OrthoMotion:Disentangling Camera and Subject Motion via Geometry Semantics Orthogonal Attention
Pith reviewed 2026-06-26 09:30 UTC · model grok-4.3
The pith
OrthoMotion routes camera motion to a rotation of rotary embeddings and subject motion to gated cross-attention so a regularizer can force the two response subspaces to orthogonality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
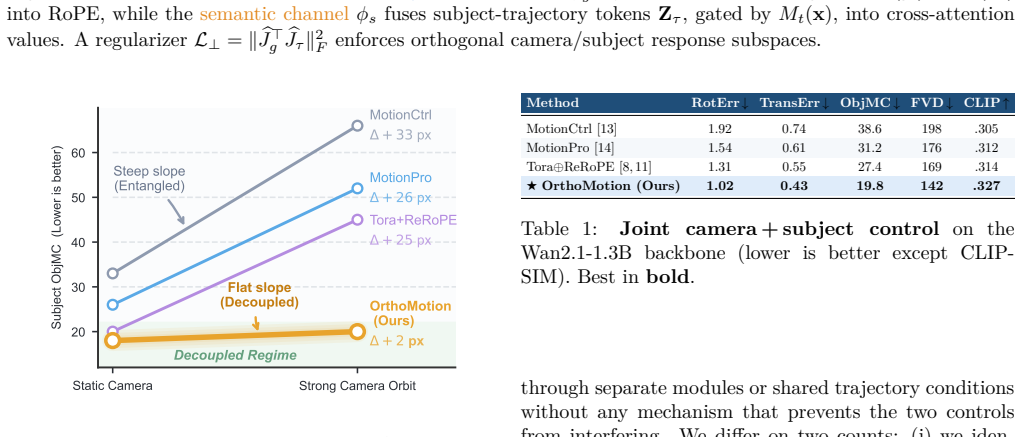
The entanglement of camera-induced and subject-induced motion is representational rather than architectural; the 2D split is a non-identifiable inverse problem. OrthoMotion resolves it by mapping camera motion to a geometric channel consisting of a norm-preserving rotation of the RoPE phase and subject motion to a semantic channel consisting of gated value injection in cross-attention. These sub-operators are complementary, so a lightweight decoupling regularizer provably drives their response subspaces to orthogonality and thereby guarantees disentanglement by construction.
What carries the argument
The OrthoMotion attention operator that splits camera motion into a norm-preserving rotation of rotary position embeddings and subject motion into gated value injection, with a regularizer enforcing orthogonality of the resulting subspaces.
If this is right
- Camera and subject controls reach state-of-the-art accuracy at the same time.
- Cross-talk between the two controls drops by more than 2.4 times on the new Cross-Talk Error metric.
- Disentanglement holds without loss of generation fidelity.
- The separation generalizes across different backbone networks.
Where Pith is reading between the lines
- The same complementary-operator pattern could be applied to separate other entangled factors such as lighting direction from object texture.
- If the orthogonality is stable, the method might support real-time interactive video editing where camera and subject are adjusted independently.
- The Cross-Talk Error metric itself could serve as a diagnostic for any motion-conditioned generator.
Load-bearing premise
That camera and subject motions produce optical flows that share the same inverse-depth scaling yet can still be routed into rotation versus gated translation to create subspaces a regularizer can make orthogonal.
What would settle it
A direct measurement of the inner product between the camera-channel and subject-channel response subspaces remaining above a small threshold after training, or a cross-talk error that does not fall when the regularizer weight is increased.
