AudioCALM: Continuous Autoregressive Language Modeling for Universal Audio Generation
Pith reviewed 2026-06-26 07:22 UTC · model grok-4.3
The pith
A single autoregressive model generates speech, sound, and music at state-of-the-art levels by predicting continuous audio latents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AudioCALM shows that continuous autoregressive language modeling, with a thin flow-matching head replacing the softmax to predict rectified-flow velocities and block-causal AR-Flow attention for arbitrary-length output, unifies the three tasks when paired with description-style conditioning reformulation and the Asymmetric Mixture-of-Modality-Experts (A-MoME) design that adds a dedicated speech expert while incurring no extra cost on non-speech inputs. This combination matches modality-specific state-of-the-art results and beats prior unified baselines on speech, sound, and music benchmarks.
What carries the argument
The Asymmetric Mixture-of-Modality-Experts (A-MoME) architecture together with data reformulation to a shared description-style conditioning interface, which together address the asymmetric text-audio mismatch while the flow-matching head on continuous latents replaces discrete token prediction.
If this is right
- One model can now replace three separate systems while matching their individual performance on speech, sound, and music tasks.
- Arbitrary-length audio can be synthesized end-to-end without modality-specific changes to the generation loop.
- Joint training across modalities succeeds once the conditioning asymmetry is handled at both data and architecture levels.
- Prior unified baselines are outperformed, showing the continuous-latent approach plus targeted experts is sufficient.
Where Pith is reading between the lines
- The speech-specific expert suggests that unified models for other sequential modalities may still need some dedicated capacity even after data unification.
- The same continuous AR plus flow-matching pattern could be tested on other time-series data such as video frames or sensor streams.
- Further ablation could check whether the speech expert can be removed if conditioning reformulation is made more aggressive.
Load-bearing premise
The data reformulation to description-style conditioning plus the addition of a speech-specific residual expert resolves the attention mismatch between modalities without creating new degradation on any of them.
What would settle it
If the unified AudioCALM model scores clearly below the best published speech-only, sound-only, or music-only systems on any of the standard benchmarks for that modality, the unification claim would be falsified.
Figures

read the original abstract
Unifying speech, sound, and music generation in one model is hindered by tradeoffs between fidelity, end-to-end training, in-context conditioning, and variable-length synthesis that no current paradigm fully resolves. To address this challenge, we present AudioCALM, a universal audio generation framework that extends autoregressive (AR) next-token prediction from discrete tokens to continuous audio latents: a thin flow-matching head replaces the softmax to predict rectified-flow velocities at each position, and a block-causal AR-Flow attention pattern produces arbitrary-length output. Joint training of multiple audio generation tasks faces an asymmetric text--audio mismatch: speech transcripts align to specific time spans and demand tight, time-aligned attention, whereas sound and music captions describe only overall semantics and rely on diffuse, holistic attention; mixing the two disproportionately degrades sound and music generation. We address this asymmetry at two levels: a data reformulation strategy that unifies all three tasks under a single description-style conditioning interface, and a novel architecture Asymmetric Mixture-of-Modality-Experts (A-MoME), which adds a dedicated residual expert for speech while sound and music share the backbone, incurring no inference overhead on non-speech inputs. Experimental results demonstrate that AudioCALM matches modality-specific state-of-the-art and outperforms prior unified baselines on speech, sound, and music generation benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AudioCALM, a universal audio generation framework extending autoregressive next-token prediction to continuous audio latents via a thin flow-matching head that predicts rectified-flow velocities and a block-causal AR-Flow attention pattern for arbitrary-length output. It identifies an asymmetric text-audio mismatch when jointly training speech (time-aligned transcripts), sound, and music (holistic captions) tasks, and addresses it via a data reformulation strategy unifying all tasks under description-style conditioning plus an Asymmetric Mixture-of-Modality-Experts (A-MoME) architecture that adds a dedicated residual expert for speech while sharing the backbone for sound/music. The central claim is that this yields performance matching modality-specific SOTAs and outperforming prior unified baselines on speech, sound, and music benchmarks.
Significance. If the experimental claims hold with appropriate controls and ablations, the work would be significant for unifying audio generation modalities in a single end-to-end AR model without the usual fidelity-conditioning-length tradeoffs, by demonstrating that targeted data reformulation and modality-asymmetric experts can resolve the text-audio asymmetry without new degradation modes.
major comments (1)
- [Abstract] Abstract: The central claim that 'Experimental results demonstrate that AudioCALM matches modality-specific state-of-the-art and outperforms prior unified baselines on speech, sound, and music generation benchmarks' is stated without any quantitative results, error bars, dataset details, ablation evidence, or implementation specifics. This makes it impossible to verify support for the claim or assess whether the data reformulation and A-MoME introduce degradation modes on any modality.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address the concern regarding the abstract below and will revise the manuscript to improve verifiability of the central claim while preserving the high-level nature of the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'Experimental results demonstrate that AudioCALM matches modality-specific state-of-the-art and outperforms prior unified baselines on speech, sound, and music generation benchmarks' is stated without any quantitative results, error bars, dataset details, ablation evidence, or implementation specifics. This makes it impossible to verify support for the claim or assess whether the data reformulation and A-MoME introduce degradation modes on any modality.
