Generative Robust Optimisation
Pith reviewed 2026-06-26 10:30 UTC · model grok-4.3
The pith
A deep generative model defines uncertainty sets for robust optimization that capture nonlinear correlations, asymmetry, and multimodality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
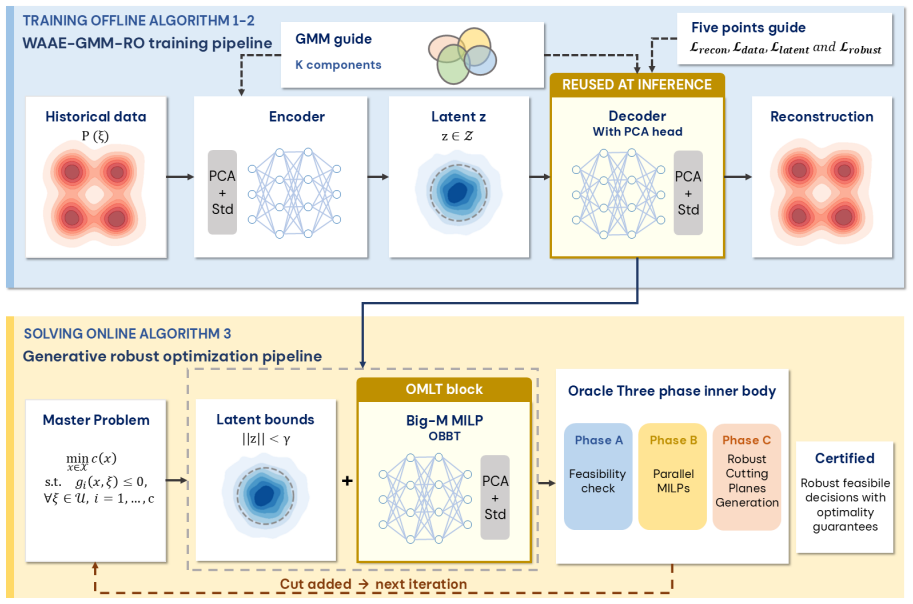
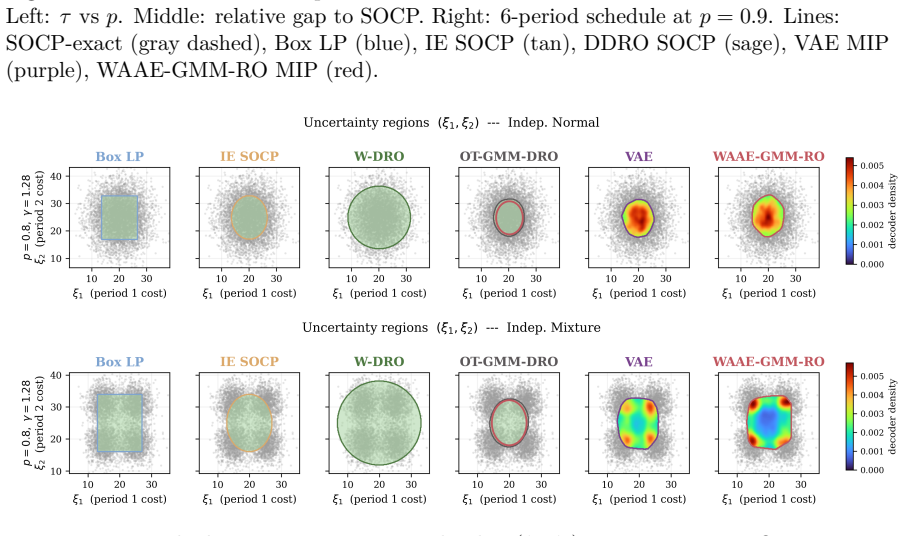
Defining the uncertainty set as the image of a neural network decoder over a calibrated latent set, instantiated via a Wasserstein Adversarial Autoencoder with GMM-guided training for latent regularity and constraint-consistency regularisation for robust relevance, and restricting the decoder to ReLU activations, produces uncertainty sets that accommodate nonlinear correlations, asymmetry, and multimodality while permitting exact worst-case verification through mixed-integer programming embedding.
What carries the argument
Generative Robust Optimisation (GRO) framework in which the uncertainty set is the image of a neural network decoder over a calibrated latent set, evaluated by a five-point model-agnostic framework and instantiated with a Wasserstein Adversarial Autoencoder using ReLU activations for mixed-integer programming embedding.
