Look Light, Think Heavy: What Multimodal Chain-of-Thought Reasoning Can and Cannot Do
Pith reviewed 2026-06-26 10:25 UTC · model grok-4.3
The pith
Multimodal chain-of-thought improves verbal reasoning tasks but reduces accuracy on perception tasks and loses visual reflection over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
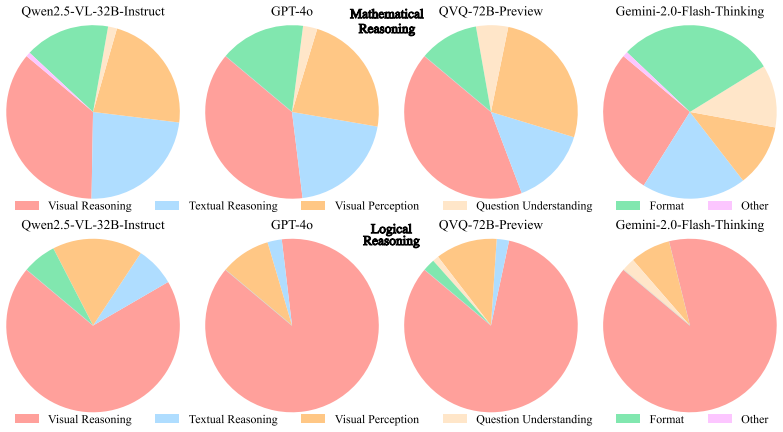
Models exhibit a Look Light, Think Heavy pattern in which verbal reflection increases then decreases during reasoning while visual reflection consistently diminishes, making sustained visual introspection the primary bottleneck for multimodal CoT.
What carries the argument
Analysis of verbal versus visual reflection patterns extracted from model outputs across perception and reasoning tasks.
If this is right
- CoT prompting should be applied selectively rather than by default in multimodal systems.
- Training focused mainly on mathematical reasoning leaves other multimodal capabilities underdeveloped.
- Future multimodal models need mechanisms to keep visual attention active across multiple reasoning steps.
Where Pith is reading between the lines
- If visual reflection can be preserved, perception-task performance may rise without sacrificing reasoning gains.
- Task-specific routing that turns CoT on only for reasoning categories could become a practical design choice.
- The pattern suggests that current vision encoders are not yet integrated deeply enough into the step-by-step reasoning loop.
Load-bearing premise
The 12 chosen tasks and 22 models represent the full range of multimodal perception and reasoning, and output reflection counts accurately reflect the model's internal processes.
What would settle it
A new model or training method that maintains high visual reflection counts through entire reasoning traces on the same perception tasks while also raising accuracy.
Figures

























read the original abstract
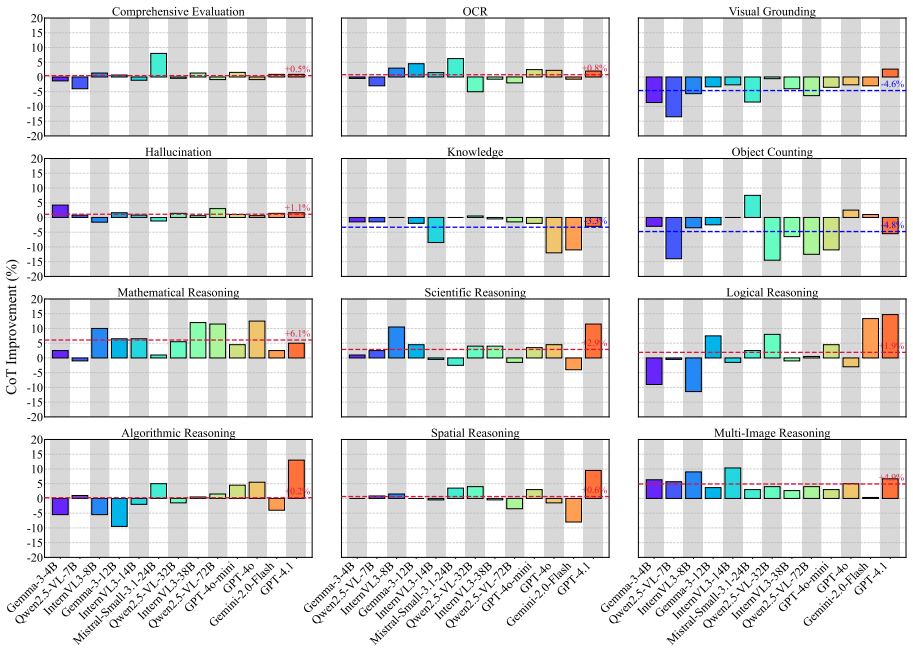
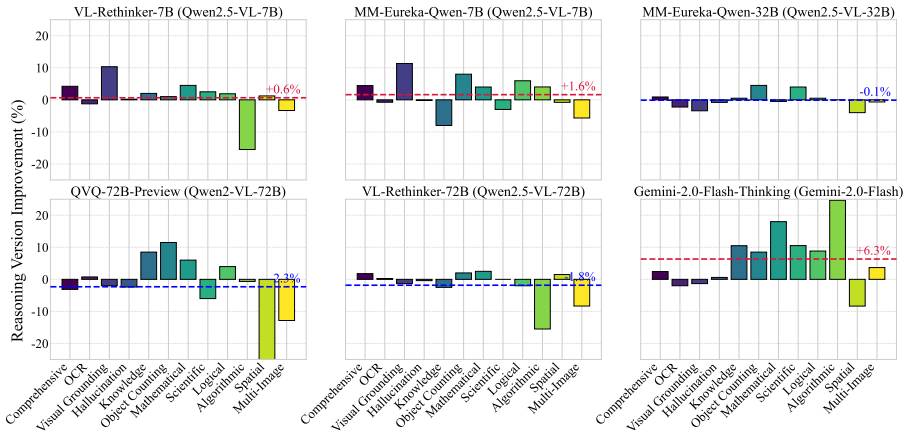
Chain-of-Thought (CoT) has become a standard method for improving reasoning capabilities in large language models (LLMs) by eliciting step-by-step thinking, but its effectiveness in multimodal tasks remains unclear. In this paper, we aim to systematically investigate the key question: What can multimodal Chain-of-Thought reasoning do, and where and why does it fall short? To this end, we evaluate 12 multimodal tasks across perception and reasoning categories using both 14 non-reasoning models and 8 reasoning models. Our analysis