RMTL: Reinforced Micro-task Learning for Long-Horizon Manipulation with VLM Rewards
Pith reviewed 2026-06-26 02:05 UTC · model grok-4.3
The pith
Decomposing long-horizon robotic tasks into micro-tasks with separate VLM prompts produces non-flat rewards that speed up reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
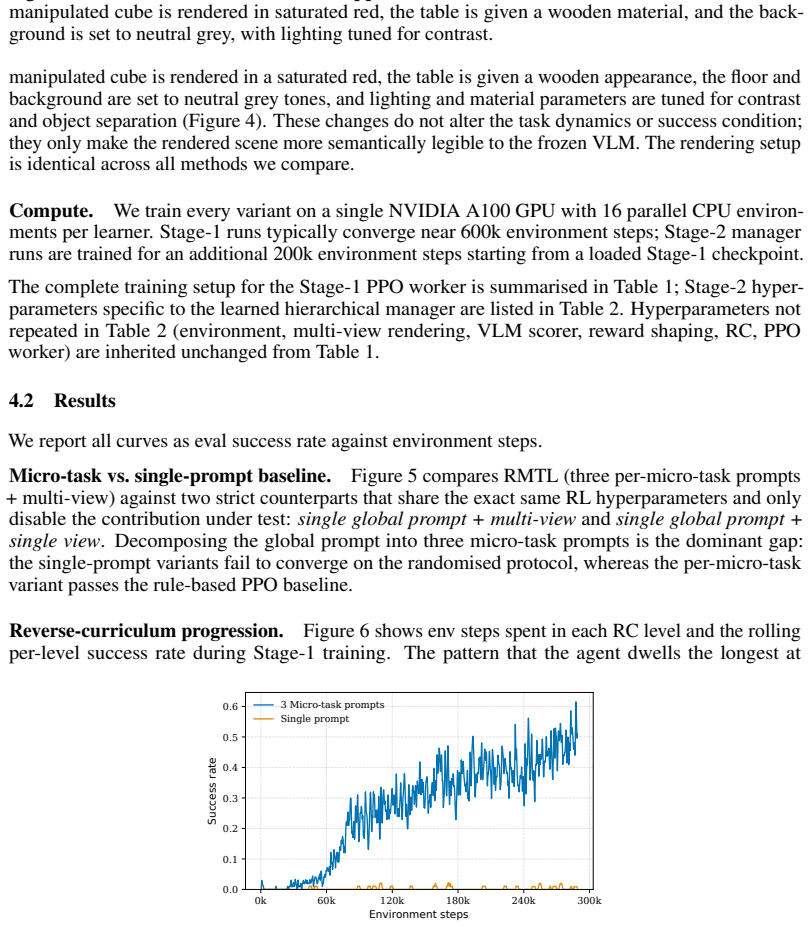
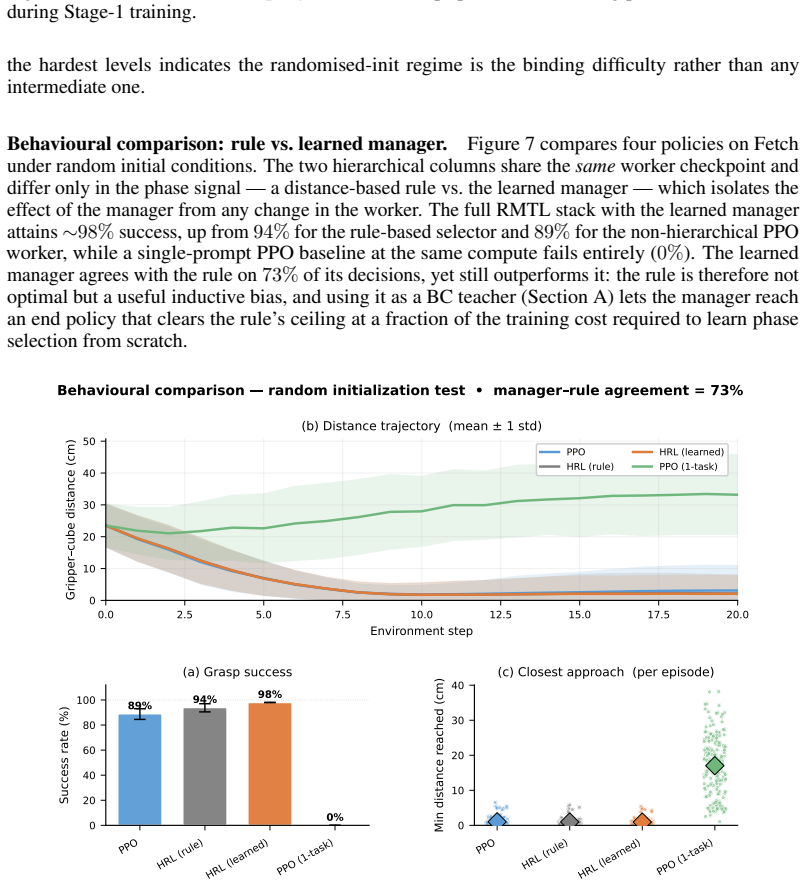
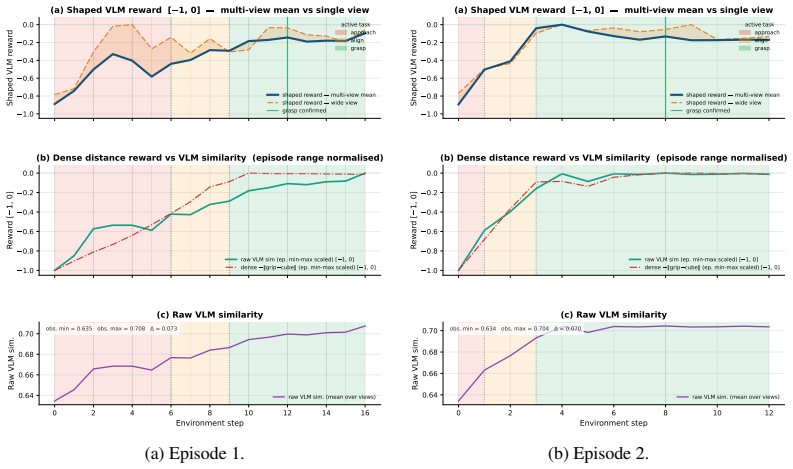
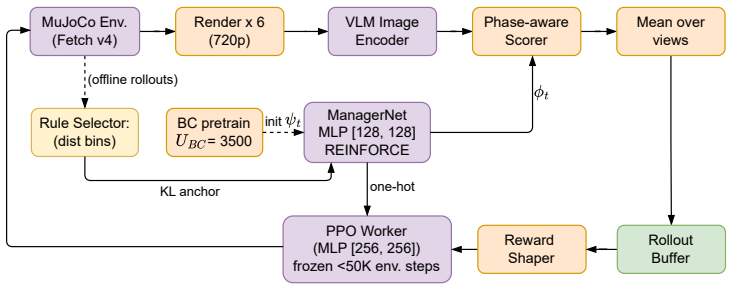
RMTL decomposes a manipulation task into a small set of language-described micro-tasks and trains the agent to switch between them. At each step the agent receives a multi-view VLM reward computed using the prompt of the currently active micro-task. A reverse curriculum gradually hardens the initial conditions while a PPO worker is first trained with a fixed distance-based rule that selects the active micro-task; this rule is later replaced by a learned hierarchical manager. The method uses three short stage-specific prompts without further tuning and produces more informative reward signals than a single global prompt.
What carries the argument
Micro-task decomposition that assigns a distinct language prompt to each stage so the VLM can compute a non-flat, view-averaged reward for the active stage only.
If this is right
- VLM rewards become usable for early phases of long sequences instead of remaining flat.