If this is right
- Uncertainty sets can represent nonlinear correlations, asymmetry, and multimodality instead of being restricted to fixed geometric shapes.
- Worst-case realizations become exactly verifiable through mixed-integer programming when the decoder uses only ReLU activations.
- The five-point evaluation framework supplies systematic criteria that any neural network-based uncertainty set can be assessed against.
- Systematic attention to reconstruction fidelity, distribution matching, latent regularity, robust relevance, and tractability produces sets that are simultaneously expressive and optimisation-tractable.
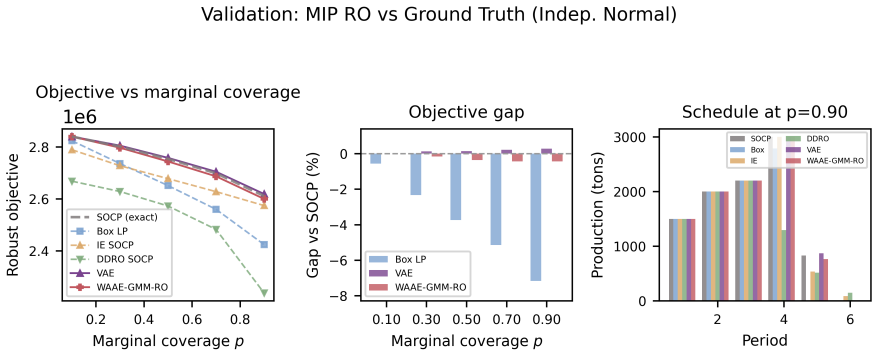
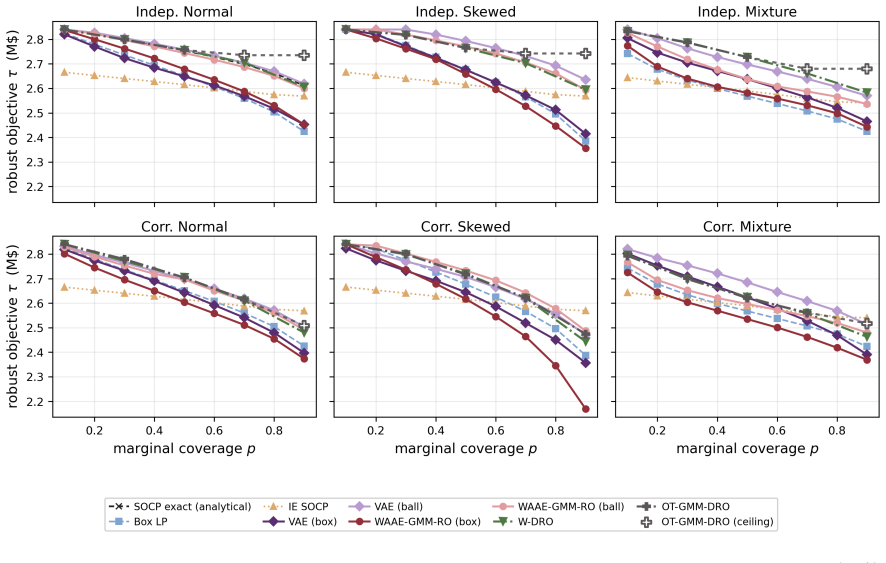
- The approach yields improved robust solutions on production planning and multi-period facility location problems across multiple uncertainty distributions.
Where Pith is reading between the lines
- The framework could be extended to multi-stage or adaptive robust optimization where uncertainty evolves over time and new data arrives sequentially.
- Hybrid combinations with stochastic programming or distributionally robust optimization might further improve performance when partial distributional information is available.
- Testing the same generative construction on high-dimensional or time-series uncertainty would reveal whether the ReLU-MIP tractability scales beyond the reported planning instances.
- The five-point criteria could serve as a template for evaluating generative models in other downstream tasks that require both fidelity to data and tractability under optimization.
Load-bearing premise
The generative model trained with the proposed regularisations produces an uncertainty set whose worst-case realizations can be reliably found and that accurately represents the true data-generating process for the downstream robust optimization problem.
What would settle it
If experiments on the production planning problem show that GRO solutions fail to outperform classical robust methods on out-of-sample data or if the mixed-integer programming embedding cannot identify the true worst-case points within the generated set, the central claim would be falsified.
