Auditing Combinatorial Randomness from Finite Transcripts
Pith reviewed 2026-06-26 11:38 UTC · model grok-4.3
The pith
Black-box audits certify k-subset uniformity from finite transcripts against structured faults with sample size logarithmic in witness count.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We construct generator-agnostic audits on the hypersimplex using marginal chi-square, pair maxima, serial overlap, anchored-box discrepancy, and low-dimensional H0/MST geometry, all calibrated under the exact combinatorial null. We also prove a finite-witness guarantee whose sample complexity depends logarithmically on the number of audited witnesses rather than on the full support size.
What carries the argument
Generator-agnostic audits on the hypersimplex calibrated under the exact combinatorial null, together with a finite-witness guarantee whose sample complexity is logarithmic in the number of witnesses.
If this is right
- Marginal-preserving deviations remain detectable through joint geometry statistics.
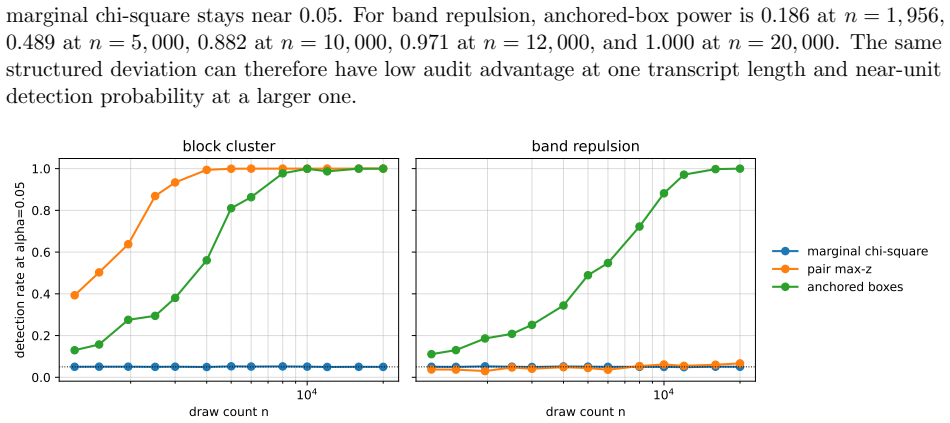
- At n=1956 a block-cluster alternative of strength 0.04 yields power 0.638 for pair maxima versus 0.051 for marginal chi-square.
- A band-repulsion alternative of strength 0.08 yields power 0.741 for anchored boxes versus 0.051 for marginal chi-square.
- No statistic remains significant after false-discovery correction on observed and reference-source data (minimum BH q=0.279).
- GPU Monte Carlo experiments with up to 300000 null replications per condition confirm calibration and power ordering.
Where Pith is reading between the lines
- The logarithmic scaling may allow the same auditing approach on other combinatorial objects whose support size is too large for direct uniformity testing.
- Exact combinatorial calibration could replace Monte Carlo for small enough m and k, removing simulation variance from the procedure.
- The framework could be extended to audit other public-randomness primitives whose transcripts are finite k-subset records.
Load-bearing premise
The deviations from uniformity that matter are structured faults the chosen hypersimplex statistics can capture, and the exact combinatorial null can be used for calibration without approximation error.
What would settle it
An experiment in which a block-cluster alternative of strength 0.04 at n=1956 produces power for pair maxima no higher than the 0.051 achieved by marginal chi-square would falsify the claimed detection advantage of joint geometry.