- A learned manager can replace an initial rule-based phase selector while preserving performance.
- The approach requires no prompt retuning once the three stage prompts are chosen.
- Single-prompt VLM rewards remain too coarse for long-horizon tasks with varied starts.
Where Pith is reading between the lines
- The same micro-task split could be tested with other vision-language reward models to check whether the gain is specific to VLM scoring.
- Adding more micro-tasks might extend the method to sequences longer than those tested in Fetch.
- The hierarchical manager learned here could be reused as a starting point for other manipulation problems that share similar stage structure.
Load-bearing premise
Three short stage-specific prompts can be written once, without further tuning, such that the VLM produces sufficiently informative and non-flat rewards for each micro-task across randomized initial conditions.
What would settle it
Training curves on the Fetch environment with randomized starts that show identical learning speed and final success rate for RMTL and the single-prompt VLM baseline.
Figures





read the original abstract
Reinforcement learning (RL) for robotic manipulation often requires manually designing a dense reward function, which is difficult to tune and often fragile, or learning a reward from human demonstrations or preferences, which can be expensive. A recent line of work uses pretrained vision-language models (VLMs) as zero-shot reward models, replacing these costs with a single text prompt. However, we argue that a single global prompt is too coarse for long-horizon manipulation tasks with randomized initial conditions. The single-prompt VLM reward is near-flat for much of the trajectory, making early progress hard for the agent to detect. We propose Reinforced Micro-Task Learning (RMTL), an approach that decomposes a manipulation task into a small set of language-described micro-tasks and trains the agent to switch between them. At each step, the agent receives a multi-view VLM reward computed using the prompt of the currently active micro-task and averaged across multiple camera views to reduce the effect of view-specific occlusions. A reverse curriculum gradually exposes the agent to harder initial conditions, while a PPO worker is first trained with a fixed distance-based rule that selects the active micro-task. We then replace this rule with a learned hierarchical manager, turning rule-based phase selection into a fully learned hierarchical policy. We instantiate RMTL on the Fetch manipulation environment using three short stage-specific prompts and without additional prompt tuning. Experiments show that RMTL provides more informative reward signals than single-prompt VLM rewards, enabling faster learning. These results suggest that decomposing VLM rewards into micro-task-specific language prompts can substantially improve the scalability of language-guided reinforcement learning for robotic manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Reinforced Micro-Task Learning (RMTL) to address flat VLM rewards in long-horizon robotic manipulation. It decomposes tasks into three language-described micro-tasks, computes multi-view VLM rewards using stage-specific prompts, employs a reverse curriculum and an initial distance-based rule for micro-task selection before replacing it with a learned hierarchical manager, and reports faster learning than single-prompt baselines on the Fetch environment without additional prompt tuning.
Significance. If the empirical claims hold, the decomposition approach could improve the practicality of zero-shot VLM rewards for complex manipulation by providing denser signals, potentially scaling language-guided RL beyond short-horizon tasks.
major comments (2)
- [Abstract] Abstract: the central claim that 'decomposing VLM rewards into micro-task-specific language prompts' yields 'more informative reward signals' and 'faster learning' rests on the unverified assumption that three fixed prompts produce non-flat rewards under randomized initial conditions; no reward density statistics, histograms, or ablation tables are provided to confirm this.
- [Abstract] Abstract: the initial training uses a distance-based rule rather than VLM rewards, so the contribution of the prompt decomposition to learning is only tested after the manager is learned; without separate curves isolating the VLM component or controls for curriculum effects, attribution to the micro-task decomposition is not established.
minor comments (1)
- [Abstract] Abstract: the Fetch environment and number of views used for averaging are not specified, which limits reproducibility assessment.
Simulated Author's Rebuttal
Thank you for the constructive comments on our manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'decomposing VLM rewards into micro-task-specific language prompts' yields 'more informative reward signals' and 'faster learning' rests on the unverified assumption that three fixed prompts produce non-flat rewards under randomized initial conditions; no reward density statistics, histograms, or ablation tables are provided to confirm this.
