Inverse Turing Bench: Evaluating Language Models as Judges of Human vs. AI Dialogue
Pith reviewed 2026-06-26 12:21 UTC · model grok-4.3
The pith
A new benchmark evaluates language models on identifying which of two dialogues is human-only versus human-AI.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes Inverse Turing Bench, a collection of paired dialogue transcripts in which one transcript records two humans talking and the other records a human talking with an AI; the required output is the correct label for which transcript is the human-only exchange. When a range of models is run on this task, GPTZero reaches 89.41 percent accuracy, Claude Opus-4.6 reaches 77.92 percent, and GPT-5.5 reaches 75.94 percent. The observed pattern is that statistical detection methods exhibit semantic blind spots while semantic methods are vulnerable to persona-prompting. The benchmark is presented as a probe of LLM theory of mind and as motivation for treating human-AI differentiation
What carries the argument
The paired dialogue transcripts (one human-human, one human-AI) that force a binary identification decision on which exchange is the human-only one.
If this is right
- Statistical detection methods overlook semantic content present in the dialogues.
- Semantic detection methods can be undermined when the model is given persona instructions.
- The benchmark functions as a probe of whether language models possess a theory of mind about conversational participants.
- Human-AI differentiation is positioned as a critical capability that future AI systems should possess.
Where Pith is reading between the lines
- The paired-transcript format could be reused to audit detection systems built for other media such as images or audio.
- High performance on the task may still reflect surface pattern matching rather than genuine social reasoning.
- The reported gap between statistical and semantic approaches suggests that hybrid detectors warrant direct testing on the same pairs.
- The benchmark's public leaderboard format allows ongoing comparison as new models appear.
Load-bearing premise
The collected paired dialogue transcripts accurately represent real-world human versus human-AI interactions without systematic biases in generation, selection, or labeling.
What would settle it
A fresh set of dialogue pairs collected and labeled by an independent process that produces markedly lower accuracy scores for the same top models would falsify the benchmark's reliability.
Figures

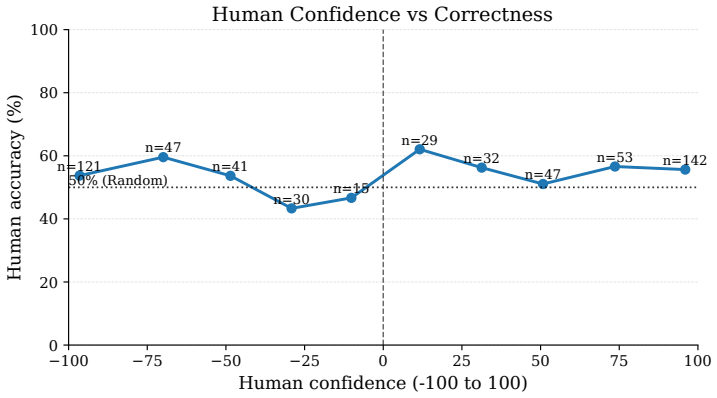

read the original abstract
As AI systems integrate into online spaces, differentiating them from humans in conversations is increasingly important. We present Inverse Turing Bench, a benchmark that evaluates LLMs and other models on their ability to differentiate humans and AI in multi-turn text. The benchmark provides a collection of paired dialogue transcripts, wherein one dialogue is between two humans and the other is between a human and an AI. The task is to correctly identify which dialogue is human-only vs. human-AI. We evaluated a preliminary set of models against this benchmark, and found that GPTZero, Claude Opus-4.6, and GPT-5.5 achieve the highest accuracy: 89.41%, 77.92%, and 75.94% respectively. Our results suggest that statistical approaches to detection have semantic blind spots, but semantic approaches are susceptible to persona-prompting. Our work speaks to the Inverse Turing Test as a probe of LLM theory of mind, and motivates human-AI differentiation as a critical capability for AI systems. Our live benchmark can be found at https://huggingface.co/spaces/roc-hci/Inverse-Turing-Bench-Leaderboard (anonymity preserved).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Inverse Turing Bench, a benchmark consisting of paired multi-turn dialogue transcripts (one human-human, one human-AI) to evaluate models' ability to identify which is which. It reports accuracies for a set of models, with GPTZero at 89.41%, Claude Opus-4.6 at 77.92%, and GPT-5.5 at 75.94%, and concludes that statistical detection methods exhibit semantic blind spots while semantic methods are vulnerable to persona-prompting; the work positions the benchmark as a probe of LLM theory of mind.
