What are Key Factors for Updates in RL for LLM Reasoning?
Pith reviewed 2026-06-26 10:22 UTC · model grok-4.3
The pith
Off-policy degree alters importance sampling ratio distributions and clipping in RLVR, changing which tokens dominate LLM updates and motivating variance-adaptive clipping in ACPO.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
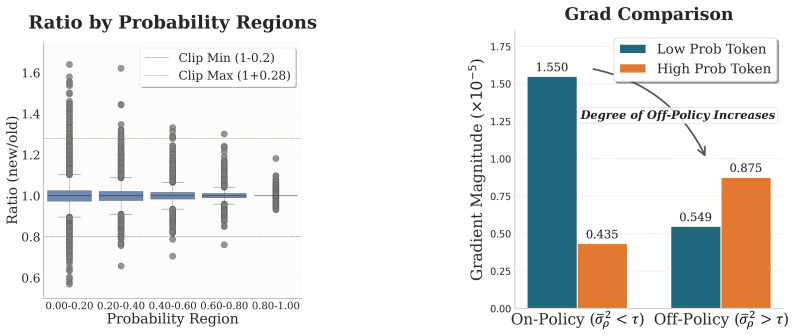
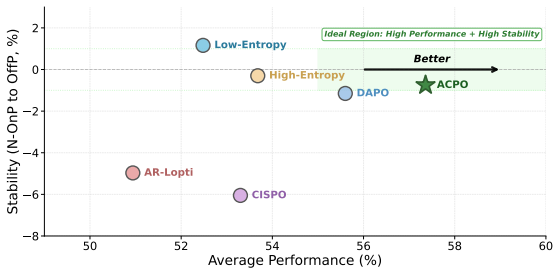
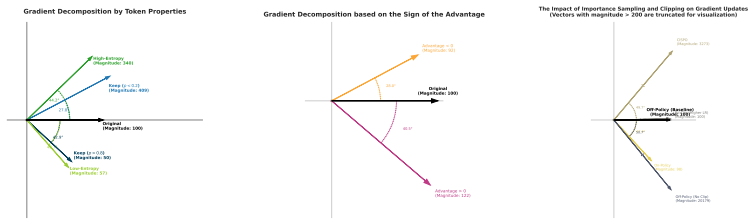
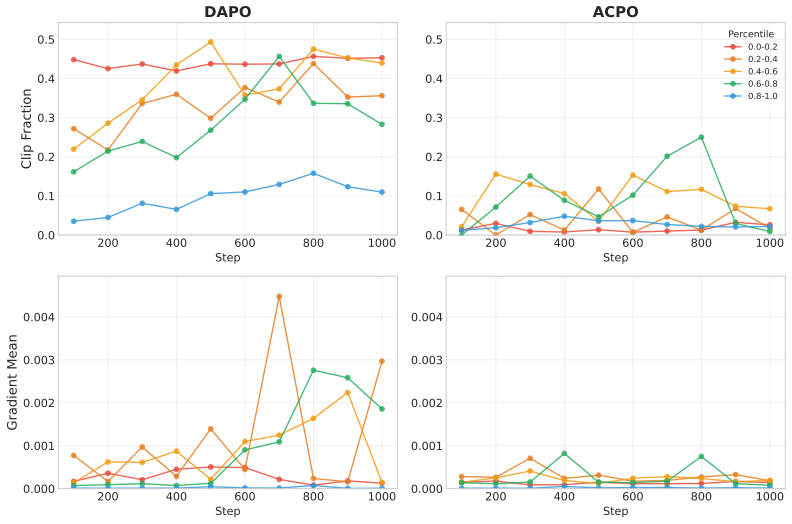
Differences in off-policy degree, determined by the number of gradient steps per rollout, substantially affect the distribution of importance sampling ratios and their clipping behavior, thereby altering which tokens dominate the update. Gradient expectation is the central quantity governing update dynamics. ACPO adjusts clipping boundaries across token groups according to the empirical variance of their importance sampling ratios and outperforms DAPO and CISPO on the tested benchmarks.
What carries the argument
Adaptive Clip Policy Optimization (ACPO), which adjusts clipping boundaries across token groups according to the empirical variance of their importance sampling ratios.
If this is right
- ACPO outperforms strong baselines such as DAPO and CISPO on diverse reasoning benchmarks with 3B and 7B models.
- Token probability, advantage, and importance sampling ratio together determine gradient expectation in RLVR updates.
- Principled analysis of update dynamics yields more robust RLVR methods than heuristic choices.
- The off-policy degree controls clipping behavior and thereby token dominance during training.
Where Pith is reading between the lines
- The variance-based clipping rule could be tested on models larger than 7B to check whether the reported gains persist.
- Similar variance-aware adjustments might be applied to other components of policy optimization beyond clipping.
- The analysis framework could be used to diagnose why certain heuristic RLVR variants succeed or fail on new tasks.
