Any-Body Guard: Universal Safeguarding for Manipulation Policies via Action Masking
Pith reviewed 2026-06-26 10:57 UTC · model grok-4.3
The pith
X-Safe masks unsafe actions by estimating collision probabilities directly in a robot's configuration space using only forward kinematics and a quasi-static object model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
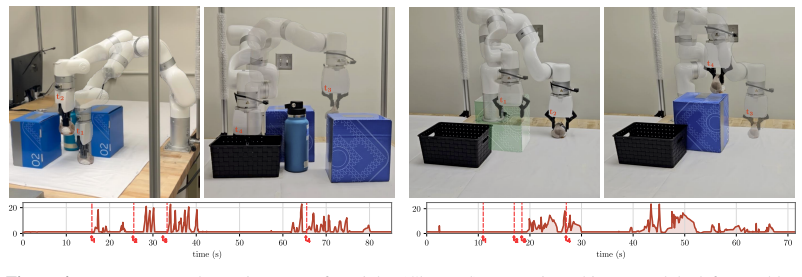
X-Safe reasons directly in the robot's configuration space to provide formal probabilistic guarantees for collision avoidance. By operating in the configuration space, our method transfers across embodiments while relying solely on an object-based, quasi-static scene representation and a forward kinematics model of the robotic manipulator. Thus, X-Safe provides useful formal safety guarantees without requiring additional data, or engineering effort for different embodiments or scenes.
What carries the argument
Action masking driven by configuration-space collision probability computed from forward kinematics and a quasi-static object-based scene model.
If this is right
- The identical safeguard module can be deployed on different robot arms without rewriting code or retraining.
- Task success rates drop less than with fallback controllers or invariance-based methods.
- No collisions are observed in the reported hardware trials.
- The same formal probability bounds hold across simulation and physical embodiments.
- Safety can be added to existing policies without collecting new training data.
Where Pith is reading between the lines
- The method could be paired with online scene reconstruction from cameras to relax the need for pre-known object models.
- Extending the probability calculation to short-horizon motion prediction might allow safe operation in mildly dynamic environments.
- Because the safeguard is embodiment-agnostic, it could serve as a common safety interface when policies trained on one robot are transferred to another.
- The approach suggests that configuration-space reasoning may be a practical route to morphology-independent safety layers in manipulation.
Load-bearing premise
A quasi-static scene model plus forward kinematics alone is sufficient to compute reliable collision probabilities, without needing robot dynamics, contact models, or extra sensors.
What would settle it
A collision occurring in hardware when the forward kinematics model matches the physical arm and the object positions are known exactly would show that the probability estimates do not deliver the claimed avoidance.
Figures





read the original abstract
Ensuring safety of learning-enabled robotic manipulation across diverse embodiments and tasks still requires significant manual engineering. Existing approaches typically rely on heuristically designed fallback controllers or complex forward invariance assessments. These methods are often too conservative for task success, too computationally expensive for real-time execution, too heuristic to provide useful safety guarantees, or too engineering-heavy to transfer between setups. In this paper, we propose a universal safeguarding approach, X-Safe, which reasons directly in the robot's configuration space to provide formal probabilistic guarantees for collision avoidance. By operating in the configuration space, our method transfers across embodiments while relying solely on an object-based, quasi-static scene representation and a forward kinematics model of the robotic manipulator. Thus, X-Safe provides useful formal safety guarantees without requiring additional data, or engineering effort for different embodiments or scenes. We demonstrate X-Safe for diverse embodiments and policies, both in simulation and on hardware. We observe less degradation in task performance compared to state-of-the-art safeguarding, no collisions on hardware experiments, and empirically corroborate our formal guarantees.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes X-Safe, a universal safeguarding method for learned manipulation policies that performs action masking by reasoning directly in configuration space. It claims to deliver formal probabilistic guarantees on collision avoidance that transfer across robot embodiments, relying only on an object-based quasi-static scene representation and a forward kinematics model, without additional data or per-embodiment engineering. The approach is evaluated in simulation and on hardware across diverse policies and embodiments, showing reduced task-performance degradation relative to prior safeguarding methods and zero collisions in hardware trials, with empirical corroboration of the formal bounds.
