The Hitchhiker's Guide to Agentic AI: From Foundations to Systems
Pith reviewed 2026-06-26 08:08 UTC · model grok-4.3
The pith
Effective agentic AI systems require understanding every layer of the development pipeline from model foundations to multi-agent coordination.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that building great agentic systems requires understanding every layer of the pipeline, not just one. The book treats the LLM substrate, alignment and reasoning layers, agentic training and retrieval methods, memory and harness design, inter-agent communication protocols, and production frameworks as interdependent components that must be addressed together for effective autonomous AI.
What carries the argument
The full pipeline architecture spanning LLM foundations, alignment techniques, agent design patterns, and A2A coordination protocols.
If this is right
- Agentic training using trajectory-based RL becomes necessary alongside standard fine-tuning for advanced capabilities.
- Retrieval-augmented generation must be extended to Agentic RAG to handle dynamic agent needs.
- Multi-agent architectures benefit from standardized protocols like MCP and A2A for reliable coordination.
- Evaluation methodologies need to assess full agent trajectories and interactions rather than isolated outputs.
- Production deployment requires attention to context management and UI design integrated with the core model.
Where Pith is reading between the lines
- Developers might benefit from modular training programs that cover the stack sequentially rather than in silos.
- This synthesis could accelerate the shift from single-model applications to orchestrated agent teams in industry.
- Future work might test whether omitting any single layer leads to measurable drops in agent reliability.
- The guide's structure implies that rapid field changes will require ongoing updates to maintain relevance.
Load-bearing premise
A single comprehensive synthesis of techniques from disparate AI subfields can be created and remain useful despite their fast pace of change.
What would settle it
A controlled comparison where teams build agents using only partial pipeline knowledge versus the full integrated guide, measuring differences in task success rates and robustness.
Figures
































































read the original abstract
