3DCarGen: Scalable 3D Car Generation via 3D-consistent Multi-view Synthesis
Pith reviewed 2026-06-30 09:59 UTC · model grok-4.3
The pith
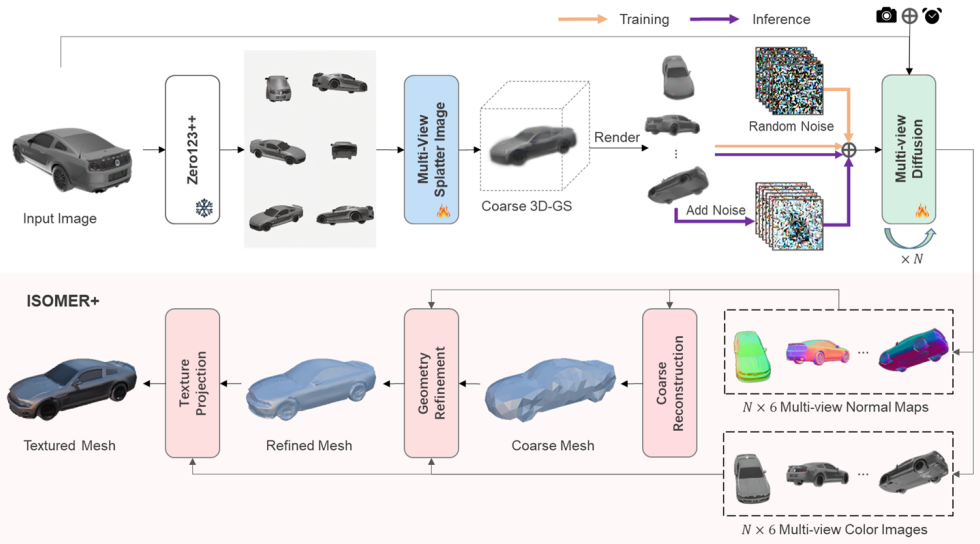
A single car photo is converted into arbitrarily many geometrically consistent multi-view images by conditioning a diffusion model on a coarse 3D Gaussian Splatting reconstruction from fixed viewpoints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given a single image as input, 3DCarGen first synthesizes a set of images from fixed viewpoints, reconstructs a coarse 3D representation based on 3D Gaussian Splatting, conditions a multi-view diffusion model on this explicit 3D prior to generate 3D-consistent images from arbitrary camera viewpoints, and extends a fast mesh reconstruction algorithm by incorporating color-normal joint optimization to recover detailed and coherent 3D vehicle models.
What carries the argument
Coarse 3D Gaussian Splatting prior obtained from fixed-viewpoint images that conditions the subsequent multi-view diffusion model to enforce geometric consistency across arbitrary generated views.
If this is right
- An arbitrary number of viewpoints can be synthesized while preserving 3D geometric consistency.
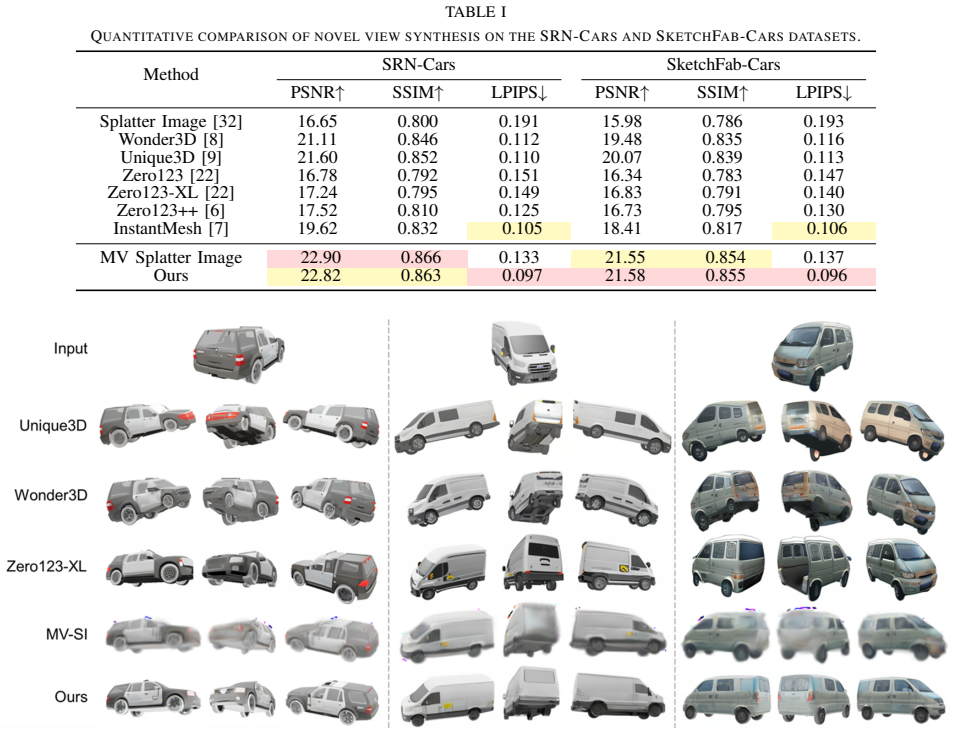
- Reconstruction fidelity improves for real-world car images that previously suffered from cross-view inconsistencies.
