DinoLink: A Token-Centric Representation Compression Framework for Bandwidth-Constrained Collaborative V2X Perception
Pith reviewed 2026-07-01 06:22 UTC · model grok-4.3
The pith
DinoLink replaces raw pixel streams with compressed semantic token indices to cut V2X transmission bitrate by 139 times while holding 32.8 percent mAP.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
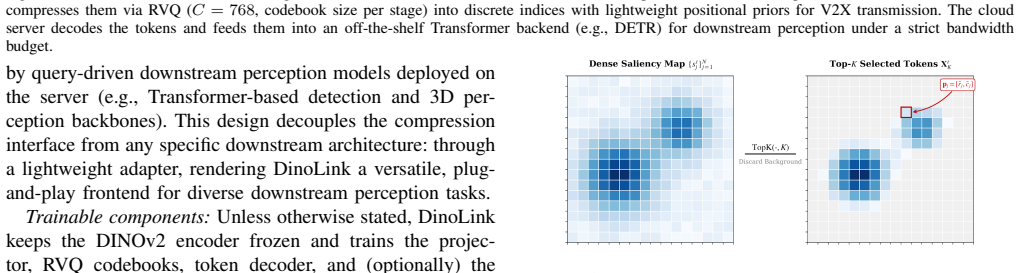
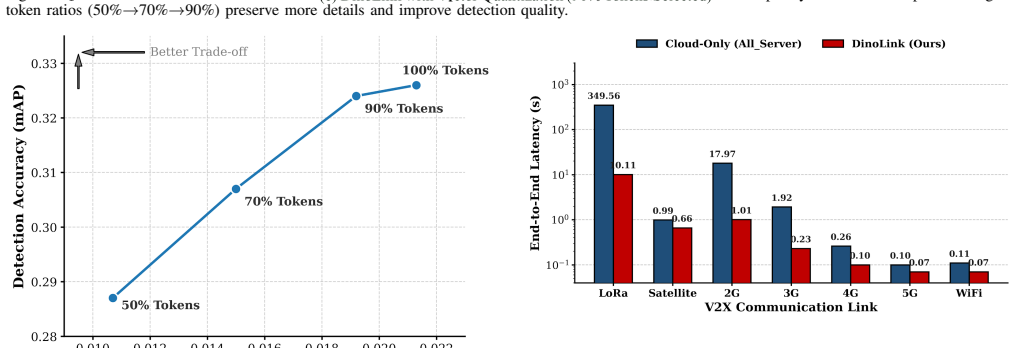
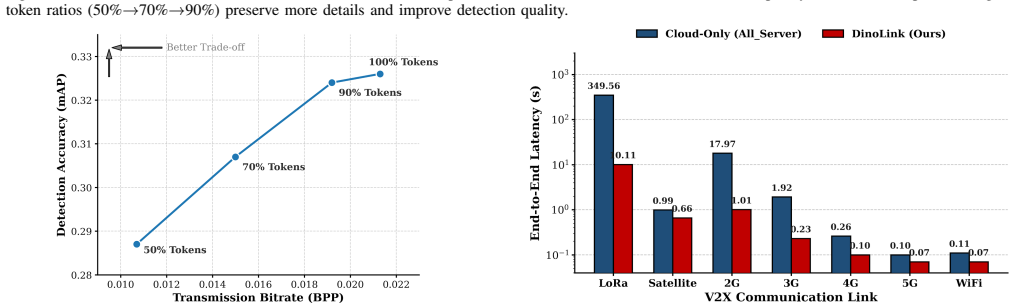
DinoLink employs a dual-sparsity architecture: a saliency-aware selector prunes redundant background tokens, while a Residual Vector Quantization module collapses features into compact codebook indices. By transmitting only lightweight indices and positional priors, DinoLink achieves a 139× bitrate reduction compared to uncompressed transmission while maintaining a competitive 32.8% mAP on the nuScenes dataset. Deployment simulations further demonstrate a 34.5× acceleration in narrow-band environments, such as LoRa.