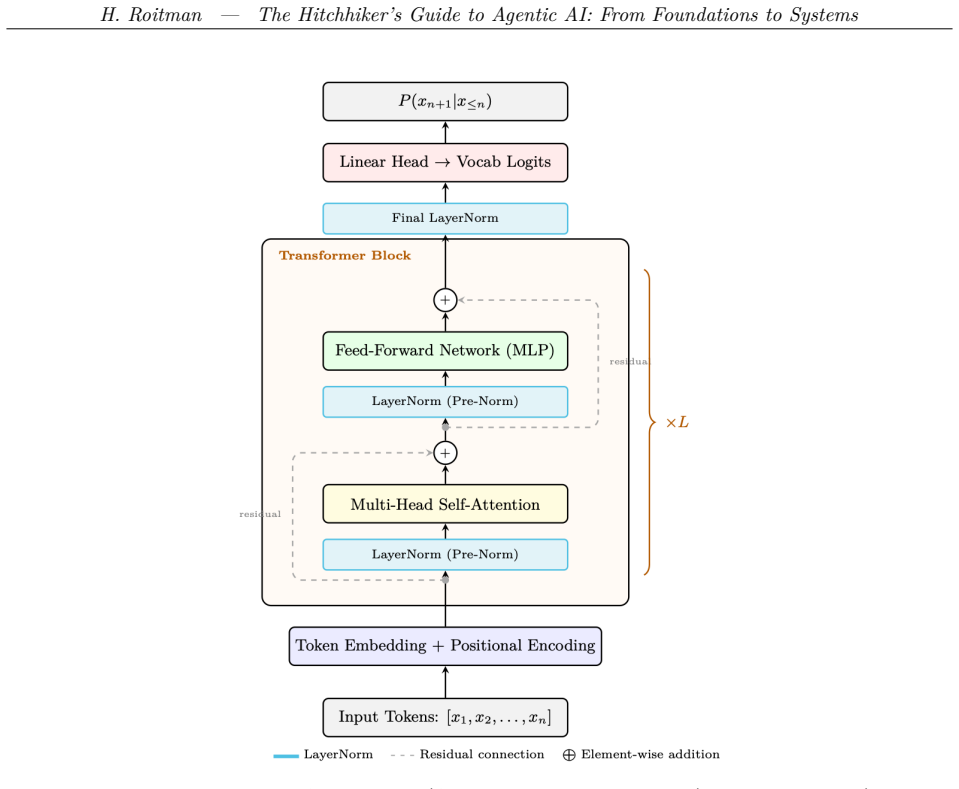
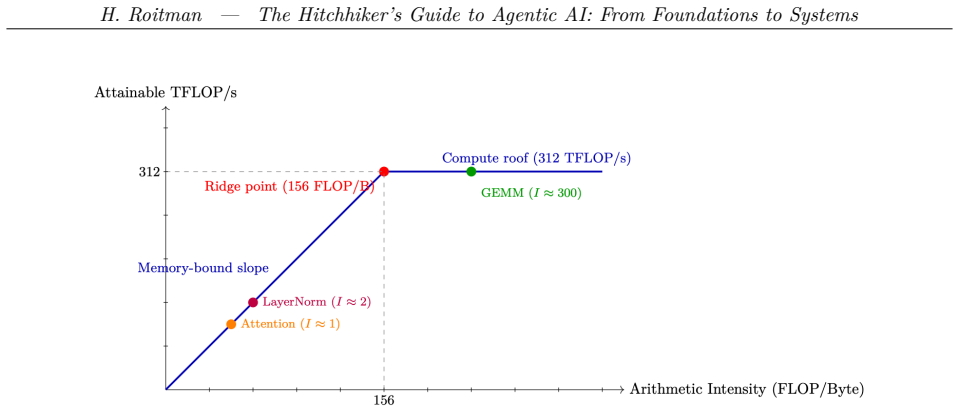
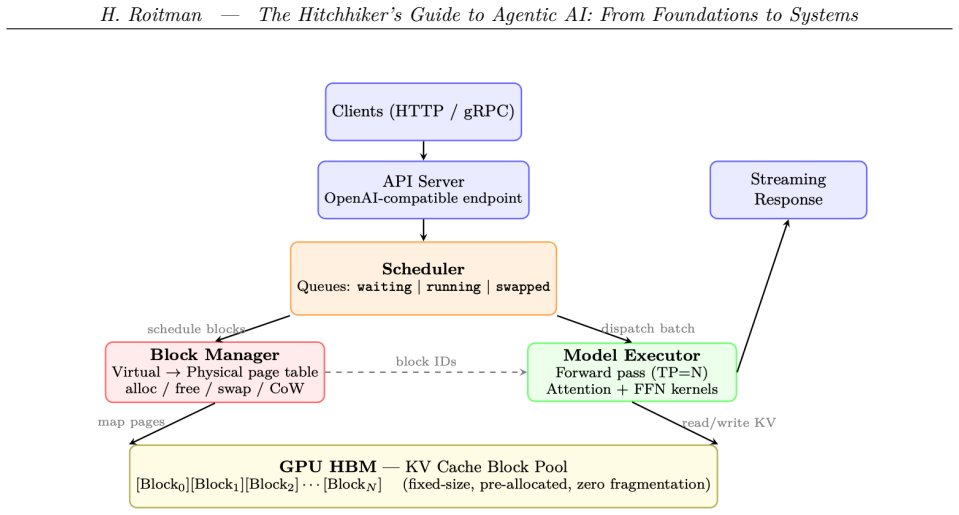
The Hitchhiker's Guide to Agentic AI is a comprehensive practitioner's reference for building autonomous AI systems. The book covers the full stack from first principles to production deployment, organized around a central thesis: building great agentic systems requires understanding every layer of the pipeline, not just one. The book opens with the LLM substrate -- transformer architecture, GPU systems, training and fine-tuning (SFT,LoRA, MoE), model compression, and inference optimization -- treated as essential foundations rather than the primary focus. It then develops the alignment and reasoning layer: reinforcement learning from human feedback (RLHF), PPO, DPO and its variants, GRPO, reward modeling, and RL for large reasoning models including chain-of-thought and test-time scaling. The second half is devoted to agentic AI proper. Topics include agentic training and trajectory-based RL, retrieval-augmented generation (RAG and Agentic RAG), memory systems (in-context, external, episodic, and semantic), agent harness design and context management, and a taxonomy of agent design patterns. Inter-agent coordination is covered in depth: the Model Context Protocol (MCP), agent skills and tool use, the Agent-to-Agent (A2A) communication protocol, and multi-agent architectures spanning centralized, decentralized, and hierarchical topologies. The book concludes with agent development frameworks, agentic UI design, evaluation methodology for agentic tasks, and production deployment. Each chapter pairs rigorous theoretical foundations with implementation guidance, code examples, and references to the primary literature.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a book-length practitioner's reference titled 'The Hitchhiker's Guide to Agentic AI: From Foundations to Systems'. It covers the full stack for building autonomous AI systems, starting with the LLM substrate (transformer architecture, GPU systems, SFT/LoRA/MoE training, model compression, inference optimization), then alignment and reasoning (RLHF, PPO/DPO/GRPO variants, reward modeling, RL for reasoning models with CoT and test-time scaling), followed by agentic topics (agentic training/trajectory RL, RAG/Agentic RAG, memory systems, agent harness/context management, design patterns), inter-agent