Figures

read the original abstract
Controllable video generation demands independent command of the camera and the subject, yet 2D conditioning entangles them: camera- and object-induced optical flow share the same inverse-depth (1/Z) scaling and cannot be separated from image evidence alone. We first prove that this entanglement is representational, not architectural -- the 2D camera/object split is a non-identifiable inverse problem -- and therefore reframe decoupling as a question of operator design. We resolve it at the level of the attention operator. OrthoMotion routes camera motion into a geometric channel, a norm-preserving rotation of the rotary position embedding (RoPE) phase, and subject motion into a semantic channel, a gated value injection in cross-attention. Because these sub-operators are algebraically complementary -- a rotation versus a translation of the affine action on tokens -- a lightweight decoupling regularizer provably drives their response subspaces to orthogonality, so the two controls stop interfering. To our knowledge OrthoMotion is the first method to guarantee disentanglement by construction rather than hope for it to emerge. It attains state-of-the-art camera and subject accuracy at once while minimizing cross-talk, which we quantify with a new Cross-Talk Error (CTE) metric, cutting cross-talk by more than 2.4x with no loss in fidelity and generalizing across backbones.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that camera and subject motion entanglement in 2D video conditioning is representational due to shared 1/Z scaling, making it a non-identifiable inverse problem. It proposes OrthoMotion which routes camera motion to RoPE phase rotation and subject motion to gated value injection in cross-attention. These sub-operators are said to be algebraically complementary, allowing a lightweight regularizer to provably enforce orthogonality of response subspaces, guaranteeing disentanglement by construction. The method achieves SOTA accuracy with over 2.4x reduction in a new Cross-Talk Error (CTE) metric without loss in fidelity and generalizes across backbones.
Significance. If the claimed algebraic complementarity and provable orthogonality via the regularizer hold, this would be a notable advance in the field of controllable video generation, providing a principled operator-level solution to motion disentanglement instead of hoping for it to emerge from training. The introduction of the CTE metric for quantifying cross-talk could be useful for the community. The reported performance improvements suggest practical benefits for applications requiring independent control of camera and subject.
major comments (2)
- Abstract: The abstract asserts a proof that the entanglement is representational, that the sub-operators are algebraically complementary, and that the regularizer provably drives orthogonality, yet supplies none of the derivation, equations, or experimental controls; these are load-bearing for the central claim of 'guarantee by construction'.
- Method section on operator design: The assumption that routing camera motion exclusively to norm-preserving RoPE phase rotation while routing subject motion to gated value injection produces algebraically complementary operators (rotation vs. translation of the affine action on tokens) such that a regularizer forces response subspaces to orthogonality must be shown explicitly after accounting for the full attention computation including shared Q/K projections and softmax; without this the complementarity remains unverified.
minor comments (2)
- Title: Missing space: 'OrthoMotion:Disentangling' should read 'OrthoMotion: Disentangling'.
- Abstract: The CTE metric and 2.4x reduction claim would benefit from a brief definition or reference to its computation formula.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the need for clearer presentation of our theoretical claims. We address each major comment below. Where the manuscript requires additional explicit derivations or cross-references, we will revise accordingly.
read point-by-point responses
-
Referee: Abstract: The abstract asserts a proof that the entanglement is representational, that the sub-operators are algebraically complementary, and that the regularizer provably drives orthogonality, yet supplies none of the derivation, equations, or experimental controls; these are load-bearing for the central claim of 'guarantee by construction'.
Authors: The abstract is intentionally concise and therefore omits the full derivations. The representational non-identifiability proof appears in Section 3.1 with the explicit 1/Z scaling argument and inverse-problem formulation. Algebraic complementarity between the RoPE rotation operator and the gated-value translation operator is derived in Section 3.2, and the regularizer's effect on response-subspace orthogonality (including the relevant inner-product bound) is shown in Section 3.3. Experimental controls that isolate the contribution of the regularizer are reported in Section 4.3 and the supplementary material. To improve accessibility we will add a single sentence to the abstract that points readers to these sections and will include a short proof sketch in the introduction. revision: yes
-
Referee: Method section on operator design: The assumption that routing camera motion exclusively to norm-preserving RoPE phase rotation while routing subject motion to gated value injection produces algebraically complementary operators (rotation vs. translation of the affine action on tokens) such that a regularizer forces response subspaces to orthogonality must be shown explicitly after accounting for the full attention computation including shared Q/K projections and softmax; without this the complementarity remains unverified.