reveals several important findings: (1) CoT is not a free lunch and should be used selectively depending on the specific requirements of each task. For perception tasks, CoT can lead to undesirable side effects, such as reduced performance in visual grounding and object counting. In contrast, it proves effective for reasoning tasks involving mathematical, scientific, and multi-image reasoning; (2) Compared to original models, existing open-source multimodal reasoning models often yield only marginal overall improvements, possibly due to an overemphasis on mathematical reasoning at the expense of broader capabilities; (3) Visual reasoning remains a key bottleneck for current multimodal CoT, as models exhibit a Look Light, Think Heavy pattern where verbal reflection rises and falls during reasoning, whereas visual reflection consistently diminishes. These findings suggest that while multimodal CoT handles verbal reflection relatively well, it lacks the ability to maintain deep visual introspection throughout the reasoning process.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates multimodal Chain-of-Thought reasoning on 12 tasks spanning perception and reasoning categories using 14 non-reasoning and 8 reasoning multimodal models. It reports that CoT harms performance on perception tasks such as visual grounding and object counting, yields only marginal gains for existing open-source reasoning models, and identifies visual reasoning as the primary bottleneck via a 'Look Light, Think Heavy' pattern in which verbal reflection varies while visual reflection consistently diminishes across reasoning steps.
Significance. If the empirical patterns hold under more rigorous controls, the work supplies a useful large-scale benchmark of multimodal CoT behavior and isolates a concrete failure mode (sustained visual introspection) that future architectures must address. The breadth of 22 models and 12 tasks is a strength that supports generalizability claims.
major comments (3)
- [§4] §4 (Reflection Pattern Analysis): The central claim that visual reasoning is the key bottleneck rests on post-hoc parsing of generated CoT text to quantify 'visual reflection.' No attention visualization, hidden-state probing, or causal ablation (e.g., forcing continued visual token references) is reported to confirm that reduced visual content in outputs reflects an internal reasoning failure rather than a generation bias or prompt artifact. This measurement choice is load-bearing for the 'Look Light, Think Heavy' conclusion.