coordination (MCP, skills/tool use, A2A protocol, centralized/decentralized/hierarchical multi-agent topologies), and concluding with frameworks, UI design, evaluation, and production deployment. The central thesis is that building great agentic systems requires understanding every layer of the pipeline, not just one; each chapter pairs theory with implementation guidance, code examples, and primary references.
Significance. If the synthesis proves coherent and current, the work could be a useful reference for practitioners by integrating transformer fundamentals, RLHF methods, RAG variants, memory systems, and multi-agent protocols into one volume with code examples. The explicit pairing of theory with implementation is a positive feature for an expository guide. The thesis correctly identifies the need for holistic pipeline understanding in agentic systems. Value is limited by the rapid evolution of the covered subfields and the absence of any mechanism described for cross-layer consistency.
major comments (1)
- [Abstract and Overall Structure] Abstract and Overall Structure: The central thesis depends on the book delivering a coherent integration across independently evolving areas (RLHF variants like PPO/DPO/GRPO, RAG/Agentic RAG, A2A protocols, multi-agent topologies). No mechanism is described for maintaining cross-layer consistency or addressing superseded recommendations, which is load-bearing for the claim that the synthesis supports building great agentic systems without internal inconsistencies.
minor comments (1)
- [Abstract] Abstract: The Model Context Protocol (MCP) is referenced without definition or expansion; ensure all acronyms are introduced at first use throughout the manuscript.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for identifying a key requirement of our central thesis. We address the major comment below.
read point-by-point responses
-
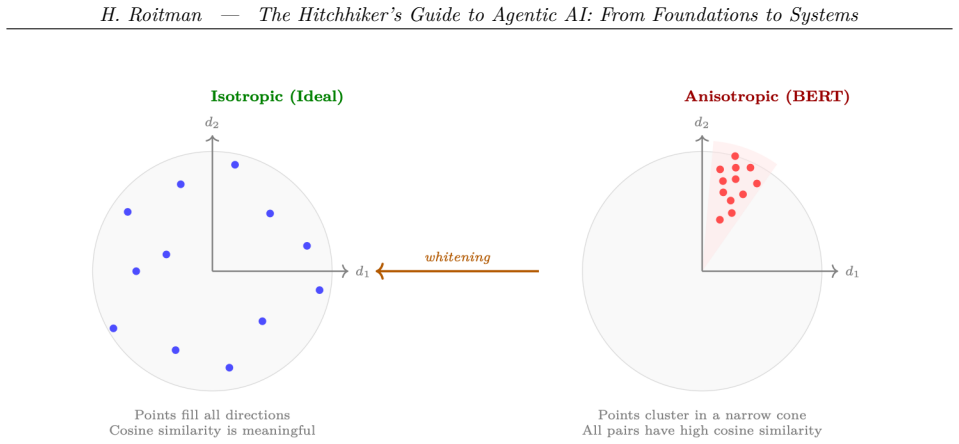
Referee: The central thesis depends on the book delivering a coherent integration across independently evolving areas (RLHF variants like PPO/DPO/GRPO, RAG/Agentic RAG, A2A protocols, multi-agent topologies). No mechanism is described for maintaining cross-layer consistency or addressing superseded recommendations, which is load-bearing for the claim that the synthesis supports building great agentic systems without internal inconsistencies.
