Graph-Based Phonetic Error Correction of Noisy ASR
Pith reviewed 2026-07-01 08:38 UTC · model grok-4.3
The pith
Phonetic graph neighborhoods restrict the search space for correcting ASR errors before contextual re-ranking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
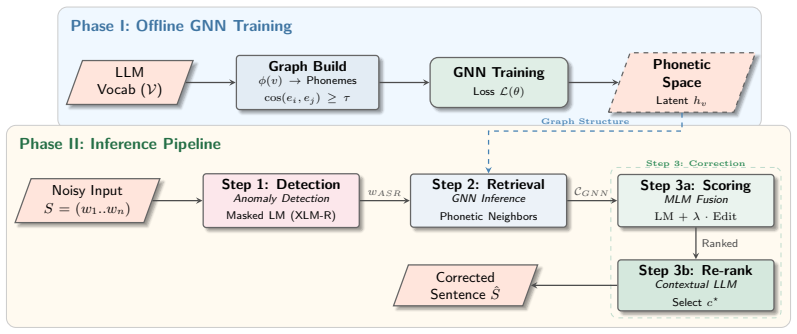
G-SPIN constructs acoustically plausible candidate neighborhoods for flagged tokens using a graph neural network that restricts the correction search space to phonetic alternatives, then applies a masked language model for local contextual scoring and an instruction-tuned large language model for final context-aware re-ranking over this compact candidate set.
What carries the argument
The G-SPIN framework that decouples structured phonetic reasoning via graph neural networks from contextual semantic selection via language models.
If this is right
- The method operates entirely at inference time without retraining the ASR system.
- Correction accuracy improves for semantically critical tokens such as named entities, negations, and sentiment-bearing words.
- The search space remains compact, avoiding the risks of unconstrained generation.
- The framework is modular and lightweight.
Where Pith is reading between the lines
- Similar graph-based restriction could apply to other sequence correction tasks like machine translation post-editing.
- Integrating the phonetic graph construction directly into the ASR decoder might further reduce error rates.
- Testing on languages with different phonetic structures could reveal the method's generality.
Load-bearing premise
Residual ASR errors are predominantly structured phonetic confusions rather than random or semantic errors.
What would settle it
A dataset of ASR errors where a large fraction of correct tokens lie outside the phonetic graph neighbors generated by the GNN would show the approach misses many fixes.
Figures

read the original abstract
Automatic speech recognition (ASR) systems, despite low overall word error rates, produce residual lexical errors that disproportionately affect semantically critical tokens such as named entities, negations, and sentiment-bearing words. These errors are often structured, arising from phonetic similarity rather than random noise, making naive token-level correction insufficient. We propose a structured ASR correction framework, that we call G-SPIN, that combines phonetic graph modeling with contextual language understanding. A graph neural network (GNN) first constructs acoustically plausible candidate neighborhoods for flagged tokens, explicitly restricting the correction search space to phonetic alternatives. A masked language model (MLM) then provides local contextual scoring, and an instruction-tuned large language model (LLM) performs final context-aware re-ranking over this compact candidate set. By decoupling structured phonetic reasoning from contextual semantic selection, our method avoids unconstrained generation while improving correction accuracy. The framework is lightweight, modular, and operates entirely at inference time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes G-SPIN, a structured ASR correction framework that uses a GNN to construct acoustically plausible phonetic candidate neighborhoods for flagged erroneous tokens, an MLM for local contextual scoring, and an instruction-tuned LLM for final context-aware re-ranking over the compact candidate set. The central claim is that decoupling phonetic reasoning from semantic selection avoids unconstrained generation while improving correction accuracy on semantically critical tokens such as named entities.