What carries the argument
Dual-sparsity architecture that combines a saliency-aware token selector with Residual Vector Quantization to convert image features into short codebook indices and position priors.
If this is right
- V2X networks can deliver high-fidelity collaborative perception under tight bandwidth limits by sending indices instead of pixels.
- Narrow-band links such as LoRa can support real-time remote perception with a measured 34.5 times speed-up.
- The same frontend works across different perception backbones because no task-specific retraining is required.
- Only code indices and position priors need to be transmitted, which directly lowers the data volume by the stated factor of 139.
Where Pith is reading between the lines
- The same token-selection and quantization steps could be tested on other multi-agent sensing tasks such as drone fleets or roadside units.
- If the learned codebook proves stable across datasets, the method could reduce the need to retrain perception models for each new compression setting.
- Real-world channel noise and packet loss may alter the reported acceleration numbers obtained in simulation.
Load-bearing premise
The saliency selector and quantizer keep enough task-relevant information that the downstream perception model still works at the reported accuracy without any retraining or extra tuning.
What would settle it
Run the nuScenes validation set through the full DinoLink pipeline, transmit only the produced indices and priors, decode at the receiver, and measure whether mean average precision stays at or above 32.8 percent.
Figures



read the original abstract
High-precision remote perception is often hindered by the severe bandwidth constraints of Vehicle-to-Everything (V2X) networks. We propose \textit{DinoLink}, a token-centric compression framework that replaces raw pixel streaming with discrete semantic communication for vehicle-cloud collaborative inference. DinoLink employs a dual-sparsity architecture: a saliency-aware selector prunes redundant background tokens, while a Residual Vector Quantization (RVQ) module collapses features into compact codebook indices. By transmitting only lightweight indices and positional priors, DinoLink achieves a $139\times$ bitrate reduction compared to uncompressed transmission while maintaining a competitive 32.8\% mAP on the nuScenes dataset. Deployment simulations further demonstrate a $34.5\times$ acceleration in narrow-band environments, such as LoRa. Our results substantiate DinoLink as a robust, bandwidth-efficient frontend for high-fidelity remote perception in constrained V2X scenarios. The code is publicly available at https://github.com/UGA-MOBILITY-LAB/dino_link.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DinoLink, a token-centric compression framework for bandwidth-constrained collaborative V2X perception. It replaces raw pixel streaming with discrete semantic communication via a dual-sparsity architecture: a saliency-aware selector that prunes redundant background tokens and a Residual Vector Quantization (RVQ) module that collapses features into compact codebook indices. By transmitting only lightweight indices and positional priors, the method claims a 139× bitrate reduction versus uncompressed transmission while achieving 32.8% mAP on nuScenes, plus 34.5× acceleration in narrow-band (e.g., LoRa) simulations. Public code is provided.
Significance. If the central claims are substantiated with clear evaluation protocols, the work could provide a practical frontend for remote perception under severe V2X bandwidth limits. Public code release supports reproducibility.
major comments (1)
- [Evaluation / Experimental Results] The evaluation protocol (likely §4 or the experimental section) must explicitly clarify whether the reported 32.8% mAP uses a frozen downstream perception head identical to the uncompressed baseline or after task-specific fine-tuning/adaptation on the compressed tokens. This detail is load-bearing: fine-tuning would show that the system can be adapted to the quantized stream rather than demonstrating that the saliency-aware selector + RVQ pipeline preserves sufficient semantics without retraining, directly affecting whether the 139× reduction claim demonstrates semantic preservation.
minor comments (1)
- [Abstract] Abstract reports headline numbers (139× reduction, 32.8% mAP, 34.5× acceleration) without referencing baselines, error bars, dataset splits, or ablations; these details should be summarized even in the abstract for immediate context.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for explicit clarification on the evaluation protocol. This is a substantive point that affects interpretation of our semantic-preservation claims, and we will address it directly in revision.
read point-by-point responses
-
Referee: [Evaluation / Experimental Results] The evaluation protocol (likely §4 or the experimental section) must explicitly clarify whether the reported 32.8% mAP uses a frozen downstream perception head identical to the uncompressed baseline or after task-specific fine-tuning/adaptation on the compressed tokens. This detail is load-bearing: fine-tuning would show that the system can be adapted to the quantized stream rather than demonstrating that the saliency-aware selector + RVQ pipeline preserves sufficient semantics without retraining, directly affecting whether the 139× reduction claim demonstrates semantic preservation.