Authors: We agree that the manuscript does not explicitly describe a mechanism for cross-layer consistency or for handling superseded recommendations. The current organization presents material sequentially with some cross-references, but this falls short of the load-bearing requirement noted. We will add a dedicated subsection (likely in the introduction) that outlines practical strategies for maintaining consistency, such as modular interface design, unified evaluation pipelines that span layers, and versioning notes for rapidly evolving components. This revision will directly support the thesis by giving readers explicit guidance on integration. revision: yes
Circularity Check
Expository synthesis with no derivations or self-referential predictions
full rationale
The manuscript is a practitioner's reference guide synthesizing existing techniques across LLM foundations, alignment methods, RAG, memory systems, and multi-agent protocols. No equations, fitted parameters, predictions, or derivation chains appear in the abstract or described structure. The central thesis is a high-level recommendation rather than a formally derived result. All topics cite primary external literature without reducing any claim to quantities defined by the book's own parameters or self-citations. This matches the default expectation of no significant circularity for expository works.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jennings, and David Kinny
Michael Wooldridge, Nicholas R. Jennings, and David Kinny. The Gaia Methodology for Agent-Oriented Analysis and Design.Autonomous Agents and Multi-Agent Systems, 2000
2000
-
[2]
JADE: Developing Multi- Agent Systems with JADE, 2007
Fabio Luigi Bellifemine, Giovanni Caire, and Dominic Greenwood. JADE: Developing Multi- Agent Systems with JADE, 2007
2007
-
[3]
FIPA ACL Message Structure Specification, 2002
Foundation for Intelligent Physical Agents. FIPA ACL Message Structure Specification, 2002. URLhttp://www.fipa.org/specs/fipa00061/
2002
-
[4]
The Semantic Web.Scientific American, 2001
Tim Berners-Lee, James Hendler, and Ora Lassila. The Semantic Web.Scientific American, 2001
2001
-
[5]
A Framework for Modeling and Evaluating Automatic Semantic Reconciliation
Avigdor Gal, Ateret Anaby-Tavor, Alberto Trombetta, and Danilo Montesi. A Framework for Modeling and Evaluating Automatic Semantic Reconciliation. InProceedings of the 31st International Conference on Very Large Data Bases (VLDB), 2005. URLhttps://link. springer.com/chapter/10.1007/11896548_42
-
[6]
Ashish Vaswani, Noam Shazeer, Niki Parmar, et al. Attention Is All You Need. InAdvances in Neural Information Processing Systems (NeurIPS), 2017. URLhttps://arxiv.org/abs/ 1706.03762
Pith/arXiv arXiv 2017
-
[7]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. InAdvances in Neural Information Processing Systems (NeurIPS), 2022. URLhttps://arxiv.org/abs/2205.14135
Pith/arXiv arXiv 2022
-
[9]
Training Language Models to Follow Instructions with Human Feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, et al. Training Language Models to Follow Instructions with Human Feedback. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[10]
URLhttps://arxiv.org/abs/2203.02155
-
[11]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct Preference Optimization: Your Language Model Is Secretly a Reward Model. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. URL https://arxiv.org/abs/2305.18290
Pith/arXiv arXiv 2023
-
[12]
KTO: Model Alignment as Prospect Theoretic Optimization.arXiv Preprint arXiv:2402.01306, 2024
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. KTO: Model Alignment as Prospect Theoretic Optimization.arXiv Preprint arXiv:2402.01306, 2024. URLhttps://arxiv.org/abs/2402.01306
