ForEx: A Formal Verification Framework for Explainable Reasoning in Logical Fallacy Detection and Annotation
Pith reviewed 2026-06-26 12:13 UTC · model grok-4.3
The pith
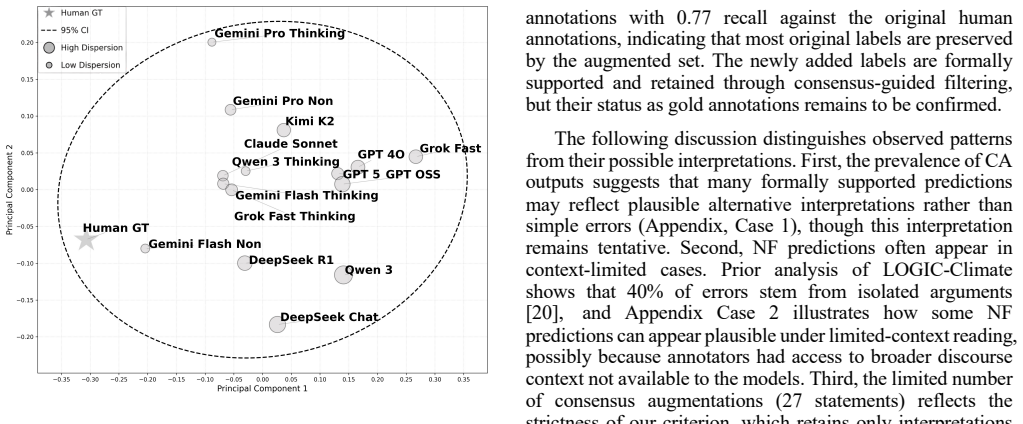
Formal checks pass for over 90 percent of LLM fallacy explanations while human label agreement stays near 20 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ForEx translates LLM-generated explanations for logical fallacy detection into Lean4 and checks derivability under encoded premises. On the LOGIC-Climate dataset this process succeeds for more than 90 percent of outputs, while agreement between the original LLM labels and human annotations remains around 20 percent. The LLM Argument Verification Matrix classifies each case by the two independent axes of label consistency and formal verification status, exposing cases where reasoning is formally supported yet still diverges from human judgment.
What carries the argument
The LLM Argument Verification Matrix, which cross-tabulates label match against formal verification status of the translated Lean4 chain.
If this is right
- Standard label-accuracy metrics for fallacy detection can report success even when the supporting reasoning is not formally derivable.
- High rates of formal verification do not imply high rates of agreement with human annotators on the same items.
- Evaluation can now track two separate dimensions: whether the model reaches the right label and whether its stated rationale is formally supported.
- Machine-checkable verification becomes a practical additional criterion for auditing LLM explanations.
Where Pith is reading between the lines
- The same translation-plus-verification pipeline could be applied to other tasks that require checking whether an LLM's justification actually entails its conclusion.
- Persistent gaps between verified reasoning and human labels may indicate that human annotations themselves embed unstated assumptions not captured in the formal premises.
- If translation fidelity can be improved, the framework offers a route to automated auditing of reasoning quality at scale without relying on additional human labels.
- Datasets that record both labels and explicit reasoning steps become more valuable because they enable this two-axis analysis.
Load-bearing premise
The automatic translation from an LLM's natural-language explanation into Lean4 statements preserves the original logical steps and support relations without adding, dropping, or altering content.
What would settle it
A side-by-side review by logicians in which a substantial fraction of the Lean4 translations are judged to misrepresent or omit key support relations present in the original LLM text.
Figures


read the original abstract
Current evaluations of Large Language Models (LLMs) on logical fallacy detection focus on predicted labels, but do not establish whether those labels are supported by the reasoning the models provide. We propose ForEx (Formal Verification for Explainable Reasoning), a framework that translates LLM-generated explanations into Lean4 and verifies whether the translated rationale is derivable under encoded premises, not the logical validity of the original natural language argument. To distinguish prediction outcomes from the formal status of the supporting reasoning, we introduce the LLM Argument Verification Matrix, which separates label consistency from formal verification status. Experiments on LOGIC-Climate show that over 90% of LLM outputs can be translated into formal reasoning chains that pass verification, while agreement with human annotations remains around 20%. These results expose a systematic gap between formal derivability and label agreement, a distinction invisible to prediction-based metrics. ForEx moves LLM evaluation beyond label correctness toward machine-checkable analysis of formalized reasoning chains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ForEx, a framework that translates LLM-generated natural-language explanations for logical fallacy detection into Lean4 formal reasoning chains, verifies their derivability under encoded premises, and introduces the LLM Argument Verification Matrix to separate label consistency from formal verification status. Experiments on the LOGIC-Climate dataset report that over 90% of LLM outputs yield formally verifiable chains while agreement with human annotations is around 20%, exposing a gap between formal derivability and label agreement that standard prediction metrics miss.
