ZeroGVC: Zero-Shot Generative Video Compression with Autoregressive Diffusion Priors
Pith reviewed 2026-06-26 10:05 UTC · model grok-4.3
The pith
ZeroGVC reconstructs video at ultra-low bitrates by steering pretrained diffusion trajectories with compact codebook noise vectors and no extra training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
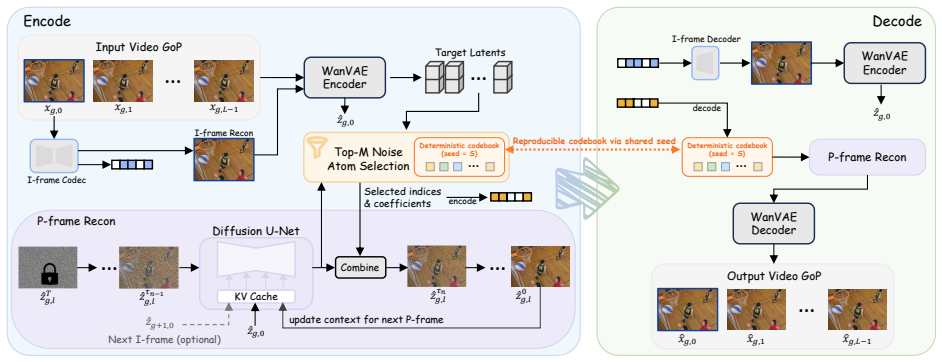
ZeroGVC achieves superior perceptual reconstruction quality at ultra-low bitrates without any additional training by encoding the first frame of each GOP with an image codec and representing subsequent P-frames through Codebook-Guided Autoregressive Latent Compression, which selects compact combinations of reproducible codebook noise vectors to steer the latent denoising trajectory toward the target P-frame while allowing the decoder to reproduce the same trajectory in only a few denoising steps.
What carries the argument
Codebook-Guided Autoregressive Latent Compression, the mechanism that selects compact reproducible codebook noise vectors to direct the denoising trajectory in few steps.
If this is right
- Video sequences can be sent at ultra-low bitrates while preserving perceptual quality using only existing pretrained diffusion models.
- Compression pipelines no longer require separate training stages to adapt generative priors for reconstruction tasks.
- Error accumulation across frames can be reduced by bidirectional reference to the next I-frame at zero extra bitrate cost.
- Low-delay decoding remains feasible because the decoder reproduces the steered trajectory in a small number of steps.
Where Pith is reading between the lines
- The same codebook selection idea might let other diffusion-based generation tasks avoid fine-tuning when the target output can be reached by trajectory steering.
- Updating the underlying diffusion model would automatically improve the compressor without retraining any codec components.
- Real-time applications that cannot afford training runs could adopt this style of compression more readily than methods that demand per-task adaptation.
Load-bearing premise
Selecting a small set of codebook noise vectors can steer the diffusion denoising process precisely enough to match a target video frame in only a few steps.
What would settle it
Side-by-side perceptual tests at the reported low bitrates where ZeroGVC reconstructions score lower than trained generative compressors on standard video quality metrics.
Figures







read the original abstract
Recent generative video compression methods leverage powerful generative priors to achieve perceptually pleasing reconstructions. However, most existing approaches require additional training to adapt generative models to produce realistic reconstructions from compact representations. In this paper, we propose ZeroGVC, a zero-shot generative video compression framework that leverages pretrained autoregressive diffusion priors for low-delay video reconstruction. ZeroGVC encodes the first frame of each group of pictures (GOP) with an image codec and represents subsequent P-frames through Codebook-Guided Autoregressive Latent Compression. This design is motivated by our observation that the compression scheme of denoising diffusion codebook models is effective in few-step consistency sampling. By selecting compact combinations of reproducible codebook noise vectors, ZeroGVC steers the latent denoising trajectory toward the target P-frame while allowing the decoder to reproduce the same trajectory in only a few denoising steps. In addition, we design an optional bidirectional reference mode that mitigates error propagation by leveraging the next I-frame context without introducing any additional bitrate overhead. Extensive experiments on standard video compression benchmarks demonstrate that ZeroGVC achieves superior perceptual reconstruction quality at ultra-low bitrates without any additional training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ZeroGVC, a zero-shot generative video compression framework that encodes I-frames of each GOP with a standard image codec and represents P-frames via Codebook-Guided Autoregressive Latent Compression. It selects compact, reproducible combinations of codebook noise vectors from pretrained denoising diffusion codebook models to steer the latent trajectory toward target P-frames, enabling decoder-side reproduction in few consistency sampling steps. An optional bidirectional reference mode is introduced to reduce error propagation without extra bitrate. The central claim is that this achieves superior perceptual reconstruction quality at ultra-low bitrates on standard benchmarks without any additional training or fine-tuning.
