Interleaved Speech Language Models Latently Work In Text
Pith reviewed 2026-06-26 10:39 UTC · model grok-4.3
The pith
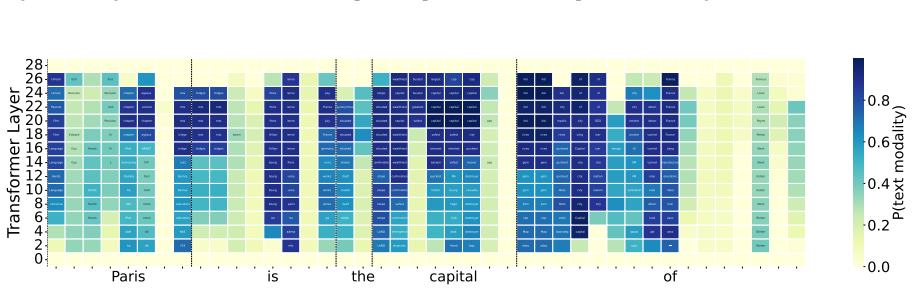
Interleaved speech language models decode spoken words as text tokens in their intermediate layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
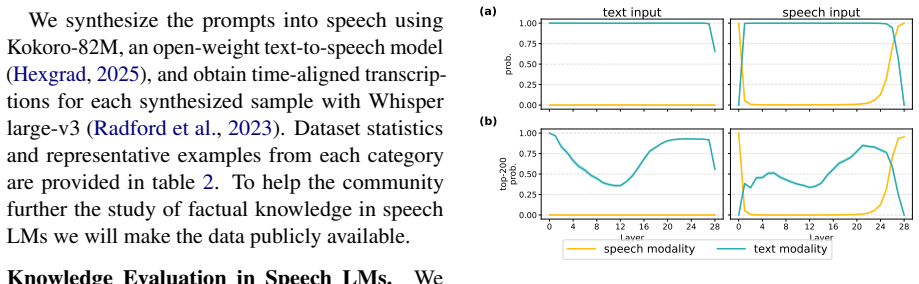
These models go through an implicit transcription phase in which the text token of the spoken word becomes decodable in intermediate layers, despite not being trained for speech recognition. The transcription of the word appears as one of the top candidate words for as much as 77% of the data. Following this stage, the models proceed to predict the next word in the text space before transforming back to the speech domain.
What carries the argument
Logit lens applied to intermediate layers, which extracts the text-token predictions that become decodable during the transcription phase.
If this is right
- Interleaving speech and text data during training elicits the internal transcription behavior.
- Initializing from a text language model strengthens the emergence of the transcription phase.
- The presence and strength of the transcription phase correlates with the model's spoken-knowledge performance.
- After the transcription stage the model completes next-word prediction entirely within the text token space.
Where Pith is reading between the lines
- Pure speech-only models without interleaving may lack access to this latent text pathway and therefore underperform on knowledge-intensive spoken tasks.
- Training objectives could be designed to explicitly strengthen or control the duration of the transcription window.
- Similar latent translation phases might appear when other modalities are interleaved with text.
Load-bearing premise
The logit lens applied to intermediate layers accurately reflects the model's actual internal computation and decision process rather than an artifact of the probing method itself.
What would settle it
A controlled experiment in which middle-layer activations are altered to suppress the observed text-token candidates and the model is then tested on whether its final speech output still matches the original behavior on the same inputs.