Load-bearing premise
Adjusting clipping boundaries across token groups according to the empirical variance of their importance sampling ratios produces more effective and robust updates than fixed clipping rules.
What would settle it
Reproducing the 3B and 7B experiments and finding that ACPO does not outperform DAPO or CISPO on the mathematical problem solving, tabular QA, and logic puzzle benchmarks would falsify the performance claim.
Figures



read the original abstract
Reinforcement Learning from Verifiable Rewards (RLVR) has emerged as a promising framework for enhancing the reasoning ability of large language models. However, much of the existing work is guided by heuristic intuition, leading to divergent algorithmic choices, even contradictory ones that nevertheless report empirical gains. To better understand this phenomenon, we conduct a theoretical analysis of RLVR updates. Our study reveals that differences in off-policy degree, determined by the number of gradient steps per rollout, substantially affect the distribution of importance sampling ratios and their clipping behavior, thereby altering which tokens dominate the update. Building on this insight, we characterize gradient expectation as the central quantity governing update dynamics and analyze the roles of token probability, advantage, and importance sampling ratio. Motivated by these findings, we propose Adaptive Clip Policy Optimization (ACPO), which adjusts clipping boundaries across token groups according to the empirical variance of their importance sampling ratios. Experiments on 3B and 7B models across diverse reasoning benchmarks, spanning mathematical problem solving, tabular QA, and logic puzzles, demonstrate that ACPO outperforms strong baselines such as DAPO and CISPO. These results demonstrate that principled, analysis-driven approaches yield more robust and effective RLVR methods. Code is available in: https://github.com/Control-derek/ACPO
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a theoretical analysis of RLVR updates for LLM reasoning, revealing that off-policy degree (gradient steps per rollout) alters IS ratio distributions and clipping behavior, changing which tokens dominate updates. It characterizes the expected gradient in terms of token probability, advantage, and IS ratio. Motivated by this, it proposes ACPO, which groups tokens by empirical variance of IS ratios and adjusts clipping boundaries per group. Experiments on 3B/7B models across math, tabular QA, and logic benchmarks show ACPO outperforming DAPO and CISPO. Code is released at the provided GitHub link.
Significance. If the results hold, the work offers insight into off-policy dynamics in RLVR and a practical adaptive clipping method that could improve robustness over fixed rules. The code release is a clear strength supporting reproducibility. The significance is limited by the heuristic mapping from analysis to the specific variance-based rule.
major comments (1)
- [Analysis of gradient expectation and ACPO proposal] The analysis identifies effects of off-policy degree on IS ratio distributions and characterizes E[gradient] via token probability, advantage, and IS ratio, but provides no derivation showing that empirical variance (as opposed to mean, quantiles, or other moments) is the statistic that best mitigates token dominance or optimizes the characterized expectation. The mapping from this analysis to the ACPO grouping and clipping adjustment therefore remains heuristic rather than derived.
minor comments (1)
- [Experiments] Reported results lack error bars, detailed ablation studies on variance grouping choices (e.g., number of groups or thresholds), and full step-by-step derivation of the theoretical claims.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and the identification of the connection between our analysis and the ACPO design. We respond to the major comment below.
read point-by-point responses
-
Referee: [Analysis of gradient expectation and ACPO proposal] The analysis identifies effects of off-policy degree on IS ratio distributions and characterizes E[gradient] via token probability, advantage, and IS ratio, but provides no derivation showing that empirical variance (as opposed to mean, quantiles, or other moments) is the statistic that best mitigates token dominance or optimizes the characterized expectation. The mapping from this analysis to the ACPO grouping and clipping adjustment therefore remains heuristic rather than derived.
Authors: We agree that the link from the gradient characterization to the specific use of empirical variance for token grouping is motivated by the analysis rather than obtained via a formal derivation of optimality. The analysis shows that off-policy degree changes the distribution of importance sampling ratios ρ, which alters clipping behavior and thereby changes which tokens dominate the update through the term involving p · A · ρ in the expected gradient. Variance of ρ within a token group directly measures the spread that causes inconsistent clipping across tokens, providing a natural grouping criterion for adaptive boundaries. While alternatives such as mean or quantiles could be considered, variance aligns with the observed effect on clipping frequency and update dominance in our characterization. We will revise the manuscript to explicitly state that the variance-based rule is a motivated heuristic grounded in the gradient expectation analysis, and to include a brief discussion of this design choice. revision: partial
Circularity Check
Theoretical analysis of IS ratio distributions motivates variance-based clipping heuristic, validated empirically with no reduction to fitted inputs or self-citation chains.