Significance. If the zero-shot selection procedure and few-step reproducibility claims hold with supporting experiments, the work would be significant for demonstrating how existing autoregressive diffusion priors can be directly repurposed for low-delay, training-free video compression, addressing a key limitation of prior generative codecs that require adaptation. The bidirectional mode and emphasis on perceptual quality at ultra-low rates could influence future codec design.
major comments (2)
- [Abstract] Abstract: the claim of 'superior perceptual reconstruction quality' and 'extensive experiments' is unsupported by any quantitative metrics, baselines, rate-distortion curves, or ablation results in the provided description, so the central performance claim rests on unverified statements.
- [Method (Codebook-Guided Autoregressive Latent Compression)] Codebook-Guided Autoregressive Latent Compression section: no encoding algorithm, distance metric, search procedure, or bitrate accounting is supplied for selecting the compact combinations of codebook noise vectors in a zero-shot manner; if selection requires optimization or auxiliary components, the zero-shot and ultra-low-bitrate guarantees are compromised, which is load-bearing for the entire rate-distortion advantage.
minor comments (2)
- Clarify the exact number of consistency steps used at the decoder and how reproducibility of the selected noise vectors is guaranteed across encoder and decoder.
- Add a diagram or pseudocode for the vector selection process to make the zero-shot claim concrete.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'superior perceptual reconstruction quality' and 'extensive experiments' is unsupported by any quantitative metrics, baselines, rate-distortion curves, or ablation results in the provided description, so the central performance claim rests on unverified statements.
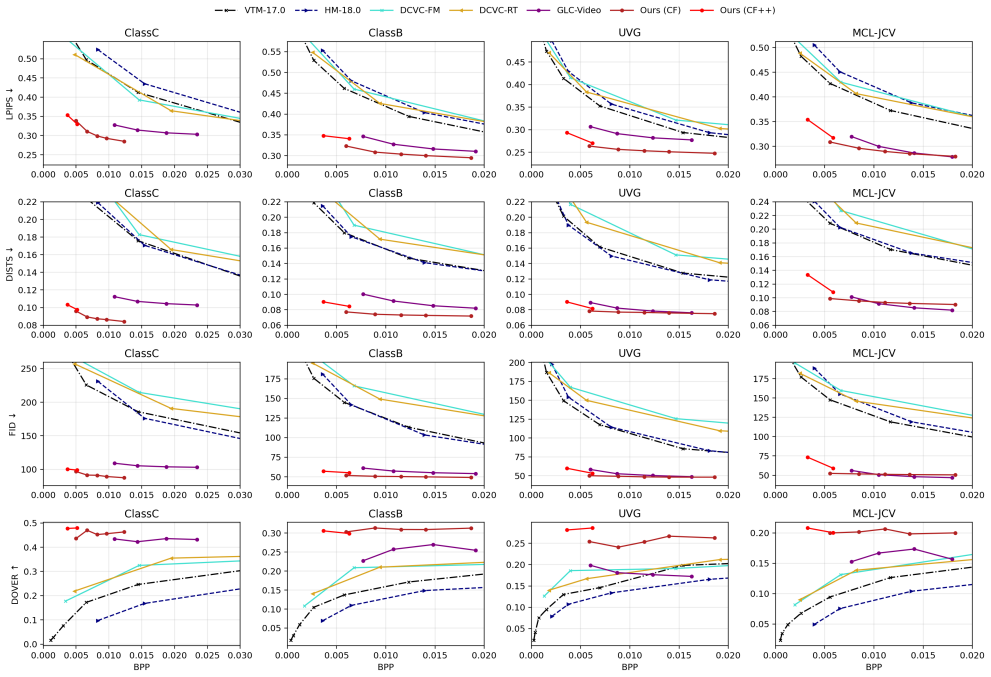
Authors: The abstract is a concise summary of the work and its claims, as is standard. The full manuscript includes a dedicated Experiments section that reports quantitative perceptual metrics (e.g., LPIPS, FID), comparisons against baselines, rate-distortion curves on standard benchmarks (UVG, MCL-JCV), and ablation studies. These results support the stated claims of superior perceptual quality at ultra-low bitrates. To improve clarity, we will revise the abstract to briefly reference the experimental validation and key findings. revision: partial
-
Referee: [Method (Codebook-Guided Autoregressive Latent Compression)] Codebook-Guided Autoregressive Latent Compression section: no encoding algorithm, distance metric, search procedure, or bitrate accounting is supplied for selecting the compact combinations of codebook noise vectors in a zero-shot manner; if selection requires optimization or auxiliary components, the zero-shot and ultra-low-bitrate guarantees are compromised, which is load-bearing for the entire rate-distortion advantage.