Figures


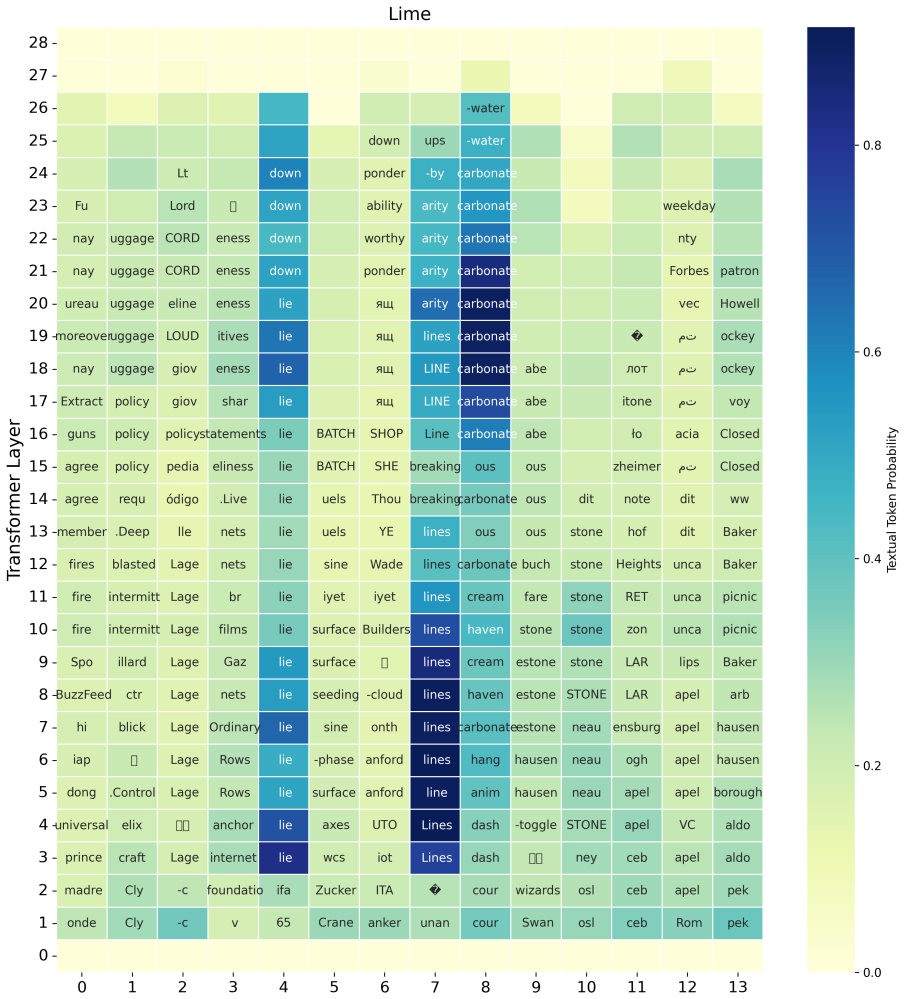



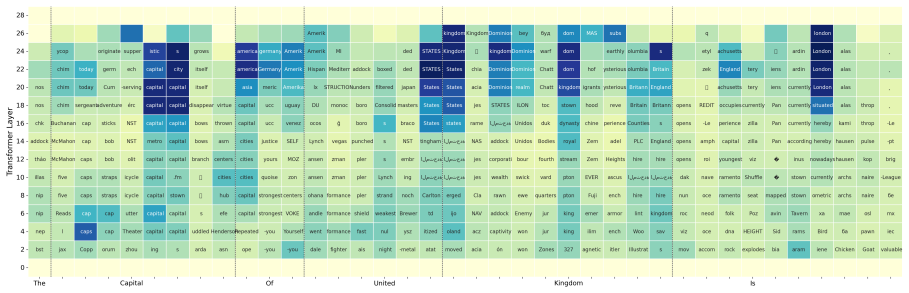
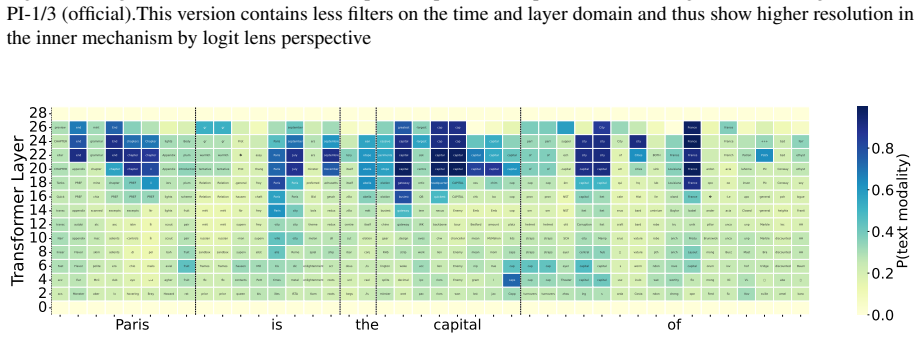
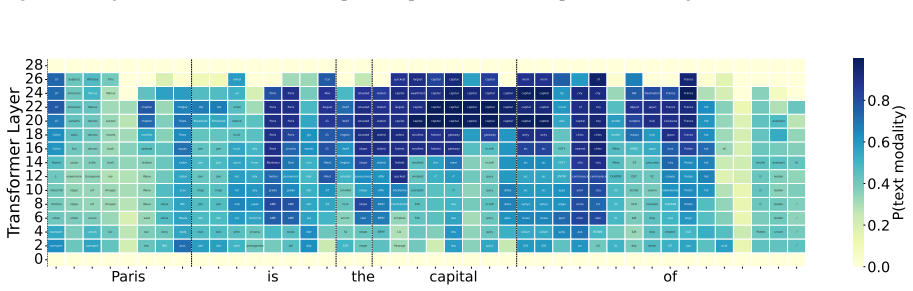






read the original abstract
Speech language models (SLMs) have been extensively studied, with the common paradigm incorporating text data and pre-trained text LMs. A leading approach is speech-text interleaving in which models are trained over sequences containing both speech and text tokens, aiming to boost even speech-only capabilities. Yet the way these two modalities interact in the model latent space remains unclear. In this work, we analyze interleaved speech-text LMs from different model families and sizes through the scope of the logit lens to provide such insight. We reveal that these models go through an implicit transcription phase in which the text token of the spoken word becomes decodable in intermediate layers, despite not being trained for speech recognition. The transcription of the word appears as one of the top candidate words for as much as 77\% of the data. Following this stage, the models proceed to predict the next word in the text space before transforming back to the speech domain. We finally analyze the role of interleaving data, and initializing from text LMs in eliciting this behavior, as well as seeing how this correlates with spoken knowledge abilities. Our analysis sheds light on the internal mechanisms underlying the relationship between speech and text modalities and could shape SLM optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes interleaved speech-text language models from multiple families and sizes using the logit lens. It claims these models undergo an implicit transcription phase in intermediate layers, where the text token of a spoken word becomes decodable and ranks among the top candidates for up to 77% of examples despite no explicit speech recognition training; models then predict the next token in text space before returning to the speech domain. The work further examines how interleaving data and text-LM initialization elicit this behavior and its correlation with spoken knowledge abilities.
Significance. If the logit-lens observations hold and reflect genuine internal computation, the result would provide a concrete mechanistic account of modality interaction in interleaved SLMs, highlighting an emergent transcription-like stage that could guide training recipes. The comparative analysis across model scales and the correlation with spoken capabilities are useful observational contributions. The work employs an established probing technique rather than introducing new machinery, so its primary value lies in the reported patterns rather than in novel methodology.
major comments (3)
- [Abstract / Methods] Abstract and Methods: the headline quantitative result (77% top-candidate rate) is presented without dataset size, number of models or examples evaluated, statistical controls, or confirmation that the metric was pre-specified rather than selected post-hoc. These details are required to evaluate whether the central claim is supported.
- [Results (logit lens)] Results section on logit-lens analysis: the claim that the decoded text token reflects an implicit transcription phase that the model actually uses rests on the unembedding matrix applied to intermediate residual streams, yet no causal intervention (activation patching, head ablation, or counterfactual editing) is reported to test whether that token influences final predictions.