Authors: We agree that the abstract, as currently written, presents the performance claim at a high level without supporting numbers or references to specific tables/sections. The full manuscript contains the requested details (quantitative results with comparisons to modality-specific SOTAs and unified baselines, dataset information, and ablations on data reformulation and A-MoME in the experimental sections). However, to directly address the referee's point and allow readers to assess potential degradation modes from the abstract alone, we will revise the abstract to incorporate key quantitative highlights from the main results (e.g., specific benchmark scores) while keeping it concise. This revision will be made in the next version. revision: yes
Circularity Check
No circularity detected; empirical model description contains no derivation chain or self-referential reductions
full rationale
The manuscript presents an architectural framework (continuous AR modeling with flow-matching head and A-MoME) justified by addressing text-audio asymmetry via data reformulation and expert specialization. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. Central performance claims rest on external experimental benchmarks rather than any internal reduction to inputs by construction. This is the expected non-finding for an empirical systems paper without visible mathematical self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ming-omni: A unified multimodal model for perception and generation.arXiv preprint arXiv:2506.09344,
Inclusion AI, Biao Gong, Cheng Zou, Chuanyang Zheng, Chunluan Zhou, Canxiang Yan, Chunxiang Jin, Chunjie Shen, Dandan Zheng, Fudong Wang, et al. Ming-omni: A unified multimodal model for perception and generation.arXiv preprint arXiv:2506.09344,
-
[2]
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Philip Anastassiou, Jiawei Chen, Jitong Chen, Yuanzhe Chen, Zhuo Chen, Ziyi Chen, Jian Cong, Lelai Deng, Chuang Ding, Lu Gao, et al. Seed-tts: A family of high-quality versatile speech generation models.arXiv preprint arXiv:2406.02430,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
The mtg-jamendo dataset for automatic music tagging
Dmitry Bogdanov, Minz Won, Philip Tovstogan, Alastair Porter, and Xavier Serra. The mtg-jamendo dataset for automatic music tagging. InMachine learning for music discovery workshop, international conference on machine learning (ICML 2019), pages 1–3. Long Beach, CA, United States,
2019
-
[4]
Vggsound: A large-scale audio-visual dataset
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zisserman. Vggsound: A large-scale audio-visual dataset. InICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 721–725. IEEE,
2020
-
[5]
FMA: A Dataset For Music Analysis
Michaël Defferrard, Kirell Benzi, Pierre Vandergheynst, and Xavier Bresson. Fma: A dataset for music analysis. arXiv preprint arXiv:1612.01840,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
High Fidelity Neural Audio Compression
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High fidelity neural audio compression. arXiv preprint arXiv:2210.13438,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foundation model for real-time dialogue.arXiv preprint arXiv:2410.00037,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Ding Ding, Zeqian Ju, Yichong Leng, Songxiang Liu, Tong Liu, Zeyu Shang, Kai Shen, Wei Song, Xu Tan, Heyi Tang, et al. Kimi-audio technical report.arXiv preprint arXiv:2504.18425,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, et al. Cosyvoice 2: Scalable streaming speech synthesis with large language models.arXiv preprint arXiv:2412.10117,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
Zhihao Du, Changfeng Gao, Yuxuan Wang, Fan Yu, Tianyu Zhao, Hao Wang, Xiang Lv, Hui Wang, Chongjia Ni, Xian Shi, et al. Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training. arXiv preprint arXiv:2505.17589,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Stable audio open
Zach Evans, Julian D Parker, CJ Carr, Zack Zukowski, Josiah Taylor, and Jordi Pons. Stable audio open. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE,
2025
-
[12]
Chia-Yu Hung, Navonil Majumder, Zhifeng Kong, Ambuj Mehrish, Amir Ali Bagherzadeh, Chuan Li, Rafael Valle, Bryan Catanzaro, and Soujanya Poria. Tangoflux: Super fast and faithful text to audio generation with flow matching and clap-ranked preference optimization.arXiv preprint arXiv:2412.21037,