Significance. If the probabilistic bounds are rigorously derived and the quasi-static assumption is shown to be sufficient, the method would meaningfully lower the barrier to safe deployment of learned policies by eliminating embodiment-specific safety engineering. The transferability claim and hardware results are practically relevant for robotics, though their value hinges on whether the formal guarantees survive the transition from idealized C-space checks to real dynamics.
major comments (2)
- [§3.2] §3.2 (probability bound derivation): the formal guarantee is obtained from configuration-space volume ratios under a quasi-static, object-based scene model and forward kinematics alone; this construction omits velocity, momentum, and contact dynamics, so the bound holds only inside the idealized regime and does not automatically extend to the hardware setting where those effects are present.
- [§5] §5 (hardware experiments): the claim of empirical corroboration of the formal guarantees is made without an accompanying error analysis, sampling procedure for the probability estimates, or explicit statement of data-exclusion rules; the reported zero-collision outcome therefore cannot be directly linked to the tightness or validity of the derived bounds.
minor comments (1)
- [§3] Notation for the configuration-space collision probability (e.g., the exact definition of the safe-action mask) should be introduced once in §3 and used consistently thereafter to avoid ambiguity when comparing simulation and hardware results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the formal derivation and hardware validation. We address each major comment below.
read point-by-point responses
-
Referee: [§3.2] §3.2 (probability bound derivation): the formal guarantee is obtained from configuration-space volume ratios under a quasi-static, object-based scene model and forward kinematics alone; this construction omits velocity, momentum, and contact dynamics, so the bound holds only inside the idealized regime and does not automatically extend to the hardware setting where those effects are present.
Authors: We agree that the probabilistic bounds are derived strictly under the quasi-static assumption and therefore exclude velocity, momentum, and full contact dynamics. Section 3.2 states this modeling choice explicitly. The hardware results are presented as empirical corroboration rather than a direct extension of the formal bound. In revision we will expand the discussion of the quasi-static regime, clarify the conditions under which it is a reasonable approximation for manipulation, and more sharply separate the formal claims from the hardware observations. revision: partial
-
Referee: [§5] §5 (hardware experiments): the claim of empirical corroboration of the formal guarantees is made without an accompanying error analysis, sampling procedure for the probability estimates, or explicit statement of data-exclusion rules; the reported zero-collision outcome therefore cannot be directly linked to the tightness or validity of the derived bounds.
Authors: The referee is correct that the current hardware section does not supply an error analysis, explicit sampling procedure, or data-exclusion rules. We will add these details in the revised manuscript, including the total number of trials, how collision events were recorded and counted, and any exclusion criteria. This will enable a clearer assessment of how the zero-collision outcome relates to the derived bounds. revision: yes
Circularity Check
No circularity detected; derivation self-contained
full rationale