Pith/arXiv arXiv 2024
-
[13]
Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, et al. A General Theoretical Paradigm to Understand Learning from Human Feedback.arXiv Preprint arXiv:2310.12036, 2024. URL https://arxiv.org/abs/2310.12036
arXiv 2024
-
[14]
Jiwoo Hong, Noah Lee, and James Thorne. ORPO: Monolithic Preference Optimization Without Reference Model.arXiv Preprint arXiv:2403.07691, 2024. URLhttps://arxiv.org/ abs/2403.07691. 578 H. Roitman — The Hitchhiker’s Guide to Agentic AI: From Foundations to Systems
Pith/arXiv arXiv 2024
-
[15]
Zhihong Shao, Peiyi Wang, Qihao Zhu, et al. DeepSeekMath: Pushing the Limits of Mathe- matical Reasoning in Open Language Models.arXiv Preprint arXiv:2402.03300, 2024. URL https://arxiv.org/abs/2402.03300
Pith/arXiv arXiv 2024
-
[16]
DeepSeek-AI, Daya Guo, Dejian Yang, et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.arXiv Preprint arXiv:2501.12948, 2025. URLhttps: //arxiv.org/abs/2501.12948
Pith/arXiv arXiv 2025
-
[17]
Joseph Hoane Jr., and Feng hsiung Hsu
Murray Campbell, A. Joseph Hoane Jr., and Feng hsiung Hsu. Deep Blue.Artificial Intelligence, 2002
2002
-
[18]
Building Watson: An Overview of the DeepQA Project.AI Magazine, 2010
David Ferrucci, Eric Brown, Jennifer Chu-Carroll, et al. Building Watson: An Overview of the DeepQA Project.AI Magazine, 2010
2010
-
[19]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks.NeurIPS, 2012
2012
-
[20]
Maddison, et al
David Silver, Aja Huang, Chris J. Maddison, et al. Mastering the Game of Go with Deep Neural Networks and Tree Search.Nature, 2016. URLhttps://www.nature.com/articles/ nature16961
2016
-
[21]
Mastering the Game of Go Without Human Knowledge.Nature, 2017
David Silver, Julian Schrittwieser, Karen Simonyan, et al. Mastering the Game of Go Without Human Knowledge.Nature, 2017. URLhttps://www.nature.com/articles/nature24270
2017
-
[22]
Language Models Are Few-Shot Learners
Tom Brown, Benjamin Mann, Nick Ryder, et al. Language Models Are Few-Shot Learners. NeurIPS, 2020
2020
-
[23]
Highly Accurate Protein Structure Prediction with AlphaFold.Nature, 2021
John Jumper, Richard Evans, Alexander Pritzel, et al. Highly Accurate Protein Structure Prediction with AlphaFold.Nature, 2021
2021
-
[24]
GPT-4 Technical Report.arXiv Preprint arXiv:2303.08774, 2023
OpenAI. GPT-4 Technical Report.arXiv Preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[25]
Neural Machine Translation of Rare Words with Subword Units
Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural Machine Translation of Rare Words with Subword Units. InProceedings of the 54th Annual Meeting of the ACL, 2016. URL https://arxiv.org/abs/1508.07909
Pith/arXiv arXiv 2016
-
[26]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The Llama 3 Herd of Models. arXiv Preprint arXiv:2407.21783, 2024. URLhttps://arxiv.org/abs/2407.21783
Pith/arXiv arXiv 2024
-
[27]
Jiang, Alexandre Sablayrolles, Arthur Mensch, et al
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, et al. Mistral 7B.arXiv Preprint arXiv:2310.06825, 2023. URLhttps://arxiv.org/abs/2310.06825
Pith/arXiv arXiv 2023
-
[28]
BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. InProceedings of NAACL-HLT,
-
[29]
URLhttps://arxiv.org/abs/1810.04805
-
[30]
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter.arXiv Preprint arXiv:1910.01108, 2019
Pith/arXiv arXiv 1910
-
[31]
Colin Raffel, Noam Shazeer, Adam Roberts, et al. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.Journal of Machine Learning Research, 2020. URL https://arxiv.org/abs/1910.10683
Pith/arXiv arXiv 2020
-
[32]