- [§3.2] §3.2 (Task and Metric Details): Performance differences for perception tasks are described as directional but the manuscript provides no error bars, statistical significance tests, or controls for confounding factors such as output length or prompt phrasing. Without these, it is unclear whether the reported harms of CoT on visual grounding and counting are robust.
- [§3.1] §3.1 (Model and Task Selection): The claim that the 12 tasks and 22 models are representative of multimodal perception/reasoning capabilities is asserted without a justification or sensitivity analysis showing that results are stable under alternative task subsets or model families.
minor comments (2)
- [Abstract] Abstract and §4: The term 'visual reflection' is used without an explicit operational definition or example of the parsing rules applied to model outputs.
- Figure captions and tables: Several result tables lack explicit column definitions for the reflection metrics, making it difficult to reproduce the 'rises and falls' versus 'consistently diminishes' patterns.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate where revisions have been or will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Reflection Pattern Analysis): The central claim that visual reasoning is the key bottleneck rests on post-hoc parsing of generated CoT text to quantify 'visual reflection.' No attention visualization, hidden-state probing, or causal ablation (e.g., forcing continued visual token references) is reported to confirm that reduced visual content in outputs reflects an internal reasoning failure rather than a generation bias or prompt artifact. This measurement choice is load-bearing for the 'Look Light, Think Heavy' conclusion.
Authors: We acknowledge that the 'Look Light, Think Heavy' analysis relies on post-hoc parsing of output text rather than internal model probes. This text-based quantification was chosen for its scalability across 22 diverse models and to directly measure observable reflection behavior in generated reasoning chains. We agree this does not constitute causal evidence of internal failure modes. In the revised manuscript we have expanded §4 with (i) the exact parsing rules and inter-annotator agreement, (ii) an explicit limitations paragraph noting the absence of attention or probing experiments, and (iii) a clearer statement that the pattern describes output-level behavior while still highlighting visual introspection as an empirical bottleneck. We view full causal ablations as valuable future work but outside the scope of the current large-scale benchmark. revision: partial
-
Referee: [§3.2] §3.2 (Task and Metric Details): Performance differences for perception tasks are described as directional but the manuscript provides no error bars, statistical significance tests, or controls for confounding factors such as output length or prompt phrasing. Without these, it is unclear whether the reported harms of CoT on visual grounding and counting are robust.
Authors: We agree that the original presentation of perception-task results lacked sufficient statistical controls. In the revised version we have added (i) error bars (standard deviation across three independent generations per model-task pair), (ii) paired statistical tests (Wilcoxon signed-rank) for the key perception tasks, and (iii) a supplementary analysis that matches CoT and non-CoT outputs by length to rule out length-related confounds. Prompt phrasing was already held constant; we now explicitly state this in §3.2. revision: yes
-
Referee: [§3.1] §3.1 (Model and Task Selection): The claim that the 12 tasks and 22 models are representative of multimodal perception/reasoning capabilities is asserted without a justification or sensitivity analysis showing that results are stable under alternative task subsets or model families.