The abstract and description present a method relying on configuration-space reasoning, quasi-static scene representation, and forward kinematics for formal probabilistic collision guarantees, but contain no equations, parameter-fitting steps, self-citations, or uniqueness theorems. No load-bearing claim reduces by construction to its inputs, fitted data renamed as prediction, or author-overlapping citations. The approach is presented as transferring via embodiment-independent primitives without visible internal reduction, qualifying as self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhang, Y
B. Zhang, Y . Zhang, J. Ji, Y . Lei, J. Dai, Y . Chen, and Y . Yang. SafeVLA: Towards safety alignment of vision-language-action model via constrained learning. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps: //openreview.net/forum?id=dt940loCBT
2026
-
[2]
D. S. Brown, J. Schneider, A. Dragan, and S. Niekum. Value alignment verification. InPro- ceedings of the 38th International Conference on Machine Learning, pages 1105–1115, 2021
2021
-
[3]
Brunke, M
L. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. Schoellig. Safe learn- ing in robotics: From learning-based control to safe reinforcement learning.Annual Review of Control, Robotics, and Autonomous Systems, 5:411–444, 2022
2022
-
[4]
Krasowski, J
H. Krasowski, J. Thumm, M. M ¨uller, L. Sch¨afer, X. Wang, and M. Althoff. Provably safe rein- forcement learning: Conceptual analysis, survey, and benchmarking.Transactions on Machine Learning Research, 2023
2023
-
[5]
W. Jung, D. Anthony, U. A. Mishra, N. R. Arachchige, M. Bronars, D. Xu, and S. Kousik. RAIL: Reachability-aided imitation learning for safe policy execution. InIEEE Inter- national Conference on Robotics and Automation (ICRA), pages 3582–3589, 2025. doi: 10.1109/ICRA55743.2025.11128656
-
[6]
Thumm and M
J. Thumm and M. Althoff. Provably safe deep reinforcement learning for robotic manipula- tion in human environments. In2022 International Conference on Robotics and Automation (ICRA), pages 6344–6350. IEEE, 2022
2022
-
[7]
M. Yu, C. Yu, M.-M. Naddaf-Sh, D. Upadhyay, S. Gao, and C. Fan. Efficient motion planning for manipulators with control barrier function-induced neural controller. InIEEE International Conference on Robotics and Automation (ICRA), pages 14348–14355, 2024. doi:10.1109/ ICRA57147.2024.10610785
arXiv 2024
-
[8]
Tayal, M
M. Tayal, M. Tayal, A. Singh, S. Kolathaya, and R. Prakash. V-OCBF: Learning safety filters from offline data via value-guided offline control barrier functions.Transactions on Machine Learning Research, 2026. ISSN 2835-8856. URLhttps://openreview.net/forum?id= PGO9mpIyyb
2026
-
[9]
Markgraf, S
H. Markgraf, S. Sawant, H. Krasowski, L. Sch¨afer, S. Gros, and M. Althoff. Safe reinforcement learning using action projection: Safeguard the policy or the environment?Transactions on Machine Learning Research, 2026
2026
-
[10]
F. P. Bejarano, L. Brunke, and A. P. Schoellig. Safety filtering while training: Improving the performance and sample efficiency of reinforcement learning agents.IEEE Robotics and Automation Letters, 10(1):788–795, 2025
2025
-
[11]
Y . S. Shao, C. Chen, S. Kousik, and R. Vasudevan. Reachability-Based Trajectory Safe- guard (RTS): A safe and fast reinforcement learning safety layer for continuous control.IEEE Robotics and Automation Letters, 6(2):3663–3670, 2021. doi:10.1109/LRA.2021.3063989
-
[12]
X. Li, Z. Serlin, G. Yang, and C. Belta. A formal methods approach to interpretable reinforce- ment learning for robotic planning.Science Robotics, 4(37), 2019. 10
2019
-
[13]