Authors: The reported 32.8% mAP is obtained using a frozen downstream perception head that is identical to the one used for the uncompressed baseline, with no task-specific fine-tuning or adaptation performed on the compressed tokens. This protocol was chosen precisely to isolate the semantic-preservation properties of the saliency-aware selector and RVQ pipeline. We will add an explicit statement of this protocol (including confirmation that the head remains frozen) to the experimental section and to the caption of the relevant result table. revision: yes
Circularity Check
No circularity detected; empirical results presented without reduction to inputs.
full rationale
The abstract and description report measured outcomes (139× bitrate reduction, 32.8% mAP on nuScenes) from the proposed saliency-aware selector and RVQ components, with no equations, fitted parameters renamed as predictions, self-citations, or derivation steps visible. No load-bearing claim reduces by construction to its own inputs; the results are presented as experimental validation on an external dataset rather than tautological restatements of the method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European conference on computer vision. Springer, 2020, pp. 213– 229
2020
-
[3]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,”arXiv preprint arXiv:2010.04159, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[4]
Deep learning with edge computing: A review,
J. Chen and X. Ran, “Deep learning with edge computing: A review,” Proceedings of the IEEE, vol. 107, no. 8, pp. 1655–1674, 2019
2019
-
[5]
Neurosurgeon: Collaborative intelligence between the cloud and mobile edge,
Y . Kang, J. Hauswald, C. Gao, A. Rovinski, T. Mudge, J. Mars, and L. Tang, “Neurosurgeon: Collaborative intelligence between the cloud and mobile edge,”ACM SIGARCH Computer Architecture News, vol. 45, no. 1, pp. 615–629, 2017
2017
-
[6]
Vehicular networking: A survey and tutorial on re- quirements, architectures, challenges, standards and solutions,
G. Karagiannis, O. Altintas, E. Ekici, G. Heijenk, B. Jarupan, K. Lin, and T. Weil, “Vehicular networking: A survey and tutorial on re- quirements, architectures, challenges, standards and solutions,”IEEE communications surveys & tutorials, vol. 13, no. 4, pp. 584–616, 2011
2011
-
[7]
The jpeg still picture compression standard,
G. K. Wallace, “The jpeg still picture compression standard,”Com- munications of the ACM, vol. 34, no. 4, pp. 30–44, 1991
1991
-
[8]
Overview of the h. 264/avc video coding standard,
T. Wiegand, G. J. Sullivan, G. Bjontegaard, and A. Luthra, “Overview of the h. 264/avc video coding standard,”IEEE Transactions on circuits and systems for video technology, vol. 13, no. 7, pp. 560– 576, 2003
2003
-
[9]
Understanding how image quality affects deep neural networks,
S. Dodge and L. Karam, “Understanding how image quality affects deep neural networks,” in2016 eighth international conference on quality of multimedia experience (QoMEX). IEEE, 2016, pp. 1–6
2016
-
[10]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
D. Hendrycks and T. Dietterich, “Benchmarking neural network ro- bustness to common corruptions and perturbations,”arXiv preprint arXiv:1903.12261, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[11]
Distributed deep neural networks over the cloud, the edge and end devices,
S. Teerapittayanon, B. McDanel, and H.-T. Kung, “Distributed deep neural networks over the cloud, the edge and end devices,” in2017 IEEE 37th international conference on distributed computing systems (ICDCS). IEEE, 2017, pp. 328–339
2017
-
[12]
Experimental assessment of communication delay’s impact on connected automated vehicle speed volatility and energy consumption,
W. Li, J. Rios-Torres, B. Wang, and Z. H. Khattak, “Experimental assessment of communication delay’s impact on connected automated vehicle speed volatility and energy consumption,” Communications in Transportation Research, vol. 4, p. 100136, 2024. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S2772424724000192
2024
-
[13]
Dynamicvit: Efficient vision transformers with dynamic token sparsification,
Y . Rao, W. Zhao, B. Liu, J. Lu, J. Zhou, and C.-J. Hsieh, “Dynamicvit: Efficient vision transformers with dynamic token sparsification,”Ad- vances in neural information processing systems, vol. 34, pp. 13 937– 13 949, 2021
2021
-
[14]
Tokenlearner: What can 8 learned tokens do for images and videos?