Figures

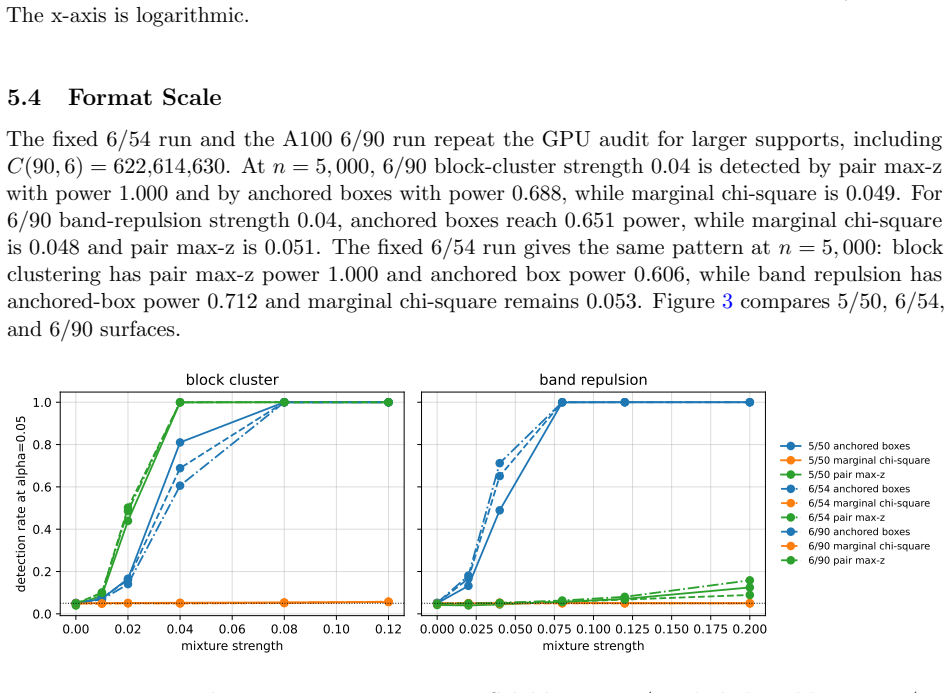
read the original abstract
Public randomness is a security primitive whose deployed behavior is often observable only through a finite transcript. We study black-box auditing of $k$-subset draws from $m$ labels under the exact uniform-without-replacement null. The outcome space has size $\binom{m}{k}$, and unrestricted uniformity testing therefore requires $\Theta(\sqrt{\binom{m}{k}}/\varepsilon^2)$ samples, establishing an information-theoretic limit on transcript-only certification. For structured faults, we construct generator-agnostic audits on the hypersimplex using marginal chi-square, pair maxima, serial overlap, anchored-box discrepancy, and low-dimensional $H_0$/MST geometry, all calibrated under the exact combinatorial null. We also prove a finite-witness guarantee whose sample complexity depends logarithmically on the number of audited witnesses rather than on the full support size. Across observed and reference-source audits, no statistic remains significant after false-discovery correction (minimum BH $q=0.279$). GPU Monte Carlo experiments, using up to 300,000 null and 60,000 alternative replications per condition, show that marginal-preserving deviations can evade one-dimensional tests while remaining detectable through joint geometry. At $n=1{,}956$, a block-cluster alternative of strength 0.04 yields power 0.638 for pair maxima versus 0.051 for marginal chi-square; a band-repulsion alternative of strength 0.08 yields power 0.741 for anchored boxes versus 0.051. These results characterize which structured deviations finite public transcripts can detect and the sample sizes required for doing so.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to develop black-box auditing methods for k-subset draws from m labels under the exact uniform-without-replacement combinatorial null. It constructs several statistics (marginal chi-square, pair maxima, serial overlap, anchored-box discrepancy, and low-dimensional H0/MST geometry) calibrated under the exact null, proves a finite-witness guarantee with sample complexity logarithmic in the number of witnesses rather than support size, and through Monte Carlo experiments shows that joint geometry tests can detect structured alternatives (e.g., block-cluster of strength 0.04 at n=1956 with power 0.638 for pair maxima vs 0.051 for marginal chi-square) that evade one-dimensional tests, while real data audits yield no significant deviations after FDR correction (minimum BH q=0.279).
Significance. If the finite-witness guarantee holds, the work would be significant for enabling efficient auditing of public randomness sources with sample complexity scaling only logarithmically in the number of witnesses, bypassing the Ω(√ binom(m,k)) barrier of unrestricted uniformity testing. The constructions are generator-agnostic and the experiments provide concrete power comparisons characterizing which structured deviations are detectable at given sample sizes. Credit is given for the extensive GPU Monte Carlo validation (up to 300k null replications) and the emphasis on exact combinatorial null calibration in the theoretical parts.
major comments (1)
- [§4 (finite-witness guarantee, Theorem on logarithmic sample complexity)] §4 (finite-witness guarantee, Theorem on logarithmic sample complexity): The guarantee achieves logarithmic dependence on the number of audited witnesses by relying on exact tail bounds or p-value thresholds under the combinatorial null to control error rates (e.g., union bound or FDR). The manuscript states that all statistics are 'calibrated under the exact combinatorial null' and the guarantee is proved, yet §5 reports that exact enumeration of the hypersimplex is intractable, so all reported results and presumably the practical application of the guarantee use Monte Carlo approximation (up to 300k replications). No analysis bounds the additive Monte Carlo p-value error or shows that it preserves the logarithmic scaling once the number of witnesses grows and BH correction is applied, which directly undermines the central claim.
minor comments (3)
- [Abstract] Abstract: 'BH q=0.279' is reported without defining the Benjamini-Hochberg procedure or specifying how the q-values were computed across the suite of statistics.