Authors: The 12 tasks were deliberately chosen to cover canonical perception and reasoning categories drawn from established benchmarks (VQA, GQA, MathVista, etc.), and the 22 models span both open-source and proprietary families as well as reasoning-specialized variants. We have added a dedicated paragraph in §3.1 that justifies this selection by referencing prior multimodal evaluation surveys and reports a limited sensitivity check on two task subsets (perception-only and math/science-only) confirming that the main directional patterns remain stable. A exhaustive sensitivity analysis across all possible subsets is computationally prohibitive at this scale; we therefore present the current selection as a broad but not exhaustive sample. revision: partial
Circularity Check
No circularity: purely observational benchmarking with no derivations or self-referential claims
full rationale
The paper conducts an empirical evaluation of 22 models across 12 multimodal tasks, measuring performance and parsing generated CoT outputs for reflection patterns. No equations, parameters, or derivations are present. The central 'Look Light, Think Heavy' observation is a direct post-hoc analysis of output text, not a fitted prediction or self-citation-dependent result. All claims rest on the experimental data collected for this study rather than reducing to prior self-referential inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 12 tasks and 22 models are representative of multimodal CoT behavior
Reference graph
Works this paper leans on
-
[1]
Yihe Deng, Hritik Bansal, Fan Yin, Nanyun Peng, Wei Wang, and Kai-Wei Chang
Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning.CoRR, abs/2501.12948. Yihe Deng, Hritik Bansal, Fan Yin, Nanyun Peng, Wei Wang, and Kai-Wei Chang. 2025. Openvlthinker: An early exploration to complex vision-language reasoning via iterative self-improvement.CoRR, abs/2503.17352. Abhimanyu Dubey, Abhinav Jauhri, Abhinav ...
Pith/arXiv arXiv 2025
-
[2]
Imagine while reasoning in space: Multimodal visualization-of-thought. InForty-second Interna- tional Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025. OpenRe- view.net. Jiachun Li, Shaoping Huang, Zhuoran Jin, Chenlong Zhang, Pengfei Cao, Yubo Chen, Kang Liu, and Jun Zhao. 2026a. MMR-life: Piecing together real-life scen...
Pith/arXiv arXiv 2025
-
[3]
Hallusionbench: You see what you think? or you think what you see? an image-context reasoning benchmark challenging for gpt-4v (ision), llava-1.5, and other multi-modality models.arXiv preprint arXiv:2310.14566, 2(3):9. Qianchu Liu, Sheng Zhang, Guanghui Qin, Timothy Os- sowski, Yu Gu, Ying Jin, Sid Kiblawi, Sam Preston, Mu Wei, Paul V ozila, Tristan Naum...
Pith/arXiv arXiv 2024
-
[4]
InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8317–8326
Towards vqa models that can read. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8317–8326. Yueqi Song, Tianyue Ou, Yibo Kong, Zecheng Li, Graham Neubig, and Xiang Yue. 2025. Visu- alpuzzles: Decoupling multimodal reasoning eval- uation from domain knowledge.arXiv preprint arXiv:2504.10342. Zayne Sprague, Fangcong...
arXiv 2025
-
[5]
DAPO: an open-source LLM reinforcement learning system at scale.CoRR, abs/2503.14476. Xiang Yue, Yuansheng Ni, Tianyu Zheng, Kai Zhang, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, and 3 others. 2024. MMMU: A massive ...
Pith/arXiv arXiv 2024
-
[6]
IEEE. Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Yu Qiao, Peng Gao, and Hongsheng Li. 2024. MATHVERSE: does your multi-modal LLM truly see the diagrams in visual math prob- lems? InComputer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29- October 4, 2024, Proce...
Pith/arXiv arXiv 2024
-
[7]
Pyvision: Agentic vision with dynamic tooling. arXiv preprint arXiv:2507.07998. Ziwei Zheng, Michael Yang, Jack Hong, Chenx- iao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. 2025. Deepeyes: Incentivizing "think- ing with images" via reinforcement learning.CoRR, abs/2505.14362. Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wa...
arXiv 2025
-
[8]
overlapping geographic regions\
/ 3 = 17 / 3 = 5.67\n- Average of 1, 9, and ? = (1 + 9 + ?) / 3 = (10 + ?) /3\n\nSetting the averages equal or finding symmetry might be complexhere. Let's try the previous sum approach again and check for calculation errors or alternative interpretations.\n\nNotice the pattern in oppositetriangles:\n- Add each opposite triangle (6+1, 4+9, 7+?) to see if ...