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V. Le. XLNet: Generalized Autoregressive Pretraining for Language Understanding. InAdvances in Neural Information Processing Systems (NeurIPS), 2019. 579 H. Roitman — The Hitchhiker’s Guide to Agentic AI: From Foundations to Systems
2019
-
[33]
Language Models Are Unsupervised Multitask Learners.OpenAI Blog,
Alec Radford, Jeffrey Wu, Rewon Child, David Luen, Dario Amodei, and Ilya Sutskever. Language Models Are Unsupervised Multitask Learners.OpenAI Blog,
-
[34]
URL https://cdn.openai.com/better-language-models/language_models_are_ unsupervised_multitask_learners.pdf
-
[35]
Qwen2.5: A Party of Foundation Models.arXiv Preprint arXiv:2412.15115, 2024
Qwen Team. Qwen2.5: A Party of Foundation Models.arXiv Preprint arXiv:2412.15115, 2024. URLhttps://arxiv.org/abs/2412.15115
Pith/arXiv arXiv 2024
-
[36]
Mike Lewis, Yinhan Liu, Naman Goyal, et al. BART: Denoising Sequence-to-Sequence Pre- Training for Natural Language Generation, Translation, and Comprehension. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020. URL https://arxiv.org/abs/1910.13461
Pith/arXiv arXiv 2020
-
[37]
Scaling Instruction-Finetuned Language Models.Journal of Machine Learning Research, 2024
Hyung Won Chung, Le Hou, Shayne Longpre, et al. Scaling Instruction-Finetuned Language Models.Journal of Machine Learning Research, 2024. URLhttps://arxiv.org/abs/2210. 11416
2024
-
[38]
RoBERTa: A Robustly Optimized BERT Pretraining Approach.arXiv Preprint arXiv:1907.11692, 2019
Yinhan Liu, Myle Ott, Naman Goyal, et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach.arXiv Preprint arXiv:1907.11692, 2019. URL https://arxiv.org/ abs/1907.11692
Pith/arXiv arXiv 1907
-
[39]
A Synopsis of Linguistic Theory, 1930–1955.Studies in Linguistic Analysis, 1957
John Rupert Firth. A Synopsis of Linguistic Theory, 1930–1955.Studies in Linguistic Analysis, 1957
1930
-
[40]
Kawin Ethayarajh. How Contextual Are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2019. URLhttps://arxiv. org/abs/1909.00512
arXiv 2019
-
[41]
Jianlin Su, Jiarun Cao, Weijie Liu, and Yangyiwen Ou. Whitening Sentence Representations for Better Semantics and Faster Retrieval.arXiv Preprint arXiv:2103.15316, 2021. URL https://arxiv.org/abs/2103.15316
arXiv 2021
-
[42]
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The Long-Document Trans- former.arXiv Preprint arXiv:2004.05150, 2020. URLhttps://arxiv.org/abs/2004.05150
Pith/arXiv arXiv 2004
-
[43]
Big Bird: Transformers for Longer Sequences
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, et al. Big Bird: Transformers for Longer Sequences. InAdvances in Neural Information Processing Systems (NeurIPS), 2020. URLhttps://arxiv.org/abs/2007.14062
Pith/arXiv arXiv 2020
-
[44]
LongT5: Efficient Text-to-Text Transformer for Long Sequences.Findings of the Association for Computational Linguistics: NAACL 2022,
Mandy Guo, Joshua Ainslie, David Uthus, et al. LongT5: Efficient Text-to-Text Transformer for Long Sequences.Findings of the Association for Computational Linguistics: NAACL 2022,
2022
-
[45]
URLhttps://arxiv.org/abs/2112.07916
-
[47]
Bo Peng, Eric Alcaide, Quentin Anthony, et al. RWKV: Reinventing RNNs for the Transformer Era.Findings of the Association for Computational Linguistics: EMNLP 2023, 2023. URL https://arxiv.org/abs/2305.13048
Pith/arXiv arXiv 2023
-
[48]
H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, et al. H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. URLhttps://arxiv.org/abs/2306.14048
Pith/arXiv arXiv 2023
-
[50]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Zirui Liu, Jiayi Yuan, Hongye Jin, et al. KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache. InInternational Conference on Machine Learning (ICML), 2024. URL https://arxiv.org/abs/2402.02750
