Utilizing Cognitive Signals Generated during Human Reading to Enhance Keyphrase Extraction from Microblogs
Pith reviewed 2026-06-26 05:36 UTC · model grok-4.3
The pith
Cognitive signals from human reading improve keyphrase extraction on microblog text, with EEG features yielding the largest gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
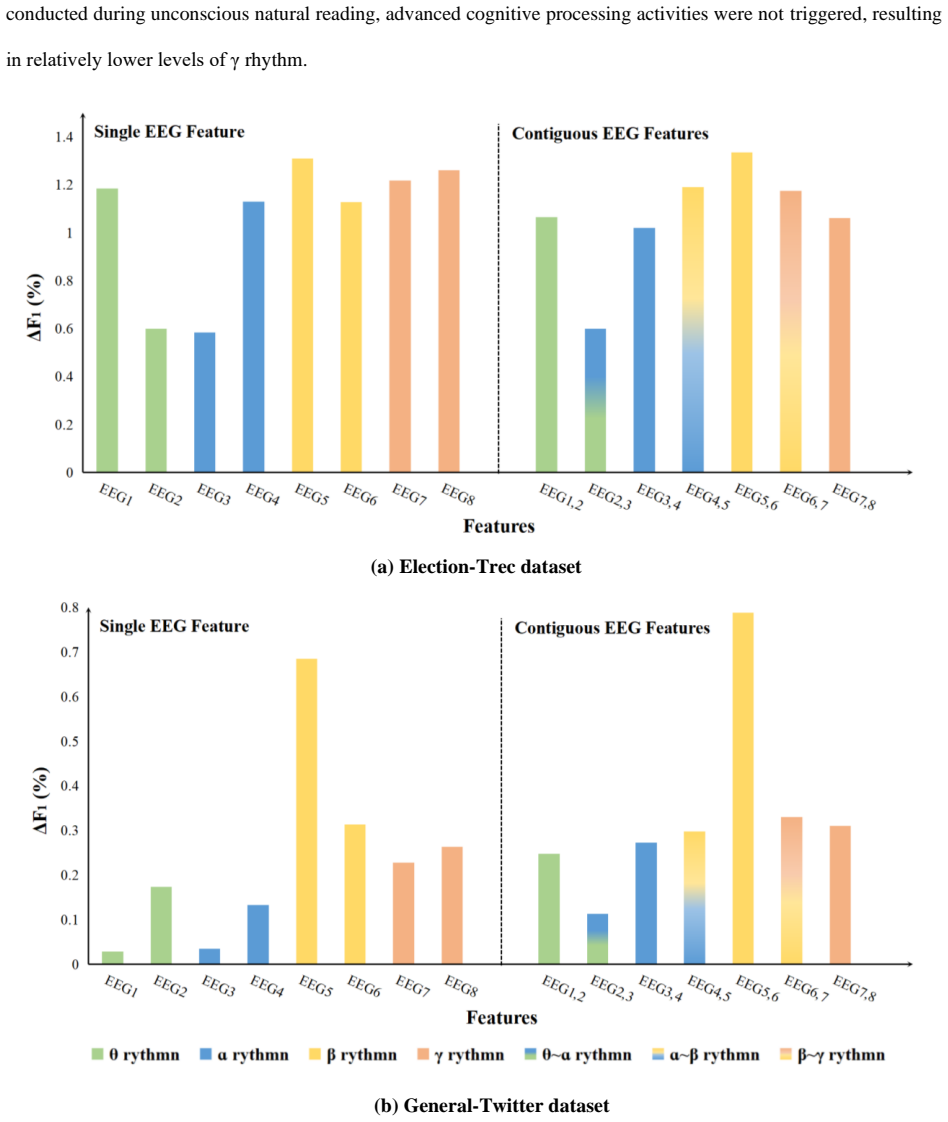
By selecting 8 EEG features and 17 eye-tracking features from reading data and injecting them into the input of the soft-attention layer and the query vectors of the self-attention layer, the models achieve higher keyphrase extraction scores on microblog data. The gains appear regardless of which feature subset or base architecture is used. EEG features alone produce the biggest lift, while the joint use of both signal types yields results that sit between the two separate cases, indicating partial complementarity together with possible overlap or added noise.
