded cases would improve clarity in §3.2.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments were raised in the report, so we have no specific points requiring rebuttal or revision at this stage.
Circularity Check
No significant circularity
full rationale
The derivation relies on supervised training of a small policy (QLoRA-tuned) from trajectories that an external verifier has already certified as ending in valid plans across 11 domains. This is standard imitation learning: the verifier supplies the (state, agent) labels directly, independent of the learned model or any fitted parameters within the paper. The abstract explicitly contrasts this with both frontier-LLM prompting at every step and sparse end-of-episode reward learning, confirming the supervision signal is external rather than self-generated. No equations, self-citations, or uniqueness claims reduce the result to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- QLoRA adaptation rank and scaling
axioms (1)
- domain assumption Verifier-certified trajectories consist of demonstrably correct (state, agent) decisions usable as direct supervision
Reference graph
Works this paper leans on
-
[1]
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency , author=. arXiv preprint arXiv:2304.11477 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2405.19793 , year=
PDDLEGO: Iterative Planning in Textual Environments , author=. arXiv preprint arXiv:2405.19793 , year=
-
[3]
arXiv preprint arXiv:2308.06391 , year=
Dynamic Planning with a LLM , author=. arXiv preprint arXiv:2308.06391 , year=
-
[4]
arXiv preprint arXiv:2406.10196 , year=
TRIP-PAL: Travel Planning with Guarantees by Combining Large Language Models and Automated Planners , author=. arXiv preprint arXiv:2406.10196 , year=
-
[5]
NeurIPS , year=
Leveraging Pre-trained Large Language Models to Construct and Utilize World Models for Model-based Task Planning , author=. NeurIPS , year=
-
[6]
arXiv preprint arXiv:2307.07696 , year=
Coupling Large Language Models with Logic Programming for Robust and General Reasoning from Text , author=. arXiv preprint arXiv:2307.07696 , year=
-
[7]
2025 , eprint=
Large Language Models Can Solve Real-World Planning Rigorously with Formal Verification Tools , author=. 2025 , eprint=
2025
-
[8]
Llms can't plan, but can help planning in llm-modulo frameworks, 2024
LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks , author=. arXiv preprint arXiv:2402.01817 , year=
-
[9]
ICLR , year=
Synapse: Trajectory-as-Exemplar Prompting with Memory for Computer Control , author=. ICLR , year=
-
[10]
UIST , year=
Generative Agents: Interactive Simulacra of Human Behavior , author=. UIST , year=
-
[11]
arXiv preprint arXiv:2310.10134 , year=
CLIN: A Continually Learning Language Agent for Rapid Task Adaptation and Generalization , author=. arXiv preprint arXiv:2310.10134 , year=
-
[12]
arXiv preprint arXiv:2309.11436 , year=
You Only Look at Screens: Multimodal Chain-of-Action Agents , author=. arXiv preprint arXiv:2309.11436 , year=
-
[13]
arXiv preprint arXiv:2403.12881 , year=
Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models , author=. arXiv preprint arXiv:2403.12881 , year=
-
[14]
Fireact: Toward language agent fine-tuning
FireAct: Toward Language Agent Fine-tuning , author=. arXiv preprint arXiv:2310.05915 , year=
-
[15]
Kechi Zhang, Jia Li, Ge Li, Xianjie Shi, and Zhi Jin
AgentTuning: Enabling Generalized Agent Abilities for LLMs , author=. arXiv preprint arXiv:2310.12823 , year=
-
[16]
arXiv preprint arXiv:2403.02502 , year=
Trial and Error: Exploration-Based Trajectory Optimization for LLM Agents , author=. arXiv preprint arXiv:2403.02502 , year=
-
[17]
arXiv preprint , year=
OpenCodeReasoning: Advancing Data Distillation for Competitive Coding , author=. arXiv preprint , year=
-
[18]
2023 , eprint=
QLoRA: Efficient Finetuning of Quantized LLMs , author=. 2023 , eprint=
2023
-
[19]
arXiv preprint arXiv:2411.02337 , year=
WebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning , author=. arXiv preprint arXiv:2411.02337 , year=
-
[20]
Training Language Models to Self-Correct via Reinforcement Learning
Training Language Models to Self-Correct via Reinforcement Learning , author=. arXiv preprint arXiv:2409.12917 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
arXiv preprint arXiv:2406.14283 , year=
Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning , author=. arXiv preprint arXiv:2406.14283 , year=
-
[22]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
NeurIPS , year=
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face , author=. NeurIPS , year=
-
[24]
arXiv preprint , year=
RaDA: Retrieval-augmented Web Agent Planning with LLMs , author=. arXiv preprint , year=
-
[25]
arXiv preprint arXiv:2410.18963 , year=
OSCAR: Operating System Control via State-Aware Reasoning and Re-Planning , author=. arXiv preprint arXiv:2410.18963 , year=
-
[26]
arXiv preprint arXiv:2406.06485 , year=
Can Language Models Serve as Text-Based World Simulators? , author=. arXiv preprint arXiv:2406.06485 , year=
-
[27]
arXiv preprint , year=
Plan-RAG: A Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers , author=. arXiv preprint , year=
-
[28]
arXiv preprint , year=
UrbanLLM: Autonomous Urban Activity Planning and Management with Large Language Models , author=. arXiv preprint , year=
-
[29]
NeurIPS , year=
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author=. NeurIPS , year=
-
[30]
arXiv preprint , year=