Authors: We agree that additional implementation details are needed in this section to fully substantiate the zero-shot procedure. The manuscript will be revised to explicitly describe: (1) the encoding algorithm for selecting compact, reproducible codebook noise vector combinations; (2) the distance metric (latent-space L2 distance to the target P-frame latent); (3) the search procedure (deterministic nearest-neighbor lookup over the pretrained codebook without iterative optimization); and (4) bitrate accounting (fixed-length indices into the codebook, incurring no extra overhead beyond the I-frame). This selection uses only the pretrained autoregressive diffusion model in a feed-forward manner, preserving the zero-shot and training-free guarantees. revision: yes
Circularity Check
No circularity; zero-shot claim relies on external pretrained priors without self-referential reduction.
full rationale
The paper presents ZeroGVC as a zero-shot framework that encodes I-frames with a standard image codec and steers P-frames via selection of codebook noise vectors from pretrained autoregressive diffusion models. The motivation is an observation about few-step consistency sampling in denoising diffusion codebook models, but no equations, fitted parameters, or self-citations are shown that would make the claimed perceptual quality or bitrate performance equivalent to the inputs by construction. The derivation remains self-contained against external benchmarks, with the selection mechanism described as leveraging existing model properties rather than redefining or fitting to the target result.
Axiom & Free-Parameter Ledger
axioms (1)
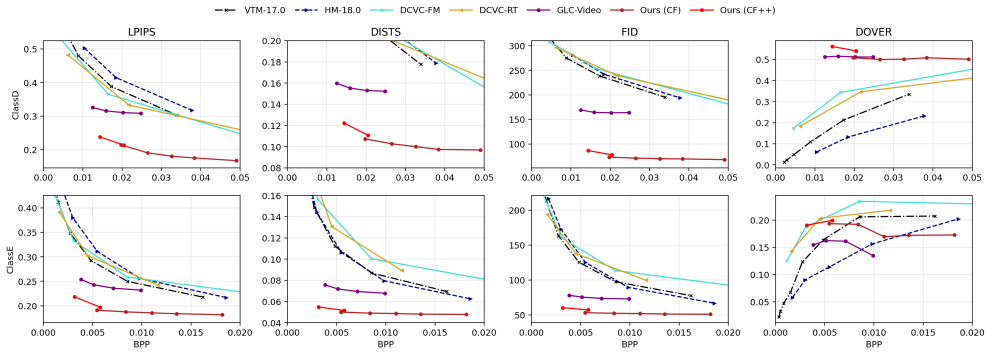
- domain assumption Pretrained autoregressive diffusion models support effective few-step consistency sampling when guided by compact codebook noise vectors
Reference graph
Works this paper leans on
-
[1]
Overview of the versatile video coding (vvc) standard and its applications
Benjamin Bross, Ye-Kui Wang, Yan Ye, Shan Liu, Jianle Chen, Gary J Sullivan, and Jens-Rainer Ohm. Overview of the versatile video coding (vvc) standard and its applications. TCSVT, 2021. 5
2021
-
[2]
Diffusion forcing: Next-token prediction meets full-sequence diffu- sion
Boyuan Chen, Diego Mart ´ı Mons´o, Yilun Du, Max Sim- chowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffu- sion. InThe Thirty-eighth Annual Conference on Neural In- formation Processing Systems, 2024. 3
2024
-
[3]
SkyReels-V2: Infinite-length Film Generative Model
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, et al. Skyreels-v2: Infinite-length film generative model.arXiv preprint arXiv:2504.13074, 2025. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Autoregressive video generation without vector quantization
Haoge Deng, Ting Pan, Haiwen Diao, Zhengxiong Luo, Yufeng Cui, Huchuan Lu, Shiguang Shan, Yonggang Qi, and Xinlong Wang. Autoregressive video generation without vector quantization. InInternational Conference on Learn- ing Representations, pages 44730–44745, 2025. 3
2025
-
[5]
Image quality assessment: Unifying structure and texture similarity.IEEE transactions on pattern analysis and ma- chine intelligence, 44(5):2567–2581, 2020
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P Simoncelli. Image quality assessment: Unifying structure and texture similarity.IEEE transactions on pattern analysis and ma- chine intelligence, 44(5):2567–2581, 2020. 6
2020
-
[6]
Common test con- ditions and software reference configurations for hevc range extensions, document jctvc-n1006
D Flynn, K Sharman, and C Rosewarne. Common test con- ditions and software reference configurations for hevc range extensions, document jctvc-n1006. Joint Collaborative Team Video Coding ITU-T SG, 16. 5