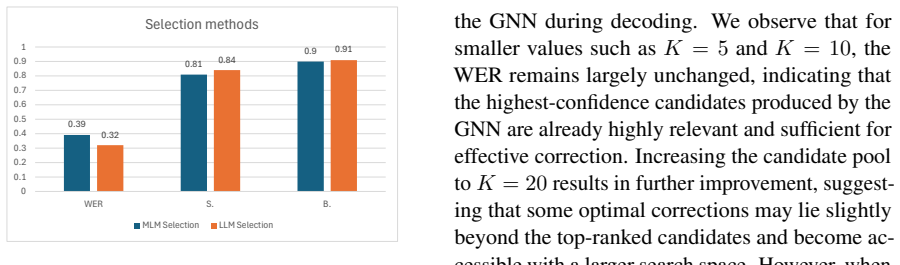
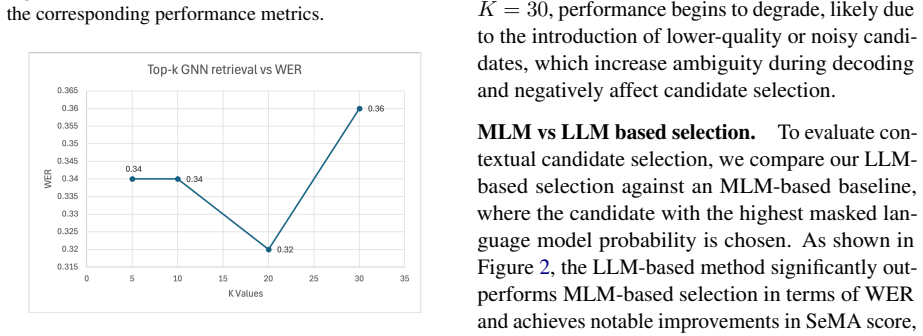
Significance. If the phonetic-graph restriction reliably includes ground-truth corrections and the staged pipeline outperforms baselines, the modular, inference-only design could offer an efficient alternative to full LLM generation for handling structured phonetic ASR errors. The emphasis on restricting search space to phonetic alternatives is a potentially useful contribution, but the complete absence of any empirical results, coverage analysis, or comparisons prevents any assessment of whether these benefits materialize.
major comments (2)
- [Abstract] Abstract: the central claim that the method 'improves correction accuracy' and 'avoids unconstrained generation' rests on the untested assertion that GNN-constructed phonetic neighborhoods contain the ground-truth token for flagged errors. No graph-coverage metric (e.g., recall of the correct token), error analysis, or experimental results are supplied to support this, rendering the claim unverifiable.
- [Abstract] Abstract: the motivating assumption that 'residual ASR errors are often structured, arising from phonetic similarity rather than random noise' is stated without supporting data or justification. This assumption is load-bearing because the entire framework (GNN neighborhood construction + subsequent stages) is predicated on it; if many errors fall outside phonetic neighborhoods, the restriction cannot improve accuracy.
minor comments (1)
- The provided manuscript text consists solely of the abstract; no sections, equations, tables, experimental setup, or results appear, which prevents evaluation of implementation details or reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We agree that the abstract claims require empirical support and will revise the manuscript to include the requested analyses and results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method 'improves correction accuracy' and 'avoids unconstrained generation' rests on the untested assertion that GNN-constructed phonetic neighborhoods contain the ground-truth token for flagged errors. No graph-coverage metric (e.g., recall of the correct token), error analysis, or experimental results are supplied to support this, rendering the claim unverifiable.
Authors: We acknowledge that the manuscript as submitted contains no experimental results, coverage metrics, or error analysis. The revised version will add a full experimental section reporting graph-coverage statistics (recall of ground-truth tokens within GNN neighborhoods), an error analysis of ASR outputs, and quantitative comparisons against baselines to substantiate the claims. revision: yes
-
Referee: [Abstract] Abstract: the motivating assumption that 'residual ASR errors are often structured, arising from phonetic similarity rather than random noise' is stated without supporting data or justification. This assumption is load-bearing because the entire framework (GNN neighborhood construction + subsequent stages) is predicated on it; if many errors fall outside phonetic neighborhoods, the restriction cannot improve accuracy.