Significance. If the benchmark dataset is shown to be free of construction artifacts and representative of real interactions, the results would provide a concrete empirical test of models' capacity to perform an inverse Turing task, with potential value for both AI detection research and understanding emergent theory-of-mind behaviors in LLMs. The public leaderboard is a constructive element for ongoing evaluation.
major comments (1)
- [Abstract] Abstract (and benchmark description): The headline accuracies and the statistical-vs-semantic distinction are presented without any information on dialogue sourcing, AI generation procedure, length/topic matching, selection criteria, or labeling validation (e.g., inter-annotator agreement). This is load-bearing for the central claim, as undetected biases in pair construction could render the measured accuracies and blind-spot pattern artifacts of the benchmark rather than general properties of the evaluated models.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a point that affects the interpretability of our results. We address the concern directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (and benchmark description): The headline accuracies and the statistical-vs-semantic distinction are presented without any information on dialogue sourcing, AI generation procedure, length/topic matching, selection criteria, or labeling validation (e.g., inter-annotator agreement). This is load-bearing for the central claim, as undetected biases in pair construction could render the measured accuracies and blind-spot pattern artifacts of the benchmark rather than general properties of the evaluated models.
Authors: We agree that the abstract and the benchmark description section must supply sufficient information on construction to support the reported accuracies and the statistical-vs-semantic distinction. The current manuscript contains a Methods section that details sourcing, generation, and matching, but these elements are not summarized at the level the referee requests. In the revised version we will (1) expand the abstract with a concise paragraph on dialogue sourcing, AI generation procedure, length/topic matching criteria, selection rules, and validation steps, and (2) strengthen the benchmark description section to explicitly discuss how pair construction was designed to reduce artifacts and to report any quantitative checks performed. These changes will make the central claims more robust without altering the experimental results. revision: yes
Circularity Check
Empirical benchmark with no derivations or self-referential steps
full rationale
The paper describes an empirical benchmark consisting of paired dialogue transcripts (human-human vs. human-AI) and reports measured accuracies for various models on the identification task. No equations, derivations, fitted parameters, or mathematical claims appear in the provided text. Claims about statistical vs. semantic approaches are interpretive summaries of results rather than reductions by construction. No self-citations are invoked as load-bearing premises, and no ansatzes or uniqueness theorems are smuggled in. Data collection biases are a validity issue but do not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The paired dialogue transcripts are representative of real human and human-AI interactions without selection bias.
Reference graph
Works this paper leans on
-
[2]
Exploring the Limitations of Detecting Machine-Generated Text
Doughman, Jad and Mohammed Afzal, Osama and Toyin, Hawau Olamide and Shehata, Shady and Nakov, Preslav and Talat, Zeerak. Exploring the Limitations of Detecting Machine-Generated Text. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[6]
From Text to Source: Results in Detecting Large Language Model-Generated Content , volume=
Antoun, Wissam and Sagot, Benoit and Seddah, Djame , year=. From Text to Source: Results in Detecting Large Language Model-Generated Content , volume=. ACL Anthology , publisher=
-
[7]
MMTEB: Massive Multilingual Text Embedding Benchmark , url =
Kenneth Enevoldsen and Isaac Chung and Imene Kerboua and Márton Kardos and Ashwin Mathur and David Stap and Jay Gala and Wissam Siblini and Dominik Krzemiński and Genta Indra Winata and Saba Sturua and Saiteja Utpala and Mathieu Ciancone and Marion Schaeffer and Gabriel Sequeira and Diganta Misra and Shreeya Dhakal and Jonathan Rystrøm and Roman Solomatin...