-
[7]
Generative adversarial nets.NeurIPS, 27,
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.NeurIPS, 27,
-
[8]
Generative latent video compression.arXiv preprint arXiv:2510.09987, 2025
Zongyu Guo, Zhaoyang Jia, Jiahao Li, Xiaoyi Zhang, Bin Li, and Yan Lu. Generative latent video compression.arXiv preprint arXiv:2510.09987, 2025. 1, 2
-
[9]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017. 6
2017
-
[10]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 3
2020
-
[11]
Self forcing: Bridging the train-test gap in autoregressive video diffusion.Advances in Neural Informa- tion Processing Systems, 38:167283–167308, 2026
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.Advances in Neural Informa- tion Processing Systems, 38:167283–167308, 2026. 2, 3, 4
2026
-
[12]
Towards practical real-time neural video compression
Zhaoyang Jia, Bin Li, Jiahao Li, Wenxuan Xie, Linfeng Qi, Houqiang Li, and Yan Lu. Towards practical real-time neural video compression. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12543–12552,
-
[13]
Pyramidal flow matching for efficient video generative modeling
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling. InInternational Conference on Learn- ing Representations, pages 23378–23402, 2025. 2, 3
2025
-
[14]
Deep contextual video com- pression.Advances in Neural Information Processing Sys- tems, 34:18114–18125, 2021
Jiahao Li, Bin Li, and Yan Lu. Deep contextual video com- pression.Advances in Neural Information Processing Sys- tems, 34:18114–18125, 2021. 1, 2
2021
-
[15]
Neural video compression with diverse contexts
Jiahao Li, Bin Li, and Yan Lu. Neural video compression with diverse contexts. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 22616–22626, 2023. 5
2023
-
[16]
Neural video compression with feature modulation
Jiahao Li, Bin Li, and Yan Lu. Neural video compression with feature modulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26099–26108, 2024. 1, 2, 5
2024
-
[17]
Yoda: Yet another one-step diffusion-based video com- pressor.arXiv preprint arXiv:2601.01141, 2026
Xingchen Li, Junzhe Zhang, Junqi Shi, Ming Lu, and Zhan Ma. Yoda: Yet another one-step diffusion-based video com- pressor.arXiv preprint arXiv:2601.01141, 2026. 1, 2 9
-
[18]
Xiaoyue Ling, Chuqin Zhou, Chunyi Li, Yunuo Chen, Yuan Tian, Guo Lu, and Wenjun Zhang. Free-gvc: To- wards training-free extreme generative video compression with temporal coherence.arXiv preprint arXiv:2602.09868,
-
[19]
Wenzhuo Ma and Zhenzhong Chen. Diffusion-based percep- tual neural video compression with temporal diffusion infor- mation reuse.ACM Transactions on Multimedia Computing, Communications and Applications, 21(12):1–22, 2025. 1, 2
2025
-
[20]
Wenzhuo Ma and Zhenzhong Chen. Diffvc-osd: One-step diffusion-based perceptual neural video compression frame- work.arXiv preprint arXiv:2508.07682, 2025. 2
-
[21]
Wenzhuo Ma and Zhenzhong Chen. Diffvc-rt: Towards prac- tical real-time diffusion-based perceptual neural video com- pression.arXiv preprint arXiv:2601.20564, 2026
-
[22]
Generative neural video compression via video diffusion prior.arXiv preprint arXiv:2512.05016, 2025
Qi Mao, Hao Cheng, Tinghan Yang, Libiao Jin, and Siwei Ma. Generative neural video compression via video diffusion prior.arXiv preprint arXiv:2512.05016, 2025. 1, 2
-
[23]
High-fidelity generative image compres- sion.arXiv preprint arXiv:2006.09965, 2020
Fabian Mentzer, George Toderici, Michael Tschannen, and Eirikur Agustsson. High-fidelity generative image compres- sion.arXiv preprint arXiv:2006.09965, 2020. 6
-
[24]
Neural video compression using gans for detail synthesis and propagation