SearChain: Adaptive Information Retrieval Chain for Multi-Turn Question Answering , author=. arXiv preprint , year=
-
[31]
AAAI , year=
Graph of Thoughts: Solving Elaborate Problems with Large Language Models , author=. AAAI , year=
-
[32]
ICLR , year=
Tree-Planner: Efficient Close-loop Task Planning with Large Language Models , author=. ICLR , year=
-
[33]
ICLR , year=
ToolChain*: Efficient Action Space Navigation in Large Language Models with A* Search , author=. ICLR , year=
-
[34]
EMNLP , year=
Reasoning with Language Model is Planning with World Model , author=. EMNLP , year=
-
[35]
arXiv preprint arXiv:2405.03553 , year=
AlphaMath Almost Zero: Process Supervision Without Process , author=. arXiv preprint arXiv:2405.03553 , year=
-
[36]
arXiv preprint , year=
SynWorld: Virtual Scenario Synthesis for Agentic Action Knowledge Refinement , author=. arXiv preprint , year=
-
[37]
arXiv preprint arXiv:2403.00092 , year=
Proc2PDDL: Open-Domain Planning Representations from Texts , author=. arXiv preprint arXiv:2403.00092 , year=
-
[38]
NeurIPS Workshop , year=
Planetarium: A Rigorous Benchmark for Translating Text to Structured Planning Languages , author=. NeurIPS Workshop , year=
-
[39]
arXiv preprint arXiv:2311.09830 , year=
AutoPlanBench: Automatically Generating Benchmarks for LLM Planners from PDDL , author=. arXiv preprint arXiv:2311.09830 , year=
-
[40]
EMNLP , year=
Unlocking the Future: Exploring Look-Ahead Planning Mechanistic Interpretability in Large Language Models , author=. EMNLP , year=
-
[41]
arXiv preprint arXiv:2405.04776 , year=
Chain of Thoughtlessness: An Analysis of CoT in Planning , author=. arXiv preprint arXiv:2405.04776 , year=
-
[42]
GitHub , year=
ToolOrchestra: An End-to-End RL Training Framework for Orchestrating Tools and Agentic Workflows , author=. GitHub , year=
-
[43]
arXiv preprint , year=
TinyAgent: Function Calling at the Edge , author=. arXiv preprint , year=
-
[44]
arXiv preprint , year=
Hammer: Robust Function-Calling for On-Device Language Models via Function Masking , author=. arXiv preprint , year=
-
[45]
arXiv preprint arXiv:2503.18809 , year=
Classical Planning with LLM-Generated Heuristics: Challenging the State of the Art with Python Code , author=. arXiv preprint arXiv:2503.18809 , year=
-
[46]
AAAI , year=
Generalized Planning in PDDL Domains with Pretrained Large Language Models , author=. AAAI , year=
-
[47]
arXiv preprint arXiv:2501.18784 , year=
LLM-Generated Heuristics for AI Planning: Do We Even Need Domain-Independence Anymore? , author=. arXiv preprint arXiv:2501.18784 , year=
-
[48]
Nature , year=
Mathematical Discoveries from Program Search with Large Language Models , author=. Nature , year=
-
[49]
2004 , publisher=
Automated Planning: Theory and Practice , author=. 2004 , publisher=
2004
-
[50]
Technical Report , year=
PDDL: The Planning Domain Definition Language , author=. Technical Report , year=
-
[51]
arXiv preprint arXiv:2403.03101 , year=
KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents , author=. arXiv preprint arXiv:2403.03101 , year=
-
[52]
End-to-end PDDL Planning with Hardcoded and Dynamic Agents
End-to-end PDDL Planning with Hardcoded and Dynamic Agents , author=. arXiv preprint arXiv:2512.09629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Advances in Neural Information Processing Systems , volume=
PlanBench: An Extensible Benchmark for Evaluating Large Language Models on Planning and Reasoning about Change , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
arXiv preprint arXiv:2405.04215 , year=
NL2Plan: Robust LLM-Driven Planning from Minimal Text Descriptions , author=. arXiv preprint arXiv:2405.04215 , year=
-
[55]
2025 , eprint=
How Far Are LLMs from Symbolic Planners? An NLP-Based Perspective , author=. 2025 , eprint=
2025
-
[56]
Advances in Neural Information Processing Systems , year=
Graph Neural Network Based Action Ranking for Planning , author=. Advances in Neural Information Processing Systems , year=
-
[57]
Proceedings of the International Conference on Automated Planning and Scheduling , volume=
GammaZero: Learning to Guide Belief-Space Search for Long-Horizon POMDPs with Generalizable Graph Representations , author=. Proceedings of the International Conference on Automated Planning and Scheduling , volume=
-
[58]
Journal of Artificial Intelligence Research , volume=
The Fast Downward Planning System , author=. Journal of Artificial Intelligence Research , volume=
-
[59]
Howey, Richard and Long, Derek and Fox, Maria , booktitle=
-
[60]
Proceedings of the International Conference on Automated Planning and Scheduling (ICAPS) , year=
Forward-Chaining Partial-Order Planning , author=. Proceedings of the International Conference on Automated Planning and Scheduling (ICAPS) , year=
-
[61]
Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics (AISTATS) , pages=
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning , author=. Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics (AISTATS) , pages=
-
[62]
Neural Computation , volume=
Efficient Training of Artificial Neural Networks for Autonomous Navigation , author=. Neural Computation , volume=
-
[63]
Proximal Policy Optimization Algorithms
Proximal Policy Optimization Algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
Zheng, Huaixiu Steven and Mishra, Swaroop and Zhang, Hugh and Chen, Xinyun and Chen, Minmin and Nova, Azade and Hou, Le and Cheng, Heng-Tze and Le, Quoc V. and Chi, Ed H. and Zhou, Denny , year=. 2406.04520 , archivePrefix=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.