- [Discussion] Discussion of modality mixing: in speech-text models the residual stream interleaves modalities, so the assumption that the text-only unembedding matrix surfaces the model's actual internal computation (rather than a spurious correlation) requires explicit justification or controls; the current observational correlations with interleaving and text initialization do not address this.
minor comments (2)
- [Methods] Clarify the precise definition of 'top candidate words' (rank threshold, vocabulary size, handling of subword tokens) and report the exact evaluation protocol in a dedicated methods subsection.
- [Figures] Figure captions and axis labels should explicitly state the number of examples and models underlying each plotted percentage.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of clarity and evidential strength. We address each major comment below and will revise the manuscript to incorporate additional details, caveats, and justifications where appropriate. These changes will improve the paper without altering its core observational findings.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: the headline quantitative result (77% top-candidate rate) is presented without dataset size, number of models or examples evaluated, statistical controls, or confirmation that the metric was pre-specified rather than selected post-hoc. These details are required to evaluate whether the central claim is supported.
Authors: We agree that these experimental details should be explicitly stated. The 77% figure represents the maximum top-candidate rate observed across the evaluated conditions. In the revised version we will report the dataset size (number of spoken utterances), the number of models and families analyzed, the total examples per condition, and any statistical measures used. We will also clarify that the top-candidate metric follows conventions from prior logit-lens studies rather than being chosen post-hoc. These additions will be made to both the abstract and methods sections. revision: yes
-
Referee: [Results (logit lens)] Results section on logit-lens analysis: the claim that the decoded text token reflects an implicit transcription phase that the model actually uses rests on the unembedding matrix applied to intermediate residual streams, yet no causal intervention (activation patching, head ablation, or counterfactual editing) is reported to test whether that token influences final predictions.
Authors: The analysis is observational and relies on the logit lens, an established but correlational technique. We do not present causal evidence that the surfaced text token is directly used in downstream computation. To address this, we will revise the results and discussion to use more precise language (e.g., “suggests a latent transcription-like stage” instead of implying direct usage) and will add an explicit limitations paragraph noting the absence of causal interventions such as patching. This revision clarifies the strength of the evidence without overstating it. revision: yes
-
Referee: [Discussion] Discussion of modality mixing: in speech-text models the residual stream interleaves modalities, so the assumption that the text-only unembedding matrix surfaces the model's actual internal computation (rather than a spurious correlation) requires explicit justification or controls; the current observational correlations with interleaving and text initialization do not address this.
Authors: We acknowledge that applying a text-only unembedding to a mixed-modality residual stream requires careful interpretation. In the revision we will expand the discussion to justify the approach by highlighting that the text-token emergence is strongly modulated by text-LM initialization and interleaving data, and that it correlates with spoken-knowledge performance. We will also cite prior logit-lens applications to multimodal models and explicitly note the possibility of spurious correlations, recommending causal follow-up work. These additions provide the requested justification and controls discussion. revision: yes
Circularity Check
No circularity: observational logit-lens analysis on existing models
full rationale