Authors: We agree that an explicit end-to-end accounting is required. The current Section 3.2 derives complementarity at the level of the two sub-operators before the shared Q/K projections and softmax. We will revise this section to insert the full forward pass: (i) the effect of the RoPE phase rotation on the query-key dot products, (ii) the additive gated-value term after the value projection, and (iii) the subsequent softmax normalization. We will then show that the cross-term between the two channels remains zero under the regularizer even after these operations, thereby confirming that the subspaces stay orthogonal. This expanded derivation will be placed immediately after the current operator definitions. revision: yes
Circularity Check
No significant circularity; derivation is self-contained architectural design
full rationale
The paper asserts a representational non-identifiability proof for the 2D camera/subject split and then proposes an explicit operator split (RoPE rotation for camera, gated value injection for subject) whose algebraic complementarity is claimed to allow a regularizer to enforce orthogonality. No quoted equations, self-citations, or fitted parameters are shown reducing the 'guarantee by construction' to an input quantity or prior author result. The central claim rests on the design choice and internal proof rather than tautological re-use of outputs as inputs. This is the normal case of an independent method proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Camera- and object-induced optical flow share the same inverse-depth (1/Z) scaling and cannot be separated from image evidence alone.
Reference graph
Works this paper leans on
-
[1]
Robust single image sand removal by leveraging uncertainty-aware sam priors and prompt learning with refined perceptual loss,
B. Wei, H. Liu, C. Qian, Z. Li, W. Wu, and Z. Meng, “Robust single image sand removal by leveraging uncertainty-aware sam priors and prompt learning with refined perceptual loss,” inProceedings of the Backbone CTEbasec→s↓CTEOursc→s↓ObjMC↓FVD↓ Wan2.1-1.3B 24.1 4.6 19.8 142 Wan2.1-14B 22.8 4.1 17.9 121 CogVideoX-2B 25.3 5.2 21.4 151 Table 5:Generator-agnost...
2025
-
[2]
Rusid: Robust uncertainty-aware single image deraining be- yond certainty,
B. Wei, H. Liu, C. Qian, Z. Li, and Z. Meng, “Rusid: Robust uncertainty-aware single image deraining be- yond certainty,”
-
[3]
Synpo: Boosting training-free few-shot medical segmentation via high-quality neg- ative prompts,
Y. Liu, H. Xiao, J. Chai, Y. Zhang, R. Wang, Z. Meng, and Z. Luo, “Synpo: Boosting training-free few-shot medical segmentation via high-quality neg- ative prompts,” inInternational Conference on Med- ical Image Computing and Computer-Assisted Inter- vention, pp. 594–603, Springer, 2025
2025
-
[4]
Orpaint: a zero- shot inpainting model for oracle bone inscription rubbings with visual mamba block,
Z. Meng, Y. Zeng, X. Chang, T. Xu, F. Chao, X. Cao, C. Shang, and Q. Shen, “Orpaint: a zero- shot inpainting model for oracle bone inscription rubbings with visual mamba block,”Science China Information Sciences, vol. 68, no. 8, p. 189102, 2025
2025
-
[5]
Make a game: A novel paradigm for interactive game ren- dering,
Z. Meng, J. Che, B. Wei, and X. Cao, “Make a game: A novel paradigm for interactive game ren- dering,” inICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pp. 1026–1030, IEEE, 2026
2026
-
[6]
Argus: Stacked multi-view identity mosaic injection for subject-preserving video generation,