Figures



read the original abstract
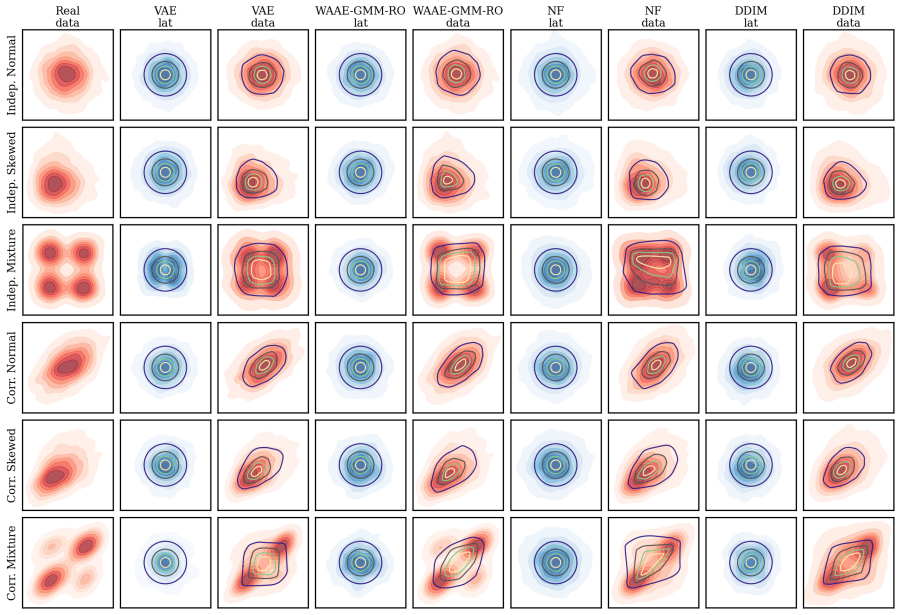
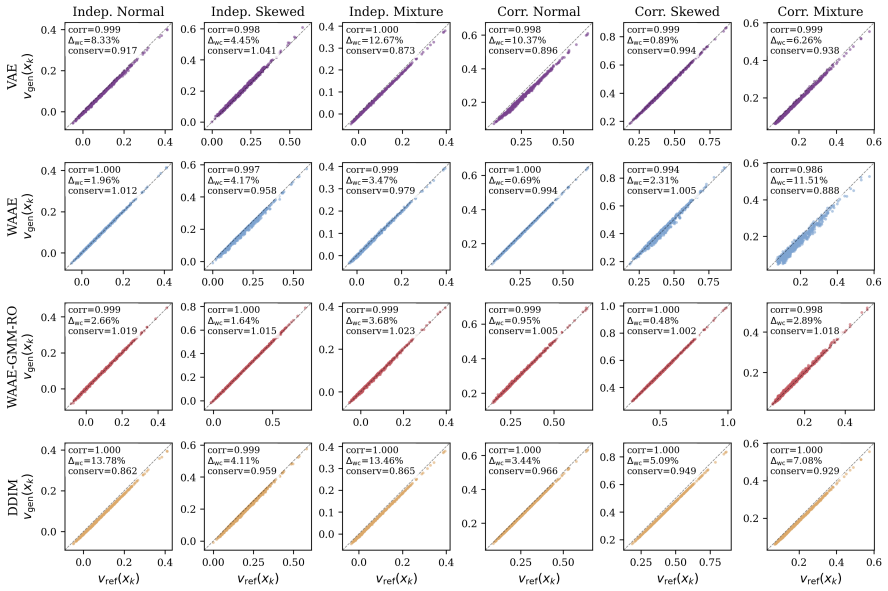
Classical uncertainty sets for robust optimisation impose fixed geometric shapes that cannot represent the complex dependencies present in real-world data. We propose Generative Robust Optimisation (GRO), a framework in which a deep generative model defines the uncertainty set as the image of a neural network decoder over a calibrated latent set, naturally accommodating nonlinear correlations, asymmetry, and multimodality. A five-point evaluation framework (reconstruction fidelity, distribution matching, latent regularity, robust relevance, and computational tractability) provides systematic, model-agnostic criteria for assessing any neural network-based uncertainty set. We instantiate this framework with a Wasserstein Adversarial Autoencoder employing Gaussian mixture model-guided training for latent regularity and constraint-consistency regularisation for robust relevance. Restricting the decoder to ReLU activations enables exact worst-case verification through mixed-integer programming embedding. Extensive experiments on a production planning problem across six uncertainty distributions and six generative architectures, together with a multi-period facility location study, validate the framework and demonstrate that systematic attention to all five criteria yields uncertainty sets that are simultaneously expressive, well-calibrated, and optimisation-tractable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Generative Robust Optimisation (GRO), a framework in which a deep generative model defines the uncertainty set for robust optimisation as the image of a neural network decoder over a calibrated latent set. It introduces a five-point evaluation framework (reconstruction fidelity, distribution matching, latent regularity, robust relevance, computational tractability) that is model-agnostic, instantiates the framework with a regularized Wasserstein Adversarial Autoencoder (WAAE) using GMM-guided latent training and constraint-consistency regularisation, restricts the decoder to ReLU activations to enable exact MIP embedding for worst-case verification, and reports experiments on a production planning problem across six uncertainty distributions and six architectures plus a multi-period facility location study.