The paper applies the established logit lens technique to probe intermediate layers of pre-trained interleaved SLMs. All claims (implicit transcription phase, top-candidate rates up to 77%, correlation with interleaving) are direct empirical observations from applying the final unembedding matrix to residual streams; no parameter is fitted to a subset and then renamed as a prediction, no self-citation chain justifies a uniqueness theorem, and no derivation reduces to its own inputs by construction. The work is self-contained against external benchmarks because the observations are falsifiable on the same models without requiring the paper's own fitted values.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On The Landscape of Spoken Language Models: A Comprehensive Survey
On the landscape of spoken lan- guage models: A comprehensive survey.Preprint, arXiv:2504.08528. Jayadev Billa
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Jingyi Chen, Zhimeng Guo, Jiyun Chun, Pichao Wang, Andrew Perrault, and Micha Elsner
The cascade equivalence hypoth- esis: When do speech llms behave like asr →llm pipelines?Preprint, arXiv:2602.17598. Jingyi Chen, Zhimeng Guo, Jiyun Chun, Pichao Wang, Andrew Perrault, and Micha Elsner
-
[3]
acoustic emotion cues reliance.Preprint, arXiv:2510.10444
Do au- dio llms really listen, or just transcribe? measuring lexical vs. acoustic emotion cues reliance.Preprint, arXiv:2510.10444. Yiming Chen, Xianghu Yue, Chen Zhang, Xiaoxue Gao, Robby T Tan, and Haizhou Li
-
[4]
VoiceBench: Benchmarking LLM-Based Voice Assistants
V oicebench: Benchmarking llm-based voice assistants.arXiv preprint arXiv:2410.17196. Santiago Cuervo and Ricard Marxer
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
InProceed- ings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 351–361
Scaling properties of speech language models. InProceed- ings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 351–361. Guy Dar, Mor Geva, Ankit Gupta, and Jonathan Berant
2024
-
[6]
Moshi: a speech-text foundation model for real-time dialogue
Moshi: a speech- text foundation model for real-time dialogue.arXiv preprint arXiv:2410.00037. Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
The llama 3 herd of models.Preprint, arXiv:2407.21783. Daniel Galvez, Greg Diamos, Juan Ciro, Juan Felipe Cerón, Keith Achorn, Anjali Gopi, David Kanter, Maximilian Lam, Mark Mazumder, and Vijay Janapa Reddi
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Mor Geva, Avi Caciularu, Kevin Wang, and Yoav Gold- berg
The people’s speech: A large-scale diverse english speech recognition dataset for com- mercial usage.Preprint, arXiv:2111.09344. Mor Geva, Avi Caciularu, Kevin Wang, and Yoav Gold- berg
-
[9]
InProceedings of the 2022 conference on empirical methods in natural language processing, pages 30–45
Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space. InProceedings of the 2022 conference on empirical methods in natural language processing, pages 30–45. Neta Glazer, Yael Segal-Feldman, Hilit Segev, Aviv Shamsian, Asaf Buchnick, Gill Hetz, Ethan Fe- taya, Joseph Keshet, and Aviv Navon
2022
-
[10]
Danny Halawi, Jean-Stanislas Denain, and Jacob Stein- hardt
Be- yond transcription: Mechanistic interpretability in asr.Preprint, arXiv:2508.15882. Danny Halawi, Jean-Stanislas Denain, and Jacob Stein- hardt
-
[11]
InInternational Conference on Learning Representa- tions, volume 2024, pages 42749–42787
Overthinking the truth: Understanding how language models process false demonstrations. InInternational Conference on Learning Representa- tions, volume 2024, pages 42749–42787. Michael Hassid, Tal Remez, Tu Anh Nguyen, Itai Gat, Alexis Conneau, Felix Kreuk, Jade Copet, Alexan- dre Defossez, Gabriel Synnaeve, Emmanuel Dupoux, and 1 others
2024
-
[12]
Anatomy of the modality gap: Dissecting the internal states of end- to-end speech llms.Preprint, arXiv:2603.01502. Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdel- rahman Mohamed
-
[13]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units.Preprint, arXiv:2106.07447. J. Kahn, M. Riviere, W. Zheng, E. Kharitonov, Q. Xu, P.E. Mazare, J. Karadayi, V . Liptchinsky, R. Col- lobert, C. Fuegen, T. Likhomanenko, G. Synnaeve, A. Joulin, A. Mohamed, and E. Dupoux
-
[14]
InICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP), page 7669–7673
Libri- light: A benchmark for asr with limited or no super- vision. InICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP), page 7669–7673. IEEE. Arne Köhn, Florian Stegen, and Timo Baumann
2020
-
[15]
InProceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Paris, France
Mining the spoken wikipedia for speech data and beyond. InProceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Paris, France. European Language Re- sources Association (ELRA). Kushal Lakhotia, Eugene Kharitonov, Wei-Ning Hsu, Yossi Adi, Adam Polyak, Benjamin Bolte, Tu-Anh Nguyen, Jade Copet, Alexei Baevski, A...