- The resulting dense consistent views support higher-quality mesh recovery via joint color-normal optimization.
- The pipeline directly supplies 3D vehicle assets usable in autonomous-driving simulation environments.
Where Pith is reading between the lines
- The same fixed-view-plus-prior pattern could be tested on other rigid object categories if the initial viewpoint synthesis step generalizes.
- Stronger consistency mechanisms might eventually allow skipping the explicit Gaussian Splatting stage altogether.
- Performance on images containing heavy occlusion or unusual lighting would test how robust the coarse prior remains.
Load-bearing premise
The fixed-viewpoint images synthesized in the first stage are accurate enough that the resulting Gaussian Splatting model supplies a usable coarse 3D prior for the diffusion stage.
What would settle it
A controlled ablation in which the Gaussian Splatting prior is removed or replaced by a weaker signal and the multi-view diffusion outputs remain equally consistent, or quantitative reconstruction metrics on real-world test images show no improvement over baseline single-image methods.
Figures






read the original abstract
High-quality 3D vehicle assets are essential for autonomous driving simulation. Although multi-view diffusion-based paradigms enable controllable single-image reconstruction, they typically produce limited viewpoints and exhibit cross-view geometric inconsistencies, thereby reducing reconstruction fidelity in real-world scenarios. In this work, we introduce 3DCarGen, a scalable single-view 3D car generation framework designed for real-world images by synthesizing an arbitrary number of 3D-consistent multi-view images. Specifically, given a single image as input, we first synthesize a set of images from fixed viewpoints. These images are then fed into a feed-forward reconstruction model, resulting in a coarse 3D representation based on 3D Gaussian Splatting. Conditioned on this explicit 3D prior, our multi-view diffusion model generates 3D-consistent images from arbitrary camera viewpoints. We further extend a fast mesh reconstruction algorithm by incorporating color-normal joint optimization to recover detailed and coherent 3D vehicle models from the synthesized dense views. Extensive experiments on synthetic and real-world datasets demonstrate that our approach achieves robust geometric consistency and reconstruction fidelity compared to existing methods. Project page: https://honglixiao.github.io/3dcargen.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 3DCarGen, a scalable single-view 3D car generation framework. Given a single real-world image, it first synthesizes images from fixed viewpoints, feeds these into a feed-forward reconstruction model to obtain a coarse 3D Gaussian Splatting prior, conditions a multi-view diffusion model on this explicit prior to generate 3D-consistent images from arbitrary viewpoints, and finally applies an extended fast mesh reconstruction algorithm with color-normal joint optimization to recover detailed 3D vehicle models. Experiments on synthetic and real-world datasets are claimed to demonstrate robust geometric consistency and reconstruction fidelity relative to existing methods.
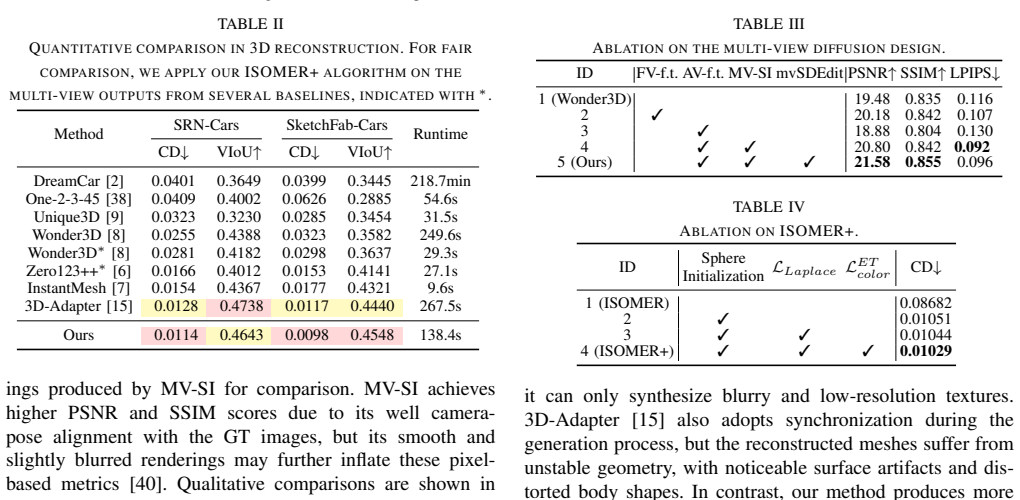
Significance. If the claims hold, the work addresses a practical limitation in multi-view diffusion approaches for 3D asset creation in autonomous driving simulation by enabling arbitrary numbers of consistent views from single inputs. The pipeline is internally coherent with no evident circularity in the construction; the central claim requires only that the coarse prior be usable rather than perfect, which aligns with the described experimental regime.