What carries the argument
Injection of EEG and eye-tracking features into the attention layers of keyphrase extraction models
If this is right
- Keyphrase extraction models gain from cognitive signals across varied feature sets and architectures.
- EEG features alone deliver larger improvements than eye-tracking features alone.
- Using both signal types together produces performance between the separate cases, pointing to some redundancy.
- Cognitive signals supply usable evidence for identifying salient phrases in microblog text.
Where Pith is reading between the lines
- The same injection approach might be tested on other short-text tasks that rely on detecting reader attention.
- Collecting signals while users actually read microblogs rather than sentences could strengthen the features further.
- If the signals scale, they might lower the amount of labeled microblog data needed to train extraction models.
Load-bearing premise
The features chosen from sentence-level reading data stay informative and undistorted when applied to short, noisy microblog posts inside the same models.
What would settle it
Running the same models on a standard microblog test set and finding that F1 scores do not rise when the cognitive features are added versus when they are withheld.
Figures
read the original abstract
Microblogging platforms generate massive amounts of short, noisy, and dispersed user content, making automatic keyphrase extraction (AKE) an important but challenging task. Prior studies have used eye-tracking signals to improve microblog-based AKE because such signals reflect readers' attention to salient words. However, eye tracking alone is limited by physiological, acquisition, and feature-decoding constraints. To address this issue, we investigate whether electroencephalogram (EEG) signals can complement eye-tracking signals for AKE. Using the ZuCo cognitive language processing corpus, we select 8 EEG features and 17 eye-tracking features and incorporate them into microblog-based AKE models. To reduce possible distortion of cognitive signals by model structures, we inject these features into the input of the soft-attention layer and the query vectors of the self-attention layer. We then evaluate different combinations of cognitive signals across AKE models. The results show that cognitive signals produced during reading consistently improve AKE performance, regardless of feature combinations and model architectures. EEG features bring the largest gains, while combining EEG and eye-tracking features yields performance between the two individual signal types, suggesting partial complementarity but also possible redundancy or noise. These findings indicate that EEG signals provide useful cognitive evidence for microblog-based AKE and that multimodal cognitive signals deserve further investigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that selecting 8 EEG and 17 eye-tracking features from the ZuCo corpus and injecting them into the soft-attention input and self-attention query vectors of neural AKE models yields consistent performance gains on microblog keyphrase extraction, with EEG features producing the largest improvements and the EEG+eye-tracking combination falling in between due to partial complementarity or redundancy.
Significance. If the transfer of ZuCo features proves robust, the result would be significant for cognitive NLP by showing that multimodal reading signals can augment attention-based models on noisy short texts where traditional features struggle; the observation of EEG dominance and possible redundancy between modalities is a concrete, testable contribution that could guide future multimodal signal selection.
major comments (2)
- [Methods / Feature Injection] The central claim requires that the chosen ZuCo features remain predictive of keyphrase salience on microblog text, yet the manuscript provides no correlation analysis, domain-adaptation step, or validation that the 8 EEG + 17 eye-tracking features align informatively with microblog tokens (differing in length, noise, and skimming behavior from ZuCo sentences). This assumption is load-bearing for the reported gains.
- [Abstract / Results] No quantitative results, error bars, statistical tests, baseline details, or data-split information appear even in the experimental summary, so the statements of “consistent improvement” and “largest gains” cannot be evaluated for magnitude or reliability.
minor comments (1)
- [Abstract] The abstract would benefit from a single sentence stating the magnitude of the reported gains (e.g., absolute F1 deltas) to allow readers to gauge practical impact without reading the full results section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods / Feature Injection] The central claim requires that the chosen ZuCo features remain predictive of keyphrase salience on microblog text, yet the manuscript provides no correlation analysis, domain-adaptation step, or validation that the 8 EEG + 17 eye-tracking features align informatively with microblog tokens (differing in length, noise, and skimming behavior from ZuCo sentences). This assumption is load-bearing for the reported gains.