-
[13]
Dongya Jia, Zhuo Chen, Jiawei Chen, Chenpeng Du, Jian Wu, Jian Cong, Xiaobin Zhuang, Chumin Li, Zhen Wei, Yuping Wang, et al. Ditar: Diffusion transformer autoregressive modeling for speech generation.arXiv preprint arXiv:2502.03930,
-
[14]
Zeqian Ju, Yuancheng Wang, Kai Shen, Xu Tan, Detai Xin, Dongchao Yang, Yanqing Liu, Yichong Leng, Kaitao Song, Siliang Tang, et al. Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models.arXiv preprint arXiv:2403.03100,
-
[15]
Fr\'echet Audio Distance: A Metric for Evaluating Music Enhancement Algorithms
Kevin Kilgour, Mauricio Zuluaga, Dominik Roblek, and Matthew Sharifi. Fréchet audio distance: A metric for evaluating music enhancement algorithms.arXiv preprint arXiv:1812.08466,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Audiocaps: Generating captions for audios in the wild
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. Audiocaps: Generating captions for audios in the wild. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 119–132,
2019
-
[17]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Audiogen: Textually guided audio generation.arXiv preprint arXiv:2209.15352,
Felix Kreuk, Gabriel Synnaeve, Adam Polyak, Uriel Singer, Alexandre Défossez, Jade Copet, Devi Parikh, Yaniv Taigman, and Yossi Adi. Audiogen: Textually guided audio generation.arXiv preprint arXiv:2209.15352,
-
[19]
Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models
Weixin Liang, Lili Yu, Liang Luo, Srinivasan Iyer, Ning Dong, Chunting Zhou, Gargi Ghosh, Mike Lewis, Wen-tau Yih, Luke Zettlemoyer, et al. Mixture-of-transformers: A sparse and scalable architecture for multi-modal foundation models.arXiv preprint arXiv:2411.04996,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Audioldm 2: Learning holistic audio generation with self-supervised pretraining
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, and Mark D Plumbley. Audioldm 2: Learning holistic audio generation with self-supervised pretraining. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 32:2871–2883, 2024a. Huadai Liu, Rongjie Huang, Xuan Lin, Wenqiang Xu, Maozong Zheng...
-
[21]
Huadai Liu, Rongjie Huang, Yang Liu, Hengyuan Cao, Jialei Wang, Xize Cheng, Siqi Zheng, and Zhou Zhao. Audiolcm: Text-to-audio generation with latent consistency models.arXiv preprint arXiv:2406.00356, 2024b. Huadai Liu, Jialei Wang, Rongjie Huang, Yang Liu, Heng Lu, Zhou Zhao, and Wei Xue. Flashaudio: Rectified flows for fast and high-fidelity text-to-au...
-
[22]
Zhenyu Liu, Yunxin Li, Xuanyu Zhang, Qixun Teng, Shenyuan Jiang, Xinyu Chen, Haoyuan Shi, Jinchao Li, Qi Wang, Haolan Chen, et al. Unimoe-audio: Unified speech and music generation with dynamic-capacity moe.arXiv preprint arXiv:2510.13344, 2025d. Ilaria Manco, Benno Weck, Seungheon Doh, Minz Won, Yixiao Zhang, Dmitry Bogdanov, Yusong Wu, Ke Chen, Philip T...
-
[23]
Matcha-tts: A fast tts architecture with conditional flow matching
Shivam Mehta, Ruibo Tu, Jonas Beskow, Éva Székely, and Gustav Eje Henter. Matcha-tts: A fast tts architecture with conditional flow matching. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 11341–11345. IEEE,
2024
-
[24]
AudioPaLM: A Large Language Model That Can Speak and Listen
Paul K Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chau- mont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, et al. Audiopalm: A large language model that can speak and listen.arXiv preprint arXiv:2306.12925,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Fun-audio-chat technical report.arXiv preprint arXiv:2512.20156,
Tongyi Fun Team, Qian Chen, Luyao Cheng, Chong Deng, Xiangang Li, Jiaqing Liu, Chao-Hong Tan, Wen Wang, Junhao Xu, Jieping Ye, et al. Fun-audio-chat technical report.arXiv preprint arXiv:2512.20156,
-
[26]
Audiobox: Unified audio generation with natural language prompts.arXiv preprint arXiv:2312.15821,
Apoorv Vyas, Bowen Shi, Matthew Le, Andros Tjandra, Yi-Chiao Wu, Baishan Guo, Jiemin Zhang, Xinyue Zhang, Robert Adkins, William Ngan, et al. Audiobox: Unified audio generation with natural language prompts.arXiv preprint arXiv:2312.15821,
-
[27]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv:2301.02111, 2023a. Wenhui Wang, Hangbo Bao, Li Dong, Johan Bjorck, Zhiliang Peng, Qiang Liu, Kriti Aggarwal, Owais Khan Mohammed, Saksha...