minor comments (3)
- [Abstract] Abstract: the assertion of superior consistency and fidelity would be strengthened by including one or two key quantitative metrics (e.g., consistency error or reconstruction PSNR) rather than relying solely on qualitative description.
- [Method] Section 3 (Method): the conditioning mechanism by which the 3D Gaussian Splatting prior is injected into the multi-view diffusion model is described at a high level; a diagram or explicit formulation of the conditioning would improve reproducibility.
- [Experiments] Experiments: while comparisons to existing methods are mentioned, the manuscript would benefit from an explicit ablation isolating the contribution of the coarse 3D prior versus the diffusion stage alone.
Simulated Author's Rebuttal
We thank the referee for the positive summary of 3DCarGen and the recommendation of minor revision. No major comments appear in the report, so we have no points requiring rebuttal or revision.
Circularity Check
No significant circularity detected
full rationale
The paper presents a sequential pipeline (single-image fixed-view synthesis → feed-forward 3DGS coarse prior → conditioned multi-view diffusion for arbitrary views → joint-optimized mesh reconstruction) with no equations, fitted parameters, or claims that reduce by construction to the target output. The central claim requires only that the coarse prior be usable for conditioning, not that it already encodes the final consistency result. No self-citation chains, uniqueness theorems, or ansatzes are invoked in a load-bearing way that would force the result; the derivation remains self-contained against external benchmarks on synthetic and real-world car images.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Car-studio: Learning car radiance fields from single-view and unlimited in-the-wild images,
T. Liu, H. Zhao, Y . Yu, G. Zhou, and M. Liu, “Car-studio: Learning car radiance fields from single-view and unlimited in-the-wild images,” IEEE Robotics and Automation Letters, 2024
2024
-
[2]
Dreamcar: Leveraging car-specific prior for in-the-wild 3d car reconstruction,
X. Du, H. Sun, M. Lu, T. Zhu, and X. Yu, “Dreamcar: Leveraging car-specific prior for in-the-wild 3d car reconstruction,”IEEE Robotics and Automation Letters, 2024
2024
-
[3]
Drive-1-to-3: Enriching diffusion priors for novel view synthesis of real vehicles,
C. Lin, B. Zhuang, S. Sun, Z. Jiang, J. Cai, and M. Chandraker, “Drive-1-to-3: Enriching diffusion priors for novel view synthesis of real vehicles,”arXiv preprint arXiv:2412.14494, 2024
-
[4]
X. Chen, J. Zheng, H. Huang, H. Xu, W. Gu, K. Chen, H.-a. Gao, H. Zhao, G. Zhou, Y . Zhanget al., “Rgm: Reconstructing high-fidelity 3d car assets with relightable 3d-gs generative model from a single image,”arXiv preprint arXiv:2410.08181, 2024
-
[5]
Cadsim: Robust and scalable in-the-wild 3d reconstruction for controllable sensor simulation,
J. Wang, S. Manivasagam, Y . Chen, Z. Yang, I. A. B ˆarsan, A. J. Yang, W.-C. Ma, and R. Urtasun, “Cadsim: Robust and scalable in-the-wild 3d reconstruction for controllable sensor simulation,”arXiv preprint arXiv:2311.01447, 2023
-
[6]
Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model
R. Shi, H. Chen, Z. Zhang, M. Liu, C. Xu, X. Wei, L. Chen, C. Zeng, and H. Su, “Zero123++: a single image to consistent multi-view diffusion base model,”arXiv preprint arXiv:2310.15110, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
J. Xu, W. Cheng, Y . Gao, X. Wang, S. Gao, and Y . Shan, “Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models,”arXiv preprint arXiv:2404.07191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Wonder3d: Single image to 3d using cross-domain diffusion,
X. Long, Y .-C. Guo, C. Lin, Y . Liu, Z. Dou, L. Liu, Y . Ma, S.-H. Zhang, M. Habermann, C. Theobaltet al., “Wonder3d: Single image to 3d using cross-domain diffusion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9970–9980
2024
-
[9]
Unique3d: High-quality and efficient 3d mesh generation from a single image,