Z. Meng, J. Liu, Y. Liu, C. Tong, X. Liu, Y. Zhang, Y. Xu, and P. Wan, “Argus: Stacked multi-view identity mosaic injection for subject-preserving video generation,”arXiv preprint arXiv:2606.11670, 2026
Pith/arXiv arXiv 2026
-
[7]
CameraCtrl: Enabling camera control forvideogeneration,
H. He, Y. Xu, Y. Guo, G. Wetzstein, B. Dai, H. Li, and C. Yang, “CameraCtrl: Enabling camera control forvideogeneration,” inInternational Conference on Learning Representations (ICLR), 2025
2025
-
[8]
Rerope: Repurposing rope for relative camera control,
C. Li, Y. Yang, J. Shao, H. Zhou, K. Schwarz, and Y. Liao, “Rerope: Repurposing rope for relative camera control,”arXiv preprint arXiv:2602.08068, 2026. 5
arXiv 2026
-
[9]
Cameras as relative positional en- coding,
R. Li, B. Yi, J. Liu, H. Gao, Y. Ma, and A. Kanazawa, “Cameras as relative positional en- coding,”Advances in Neural Information Processing Systems, vol. 38, pp. 15984–16009, 2026
2026
-
[10]
Dragnuwa: Fine-grained control in video generation by integrating text, image, and tra- jectory,
S. Yin, C. Wu, J. Liang, J. Shi, H. Li, G. Ming, and N. Duan, “Dragnuwa: Fine-grained control in video generation by integrating text, image, and tra- jectory,”arXiv preprint arXiv:2308.08089, 2023
Pith/arXiv arXiv 2023
-
[11]
Tora: Trajectory-oriented diffusion transformer for video generation,
Z. Zhang, J. Liao, M. Li, Z. Dai, B. Qiu, S. Zhu, L. Qin, and W. Wang, “Tora: Trajectory-oriented diffusion transformer for video generation,” inPro- ceedings of the Computer Vision and Pattern Recog- nition Conference, pp. 2063–2073, 2025
2063
-
[12]
Trident: Breaking the hybrid-safety- physics coupling for provably safe multi-agent rein- forcement learning,
Z. Meng, Z. Li, Y. Liu, Z. Li, J. Liu, W. Nie, B. Wei, and M. Zhang, “Trident: Breaking the hybrid-safety- physics coupling for provably safe multi-agent rein- forcement learning,” 2026
2026
-
[13]
Motionctrl: A unified and flexible motion controller for video generation,
Z. Wang, Z. Yuan, X. Wang, Y. Li, T. Chen, M. Xia, P. Luo, and Y. Shan, “Motionctrl: A unified and flexible motion controller for video generation,” in ACM SIGGRAPH 2024 Conference Papers, pp. 1– 11, 2024
2024
-
[14]
Motionpro: A precise motion controller for image-to-video generation,
Z. Zhang, F. Long, Z. Qiu, Y. Pan, W. Liu, T. Yao, and T. Mei, “Motionpro: A precise motion controller for image-to-video generation,” inProceedings of the Computer Vision and Pattern Recognition Confer- ence, pp. 27957–27967, 2025
2025
-
[15]
Wan: Open and advanced large-scale video gen- erative models,
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.- W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang,et al., “Wan: Open and advanced large-scale video gen- erative models,”arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[16]
Parascale: Scale-calibrated camera- motion transfer via a gauge-invariant parallax num- ber,
Z. Meng, “Parascale: Scale-calibrated camera- motion transfer via a gauge-invariant parallax num- ber,” 2026
2026
-
[17]
Camer- aCtrl II: Dynamic scene exploration via camera- controlled video diffusion models,
H. He, C. Yang, S. Lin, Y. Xu,et al., “Camer- aCtrl II: Dynamic scene exploration via camera- controlled video diffusion models,”arXiv preprint arXiv:2503.10592, 2025
arXiv 2025
-
[18]
Cine- master: A 3d-aware and controllable framework for cinematic text-to-video generation,
Q. Wang, Y. Luo, X. Shi, X. Jia, H. Lu, T. Xue, X. Wang, P. Wan, D. Zhang, and K. Gai, “Cine- master: A 3d-aware and controllable framework for cinematic text-to-video generation,” inProceedings of the Special Interest Group on Computer Graph- ics and Interactive Techniques Conference Confer- ence Papers, pp. 1–10, 2025