-
[8]
2024 , eprint=
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference , author=. 2024 , eprint=
2024
-
[9]
2024 , url=
Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan , booktitle=. 2024 , url=
2024
-
[10]
2026 , eprint=
ARC-AGI-3: A New Challenge for Frontier Agentic Intelligence , author=. 2026 , eprint=
2026
-
[11]
LLMD et: A Third Party Large Language Models Generated Text Detection Tool
Wu, Kangxi and Pang, Liang and Shen, Huawei and Cheng, Xueqi and Chua, Tat-Seng. LLMD et: A Third Party Large Language Models Generated Text Detection Tool. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.139
-
[12]
Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security , pages =
He, Xinlei and Shen, Xinyue and Chen, Zeyuan and Backes, Michael and Zhang, Yang , title =. Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security , pages =. 2024 , isbn =. doi:10.1145/3658644.3670344 , abstract =
-
[13]
2024 , eprint=
M4GT-Bench: Evaluation Benchmark for Black-Box Machine-Generated Text Detection , author=. 2024 , eprint=
2024
-
[14]
TURINGBENCH : A Benchmark Environment for T uring Test in the Age of Neural Text Generation
Uchendu, Adaku and Ma, Zeyu and Le, Thai and Zhang, Rui and Lee, Dongwon. TURINGBENCH : A Benchmark Environment for T uring Test in the Age of Neural Text Generation. Findings of the Association for Computational Linguistics: EMNLP 2021. 2021. doi:10.18653/v1/2021.findings-emnlp.172
-
[15]
Naive psychology and the inverted Turing test , abstract =
Watt, Stuart , langid =. Naive psychology and the inverted Turing test , abstract =. 1996
1996
-
[16]
and Finn, Chelsea , title =
Mitchell, Eric and Lee, Yoonho and Khazatsky, Alexander and Manning, Christopher D. and Finn, Chelsea , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[17]
2026 , eprint=
TurnWise: The Gap between Single- and Multi-turn Language Model Capabilities , author=. 2026 , eprint=
2026
-
[18]
2026 , eprint=
Disclosure By Design: Identity Transparency as a Behavioural Property of Conversational AI Models , author=. 2026 , eprint=
2026
-
[19]
2025 , eprint=
Illusions of Intimacy: How Emotional Dynamics Shape Human-AI Relationships , author=. 2025 , eprint=
2025
-
[20]
Ai outperforms humans in establishing interpersonal closeness in emotionally engaging interactions, but only when labelled as human , url=
Kleinert, Tobias and Waldschütz, Marie and Blau, Julian and Heinrichs, Markus and Schiller, Bastian , year=. Ai outperforms humans in establishing interpersonal closeness in emotionally engaging interactions, but only when labelled as human , url=. Nature News , publisher=
-
[21]
H1 Adversarial Threat Report , url =
-
[22]
The spread of low-credibility content by Social Bots , url=
Shao, Chengcheng and Ciampaglia, Giovanni Luca and Varol, Onur and Yang, Kai-Cheng and Flammini, Alessandro and Menczer, Filippo , year=. The spread of low-credibility content by Social Bots , url=. Nature News , publisher=
-
[23]
Persuasive effects of political microtargeting in the age of Generative Artificial Intelligence | PNAS Nexus | oxford academic , url=
Simchon, Almog and Edwards, Matthew and Lewandowsky, Stephen , year=. Persuasive effects of political microtargeting in the age of Generative Artificial Intelligence | PNAS Nexus | oxford academic , url=. Oxford Academic , publisher=
-
[24]
Bots and Misinformation Spread on Social Media: Implications for
Himelein-Wachowiak,. Bots and Misinformation Spread on Social Media: Implications for. 2021 , keywords =. doi:10.2196/26933 , pages =
-
[25]
Reverse turing test using touchscreens and CAPTCHA , volume =
Yamamura, Akihiro , year =. Reverse turing test using touchscreens and CAPTCHA , volume =
-
[26]
2020 , eprint=
Deceiving computers in Reverse Turing Test through Deep Learning , author=. 2020 , eprint=
2020
-
[27]