K. Wu, F. Liu, Z. Cai, R. Yan, H. Wang, Y . Hu, Y . Duan, and K. Ma, “Unique3d: High-quality and efficient 3d mesh generation from a single image,”arXiv preprint arXiv:2405.20343, 2024
-
[10]
Dreamfusion: Text- to-3d using 2d diffusion,
B. Poole, A. Jain, J. T. Barron, and B. Mildenhall, “Dreamfusion: Text- to-3d using 2d diffusion,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[11]
Magic3d: High-resolution text- to-3d content creation,
C.-H. Lin, J. Gao, L. Tang, T. Takikawa, X. Zeng, X. Huang, K. Kreis, S. Fidler, M.-Y . Liu, and T.-Y . Lin, “Magic3d: High-resolution text- to-3d content creation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 300–309
2023
-
[12]
Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation,
R. Chen, Y . Chen, N. Jiao, and K. Jia, “Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 22 246–22 256
2023
-
[13]
Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation,
Z. Wang, C. Lu, Y . Wang, F. Bao, C. Li, H. Su, and J. Zhu, “Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation,”Advances in Neural Information Pro- cessing Systems, vol. 36, 2024
2024
-
[14]
MVDream: Multi-view Diffusion for 3D Generation
Y . Shi, P. Wang, J. Ye, L. Mai, K. Li, and X. Yang, “Mvdream: Multi- view diffusion for 3d generation,”arXiv:2308.16512, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
3d-adapter: Geometry-consistent multi-view diffusion for high-quality 3d generation,
H. Chen, B. Shen, Y . Liu, R. Shi, L. Zhou, C. Z. Lin, J. Gu, H. Su, G. Wetzstein, and L. Guibas, “3d-adapter: Geometry-consistent multi-view diffusion for high-quality 3d generation,”arXiv preprint arXiv:2410.18974, 2024
-
[16]
Reconfusion: 3d reconstruction with diffusion priors,
R. Wu, B. Mildenhall, P. Henzler, K. Park, R. Gao, D. Watson, P. P. Srinivasan, D. Verbin, J. T. Barron, B. Pooleet al., “Reconfusion: 3d reconstruction with diffusion priors,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 21 551–21 561
2024
-
[17]
Sdedit: Guided image synthesis and editing with stochastic differen- tial equations,
C. Meng, Y . He, Y . Song, J. Song, J. Wu, J.-Y . Zhu, and S. Ermon, “Sdedit: Guided image synthesis and editing with stochastic differen- tial equations,” inInternational Conference on Learning Representa- tions
-
[18]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[19]
Objaverse: A universe of annotated 3d objects,
M. Deitke, D. Schwenk, J. Salvador, L. Weihs, O. Michel, E. Vander- Bilt, L. Schmidt, K. Ehsani, A. Kembhavi, and A. Farhadi, “Objaverse: A universe of annotated 3d objects,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 13 142–13 153
2023
-
[20]
Objaverse-xl: A universe of 10m+ 3d objects,
M. Deitke, R. Liu, M. Wallingford, H. Ngo, O. Michel, A. Kusupati, A. Fan, C. Laforte, V . V oleti, S. Y . Gadreet al., “Objaverse-xl: A universe of 10m+ 3d objects,”Advances in Neural Information Processing Systems, vol. 36, pp. 35 799–35 813, 2023
2023
-
[21]
Magic123: One image to high-quality 3d object generation using both 2d and 3d diffusion priors,
G. Qian, J. Mai, A. Hamdi, J. Ren, A. Siarohin, B. Li, H.-Y . Lee, I. Skorokhodov, P. Wonka, S. Tulyakovet al., “Magic123: One image to high-quality 3d object generation using both 2d and 3d diffusion priors,” inThe Twelfth International Conference on Learning Representations
-
[22]
Zero-1-to-3: Zero-shot one image to 3d object,
R. Liu, R. Wu, B. Van Hoorick, P. Tokmakov, S. Zakharov, and C. V ondrick, “Zero-1-to-3: Zero-shot one image to 3d object,” in Proceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 9298–9309
2023
-
[23]
Imagedream: Image-prompt multi-view diffusion for 3d generation,
P. Wang and Y . Shi, “Imagedream: Image-prompt multi-view diffusion for 3d generation,”arXiv preprint arXiv:2312.02201, 2023
-
[24]
Multi-view mesh reconstruction with neural deferred shading,
M. Worchel, R. Diaz, W. Hu, O. Schreer, I. Feldmann, and P. Eisert, “Multi-view mesh reconstruction with neural deferred shading,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 6187–6197