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE,
2023
-
[29]
12 Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report.arXiv preprint arXiv:2503.20215, 2025a. Xuenan Xu, Jiahao Mei, Zihao Zheng, Ye Tao, Zeyu Xie, Yaoyun Zhang, Haohe Liu, Yuning Wu, Ming Yan, Wen Wu, et al. Uniflo...
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Uniaudio: An audio foundation model toward universal audio generation
Dongchao Yang, Jinchuan Tian, Xu Tan, Rongjie Huang, Songxiang Liu, Xuankai Chang, Jiatong Shi, Sheng Zhao, Jiang Bian, Xixin Wu, et al. Uniaudio: An audio foundation model toward universal audio generation. arXiv preprint arXiv:2310.00704,
-
[31]
LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech
Heiga Zen, Viet Dang, Rob Clark, Yu Zhang, Ron J Weiss, Ye Jia, Zhifeng Chen, and Yonghui Wu. Libritts: A corpus derived from librispeech for text-to-speech.arXiv preprint arXiv:1904.02882,
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[32]
Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities
Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 15757–15773,
2023
-
[33]
Mimo-audio: Audio language models are few-shot learners.arXiv preprint arXiv:2512.23808,
Dong Zhang, Gang Wang, Jinlong Xue, Kai Fang, Liang Zhao, Rui Ma, Shuhuai Ren, Shuo Liu, Tao Guo, Weiji Zhuang, et al. Mimo-audio: Audio language models are few-shot learners.arXiv preprint arXiv:2512.23808,
-
[34]
This is
13 A Additional Implementation Details A.1 Continuous Audio V AE Architecture.Our autoencoder is a CNN–GAN of the STABLEAUDIOOPEN[Evans et al., 2025]/DAC [Kumar et al., 2023] family with three deviations: (i) an iSTFT synthesis head re- places the time-domain transposed-convolution stack at the decoder output, (ii) self-attention layers are inserted at th...
2025
-
[35]
rating the perceived quality of computer- generated audio
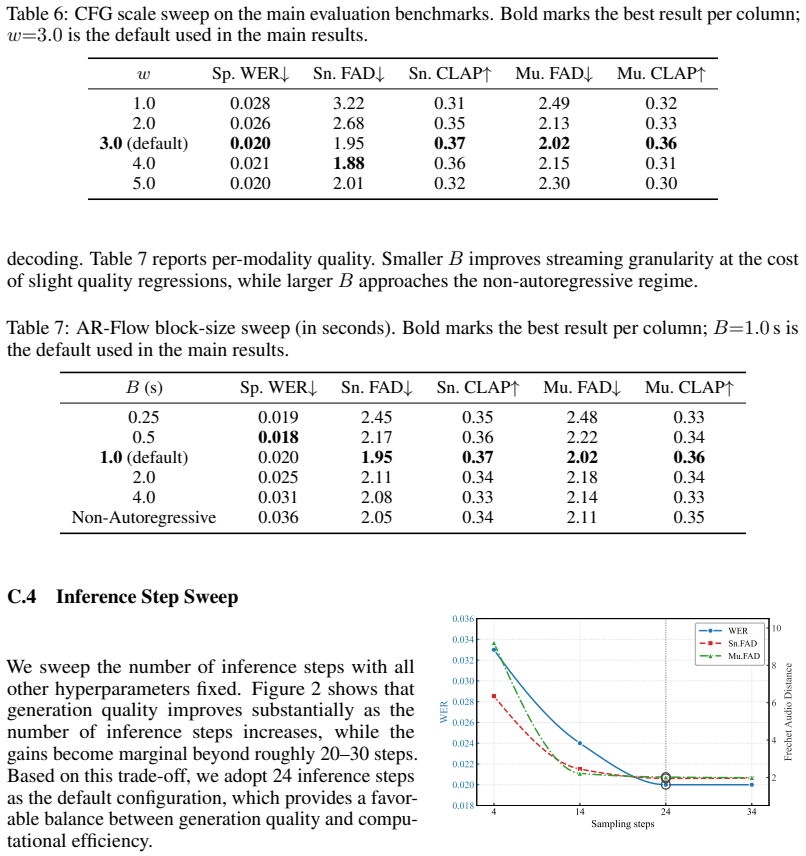
The appendix sweeps (Tables 5–7) differ only along the swept axis. All values were fixed before any evaluation on held-out splits: optimizer settings follow the Qwen3 pretraining recipe, the rectified-flow schedule and CFG dropout follow [Esser et al., 2024, Liu et al., 2022], and the AR-Flow block size, exposure-bias scale, and clean-prefix noise scale w...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.