Turing, A. M. , year =. I.---. Mind , volume =. doi:10.1093/mind/LIX.236.433 , urldate =
-
[28]
2026 , url =
Claude Code: Anthropic's Agentic Coding Tool , author =. 2026 , url =
2026
-
[29]
Humans welcome to observe
"Humans welcome to observe": A First Look at the Agent Social Network Moltbook , author=. 2026 , eprint=
2026
-
[30]
2022 , eprint=
OPT: Open Pre-trained Transformer Language Models , author=. 2022 , eprint=
2022
-
[31]
Proceedings of the National Academy of Sciences , author=
Large language models pass a standard three-party Turing test , volume=. Proceedings of the National Academy of Sciences , author=. 2026 , pages=. doi:10.1073/pnas.2524472123 , abstractNote=
-
[32]
Communications of the ACM , volume=
ELIZA—a computer program for the study of natural language communication between man and machine , author=. Communications of the ACM , volume=. 1966 , publisher=
1966
-
[33]
2025 , month = feb, day =
2025
-
[34]
2024 , month = aug, day =
2024
-
[35]
The Llama 3 Herd of Models , year =. 2407.21783 , archivePrefix=
-
[36]
2026 , month =
Anthropic , title =. 2026 , month =
2026
-
[37]
2026 , month =
OpenAI , title =. 2026 , month =
2026
-
[38]
2026 , eprint=
GPTZero: Robust Detection of LLM-Generated Texts , author=. 2026 , eprint=
2026
-
[39]
2020 , eprint=
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter , author=. 2020 , eprint=
2020
-
[40]
Scientific Reports , volume=
A global comparison of social media bot and human characteristics , author=. Scientific Reports , volume=. 2025 , publisher=
2025
-
[41]
Artificial Intelligence Review , year=
Lies, damned lies, and language statistics: a comprehensive review of risks from manipulation, persuasion, and deception with large language models , author=. Artificial Intelligence Review , year=
-
[42]
arXiv preprint arXiv:2602.21012 , year=
International ai safety report 2026 , author=. arXiv preprint arXiv:2602.21012 , year=
arXiv 2026
-
[43]
New media & society , volume=
The disconcerting potential of online disinformation: Persuasive effects of astroturfing comments and three strategies for inoculation against them , author=. New media & society , volume=. 2021 , publisher=
2021
-
[44]
2024 , eprint=
Sleeper Social Bots: a new generation of AI disinformation bots are already a political threat , author=. 2024 , eprint=
2024
-
[45]
Dennett, Daniel C. , year=. The problem with counterfeit people , url=. The Atlantic , publisher=
-
[46]
Psychonomic bulletin & review , volume=
Understanding individual differences in theory of mind via representation of minds, not mental states , author=. Psychonomic bulletin & review , volume=. 2019 , publisher=
2019
-
[47]
Uchendu, Adaku and Zeyu, Ma and Thai, Le and Zhang, Rui and Lee, Dongwon , urldate =
-
[48]
Exploring the Limitations of Detecting Machine-Generated Text , volume =
Doughman, Jad and Mohammed Afzal, Osama and Olamide Toyin, Hawau and Shehata, Shady and Nakov, Preslav and Talat, Zeerak , file =. Exploring the Limitations of Detecting Machine-Generated Text , volume =
-
[49]
Naive psychology and the inverted Turing test , abstract =
Watt, Stuart , langid =. Naive psychology and the inverted Turing test , abstract =
-
[50]
French, Robert M. , urldate =. The Turing Test: the first 50 years , volume =. doi:10.1016/S1364-6613(00)01453-4 , shorttitle =
-
[51]
Sejnowski, Terrence J. , urldate =. Large Language Models and the Reverse Turing Test , volume =. doi:10.1162/neco_a_01563 , abstract =
-
[52]
From Text to Source: Results in Detecting Large Language Model-Generated Content , volume =
-
[53]
Deception abilities emerged in large language models , volume =
Hagendorff, Thilo , urldate =. Deception abilities emerged in large language models , volume =
-
[54]
doi:10.3389/frai.2025.1569115 , shorttitle =
Romanishyn, Alexander and Malytska, Olena and Goncharuk, Vitaliy , urldate =. doi:10.3389/frai.2025.1569115 , shorttitle =