2022
-
[25]
Continuous remeshing for inverse rendering,
W. Palfinger, “Continuous remeshing for inverse rendering,”Computer Animation and Virtual Worlds, vol. 33, no. 5, p. e2101, 2022
2022
-
[26]
M-lrm: Multi-view large reconstruction model,
M. Li, X. Long, Y . Liang, W. Li, Y . Liu, P. Li, X. Chi, X. Qi, W. Xue, W. Luoet al., “M-lrm: Multi-view large reconstruction model,”arXiv preprint arXiv:2406.07648, 2024
-
[27]
Lgm: Large multi-view gaussian model for high-resolution 3d content creation,
J. Tang, Z. Chen, X. Chen, T. Wang, G. Zeng, and Z. Liu, “Lgm: Large multi-view gaussian model for high-resolution 3d content creation,” in European Conference on Computer Vision. Springer, 2024, pp. 1–18
2024
-
[28]
Generative novel view synthesis with 3d-aware diffusion models,
E. R. Chan, K. Nagano, M. A. Chan, A. W. Bergman, J. J. Park, A. Levy, M. Aittala, S. De Mello, T. Karras, and G. Wetzstein, “Generative novel view synthesis with 3d-aware diffusion models,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4217–4229
2023
-
[29]
Gina-3d: Learning to generate implicit neural assets in the wild,
B. Shen, X. Yan, C. R. Qi, M. Najibi, B. Deng, L. Guibas, Y . Zhou, and D. Anguelov, “Gina-3d: Learning to generate implicit neural assets in the wild,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 4913–4926
2023
-
[30]
Free3d: Consistent novel view synthesis without 3d representation,
C. Zheng and A. Vedaldi, “Free3d: Consistent novel view synthesis without 3d representation,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2024, pp. 9720– 9731
2024
-
[31]
3dgs-enhancer: Enhancing un- bounded 3d gaussian splatting with view-consistent 2d diffusion priors,
X. Liu, C. Zhou, and S. Huang, “3dgs-enhancer: Enhancing un- bounded 3d gaussian splatting with view-consistent 2d diffusion priors,”Advances in Neural Information Processing Systems, vol. 37, pp. 133 305–133 327, 2024
2024
-
[32]
Splatter image: Ultra-fast single-view 3d reconstruction,
S. Szymanowicz, C. Rupprecht, and A. Vedaldi, “Splatter image: Ultra-fast single-view 3d reconstruction,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 10 208–10 217
2024
-
[33]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[34]
Real-esrgan: Training real- world blind super-resolution with pure synthetic data,
X. Wang, L. Xie, C. Dong, and Y . Shan, “Real-esrgan: Training real- world blind super-resolution with pure synthetic data,” inInternational Conference on Computer Vision Workshops (ICCVW)
-
[35]
Multi-view mesh reconstruction with neural deferred shading,
M. Worchel, R. Diaz, W. Hu, O. Schreer, I. Feldmann, and P. Eisert, “Multi-view mesh reconstruction with neural deferred shading,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 6187–6197
2022
-
[36]
Scene representation networks: Continuous 3d-structure-aware neural scene representa- tions,
V . Sitzmann, M. Zollh ¨ofer, and G. Wetzstein, “Scene representation networks: Continuous 3d-structure-aware neural scene representa- tions,”Advances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[37]
3drealcar: An in-the-wild rgb-d car dataset with 360-degree views,
X. Du, H. Sun, S. Wang, Z. Wu, H. Sheng, J. Ying, M. Lu, T. Zhu, K. Zhan, and X. Yu, “3drealcar: An in-the-wild rgb-d car dataset with 360-degree views,”arXiv preprint arXiv:2406.04875, 2024
-
[38]
One-2-3-45: Any single image to 3d mesh in 45 seconds without per-shape optimization,
M. Liu, C. Xu, H. Jin, L. Chen, M. Varma T, Z. Xu, and H. Su, “One-2-3-45: Any single image to 3d mesh in 45 seconds without per-shape optimization,”Advances in Neural Information Processing Systems, vol. 36, pp. 22 226–22 246, 2023
2023
-
[39]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,”IEEE transactions on image processing, vol. 13, no. 4, pp. 600–612, 2004
2004
-
[40]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
2018
-
[41]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,”arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.