- [Introduction / Notation] Notation: The hypersimplex is invoked without an explicit definition in terms of the parameters m and k in the early sections, which may hinder readers outside combinatorial optimization.
- [Experimental results] Experimental section: The power values (e.g., 0.638 and 0.051) are given to three decimals, but it is unclear whether the number of alternative replications (60k) suffices for reliable estimation of these quantities at the reported precision.
Simulated Author's Rebuttal
We appreciate the referee's careful reading of the manuscript and the identification of this important point regarding the finite-witness guarantee. Below we respond to the major comment and indicate the planned revision.
read point-by-point responses
-
Referee: [§4 (finite-witness guarantee, Theorem on logarithmic sample complexity)] §4 (finite-witness guarantee, Theorem on logarithmic sample complexity): The guarantee achieves logarithmic dependence on the number of audited witnesses by relying on exact tail bounds or p-value thresholds under the combinatorial null to control error rates (e.g., union bound or FDR). The manuscript states that all statistics are 'calibrated under the exact combinatorial null' and the guarantee is proved, yet §5 reports that exact enumeration of the hypersimplex is intractable, so all reported results and presumably the practical application of the guarantee use Monte Carlo approximation (up to 300k replications). No analysis bounds the additive Monte Carlo p-value error or shows that it preserves the logarithmic scaling once the number of witnesses grows and BH correction is applied, which directly undermines th
Authors: We agree with the referee that the central finite-witness guarantee relies on exact calibration under the combinatorial null, while the reported experiments and data audits rely on Monte Carlo approximations due to the intractability of exact enumeration. The manuscript does not currently provide an explicit analysis of how the Monte Carlo error affects the error control in the union bound or FDR procedure when the number of witnesses increases. We will revise §4 to include a discussion of Monte Carlo p-value error bounds. Using standard concentration inequalities, we can bound the deviation between the Monte Carlo p-value and the true p-value by O(sqrt((log(1/δ))/R)) with probability 1-δ, where R is the number of replications. We will show that for the replication counts used (R=300,000) and the witness counts in our applications, this error is sufficiently small to maintain the logarithmic sample complexity scaling. For general cases, we will note that R can be increased as needed to control the error. This revision will strengthen the connection between the theoretical guarantee and its practical use. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper states a mathematical proof of the finite-witness guarantee under exact combinatorial null calibration, with sample complexity logarithmic in the number of witnesses via standard concentration or union-bound arguments that do not reduce to fitted parameters, self-citations, or ansatzes. All listed statistics are calibrated directly from the exact null without renaming or smuggling prior results. Monte Carlo is used only for experiments, not in the proof itself. No load-bearing step equates a prediction to its input by construction, and the central claim remains independent of any self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The null is exactly the uniform-without-replacement distribution over all k-subsets of m labels.
Reference graph
Works this paper leans on
-
[1]
Bassham, Andrew L
Lawrence E. Bassham, Andrew L. Rukhin, Juan Soto, James R. Nechvatal, Miles E. Smid, Elaine B. Barker, Stefan D. Leigh, Mark Levenson, Mark Vangel, David L. Banks, Nathanael Alan Heckert, James F. Dray, and San Vo. A statistical test suite for random and pseudorandom number generators for cryptographic applications. Special Publication 800-22 Revision 1a,...