-
[55]
A Survey on LLM -Generated Text Detection: Necessity, Methods, and Future Directions
Wu, Junchao and Yang, Shu and Zhan, Runzhe and Yuan, Yulin and Sam Chao, Lidia and Fai Wong, Derek , date =. A Survey on. doi:10.1162/coli_a_00549 , pages =
-
[56]
A Survey on Evaluation of Large Language Models , volume =
Chang, Yupeng and Wang, Xu and Wang, Jindong and Wu, Yuan and Yang, Linyi and Zhu, Kaijie and Chen, Hao , date =. A Survey on Evaluation of Large Language Models , volume =
-
[57]
Abdali, Sara and Anarfi, Richard and Barberan, C. J. and He, Jia , urldate =. Decoding the. Proceedings of the 30th. doi:10.1145/3637528.3671463 , shorttitle =. 2403.05750 [cs] , keywords =
-
[58]
Dual Turing Test: A Framework for Detecting and Mitigating Undetectable
Messina, Alberto , urldate =. Dual Turing Test: A Framework for Detecting and Mitigating Undetectable. doi:10.48550/arXiv.2507.15907 , shorttitle =. 2507.15907 [cs] , keywords =
-
[59]
Evaluating & Reducing Deceptive Dialogue From Language Models with Multi-turn
Abdulhai, Marwa and Cheng, Ryan and Shrivastava, Aryansh and Jaques, Natasha and Gal, Yarin and Levine, Sergey , urldate =. Evaluating & Reducing Deceptive Dialogue From Language Models with Multi-turn. doi:10.48550/arXiv.2510.14318 , abstract =. 2510.14318 [cs] , keywords =
-
[60]
Adversarial Paraphrasing: A Universal Attack for Humanizing
Cheng, Yize and Sadasivan, Vinu Sankar and Saberi, Mehrdad and Saha, Shoumik and Feizi, Soheil , urldate =. Adversarial Paraphrasing: A Universal Attack for Humanizing. doi:10.48550/arXiv.2506.07001 , shorttitle =. 2506.07001 [cs] , keywords =
-
[61]
doi:10.1787/fae2d1e6-en , number =
Initial policy considerations for generative artificial intelligence , url =. doi:10.1787/fae2d1e6-en , number =
-
[62]
Jones, Cameron R. and Bergen, Benjamin K. , urldate =. Lies, Damned Lies, and Distributional Language Statistics: Persuasion and Deception with Large Language Models , url =. doi:10.48550/arXiv.2412.17128 , shorttitle =. 2412.17128 [cs] , keywords =
-
[63]
Large Language Models as Misleading Assistants in Conversation , url =
Hou, Betty Li and Shi, Kejian and Phang, Jason and Aung, James and Adler, Steven and Campbell, Rosie , urldate =. Large Language Models as Misleading Assistants in Conversation , url =. doi:10.48550/arXiv.2407.11789 , abstract =. 2407.11789 [cs] , keywords =
-
[64]
doi:10.32604/cmc.2025.073347 , shorttitle =
Xiang, Lingyun and Li, Nian and Liu, Yuling and Hu, Jiayong , urldate =. doi:10.32604/cmc.2025.073347 , shorttitle =
-
[65]
Does My Chatbot Have an Agenda? Understanding Human and
Yun, Bhada and Taranova, Evgenia and Wang, April Yi , urldate =. Does My Chatbot Have an Agenda? Understanding Human and. Proceedings of the 2026. doi:10.1145/3772318.3791620 , shorttitle =. 2601.22452 [cs] , keywords =
-
[66]
Does Social Bot Help Socialize? Evidence from a Microblogging Platform , volume =
Gao, Yang and Zhang, Maggie Mengqing and Lysyakov, Mikhail , urldate =. Does Social Bot Help Socialize? Evidence from a Microblogging Platform , volume =. doi:10.1287/isre.2024.1089 , shorttitle =
-
[67]
Humane Bench , url =
-
[68]
and Elsaid, Khaled and Almeer, Saeed , urldate =
Elkhatat, Ahmed M. and Elsaid, Khaled and Almeer, Saeed , urldate =. Evaluating the efficacy of. doi:https://doi.org/10.1007/s40979-023-00140-5 , journaltitle =
-
[69]
M4: Multi-generator, Multi-domain, and Multi-lingual Black-Box Machine-Generated Text Detection
Wang, Yuxia and Mansurov, Jonibek and Ivanov, Petar and Su, Jinyan and Shelmanov, Artem and Witehouse, Chenxie and Mohammed Afzal, Osama and Mahmoud, Tarek and Sasaki, Toru and Arnold, Thomas and Aji, Alham Fikri and Habash, Nizar and Gurevych, Iryna and Nakov, Preslav , date =. M4: Multi-generator, Multi-domain, and Multi-lingual Black-Box Machine-Genera...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.