2025
-
[11]
original correct answer to that question
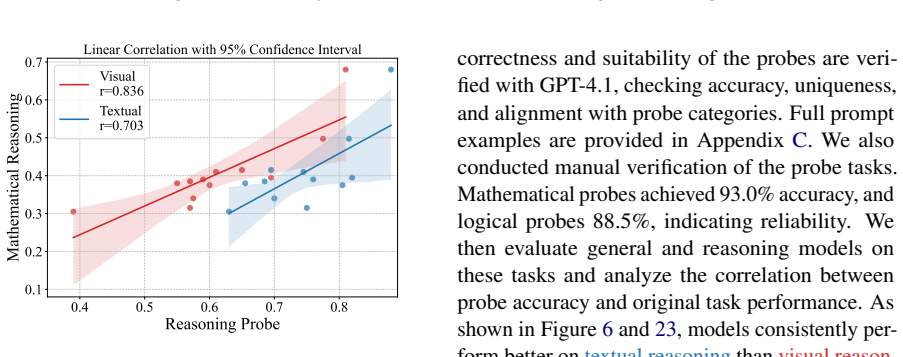
“original correct answer to that question”:{answer} . Your task is to generate 3 “textual probe” sub-questions (and their answers) per example. Each probe must satisfy: a. The probe question ONLY requires text reasoning of the tasks. (No visual information is required, which may be the last step in solving this problem. After visual information extraction...
-
[14]
original correct answer to that question
“original correct answer to that question”:{answer} . Your task is to generate 3 “visual probe” sub-questions (and their answers) per example. Each probe must satisfy: a. The probe question requires genuine perception and reasoning of the image (It CANNOT be answered from the text). b. Relevance as a step: answering the probe is a necessary intermediate s...
-
[21]
If and only if all three conditions are met, output exactly \boxed{Y}
Relevance as a step: answering the probe is a necessary intermediate step toward solving the original question. If and only if all three conditions are met, output exactly \boxed{Y}. Otherwise, output exactly \boxed{N}. Table 17: Prompt for visual reasoning probe judgment. Prompt for Visual Reasoning Probe Judgment You are a Visual Probe Validator for mul...
-
[22]
original image
“original image”: an image{image} (visual context)
-
[23]
original question for the multimodal reasoning task
“original question for the multimodal reasoning task”:{question}
-
[24]
original correct answer to that question
“original correct answer to that question”:{answer}
-
[25]
probe: - probe.question: {probe question} (a single visual-probe sub-question) - probe.answer: {probe answer} (the proposed answer to that probe question) Your job is to check the probe against three criteria:
-
[26]
Correctness & uniqueness: the probe question and answer are factually correct from the image, and the answer is unambiguous
-
[27]
Visual dependency: the probe cannot be answered without analyzing visual content; it genuinely requires perceiving the image
-
[28]
If and only if all three conditions are met, output exactly \boxed{Y}
Relevance as a step: answering the probe is a necessary intermediate step toward solving the original question. If and only if all three conditions are met, output exactly \boxed{Y}. Otherwise, output exactly \boxed{N}. Table 18: Prompt for verbal and visual reflection annotation. Prompt for Verbal and Visual Reflection Annotation You will be given a reas...
-
[29]
Let me double-check the image
**Visual Reflection**: Does the model reflect on its visual perception or interpretation? For example: - Expressing uncertainty, doubt, or re-evaluation of visual input (e.g., “Let me double-check the image” or “Maybe I misinterpreted the object in the picture”) - Actively describing or reassessing visual elements (e.g., “There seems to be a red circle ne...
-
[30]
Wait, my earlier assumption might be wrong
**Reasoning Reflection**: Does the model reflect on its own line of reasoning? For example: - Revising earlier assumptions or identifying logical errors (e.g., “Wait, my earlier assumption might be wrong”) - Evaluating the completeness or validity of its approach (e.g., “This line of reasoning may not be sufficient”) Please provide a boolean value for eac...
-
[31]
To solve the problem, we need to place two more queens
The queens are placed at coordinates: (1,3), (2,5), (3,7), (6,2), (7,8), (8,6), and (9,9). To solve the problem, we need to place two more queens. The rows with queens already are 1, 2, 3, 6, 7, 8, and 9. The missing rows are 4 and 5, so we’ll focus on placing queens there, ensuring no two queens share the same row, column, or diagonal. The only way to co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.