D. Morton and M. Pavone. Safe, task-consistent manipulation with operational space control barrier functions. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 187–194, 2025. doi:10.1109/IROS60139.2025.11246389
-
[14]
K. P. Wabersich, A. J. Taylor, J. J. Choi, K. Sreenath, C. J. Tomlin, A. D. Ames, and M. N. Zeilinger. Data-driven safety filters: Hamilton-jacobi reachability, control barrier functions, and predictive methods for uncertain systems.IEEE Control Systems Magazine, 43(5):137– 177, 2023
2023
-
[15]
Sharma, N
V . Sharma, N. Mehr, and N. Hovakimyan. Learning differentiable and safe multi-robot control for generalization to novel environments using control barrier functions. In2024 IEEE 63rd Conference on Decision and Control (CDC), pages 8423–8428. IEEE, 2024
2024
-
[16]
J.-B. Bouvier, K. Nagpal, and N. Mehr. POLICEd RL: Learning Closed-Loop Robot Control Policies with Provable Satisfaction of Hard Constraints. InProceedings of Robotics: Science and Systems, Delft, Netherlands, July 2024. doi:10.15607/RSS.2024.XX.104
-
[17]
Bouvier, K
J.-B. Bouvier, K. Nagpal, and N. Mehr. Learning to provably satisfy high relative degree constraints for black-box systems. In2024 IEEE 63rd Conference on Decision and Control (CDC), pages 8320–8325. IEEE, 2024
2024
-
[18]
A. Shrivastava, K. Nagpal, S. Jinkala, J.-B. Bouvier, and N. Mehr. Learning control policies to provably satisfy hard affine constraints for black-box hybrid dynamical systems.arXiv preprint arXiv:2604.22244, 2026
Pith/arXiv arXiv 2026
-
[19]
Kochdumper, H
N. Kochdumper, H. Krasowski, X. Wang, S. Bak, and M. Althoff. Provably safe reinforcement learning via action projection using reachability analysis and polynomial zonotopes.IEEE Open Journal of Control Systems, 2:79–92, 2023
2023
-
[20]
Selim, A
M. Selim, A. Alanwar, M. W. El-Kharashi, H. M. Abbas, and K. H. Johansson. Safe reinforce- ment learning using data-driven predictive control. InProc. of the Int. Conf. on Communica- tions, Signal Processing, and their Applications (ICCSPA), pages 1–6, 2022
2022
-
[21]
J.-B. Bouvier, K. Ryu, K. Nagpal, Q. Liao, K. Sreenath, and N. Mehr. Ddat: Diffusion policies enforcing dynamically admissible robot trajectories.arXiv preprint arXiv:2502.15043, 2025
arXiv 2025
-
[22]
S. Gros, M. Zanon, and A. Bemporad. Safe reinforcement learning via projection on a safe set: How to achieve optimality?IFAC-PapersOnLine, 53(2):8076–8081, 2020
2020
-
[23]
Stolz, H
R. Stolz, H. Krasowski, J. Thumm, M. Eichelbeck, P. Gassert, and M. Althoff. Excluding the irrelevant: Focusing reinforcement learning through continuous action masking. InAdvances in Neural Information Processing Systems, volume 37, pages 95067–95094, 2024
2024
-
[24]
Zico Kolter and Hamed Hassani and George J
A. Robey, Z. Ravichandran, E. K. Jones, J. Perlo, F. Barez, V . Kumar, J. Z. Kolter, H. Hassani, and G. J. Pappas. Beyond alignment: Why robotic foundation models need context-aware safety.Science Robotics, 11(113), 2026. doi:10.1126/scirobotics.aef2191
-
[25]
A. Johansson, D. Lindmark, V . Wiberg, and M. Servin. Safety filtering of robotic manipulation under environment uncertainty: a computational approach.arXiv preprint 2509.12674, 2025
arXiv 2025
- [26]
-
[27]
A. Dastider, H. Fang, and M. Lin. APEX: Ambidextrous dual-arm robotic manipulation using collision-free generative diffusion models. InIEEE/RSJ International Conference on Intel- ligent Robots and Systems (IROS), pages 9526–9533, 2024. doi:10.1109/IROS58592.2024. 10802655. 11
-
[28]
K. Long, K. M. B. Lee, N. Raicevic, N. Attasseri, M. Leok, and N. Atanasov. Neu- ral configuration-space barriers for manipulation planning and control.arXiv preprint 2503.04929, 2025
Pith/arXiv arXiv 2025