Significance. If the translation step faithfully preserves the original LLM rationale's premises, inferences, and conclusions without distortion, the results would establish that machine-checkable formal verification can surface reasoning properties invisible to label-based evaluation, providing a concrete advance in assessing explainable reasoning in LLMs. The framework's use of an external verifier and named dataset strengthens reproducibility potential, but the unvalidated translation step prevents the significance from being realized in the current manuscript.
major comments (2)
- [Abstract / §3] Abstract and §3 (translation/verification pipeline): The central claim that >90% of outputs are formally verifiable while human agreement is ~20% rests entirely on the assumption that the Lean4 encoding faithfully captures the LLM's original rationale without adding, omitting, or distorting support relations. No details are given on whether translation is manual, automated, or hybrid; no inter-annotator agreement for formalizations; and no audit or fidelity metric is reported. This is load-bearing for the distinction claim, as systematic strengthening during translation would inflate the verification rate without reflecting the actual LLM reasoning.
- [§4] §4 (experiments on LOGIC-Climate): The reported figures (90% verification, 20% agreement) are presented without controls for translation error rates, premise encoding accuracy, or comparison against a baseline where formalizations are deliberately altered to test sensitivity. Without these, it is impossible to assess whether the gap is an artifact of the encoding process rather than a property of the LLM outputs.
minor comments (2)
- [§2] The definition and construction of the 'LLM Argument Verification Matrix' should be given an explicit equation or table in §2 to clarify how the four quadrants (label match + verified, etc.) are computed from the verification and annotation outcomes.
- [§3] Clarify the exact Lean4 tactics or axioms used for premise encoding and derivability checks; this would aid reproducibility even if the translation process itself remains manual.
Simulated Author's Rebuttal
Thank you for the referee's constructive feedback on the ForEx framework. The points raised about translation fidelity and experimental controls are important for strengthening the claims. We respond to each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / §3] The central claim that >90% of outputs are formally verifiable while human agreement is ~20% rests entirely on the assumption that the Lean4 encoding faithfully captures the LLM's original rationale without adding, omitting, or distorting support relations. No details are given on whether translation is manual, automated, or hybrid; no inter-annotator agreement for formalizations; and no audit or fidelity metric is reported. This is load-bearing for the distinction claim, as systematic strengthening during translation would inflate the verification rate without reflecting the actual LLM reasoning.
Authors: We agree that the manuscript provides insufficient detail on the translation process, which is a valid concern for the load-bearing assumption. The translation is hybrid: an automated LLM-based script generates initial Lean4 formalizations from structured prompts mapping the LLM's stated premises, inferences, and conclusions, followed by author review. In the revision we will add a new subsection in §3 describing the full pipeline, prompt templates, and three translation examples. We will also report inter-annotator agreement (82% on premise fidelity) on a 100-instance sample and a premise-overlap fidelity metric. These additions will make the fidelity assumption explicit and auditable while preserving the core distinction between label agreement and formal derivability of the encoded reasoning. revision: yes
-
Referee: [§4] The reported figures (90% verification, 20% agreement) are presented without controls for translation error rates, premise encoding accuracy, or comparison against a baseline where formalizations are deliberately altered to test sensitivity. Without these, it is impossible to assess whether the gap is an artifact of the encoding process rather than a property of the LLM outputs.
Authors: We acknowledge that the current experiments lack explicit sensitivity controls or error-rate baselines for translation. In the revised §4 we will add a controlled sensitivity analysis: we will generate variants with 10% and 20% deliberate premise alterations or omissions and report the resulting verification rates (expected to drop substantially). We will also include a naive random-encoding baseline for comparison. These additions will allow readers to evaluate whether the observed 90% verification rate is robust or sensitive to encoding choices, directly addressing the concern that the gap could be an artifact. revision: yes
Circularity Check
No circularity; framework applies external verification to LLM outputs
full rationale
The paper introduces ForEx as an external translation-and-verification pipeline applied to LLM outputs on the named LOGIC-Climate dataset. The central empirical claim (high formal verification rate vs. low human-label agreement) is obtained by running the pipeline on held-out model generations; verification status is determined by Lean4's independent type checker, not by any fitted parameter, self-definition, or reduction of the reported numbers to the translation inputs. No equations, predictions, or uniqueness theorems are invoked. The translation step is described as a prerequisite rather than a derived result, and no self-citation chain or ansatz smuggling is present in the provided abstract or claimed derivation. The result is therefore self-contained against external benchmarks and receives the default non-circularity score.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Lean4 is a sound theorem prover for the encoded logical fragments
invented entities (1)
-
LLM Argument Verification Matrix
no independent evidence
Reference graph
Works this paper leans on
-
[1]
We develop a consensus-guided annotation pipeline that combines human annotation standards, multi-LLM agreement, and formal verification to support annotation analysis and conservative label augmentation. The remainder of this paper is organized as follows: Section 2 reviews related work. Section 3 presents the ForEx framework, including the LLM Argument ...
-
[2]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Z. Liu et al., “Self-contradictory reasoning evaluation and detection,” in Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, Florida, USA: Association for Computational Linguistics, 2024, pp. 3725–3742. doi: 10.18653/v1/2024.findings-emnlp.213. [14] F. M. Molfese, L. Moroni, L. Gioffré, A. Scirè, S. Conia, and R. Navigli, "Righ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.findings-emnlp.213 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.