2016
-
[16]
10 Omar Mahmoud, Buddhika Laknath Semage, Thom- men George Karimpanal, and Santu Rana
Looking beyond the top-1: Transformers determine top tokens in order.Preprint, arXiv:2410.20210. 10 Omar Mahmoud, Buddhika Laknath Semage, Thom- men George Karimpanal, and Santu Rana
-
[17]
Gallil Maimon, Avishai Elmakies, and Yossi Adi
Improving multilingual language models by align- ing representations through steering.Preprint, arXiv:2505.12584. Gallil Maimon, Avishai Elmakies, and Yossi Adi. 2025a. Slamming: Training a speech language model on one GPU in a day. InFindings of the Association for Computational Linguistics: ACL 2025, pages 12201– 12216, Vienna, Austria. Association for ...
-
[18]
Scaling open discrete audio founda- tion models with interleaved semantic, acoustic, and text tokens.arXiv preprint arXiv:2602.16687. Pooneh Mousavi, Gallil Maimon, Adel Moumen, Dar- ius Petermann, Jiatong Shi, Haibin Wu, Haici Yang, Anastasia Kuznetsova, Artem Ploujnikov, Ricard Marxer, Bhuvana Ramabhadran, Benjamin Elizalde, Loren Lugosch, Jinyu Li, Cem...
-
[19]
InInternational Conference on Learn- ing Representations, volume 2024, pages 51883– 51898
Spoken question an- swering and speech continuation using spectrogram- powered llm. InInternational Conference on Learn- ing Representations, volume 2024, pages 51883– 51898. Clement Neo, Luke Ong, Philip Torr, Mor Geva, David Krueger, and Fazl Barez
2024
-
[20]
InInternational Conference on Learning Representations, volume 2025, pages 57172–57189
Towards interpret- ing visual information processing in vision-language models. InInternational Conference on Learning Representations, volume 2025, pages 57172–57189. Tu Anh Nguyen, Benjamin Muller, Bokai Yu, Marta R. Costa-jussa, Maha Elbayad, Sravya Pop- uri, Christophe Ropers, Paul-Ambroise Duquenne, Robin Algayres, Ruslan Mavlyutov, Itai Gat, Mary Wi...
2025
-
[21]
Qwen2.5 technical report.Preprint, arXiv:2412.15115. Alec Radford, Jong Wook Kim, Tao Xu, Greg Brock- man, Christine McLeavey, and Ilya Sutskever
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Scaling language models: Methods, analysis & insights from training gopher.arXiv preprint arXiv:2112.11446. Sakshi Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ra- mani Duraiswami, Sreyan Ghosh, and Dinesh Manocha
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
InInter- national Conference on Learning Representations, volume 2025, pages 84929–84964
Mmau: A massive multi-task audio understanding and reasoning benchmark. InInter- national Conference on Learning Representations, volume 2025, pages 84929–84964. Changhan Wang, Morgane Rivière, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, and Emmanuel Dupoux
2025
-
[24]
V oxpop- uli: A large-scale multilingual speech corpus for rep- resentation learning, semi-supervised learning and interpretation.Preprint, arXiv:2101.00390. Maurice Weber, Daniel Y . Fu, Quentin Anthony, Yonatan Oren, Shane Adams, Anton Alexandrov, Xiaozhong Lyu, Huu Nguyen, Xiaozhe Yao, Vir- ginia Adams, Ben Athiwaratkun, Rahul Chalamala, Kezhen Chen, M...
-
[25]
Bajian Xiang, Shuaijiang Zhao, Tingwei Guo, and Wei Zou
The semantic hub hypothesis: Language models share semantic repre- sentations across languages and modalities.Preprint, arXiv:2411.04986. Bajian Xiang, Shuaijiang Zhao, Tingwei Guo, and Wei Zou
-
[26]
Understanding the modality gap: An empirical study on the speech-text alignment mech- anism of large speech language models.Preprint, arXiv:2510.12116. Zhifei Xie and Changqiao Wu
-
[27]
Sohee Yang, Elena Gribovskaya, Nora Kassner, Mor Geva, and Sebastian Riedel
Mini-omni: Lan- guage models can hear, talk while thinking in stream- ing.arXiv preprint arXiv:2408.16725. Sohee Yang, Elena Gribovskaya, Nora Kassner, Mor Geva, and Sebastian Riedel
-
[28]
StressTest: Can YOUR Speech LM Handle the Stress?