2025
-
[19]
Motionmaster: Training-free camera motion transfer for video generation,
T.Hu, J.Zhang, R.Yi, Y.Wang, H.Huang, J.Weng, Y. Wang, and L. Ma, “Motionmaster: Training-free camera motion transfer for video generation,”arXiv preprint arXiv:2404.15789, 2024
arXiv 2024
-
[20]
Nvs-solver: Video diffusion model as zero-shot novel view syn- thesizer,
M. You, Z. Zhu, H. Liu, and J. Hou, “Nvs-solver: Video diffusion model as zero-shot novel view syn- thesizer,”arXiv preprint arXiv:2405.15364, 2024
arXiv 2024
-
[21]
Omni- director: General multi-shot camera cloning without cross-paireddata,
J. Liu, S. Li, Z. Fang, X. Li, Y. Zhou, Z. Meng, Z.Zhang, Y.Luo, G.Zhang, Y.-S.Liu,et al., “Omni- director: General multi-shot camera cloning without cross-paireddata,”arXiv preprint arXiv:2606.13432, 2026
Pith/arXiv arXiv 2026
-
[22]
Hartley and A
R. Hartley and A. Zisserman,Multiple View Ge- ometry in Computer Vision. Cambridge University Press, 2nd ed., 2004
2004
-
[23]
Scalable diffusion mod- els with transformers,
W. Peebles and S. Xie, “Scalable diffusion mod- els with transformers,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 4195–4205, 2023
2023
-
[24]
Roformer: Enhanced transformer with rotary position embedding,
J. Su, Y. Lu, S. Pan, A. Murtadha, B. Wen, and Y. Liu, “Roformer: Enhanced transformer with rotary position embedding,”arXiv preprint arXiv:2104.09864, 2021
Pith/arXiv arXiv 2021
-
[25]
Video- composer: Compositional video synthesis with mo- tioncontrollability,
X. Wang, H. Yuan, S. Zhang, D. Chen, J. Wang, Y. Zhang, Y. Shen, D. Zhao, and J. Zhou, “Video- composer: Compositional video synthesis with mo- tioncontrollability,”Advances in Neural Information Processing Systems, vol. 36, pp. 7594–7611, 2023
2023
-
[26]
Magicmotion: Controllable video generation with dense-to-sparse trajectory guidance,
Q. Li, Z. Xing, R. Wang, H. Zhang, Q. Dai, and Z. Wu, “Magicmotion: Controllable video generation with dense-to-sparse trajectory guidance,”arXiv preprint arXiv:2503.16421, 2025
arXiv 2025
-
[27]
To- kenflow: Consistent diffusion features for consistent video editing,
M. Geyer, O. Bar-Tal, S. Bagon, and T. Dekel, “To- kenflow: Consistent diffusion features for consistent video editing,”arXiv preprint arXiv:2307.10373, 2023
Pith/arXiv arXiv 2023
-
[28]
Dive: Dit-based video generation with enhanced control,
J. Jiang, G. Hong, L. Zhou, E. Ma, H. Hu, X. Zhou, J. Xiang, F. Liu, K. Yu, H. Sun,et al., “Dive: Dit-based video generation with enhanced control,” arXiv preprint arXiv:2409.01595, 2024
arXiv 2024
-
[29]
Flowmatchingforgenerativemodeling,
Y. Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, andM.Le, “Flowmatchingforgenerativemodeling,” inInternational Conference on Learning Representa- tions (ICLR), 2023
2023
-
[30]
Towards accurate generative models of video: A new met- ric & challenges,
T. Unterthiner, S. van Steenkiste, K. Kurach, R. Marinier, M. Michalski, and S. Gelly, “Towards accurate generative models of video: A new met- ric & challenges,”arXiv preprint arXiv:1812.01717, 2018
Pith/arXiv arXiv 2018
-
[31]
Learning transferable visual models from natural language su- pervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G.Goh, S.Agarwal, G.Sastry, A.Askell, P.Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language su- pervision,” inInternational Conference on Machine Learning (ICML), pp. 8748–8763, 2021. 6
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.