Pith/arXiv arXiv 2024
-
[51]
Ring Attention with Blockwise Transformers for Near-Infinite Context
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring Attention with Blockwise Transformers for Near-Infinite Context. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. URLhttps://arxiv.org/abs/2310.01889
Pith/arXiv arXiv 2023
-
[52]
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
BigScience Workshop. BLOOM: A 176B-Parameter Open-Access Multilingual Language Model. arXiv Preprint arXiv:2211.05100, 2023. URLhttps://arxiv.org/abs/2211.05100
Pith/arXiv arXiv 2023
-
[53]
MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs.MosaicML Blog, 2023
MosaicML. MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs.MosaicML Blog, 2023. URLhttps://www.mosaicml.com/blog/mpt-7b
2023
-
[54]
RoFormer: Enhanced Transformer with Rotary Position Embedding.Neurocomputing, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: Enhanced Transformer with Rotary Position Embedding.Neurocomputing, 2024
2024
-
[55]
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shao. YaRN: Efficient Context Window Extension of Large Language Models.arXiv Preprint arXiv:2309.00071, 2023
Pith/arXiv arXiv 2023
-
[56]
Smith, and Mike Lewis
Ofir Press, Noah A. Smith, and Mike Lewis. Train Short, Test Long: Attention with Linear Biases Enables Input Length Generalization.ICLR, 2022
2022
-
[57]
The Claude 3 Model Family: Opus, Sonnet, Haiku.Anthropic Technical Report,
Anthropic. The Claude 3 Model Family: Opus, Sonnet, Haiku.Anthropic Technical Report,
-
[58]
URLhttps://www.anthropic.com/news/claude-3-family
-
[59]
Google Gemini Team. Gemini 1.5: Unlocking Multimodal Understanding Across Millions of Tokens of Context.arXiv Preprint arXiv:2403.05530, 2024. URLhttps://arxiv.org/abs/ 2403.05530
Pith/arXiv arXiv 2024
-
[61]
URLhttps://arxiv.org/abs/2306.15595
-
[62]
Liu, Kevin Lin, John Hewitt, et al
Nelson F. Liu, Kevin Lin, John Hewitt, et al. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Association for Computational Linguistics, 2024. URL https://arxiv.org/abs/2307.03172
Pith/arXiv arXiv 2024
-
[63]
Transformer Feed-Forward Layers Are Key-Value Memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer Feed-Forward Layers Are Key-Value Memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021
2021
-
[64]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer Normalization.arXiv Preprint arXiv:1607.06450, 2016. URLhttps://arxiv.org/abs/1607.06450
Pith/arXiv arXiv 2016
-
[65]
Root Mean Square Layer Normalization
Biao Zhang and Rico Sennrich. Root Mean Square Layer Normalization. InAdvances in Neural Information Processing Systems (NeurIPS), 2019. URLhttps://arxiv.org/abs/1910.07467
Pith/arXiv arXiv 2019
-
[66]
The Llama 4 Herd: The Beginning of a New Era of Natively Multimodal AI.Meta AI Blog, 2025
Meta AI. The Llama 4 Herd: The Beginning of a New Era of Natively Multimodal AI.Meta AI Blog, 2025. URLhttps://ai.meta.com/blog/llama-4-multimodal-intelligence/
2025
-
[67]
Mistral Large 2.Mistral AI Blog, 2024
Mistral AI. Mistral Large 2.Mistral AI Blog, 2024. URL https://mistral.ai/news/ mistral-large-2407/
2024
-
[68]
DeepSeek-V3 Technical Report.arXiv Preprint arXiv:2412.19437, 2024
DeepSeek-AI. DeepSeek-V3 Technical Report.arXiv Preprint arXiv:2412.19437, 2024. URL https://arxiv.org/abs/2412.19437
Pith/arXiv arXiv 2024
-
[69]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient Streaming Language Models with Attention Sinks. InProceedings of the 12th International Conference on Learning Representations (ICLR), 2024. URLhttps://arxiv.org/abs/2309.17453. 581 H. Roitman — The Hitchhiker’s Guide to Agentic AI: From Foundations to Systems