Stresstest: Can your speech lm handle the stress? Preprint, arXiv:2505.22765. Aohan Zeng, Zhengxiao Du, Mingdao Liu, Lei Zhang, Yuxiao Dong, Jie Tang, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
InInternational Conference on Learning Rep- resentations, volume 2025, pages 49396–49419
Scaling speech-text pre-training with synthetic interleaved data. InInternational Conference on Learning Rep- resentations, volume 2025, pages 49396–49419. Yiran Zhao, Wenxuan Zhang, Guizhen Chen, Kenji Kawaguchi, and Lidong Bing
2025
-
[30]
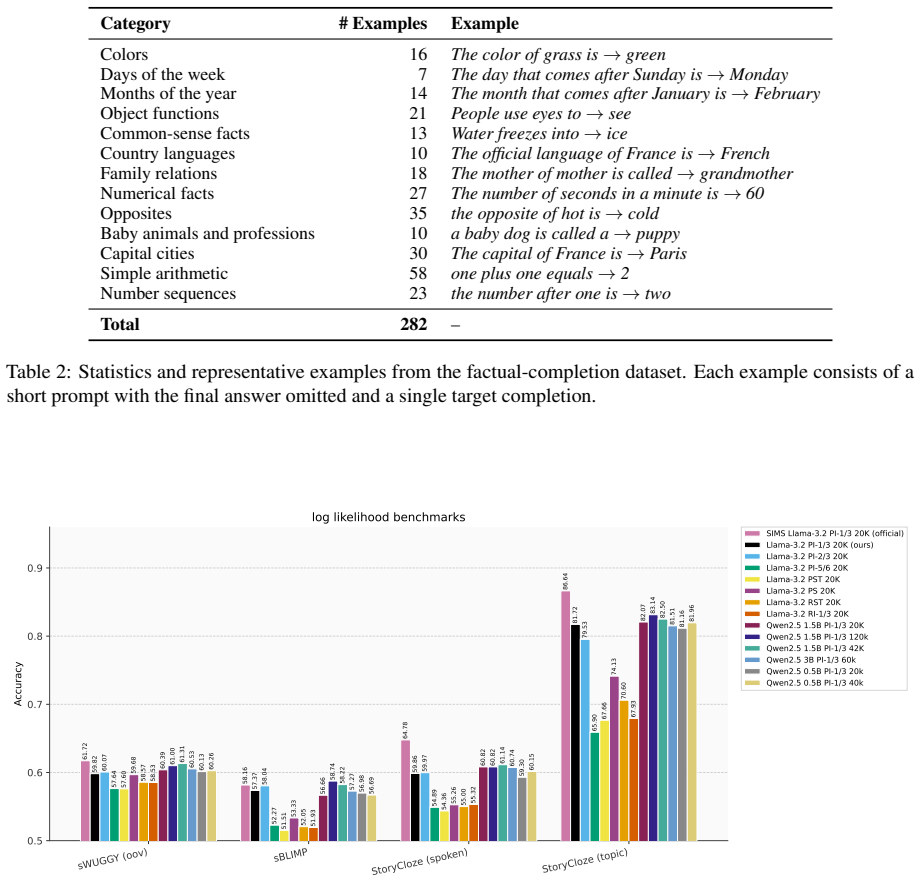
How do large language models handle multilingualism?Preprint, arXiv:2402.18815. 12 A Appendix A.1 Common Sense Dataset Table 2 reports statistics for the different subsets of our evaluation dataset, along with one representa- tive example from each subset. A.2 Experimental Setup Interleaving.We follow Zeng et al. (2025), sam- pling speech-segment lengths ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.