M. S. Ryoo, A. Piergiovanni, A. Arnab, M. Dehghani, and A. An- gelova, “Tokenlearner: What can 8 learned tokens do for images and videos?”arXiv preprint arXiv:2106.11297, 2021
-
[15]
Soundstream: An end-to-end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasac- chi, “Soundstream: An end-to-end neural audio codec,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 495–507, 2021
2021
-
[16]
High Fidelity Neural Audio Compression
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,”arXiv preprint arXiv:2210.13438, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Neural discrete representation learning,
A. Van Den Oord, O. Vinyalset al., “Neural discrete representation learning,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[18]
Generating diverse high-fidelity images with vq-vae-2,
A. Razavi, A. Van den Oord, and O. Vinyals, “Generating diverse high-fidelity images with vq-vae-2,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[19]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 621–11 631
2020
-
[20]
Vehicle-to-everything (v2x) services supported by lte-based systems and 5g,
S. Chen, J. Hu, Y . Shi, Y . Peng, J. Fang, R. Zhao, and L. Zhao, “Vehicle-to-everything (v2x) services supported by lte-based systems and 5g,”IEEE communications standards magazine, vol. 1, no. 2, pp. 70–76, 2017
2017
-
[21]
Wireless access in vehicular environments,
W. Xiang, J. Gozalvez, Z. Niu, O. Altintas, and E. Ekici, “Wireless access in vehicular environments,”EURASIP Journal on Wireless Communications and Networking, vol. 2009, no. 1, p. 576217, 2009
2009
-
[22]
V2vnet: Vehicle-to-vehicle communication for joint per- ception and prediction,
T.-H. Wang, S. Manivasagam, M. Liang, B. Yang, W. Zeng, and R. Urtasun, “V2vnet: Vehicle-to-vehicle communication for joint per- ception and prediction,” inEuropean conference on computer vision. Springer, 2020, pp. 605–621
2020
-
[23]
Dair-v2x: A large-scale dataset for vehicle- infrastructure cooperative 3d object detection,
H. Yu, Y . Luo, M. Shu, Y . Huo, Z. Yang, Y . Shi, Z. Guo, H. Li, X. Hu, J. Yuanet al., “Dair-v2x: A large-scale dataset for vehicle- infrastructure cooperative 3d object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 21 361–21 370
2022
-
[24]
Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication,
R. Xu, H. Xiang, X. Xia, X. Han, J. Li, and J. Ma, “Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication,” in2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 2583–2589
2022
-
[25]
V2x-vit: Vehicle-to-everything cooperative perception with vision transformer,
R. Xu, H. Xiang, Z. Tu, X. Xia, M.-H. Yang, and J. Ma, “V2x-vit: Vehicle-to-everything cooperative perception with vision transformer,” inEuropean conference on computer vision. Springer, 2022, pp. 107– 124
2022
-
[26]
A wire- less collaborated inference acceleration framework for plant disease recognition,
H. Zhu, X. Huang, H. Gao, M. Jiang, H. Que, and L. Mu, “A wire- less collaborated inference acceleration framework for plant disease recognition,” inInternational Conference on Intelligent Computing. Springer, 2025, pp. 331–341
2025
-
[27]
Wireless collaborative inference acceleration based on distillation for weed detection and instance segmentation,
R. Li, Y . Mo, R. Zhao, H. Gao, H. Que, and L. Mu, “Wireless collaborative inference acceleration based on distillation for weed detection and instance segmentation,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 1847–1854
2025
-
[28]
Roadside cross-camera vehicle tracking combining visual and spatial-temporal information for a cloud control system,