Significance. If the empirical results hold, the framework supplies a systematic route to uncertainty sets that capture nonlinear correlations, asymmetry and multimodality while remaining optimisation-tractable. The explicit five-criterion checklist and the MIP-embedding technique for ReLU decoders are concrete strengths; the breadth of the experimental suite (six distributions, six architectures, multi-period case) supplies falsifiable evidence on the central claim.
minor comments (3)
- [§3] §3 (five-point framework): the definitions of the five criteria are stated at a high level; explicit formulas or pseudocode for each metric (especially 'robust relevance' and 'latent regularity') would make the model-agnostic claim easier to replicate.
- [Table 2] Table 2 (production planning results): the reported out-of-sample robust costs for the GRO variants are compared only to classical sets; adding a simple data-driven baseline (e.g., empirical quantile set) would strengthen the claim that the generative construction is necessary.
- [§5.2] §5.2 (MIP embedding): the reduction of the worst-case problem to a mixed-integer program is asserted for ReLU decoders, but the precise big-M constants and the handling of the latent GMM components are not shown; a short appendix derivation would remove any ambiguity.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report accurately captures the manuscript's contributions without identifying any specific major comments requiring detailed rebuttal.
Circularity Check
No significant circularity detected
full rationale
The paper proposes the GRO framework defining uncertainty sets as decoder images over latent sets, instantiated with standard WAAE, GMM-guided training, constraint-consistency regularization, and ReLU MIP embedding. The five evaluation criteria are explicitly model-agnostic, and claims rest on empirical validation across multiple distributions and architectures rather than any derivation that reduces by construction to fitted inputs, self-definitions, or self-citation chains. No load-bearing step equates a prediction to its own training data or imports uniqueness from prior author work as an external theorem.
Axiom & Free-Parameter Ledger
free parameters (2)
- regularization weights for constraint-consistency
- GMM component parameters for latent training
axioms (1)
- standard math ReLU networks admit exact MIP encoding for worst-case verification
Reference graph
Works this paper leans on
-
[1]
Panagiotis Andrianesis, Dimitris Bertsimas, Thodoris Koukouvinos, and Angelos Georgios Koulouras
doi: 10.1007/s10107-020-01474-5. Panagiotis Andrianesis, Dimitris Bertsimas, Thodoris Koukouvinos, and Angelos Georgios Koulouras. Ensembling wind forecasting models to construct data-driven uncertainty sets in robust optimization. InIEEE Power & Energy Society General Meeting (PESGM),
-
[2]
Foundations and Trends® in Machine Learning , author =
doi: 10.1561/2200000101. Opher Baron, Joseph Milner, and Hussein Naseraldin. Facility location: A robust optimization approach.Production and Operations Management, 20(5):772–785,
-
[3]
Geophysical Journal International13(1-3), 247–276 (1967) https://doi.org/10.1111/j
doi: 10.1111/j. 1937-5956.2010.01194.x. Aharon Ben-Tal and Arkadi Nemirovski. Robust convex optimization.Mathematics of Opera- tions Research, 23(4):769–805,
work page doi:10.1111/j 1937
-
[4]
Aharon Ben-Tal, Laurent El Ghaoui, and Arkadi Nemirovski.Robust Optimization
doi: 10.1016/S0167-6377(99)00016-4. Aharon Ben-Tal, Laurent El Ghaoui, and Arkadi Nemirovski.Robust Optimization. Princeton University Press,
-
[6]
Jamie Fairbrother, Amanda Turner, and Stein W