Pith/arXiv arXiv 2024
-
[70]
Data Engineering for Scaling Language Models to 128K Context.arXiv Preprint arXiv:2402.10171, 2024
Yao Fu, Rameswar Panda, Xinyao Niu, et al. Data Engineering for Scaling Language Models to 128K Context.arXiv Preprint arXiv:2402.10171, 2024. URL https://arxiv.org/abs/ 2402.10171
arXiv 2024
-
[71]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024. URL https://arxiv.org/abs/2312.00752
Pith/arXiv arXiv 2024
-
[72]
Analyzing Multi- Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
Elena Voita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. Analyzing Multi- Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL),
-
[73]
URLhttps://arxiv.org/abs/1905.09418
Pith/arXiv arXiv 1905
-
[74]
In-Context Learning and Induction Heads.Transformer Circuits Thread, 2022
Catherine Olsson, Nelson Elhage, Neel Nanda, et al. In-Context Learning and Induction Heads.Transformer Circuits Thread, 2022. URL https://transformer-circuits.pub/ 2022/in-context-learning-and-induction-heads/index.html
2022
-
[76]
URLhttps://arxiv.org/abs/2404.15574
-
[77]
A Multiscale Visualization of Attention in the Transformer Model
Jesse Vig. A Multiscale Visualization of Attention in the Transformer Model. InProceedings of the 57th ACL: System Demonstrations, 2019. URLhttps://arxiv.org/abs/1906.05714
Pith/arXiv arXiv 2019
-
[78]
Quantifying Attention Flow in Transformers
Samira Abnar and Willem Zuidema. Quantifying Attention Flow in Transformers. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020. URLhttps://arxiv.org/abs/2005.00928
arXiv 2020
-
[79]
Grad-SAM: Explaining Transformers via Gradient Self-Attention Maps
Oren Barkan, Edan Hauon, Avi Caciularu, Ido Dagan, and Noam Koenigstein. Grad-SAM: Explaining Transformers via Gradient Self-Attention Maps. InProceedings of the 30th ACM International Conference on Information and Knowledge Management (CIKM), 2021. URL https://arxiv.org/abs/2104.13299
arXiv 2021
-
[80]
Sarthak Jain and Byron C. Wallace. Attention Is Not Explanation. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2019. URLhttps://arxiv.org/abs/1902.10186
Pith/arXiv arXiv 2019
-
[81]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse Autoencoders Find Highly Interpretable Features in Language Models. InProceedings of the 12th International Conference on Learning Representations (ICLR), 2024. URLhttps: //arxiv.org/abs/2309.08600
Pith/arXiv arXiv 2024
-
[82]
Towards Monosemanticity: Decom- posing Language Models with Dictionary Learning.Transformer Circuits Thread, 2023
Trenton Bricken, Adly Templeton, Joshua Batson, et al. Towards Monosemanticity: Decom- posing Language Models with Dictionary Learning.Transformer Circuits Thread, 2023. URL https://transformer-circuits.pub/2023/monosemantic-features/index.html
2023
-
[83]
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet.Transformer Circuits Thread, 2024
Adly Templeton, Tom Conerly, Jonathan Marcus, et al. Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet.Transformer Circuits Thread, 2024. URL https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
2024
-
[84]
Natural Language Autoencoders: Interpreting Neural Networks with Natural Language Descriptions.Anthropic Research Blog, 2026
Anthropic. Natural Language Autoencoders: Interpreting Neural Networks with Natural Language Descriptions.Anthropic Research Blog, 2026. URLhttps://www.anthropic.com/ research/natural-language-autoencoders
2026
-
[85]
David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. Learning Representations by Back-Propagating Errors.Nature, 1986. URLhttps://doi.org/10.1038/323533a0
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.