-
[29]
T. Kim. Is your safe controller actually safe? a critical review of cbf tautologies and hidden assumptions, 2026. URLhttps://arxiv.org/abs/2603.06954
arXiv 2026
-
[30]
Smith, Y
C. Smith, Y . Karayiannidis, L. Nalpantidis, X. Gratal, P. Qi, D. V . Dimarogonas, and D. Kragic. Dual arm manipulation — A survey.Robotics and Autonomous systems, 60(10):1340–1353, 2012
2012
-
[31]
Orthey, C
A. Orthey, C. Chamzas, and L. E. Kavraki. Sampling-based motion planning: A comparative review.Annual Review of Control, Robotics, and Autonomous Systems, 7, 2023
2023
-
[32]
M. Elbanhawi and M. Simic. Sampling-based robot motion planning: A review.IEEE Access, 2:56–77, 2014. doi:10.1109/ACCESS.2014.2302442
-
[33]
Schulman, Y
J. Schulman, Y . Duan, J. Ho, A. Lee, I. Awwal, H. Bradlow, J. Pan, S. Patil, K. Goldberg, and P. Abbeel. Motion planning with sequential convex optimization and convex collision checking.The International Journal of Robotics Research, 33(9):1251–1270, 2014
2014
-
[34]
Zucker, N
M. Zucker, N. Ratliff, A. D. Dragan, M. Pivtoraiko, M. Klingensmith, C. M. Dellin, J. A. Bagnell, and S. S. Srinivasa. Chomp: Covariant hamiltonian optimization for motion planning. The International journal of robotics research, 32(9-10):1164–1193, 2013
2013
-
[35]
Mastalli, M
C. Mastalli, M. Focchi, I. Havoutis, A. Radulescu, S. Calinon, J. Buchli, D. G. Caldwell, and C. Semini. Trajectory and foothold optimization using low-dimensional models for rough terrain locomotion. InIEEE International Conference on Robotics and Automation (ICRA), pages 1096–1103, 2017
2017
-
[36]
Deits and R
R. Deits and R. Tedrake. Computing large convex regions of obstacle-free space through semidefinite programming. InAlgorithmic Foundations of Robotics XI: Selected Contributions of the Eleventh International Workshop on the Algorithmic Foundations of Robotics, pages 109–124, 2015
2015
-
[37]
Marcucci, M
T. Marcucci, M. Petersen, D. V on Wrangel, and R. Tedrake. Motion planning around obstacles with convex optimization.Science robotics, 8(84), 2023
2023
- [38]
-
[39]
P. Werner, R. Cheng, T. Stewart, R. Tedrake, and D. Rus. Superfast configuration-space convex set computation on GPUs for online motion planning. InProceedings of Robotics: Science and Systems, 2025. doi:10.15607/RSS.2025.XXI.045
-
[40]
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026– 5033, 2012. doi:10.1109/IROS.2012.6386109
-
[41]
X. Peng, C. Gao, L. Jin, A. Li, and S. Liu. BiCoord: A bimanual manipulation benchmark towards long-horizon spatial-temporal coordination, 2026. URLhttps://arxiv.org/abs/ 2604.05831
Pith/arXiv arXiv 2026
-
[42]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control, 2026. URLhttps://arxiv. o...
Pith/arXiv arXiv 2026
-
[43]
N. Hunt, N. Fulton, S. Magliacane, T. N. Hoang, S. Das, and A. Solar-Lezama. Verifiably safe exploration for end-to-end reinforcement learning. InProceedings of the 24th International Conference on Hybrid Systems: Computation and Control, pages 1–11, 2021
2021
-
[44]
D. Dong, M. Bhatt, S. Choi, and N. Mehr. Mimic-d: Multi-modal imitation for multi-agent coordination with decentralized diffusion policies.arXiv preprint arXiv:2509.14159, 2025
Pith/arXiv arXiv 2025
-
[45]
X. Sun, S. Yang, Y . Chen, F. Fan, Y . Liang, and D. Rakita. Dynamic rank adjustment in diffusion policies for efficient and flexible training.arXiv preprint arXiv:2502.03822, 2025. 13 A Safeguard parameters We specify the safeguard parameters in Tab. 2. We setD=Aand define the width of the box based on the maximum joint differences per single step∆ max. ...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.