2010
-
[2]
Omer Bobrowski and Matthew Kahle. Topology of random geometric complexes: A survey.Journal of Applied and Computational Topology, 1(3–4):331–364, 2018. doi: 10.1007/s41468-017-0010-0
-
[3]
Statistical topological data analysis using persistence landscapes.Journal of Machine Learning Research, 16(3):77–102, 2015
Peter Bubenik. Statistical topological data analysis using persistence landscapes.Journal of Machine Learning Research, 16(3):77–102, 2015. URL https://jmlr.org/papers/v16/ bubenik15a.html
2015
-
[4]
Cl´ ement L. Canonne. A survey on distribution testing: Your data is big. but is it blue? Theory of Computing, pages 1–100, 2020. doi: 10.4086/toc.gs.2020.009. URL https:// theoryofcomputing.org/articles/gs009/. Graduate Surveys 9
-
[5]
Vasek Chvatal. The tail of the hypergeometric distribution.Discrete Mathematics, 25(3): 285–287, 1979. doi: 10.1016/0012-365X(79)90084-0
-
[6]
Persi Diaconis and Frederick Mosteller. Methods for studying coincidences.Journal of the American Statistical Association, 84(408):853–861, 1989. doi: 10.1080/01621459.1989.10478847
-
[7]
American Mathematical Society, Providence, RI, 2010
Herbert Edelsbrunner and John Harer.Computational Topology: An Introduction. American Mathematical Society, Providence, RI, 2010. ISBN 9780821849255
2010
-
[8]
Robert Ghrist. Barcodes: The persistent topology of data.Bulletin of the American Mathe- matical Society, 45(1):61–75, 2008. doi: 10.1090/S0273-0979-07-01191-3
-
[9]
Michael Gnewuch, Anand Srivastav, and Carola Winzen. Finding optimal volume subintervals with k points and calculating the star discrepancy are NP-hard problems.Journal of Complexity, 25(2):115–127, 2009. doi: 10.1016/j.jco.2008.07.001
-
[10]
Kavuri, Jasper Palfree, Dileep V
Gautam A. Kavuri, Jasper Palfree, Dileep V. Reddy, Yanbao Zhang, Joshua C. Bienfang, Michael D. Mazurek, et al. Traceable random numbers from a non-local quantum advantage. Nature, 2025. doi: 10.1038/s41586-025-09054-3
-
[11]
John Kelsey, Lu´ ıs T. A. N. Brand˜ ao, Rene Peralta, and Harold Booth. A reference for randomness beacons: Format and protocol version 2. Draft NISTIR 8213, National Institute of Standards and Technology, 2019
2019
-
[12]
Pierre L’Ecuyer and Richard Simard. TestU01: A C library for empirical testing of random number generators.ACM Transactions on Mathematical Software, 33(4):22, 2007. doi: 10. 1145/1268776.1268777
arXiv 2007
-
[13]
Euromillions public API
Pedro Mealha. Euromillions public API. https://github.com/pedro-mealha/ euromillions-api, 2026. Accessed 2026-06-20
2026
-
[14]
Harald Niederreiter.Random Number Generation and Quasi-Monte Carlo Methods. SIAM, Philadelphia, 1992. doi: 10.1137/1.9781611970081
-
[15]
A Family of Optimal Locally Recoverable Codes
Liam Paninski. A coincidence-based test for uniformity given very sparsely sampled discrete data.IEEE Transactions on Information Theory, 54(10):4750–4755, 2008. doi: 10.1109/TIT. 2008.928987
work page doi:10.1109/tit 2008
-
[16]
Robert J. Serfling. Probability inequalities for the sum in sampling without replacement.The Annals of Statistics, 2(1):39–48, 1974. doi: 10.1214/aos/1176342611. 9
-
[17]
McKay, Mary L
Meltem S¨ onmez Turan, Elaine Barker, John Kelsey, Kerry A. McKay, Mary L. Baish, and Mike Boyle. Recommendation for the entropy sources used for random bit generation. Special Publication 800-90B, National Institute of Standards and Technology, 2018
2018
-
[18]
CURBy: CU randomness beacon
University of Colorado Boulder. CURBy: CU randomness beacon. https://random.colorado. edu/, 2026. Accessed 2026-06-20
2026
-
[19]
GPU-accelerated computation of Vietoris–Rips persistence barcodes
Simon Zhang, Mengbai Xiao, and Hao Wang. GPU-accelerated computation of Vietoris–Rips persistence barcodes. In36th International Symposium on Computational Geometry (SoCG 2020), volume 164 ofLeibniz International Proceedings in Informatics (LIPIcs), pages 70:1–70:17. Schloss Dagstuhl – Leibniz-Zentrum f¨ ur Informatik, 2020. doi: 10.4230/LIPIcs.SoCG.2020.70. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.