B. Gao, Z. Li, D. Zhang, Y . Liu, J. Chen, and Z. Lv, “Roadside cross-camera vehicle tracking combining visual and spatial-temporal information for a cloud control system,”Journal of Intelligent and Connected Vehicles, vol. 7, no. 2, pp. 129–137, 2024
2024
-
[29]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[30]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022
2021
-
[31]
Perception strategies in low- altitude transportation: Single aircraft autonomous system vs. aircraft- ground-cloud integration system,
Y . Wang, K. Wang, J. Gong, and X. Qu, “Perception strategies in low- altitude transportation: Single aircraft autonomous system vs. aircraft- ground-cloud integration system,”Communications in Transportation Research, vol. 5, p. 100208, 2025. [Online]. Available: https: //www.sciencedirect.com/science/article/pii/S2772424725000484
2025
-
[32]
Emerging properties in self-supervised vision trans- formers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision trans- formers,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 9650–9660
2021
-
[33]
Masked autoencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked autoencoders are scalable vision learners,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16 000–16 009
2022
-
[34]
iBOT: Image BERT Pre-Training with Online Tokenizer
J. Zhou, C. Wei, H. Wang, W. Shen, C. Xie, A. Yuille, and T. Kong, “ibot: Image bert pre-training with online tokenizer,”arXiv preprint arXiv:2111.07832, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger, “Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 11, pp. 12 878–12 895, 2022
2022
-
[36]
Bev- former: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai, “Bev- former: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 3, pp. 2020–2036, 2024
2020
-
[37]
Lossy Image Compression with Compressive Autoencoders
L. Theis, W. Shi, A. Cunningham, and F. Husz ´ar, “Lossy im- age compression with compressive autoencoders,”arXiv preprint arXiv:1703.00395, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
End-to-end optimized image compression,
J. Ball ´e, V . Laparra, and E. P. Simoncelli, “End-to-end optimized image compression,”arXiv preprint arXiv:1611.01704, 2016
-
[39]
Joint autoregressive and hier- archical priors for learned image compression,
D. Minnen, J. Ball ´e, and G. D. Toderici, “Joint autoregressive and hier- archical priors for learned image compression,” inAdvances in Neural Information Processing Systems, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, Eds., vol. 31. Curran Associates, Inc., 2018
2018
-
[40]
Real-time adaptive image compression,
O. Rippel and L. Bourdev, “Real-time adaptive image compression,” inProceedings of the 34th International Conference on Machine Learning - Volume 70, ser. ICML’17. JMLR.org, 2017, p. 2922–2930
2017
-
[41]
Full Resolution Image Compression with Recurrent Neural Networks
G. Toderici, D. Vincent, N. Johnston, S. Hwang, D. Minnen, J. Shor, and M. Covell, “Full resolution image compression with recurrent neural networks,”arXiv preprint arXiv:1608.05148, 08 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[42]
Learned image com- pression with discretized gaussian mixture likelihoods and attention modules,
Z. Cheng, H. Sun, M. Takeuchi, and J. Katto, “Learned image com- pression with discretized gaussian mixture likelihoods and attention modules,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[43]
High-fidelity generative image compression,
F. Mentzer, G. Toderici, M. Tschannen, and E. Agustsson, “High-fidelity generative image compression,”arXiv preprint arXiv:2006.09965, 2020
-
[44]
Taming transformers for high- resolution image synthesis,
P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high- resolution image synthesis,” 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.