Authors: We agree that the manuscript does not provide direct reward density statistics, histograms, or ablation tables to verify non-flat rewards from the micro-task prompts. The claim of more informative signals is supported indirectly by the faster learning curves relative to the single-prompt baseline. To address this, we will add reward signal analysis or visualizations in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the initial training uses a distance-based rule rather than VLM rewards, so the contribution of the prompt decomposition to learning is only tested after the manager is learned; without separate curves isolating the VLM component or controls for curriculum effects, attribution to the micro-task decomposition is not established.
Authors: We clarify that VLM rewards (computed with the active micro-task prompt) are used from the start of training; the distance-based rule governs only the selection of the active micro-task in the initial phase, prior to training the learned hierarchical manager. The reverse curriculum is applied consistently. We acknowledge that this setup leaves potential confounding from the rule-based selection and curriculum, and that isolating curves or additional controls would better establish attribution to the decomposition. We will incorporate further discussion or ablations in the revision. revision: partial
Circularity Check
No circularity: empirical method with external VLM evaluation
full rationale
The paper presents an empirical RL approach that decomposes tasks into micro-tasks and uses fixed VLM prompts for rewards, validated via experiments on the Fetch environment. No equations, fitted parameters, or self-citations reduce any performance claim to a quantity defined by construction within the paper. The central results rely on observed learning curves rather than any self-referential derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
The option-critic architecture
Pierre-Luc Bacon, Jean Harb, and Doina Precup. The option-critic architecture. InAAAI Conference on Artificial Intelligence (AAAI), 2017
2017
-
[3]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, et al. RT-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
MineDojo: Building open-ended embodied agents with internet-scale knowledge.Advances in Neural Information Processing Systems (NeurIPS), 35:18343–18362, 2022
Linxi Fan, Guanzhi Wang, Yunfan Jiang, Ajay Mandlekar, Yuncong Yang, Haoyi Zhu, Andrew Tang, De-An Huang, Yuke Zhu, and Anima Anandkumar. MineDojo: Building open-ended embodied agents with internet-scale knowledge.Advances in Neural Information Processing Systems (NeurIPS), 35:18343–18362, 2022
2022
-
[5]
Reverse curriculum generation for reinforcement learning
Carlos Florensa, David Held, Markus Wulfmeier, Michael Zhang, and Pieter Abbeel. Reverse curriculum generation for reinforcement learning. InConference on Robot Learning (CoRL), 2017
2017
-
[6]
CURL: Contrastive unsupervised rep- resentations for reinforcement learning
Michael Laskin, Aravind Srinivas, and Pieter Abbeel. CURL: Contrastive unsupervised rep- resentations for reinforcement learning. InInternational Conference on Machine Learning (ICML), pages 5639–5650, 2020
2020
-
[7]
Reinforcement learning with augmented data.Advances in Neural Information Processing Systems (NeurIPS), 33:19884–19895, 2020
Misha Laskin, Kimin Lee, Adam Stooke, Lerrel Pinto, Pieter Abbeel, and Aravind Srinivas. Reinforcement learning with augmented data.Advances in Neural Information Processing Systems (NeurIPS), 33:19884–19895, 2020