Fabian Mentzer, Eirikur Agustsson, Johannes Ball ´e, David Minnen, Nick Johnston, and George Toderici. Neural video compression using gans for detail synthesis and propagation. InEuropean Conference on Computer Vision, pages 562–
-
[25]
Springer, 2022. 1, 2
2022
-
[26]
Uvg dataset: 50/120fps 4k sequences for video codec analysis and development
Alexandre Mercat, Marko Viitanen, and Jarno Vanne. Uvg dataset: 50/120fps 4k sequences for video codec analysis and development. InProceedings of the 11th ACM multimedia systems conference, pages 297–302, 2020. 5
2020
-
[27]
Improving statistical fi- delity for neural image compression with implicit local like- lihood models
Matthew J Muckley, Alaaeldin El-Nouby, Karen Ullrich, Herv´e J ´egou, and Jakob Verbeek. Improving statistical fi- delity for neural image compression with implicit local like- lihood models. InInternational Conference on Machine Learning, pages 25426–25443. PMLR, 2023. 6
2023
-
[28]
Compressed image generation with denoising diffusion codebook models
Guy Ohayon, Hila Manor, Tomer Michaeli, and Michael Elad. Compressed image generation with denoising diffusion codebook models. InForty-second International Conference on Machine Learning, 2025. 1, 2, 3, 4
2025
-
[29]
Generative latent coding for ultra-low bitrate image and video compression.IEEE Transactions on Cir- cuits and Systems for Video Technology, 2025
Linfeng Qi, Zhaoyang Jia, Jiahao Li, Bin Li, Houqiang Li, and Yan Lu. Generative latent coding for ultra-low bitrate image and video compression.IEEE Transactions on Cir- cuits and Systems for Video Technology, 2025. 1, 2, 5
2025
-
[30]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions.arXiv preprint arXiv:2011.13456, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[31]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. InProceedings of the 40th International Conference on Machine Learning, pages 32211–32252. PMLR, 2023. 2, 4
2023
-
[32]
Overview of the high efficiency video coding (hevc) standard.TCSVT, 22(12):1649–1668, 2012
Gary J Sullivan, Jens-Rainer Ohm, Woo-Jin Han, and Thomas Wiegand. Overview of the high efficiency video coding (hevc) standard.TCSVT, 22(12):1649–1668, 2012. 5
2012
-
[33]
MAGI-1: Autoregressive Video Generation at Scale
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video genera- tion at scale.arXiv preprint arXiv:2505.13211, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Lossy compression with gaussian diffusion
Lucas Theis, Tim Salimans, Matthew D Hoffman, and Fabian Mentzer. Lossy compression with gaussian diffusion. arXiv preprint arXiv:2206.08889, 2022. 1, 2
-
[35]
Turbo-DDCM: Fast and flexible zero-shot diffusion-based image compression
Amit Vaisman, Guy Ohayon, Hila Manor, Michael Elad, and Tomer Michaeli. Turbo-DDCM: Fast and flexible zero-shot diffusion-based image compression. InThe Fourteenth In- ternational Conference on Learning Representations, 2026. 1, 2, 3, 4, 5
2026
-
[36]
Lossy compression with pretrained diffusion models
Jeremy V onderfecht and Feng Liu. Lossy compression with pretrained diffusion models. InThe Thirteenth International Conference on Learning Representations, 2025. 1, 2
2025
-
[37]
Mcl-jcv: a jnd-based h
Haiqiang Wang, Weihao Gan, Sudeng Hu, Joe Yuchieh Lin, Lina Jin, Longguang Song, Ping Wang, Ioannis Katsavouni- dis, Anne Aaron, and C-C Jay Kuo. Mcl-jcv: a jnd-based h. 264/avc video quality assessment dataset. In2016 IEEE international conference on image processing (ICIP), pages 1509–1513. IEEE, 2016. 5
2016
-
[38]
Chan, and Chen Change Loy
Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin C.K. Chan, and Chen Change Loy. Exploiting diffusion prior for real-world image super-resolution.International Journal of Computer Vision, 2024. 6