URLhttps://arxiv.org/ abs/1611.02648. Jamie Fairbrother, Amanda Turner, and Stein W. Wallace. Problem-driven scenario genera- tion: an analytical approach for stochastic programs with tail risk measure.Mathematical Programming, 191(1):141–182,
-
[7]
doi: 10.1007/s10107-019-01451-7. Rui Gao, Xi Chen, and Anton J. Kleywegt. Wasserstein distributionally robust optimization and variation regularization.Operations Research, 72(3):1177–1191,
-
[8]
doi: 10.1287/opre. 2022.2383. Marc Goerigk and Jannis Kurtz. Data-driven robust optimization using deep neural networks. Computers & Operations Research, 151:106087,
-
[9]
doi: 10.1287/mnsc. 2020.3640. Zhuxi Jiang, Yin Zheng, Huachun Tan, Bangsheng Tang, and Hanning Zhou. Variational deep embedding: An unsupervised and generative approach to clustering. InProceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), pages 1965–1972,
-
[10]
Sanjula Kammammettu, Shu-Bo Yang, and Zukui Li
doi: 10.24963/ijcai.2017/273. Sanjula Kammammettu, Shu-Bo Yang, and Zukui Li. Distributionally robust optimization using optimal transport for Gaussian mixture models.Optimization and Engineering, 25(3):1571– 1596,
-
[11]
doi: 10.1007/s11081-023-09856-2. 44 Diederik P. Kingma and Max Welling. Auto-encoding variational Bayes. InInternational Con- ference on Learning Representations (ICLR),
-
[12]
Zukui Li, Qiuhua Tang, and Christodoulos A
doi: 10.1017/S0962492924000084. Zukui Li, Qiuhua Tang, and Christodoulos A. Floudas. A comparative theoretical and compu- tational study on robust counterpart optimization: II. Probabilistic guarantees on constraint satisfaction.Industrial & Engineering Chemistry Research, 51(19):6769–6788,
-
[13]
Benoît Loger, Alexandre Dolgui, Fabien Lehuédé, and Guillaume Massonnet
doi: 10.1021/ie201651s. Benoît Loger, Alexandre Dolgui, Fabien Lehuédé, and Guillaume Massonnet. Approximate kernel learning uncertainty set for robust combinatorial optimization.INFORMS Journal on Computing, 36(3):900–917,
-
[14]
Weiguo Lu, Deng Ding, Fengyan Wu, and Gangnan Yuan
doi: 10.1287/ijoc.2022.0330. Weiguo Lu, Deng Ding, Fengyan Wu, and Gangnan Yuan. An efficient Gaussian mixture model and its application to neural networks.Knowledge-Based Systems, 310:112942,
-
[15]
doi: 10.1016/j.knosys.2024.112942. Yulong Lu and Jianfeng Lu. A universal approximation theorem of deep neural networks for expressing probability distributions. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[16]
Peyman Mohajerin Esfahani and Daniel Kuhn
doi: 10.69997/sct.168949. Peyman Mohajerin Esfahani and Daniel Kuhn. Data-driven distributionally robust optimiz- ation using the Wasserstein metric: performance guarantees and tractable reformulations. Mathematical Programming, 171(1):115–166,
-
[17]
doi: 10.1007/s10107-017-1172-1. George Papamakarios, Eric Nalisnick, Danilo Jimenez Rezende, Shakir Mohamed, and Balaji Lakshminarayanan. Normalizing flows for probabilistic modeling and inference.Journal of Machine Learning Research, 22(57):1–64,
-
[18]
Danilo Jimenez Rezende and Fabio Viola
ISBN 9781420091823. Danilo Jimenez Rezende and Fabio Viola. Taming VAEs.arXiv:1810.00597,
-
[19]
Akylas Stratigakos and Panagiotis Andrianesis. Learning data-driven uncertainty set par- titions for robust and adaptive energy forecasting with missing data.arXiv preprint arXiv:2503.20410,
-
[20]
Chen Xu, Jonghyeok Lee, Xiuyuan Cheng, and Yao Xie
doi: 10.1287/opre.2014.1314. Chen Xu, Jonghyeok Lee, Xiuyuan Cheng, and Yao Xie. Flow-based distributionally robust optimization.IEEE Journal on Selected Areas in Information Theory, 5:62–77,
-
[21]
doi: 10.1109/JSAIT.2024.3370699. 46
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.