Authors: The assumption draws from well-documented patterns in the ASR literature, but we agree it requires explicit support in the paper. The revision will add relevant citations to prior ASR error analyses and, where feasible, supporting statistics drawn from standard benchmarks to justify the phonetic-neighborhood design. revision: yes
Circularity Check
No circularity: modular composition of existing components with no self-referential derivations or fitted predictions
full rationale
The abstract and description present G-SPIN as an inference-time composition of a GNN for candidate neighborhoods, an MLM for local scoring, and an LLM for re-ranking. No equations appear, no parameters are fitted to data subsets and then called predictions, and no self-citations or uniqueness theorems are invoked to justify core choices. The claim of decoupling phonetic reasoning from semantic selection is a stated architectural decision rather than a result derived from inputs that reduce to those inputs by construction. The method is self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Graph-Assisted Culturally Adaptable Idiomatic Translation for I ndic languages
Singh, Pratik Rakesh and Prasad, Kritarth and Zaki, Mohammadi and Wasnik, Pankaj. Graph-Assisted Culturally Adaptable Idiomatic Translation for I ndic languages. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.367
-
[9]
doi:10.21437/Interspeech.2020-2844 , issn =
Weitong Ruan and Yaroslav Nechaev and Luoxin Chen and Chengwei Su and Imre Kiss , year =. doi:10.21437/Interspeech.2020-2844 , issn =
-
[10]
2020 , eprint=
Learning ASR-Robust Contextualized Embeddings for Spoken Language Understanding , author=. 2020 , eprint=
2020
-
[11]
G. Bouselmi and D. Fohr and I. Illina and Jean-Paul Haton , year =. doi:10.21437/Interspeech.2006-28 , issn =
-
[12]
Integrated Semantic and Phonetic Post-correction for C hinese Speech Recognition
Chen, Yi-Chang and Cheng, Chun-Yen and Chen, Chien-An and Sung, Ming-Chieh and Yeh, Yi-Ren. Integrated Semantic and Phonetic Post-correction for C hinese Speech Recognition. Proceedings of the 33rd Conference on Computational Linguistics and Speech Processing (ROCLING 2021). 2021
2021
-
[13]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
DANCER: Entity description augmented named entity corrector for automatic speech recognition , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[14]
Speech Errors on Frequently Observed Homophones in F rench: Perceptual Evaluation vs Automatic Classification
Nemoto, Rena and Vasilescu, Ioana and Adda-Decker, Martine. Speech Errors on Frequently Observed Homophones in F rench: Perceptual Evaluation vs Automatic Classification. Proceedings of the Sixth International Conference on Language Resources and Evaluation ( LREC '08). 2008
2008
-
[15]
2025 , eprint=
Fewer Hallucinations, More Verification: A Three-Stage LLM-Based Framework for ASR Error Correction , author=. 2025 , eprint=
2025
-
[16]
2025 , eprint=
DoCIA: An Online Document-Level Context Incorporation Agent for Speech Translation , author=. 2025 , eprint=
2025
-
[17]
2025 , eprint=
ASR Error Correction using Large Language Models , author=. 2025 , eprint=
2025
-
[18]
2020 , eprint=
WER we are and WER we think we are , author=. 2020 , eprint=
2020
-
[19]
2023 , eprint=
SoftCorrect: Error Correction with Soft Detection for Automatic Speech Recognition , author=. 2023 , eprint=
2023
-
[20]
Fewer Hallucinations, More Verification: A Three-Stage LLM-Based Framework for ASR Error Correction,
Fewer hallucinations, more verification: A three-stage llm-based framework for asr error correction , author=. arXiv preprint arXiv:2505.24347 , year=
-
[21]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[22]
2020 , eprint=
Unsupervised Cross-lingual Representation Learning at Scale , author=. 2020 , eprint=
2020
-
[23]
Inductive Representation Learning on Large Graphs , url =
Hamilton, Will and Ying, Zhitao and Leskovec, Jure , booktitle =. Inductive Representation Learning on Large Graphs , url =
-
[24]
2025 , eprint=
Loquacious Set: 25,000 Hours of Transcribed and Diverse English Speech Recognition Data for Research and Commercial Use , author=. 2025 , eprint=
2025
-
[25]
ArXiv , year=
Seamless: Multilingual Expressive and Streaming Speech Translation , author=. ArXiv , year=
-
[26]
Sasindran, Zitha and Yelchuri, Harsha and Prabhakar, T. V. , year=. SeMaScore: A new evaluation metric for automatic speech recognition tasks , url=. doi:10.21437/interspeech.2024-2033 , booktitle=
-
[27]
2020 , eprint=
BERTScore: Evaluating Text Generation with BERT , author=. 2020 , eprint=
2020
-
[28]
Interspeech , year=
Multilingual non-native speech recognition using phonetic confusion-based acoustic model modification and graphemic constraints , author=. Interspeech , year=
-
[29]
Proceedings of Interspeech 2020 , pages =
Ruan, Wei and Nechaev, Yuriy and Chen, Lin and Su, Chang and Kiss, Istvan , title =. Proceedings of Interspeech 2020 , pages =. 2020 , doi =
2020
-
[30]
ArXiv , year=
SeMaScore : a new evaluation metric for automatic speech recognition tasks , author=. ArXiv , year=
-
[31]
and Ying, Rex and Leskovec, Jure , title =
Hamilton, William L. and Ying, Rex and Leskovec, Jure , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.