2024
-
[39]
Multi- scale structural similarity for image quality assessment
Zhou Wang, Eero P Simoncelli, and Alan C Bovik. Multi- scale structural similarity for image quality assessment. In The thrity-seventh asilomar conference on signals, systems & computers, 2003, pages 1398–1402. Ieee, 2003. 6
2003
-
[40]
Exploring video quality assessment on user generated contents from aesthetic and technical perspectives
Haoning Wu, Erli Zhang, Liang Liao, Chaofeng Chen, Jing- wen Hou Hou, Annan Wang, Wenxiu Sun Sun, Qiong Yan, and Weisi Lin. Exploring video quality assessment on user generated contents from aesthetic and technical perspectives. InInternational Conference on Computer Vision (ICCV),
-
[41]
One-step diffusion-based image compression with semantic distillation
Naifu Xue, Zhaoyang Jia, Jiahao Li, Bin Li, Yuan Zhang, and Yan Lu. One-step diffusion-based image compression with semantic distillation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 6
2025
-
[42]
Naifu Xue, Zhaoyang Jia, Jiahao Li, Bin Li, Zihan Zheng, Yuan Zhang, and Yan Lu. Single-step diffusion-based video coding with semantic-temporal guidance.arXiv preprint arXiv:2512.07480, 2025. 1, 2
-
[43]
Perceptual learned video compression with recurrent conditional gan
Ren Yang, Radu Timofte, and Luc Van Gool. Perceptual learned video compression with recurrent conditional gan. InIJCAI, pages 1537–1544, 2022. 1, 2
2022
-
[44]
From slow bidirectional to fast autoregressive video diffusion mod- els
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Free- man, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion mod- els. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 22963–22974,
-
[45]
GVCC: Zero-Shot Video Compression via Codebook-Driven Stochastic Rectified Flow
Ziyue Zeng, Xun Su, Haoyuan Liu, Bingyu Lu, Yui Tatsumi, and Hiroshi Watanabe. Gvcc: Zero-shot video compression via codebook-driven stochastic rectified flow.arXiv preprint arXiv:2603.26571, 2026. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
When video compression meets multimodal large lan- 10 guage models: A unified paradigm for cross-modality video compression.IEEE Signal Processing Letters, 2026
Pingping Zhang, Jinlong Li, Kecheng Chen, Meng Wang, Long Xu, Haoliang Li, Nicu Sebe, Sam Kwong, and Shiqi Wang. When video compression meets multimodal large lan- 10 guage models: A unified paradigm for cross-modality video compression.IEEE Signal Processing Letters, 2026. 1, 2
2026
-
[47]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, pages 586–595,
-
[48]
Stablecodec: Taming one-step diffusion for extreme image compression
Tianyu Zhang, Xin Luo, Li Li, and Dong Liu. Stablecodec: Taming one-step diffusion for extreme image compression. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 17379–17389, 2025. 6
2025
-
[49]
Hongzhou Zhu, Min Zhao, Guande He, Hang Su, Chongx- uan Li, and Jun Zhu. Causal forcing: Autoregressive diffu- sion distillation done right for high-quality real-time inter- active video generation.arXiv preprint arXiv:2602.02214,
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
2, 3, 4, 6 11 ZeroGVC: Zero-Shot Generative Video Compression with Autoregressive Diffusion Priors Supplementary Material
-
[51]
More Quantitative Results Fig
Additional Experiments 7.1. More Quantitative Results Fig. 7 further presents perceptual results on HEVC Class D and Class E. For the HEVC Class D dataset, whose resolution (416×240) is relatively low, we instead com- pute FID using128×128patches. On Class D, ZeroGVC consistently outperforms competing methods across LPIPS, DISTS, FID, and DOVER. Because t...
1942
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.