Authors: We acknowledge that the manuscript does not include an explicit correlation analysis or domain-adaptation procedure between ZuCo sentence reading and microblog skimming. The feature selection was based on prior cognitive NLP work demonstrating these signals' relevance to salience detection in English text. The empirical gains from direct injection into attention layers provide the primary evidence of transferability. To address the concern, we will add a dedicated paragraph in the Methods section discussing domain differences (e.g., text length and noise) and their potential impact on feature alignment, along with the rationale for not performing separate adaptation. revision: yes
-
Referee: [Abstract / Results] No quantitative results, error bars, statistical tests, baseline details, or data-split information appear even in the experimental summary, so the statements of “consistent improvement” and “largest gains” cannot be evaluated for magnitude or reliability.
Authors: We agree that the abstract currently presents results only qualitatively. In the revised manuscript we will update the abstract to report concrete metrics (e.g., F1 improvements), note the use of statistical significance testing, and briefly reference the data splits and baseline models employed. revision: yes
Circularity Check
No circularity: empirical feature-injection study with no derivations or self-referential predictions
full rationale
The paper conducts an empirical comparison: it selects 8 EEG and 17 eye-tracking features from the external ZuCo corpus, injects them into attention layers of AKE models, and reports performance gains on microblog data. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim rests on cross-feature and cross-architecture ablation results that are directly measurable against external test sets, rendering the work self-contained without any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Cognitive signals collected during sentence reading remain predictive when applied to microblog text.
- domain assumption Injecting features directly into attention layers does not distort their cognitive information.
Reference graph
Works this paper leans on
-
[1]
https://doi.org/10.1109/TASLP.2021.3120587 Lum, J. A. G., Clark, G. M., Bigelow, F. J., & Enticott, P. G. (2022). Resting state electroencephalography (EEG) correlates with children’s language skills: Evidence from sentence repetition. Brain and Language, 230, 105137. https://doi.org/10.1016/j.bandl.2022.105137 Lundqvist, M., Brincat, S. L., Rose, J., War...
-
[2]
https://doi.org/10.1145/3151759.3151841 Nasar, Z., Jaffry, S. W., & Malik, M. K. (2019). Textual keyword extraction and summarization: State -of-the-art. Information Processing & Management, 56(6), 102088. https://doi.org/10.1016/j.ipm.2019.102088 OpenAI. (2023). GPT-4 Technical Report (arXiv:2303.08774). arXiv. https://doi.org/10.48550/arXiv.2303.08774 P...
-
[3]
https://doi.org/10.18653/v1/N18-1202 Plö chl, M., Ossandó n, J. P., & Kö nig, P. (2012). Combining EEG and eye tracking: Identification, characterization, and correction of eye movement artifacts in electroencephalographic data. Frontiers in Human Neuroscience, 6,
-
[4]
C., Rampichini, C., & Bocci, C
https://doi.org/10.3389/fnhum.2012.00278 Porzio, G. C., Rampichini, C., & Bocci, C. (Eds.). (2021). CLADAG 2021 BOOK OF ABSTRACTS AND SHORT PAPERS: 13th Scientific Meeting of the Classification and Data Analysis Group - Firenze, September 9-11, 2021 (1st ed., Vol. 128). Firenze University Press. https://doi.org/10.36253/978 -88-5518-340-6 Potnis, D., & Ta...
-
[5]
https://doi.org/10.18653/v1/D16-1080 Zhang, Y., & Zhang, C. (2019). Using Human Attention to Extract Keyphrase from Microblog Post. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , 5867 –5872. https://doi.org/10.18653/v1/P19-1588 Zhang, Y., & Zhang, C. (2021). Enhancing keyphrase extraction from microblogs using hu...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/d16-1080 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.