2020
-
[8]
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Yecheng Jason Ma, Shagun Sodhani, Dinesh Jayaraman, Osbert Bastani, Vikash Kumar, and Amy Zhang. VIP: Towards universal visual reward and representation via value-implicit pre-training.arXiv preprint arXiv:2210.00030, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
LIV: Language-image representations and rewards for robotic control
Yecheng Jason Ma, Vikash Kumar, Amy Zhang, Osbert Bastani, and Dinesh Jayaraman. LIV: Language-image representations and rewards for robotic control. InInternational Conference on Machine Learning (ICML), pages 23301–23320, 2023
2023
-
[10]
Eureka: Human-Level Reward Design via Coding Large Language Models
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Eureka: Human-level reward design via coding large language models.arXiv preprint arXiv:2310.12931, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
PE-Core-bigG-14-448: Perception encoders for vision-language modelling, 2025
Meta AI. PE-Core-bigG-14-448: Perception encoders for vision-language modelling, 2025. Open weights, distributed via the OpenCLIP API; available at https://huggingface.co/ facebook/PE-Core-bigG-14-448
2025
-
[12]
Data-efficient hierarchical reinforcement learning.Advances in Neural Information Processing Systems (NeurIPS), 31, 2018
Ofir Nachum, Shixiang Shane Gu, Honglak Lee, and Sergey Levine. Data-efficient hierarchical reinforcement learning.Advances in Neural Information Processing Systems (NeurIPS), 31, 2018
2018
-
[13]
Multi-goal reinforcement learning: Challenging robotics environments and request for research
Matthias Plappert, Marcin Andrychowicz, Alex Ray, Bob McGrew, Bowen Baker, Glenn Powell, Jonas Schneider, Josh Tobin, Maciek Chociej, Peter Welinder, Vikash Kumar, and Wojciech Zaremba. Multi-goal reinforcement learning: Challenging robotics environments and request for research. 2018
2018
-
[14]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInterna- tional Conference on Machine Learning (ICML), 2021
2021
-
[15]
Stable-Baselines3: Reliable reinforcement learning implementations.Journal of Machine Learning Research (JMLR), 2021
Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernestus, and Noah Dormann. Stable-Baselines3: Reliable reinforcement learning implementations.Journal of Machine Learning Research (JMLR), 2021. 10
2021
-
[16]
Vision- language models are zero-shot reward models for reinforcement learning
Juan Rocamonde, Victoriano Montesinos, Elvis Nava, Ethan Perez, and David Lindner. Vision- language models are zero-shot reward models for reinforcement learning. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[17]
Gordon, and J
Stéphane Ross, Geoffrey J. Gordon, and J. Andrew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2011
2011
-
[18]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [19]
-
[20]
Sutton, Doina Precup, and Satinder Singh
Richard S. Sutton, Doina Precup, and Satinder Singh. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning.Artificial Intelligence, 112(1–2): 181–211, 1999
1999
-
[21]
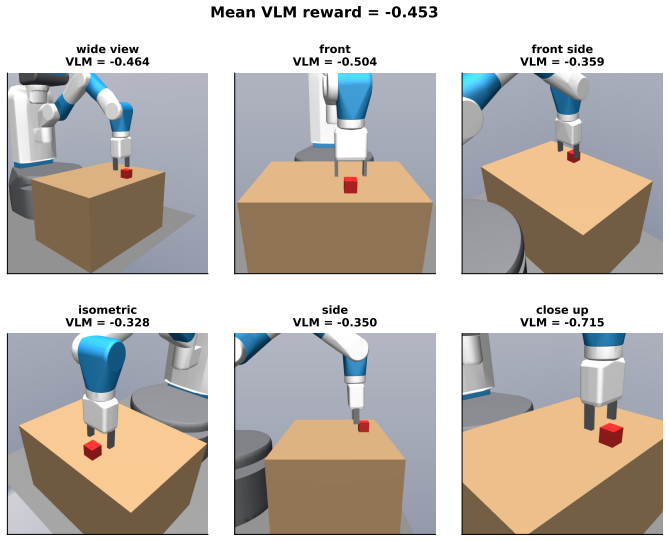
a robot gripper and a red cube on a table
Emanuel Todorov, Tom Erez, and Yuval Tassa. MuJoCo: A physics engine for model-based control. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2012. 11 A Implementation details Algorithm.The RMTL algorithm is given below. Algorithm 1Stage-2 HRL Learned Manager with a Frozen-then-Unfrozen PPO Worker Require: Pretrained PPO work...
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.