full rationale
The paper conducts an analysis showing how off-policy degree (gradient steps per rollout) affects IS ratio distributions and token dominance under clipping, then characterizes E[gradient] in terms of token probability, advantage, and IS ratio. It proposes ACPO by grouping tokens on empirical variance of IS ratios and adjusting clipping boundaries. No quoted equations or sections demonstrate that the variance statistic or the resulting clipping rule is equivalent to the analysis inputs by construction, nor does any load-bearing premise rely on self-citations. The claimed superiority is established via empirical comparison on held-out benchmarks, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Vapo: Efficient and reliable reinforcement learning for advanced reasoning tasks , author=. arXiv preprint arXiv:2504.05118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[9]
2025 , eprint=
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model , author=. 2025 , eprint=
2025
-
[10]
H i T ab: A Hierarchical Table Dataset for Question Answering and Natural Language Generation
Cheng, Zhoujun and Dong, Haoyu and Wang, Zhiruo and Jia, Ran and Guo, Jiaqi and Gao, Yan and Han, Shi and Lou, Jian-Guang and Zhang, Dongmei. H i T ab: A Hierarchical Table Dataset for Question Answering and Natural Language Generation. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. d...
-
[11]
2025 , note =
Countdown Numbers Game Dataset , author =. 2025 , note =
2025
-
[12]
2024 , journal =
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
2024
-
[13]
2021 , eprint=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. 2021 , eprint=
2021
-
[14]
2024 , eprint=
OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems , author=. 2024 , eprint=
2024
-
[15]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Tülu 3: Pushing Frontiers in Open Language Model Post-Training , author=. arXiv preprint arXiv:2411.15124 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
2025 , month =
Qwen Team , title =. 2025 , month =
2025
-
[19]
arXiv preprint arXiv:2505.16400 , year=
Acereason-nemotron: Advancing math and code reasoning through reinforcement learning , author=. arXiv preprint arXiv:2505.16400 , year=
-
[20]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning , author=. arXiv preprint arXiv:2506.01939 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
arXiv preprint arXiv:2505.12929 , year=
Do Not Let Low-Probability Tokens Over-Dominate in RL for LLMs , author=. arXiv preprint arXiv:2505.12929 , year=
-
[24]
Reasoning with Exploration: An Entropy Perspective
Reasoning with exploration: An entropy perspective , author=. arXiv preprint arXiv:2506.14758 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
The entropy mechanism of reinforcement learning for reasoning language models , author=. arXiv preprint arXiv:2505.22617 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
arXiv preprint arXiv:2505.20282 , year=
One-shot entropy minimization , author=. arXiv preprint arXiv:2505.20282 , year=
-
[27]
Seed-grpo: Semantic entropy enhanced grpo for uncertainty-aware policy optimization , author=. arXiv preprint arXiv:2505.12346 , year=
-
[28]
arXiv preprint arXiv:2505.23564 , year=
Segment policy optimization: Effective segment-level credit assignment in rl for large language models , author=. arXiv preprint arXiv:2505.23564 , year=
-
[29]
arXiv preprint arXiv:2507.07017 , year=
First return, entropy-eliciting explore , author=. arXiv preprint arXiv:2507.07017 , year=
-
[30]
arXiv preprint arXiv:2503.14286 , year=
Tapered off-policy reinforce: Stable and efficient reinforcement learning for llms , author=. arXiv preprint arXiv:2503.14286 , year=
-
[31]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention , author=. arXiv preprint arXiv:2506.13585 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
arXiv preprint arXiv:2508.07629 , year=
Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization , author=. arXiv preprint arXiv:2508.07629 , year=
-
[33]
Stabilizing Knowledge, Promoting Reasoning: Dual-Token Constraints for RLVR
Stabilizing knowledge, promoting reasoning: Dual-token constraints for rlvr , author=. arXiv preprint arXiv:2507.15778 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
arXiv preprint arXiv:2506.01347 , year=
The surprising effectiveness of negative reinforcement in LLM reasoning , author=. arXiv preprint arXiv:2506.01347 , year=
-
[35]
arXiv preprint arXiv:2504.11343 , year=
A minimalist approach to llm reasoning: from rejection sampling to reinforce , author=. arXiv preprint arXiv:2504.11343 , year=
-
[36]
Learning to Reason under Off-Policy Guidance
Learning to reason under off-policy guidance , author=. arXiv preprint arXiv:2504.14945 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
arXiv preprint arXiv:2506.07527 , year=
Learning What Reinforcement Learning Can't: Interleaved Online Fine-Tuning for Hardest Questions , author=. arXiv preprint arXiv:2506.07527 , year=
-
[38]
arXiv preprint arXiv:2506.19767 , year=
SRFT: A Single-Stage Method with Supervised and Reinforcement Fine-Tuning for Reasoning , author=. arXiv preprint arXiv:2506.19767 , year=
- [39]
-
[40]
arXiv preprint arXiv:2508.08221 , year=
Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning , author=. arXiv preprint arXiv:2508.08221 , year=
-
[41]
June , volume=
Minerva: Solving quantitative reasoning problems with language models , author=. June , volume=
-
[42]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[44]
arXiv preprint arXiv:2504.02546 , year=
Gpg: A simple and strong reinforcement learning baseline for model reasoning , author=. arXiv preprint arXiv:2504.02546 , year=
-
[45]
Group Sequence Policy Optimization
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.