SSI-Policy: Learning Structured Scene Interfaces for Vision-Language Robotic Manipulation
Pith reviewed 2026-06-30 09:59 UTC · model grok-4.3
The pith
A robot-agnostic Structured Scene Interface lets policies learn manipulation tasks from only 10 demonstrations by training on action-free video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a unified RGB-only Structured Scene Interface encoding monocular depth features, language-grounded object layouts, and instruction-conditioned 2D motion trajectories can be trained from action-free video, remains robot-agnostic, and supplies a sufficiently structured representation for a downstream policy to solve vision-language manipulation tasks from few demonstrations.
What carries the argument
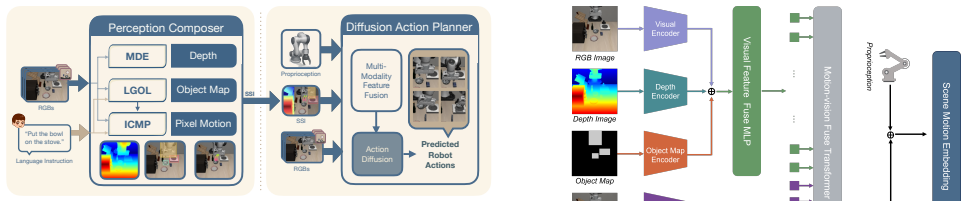
The Structured Scene Interface (SSI), a modular RGB-only intermediate representation that jointly encodes monocular depth, language-grounded layouts, and conditioned motion trajectories to decouple perception from control.
If this is right
- Geometric depth cues and motion trajectories supply complementary information inside the shared interface.
- The robot-agnostic interface supports cross-embodiment transfer on real hardware.
- Performance remains competitive without large-scale external pretraining.
- The modular split allows the interface to be trained separately from the policy on video data.
Where Pith is reading between the lines
- The same interface could be pre-trained on large unlabeled video corpora to further reduce demonstration needs.
- Replacing the monocular depth branch with stereo or depth-sensor input might improve precision on contact-rich tasks.
- The explicit layout and trajectory channels may ease debugging of spatial failures compared with opaque end-to-end models.
Load-bearing premise
The Structured Scene Interface trained on action-free video produces a representation that transfers to a policy without introducing geometric drift or control errors on downstream tasks.
What would settle it
A controlled comparison in which an SSI-trained policy exhibits measurably higher failure rates or larger spatial errors on long-horizon LIBERO tasks than an otherwise identical end-to-end policy trained on the same 10 demonstrations would falsify the transfer claim.
Figures


read the original abstract
Real-world robotic manipulation demands spatial grounding, task-aware reasoning, and precise control. Learning such capabilities becomes particularly challenging in the low-data regime. Prior methods often trade off scalable task-level reasoning and explicit physical structure: video-based approaches can drift geometrically over long horizons, 3D approaches often require depth sensing, and many flow/trajectory interfaces emphasize motion without an explicit RGB-only geometric representation. We introduce SSI-Policy, a modular framework built around a Structured Scene Interface (SSI) -- a unified, RGB-only intermediate representation that jointly encodes monocular depth features, language-grounded object layouts, and instruction-conditioned 2D motion trajectories. Critically, SSI is robot-agnostic and trainable from action-free video, decoupling perception from control so that the downstream policy can learn from few demonstrations. On the LIBERO benchmark with only 10 demonstrations per task, SSI-Policy improves over the strongest prior method by nearly 15\% and remains competitive with 50-demo methods that leverage large-scale external pretraining. Ablations show that geometric and motion cues provide complementary benefits within the shared interface. We further validate on 13 real-world tasks spanning spatial reasoning, cross-embodiment transfer, and contact-rich manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SSI-Policy, a modular framework for vision-language robotic manipulation built around a Structured Scene Interface (SSI). SSI is an RGB-only unified representation that jointly encodes monocular depth features, language-grounded object layouts, and instruction-conditioned 2D motion trajectories. It is designed to be robot-agnostic and trainable from action-free video, decoupling perception from control to enable policy learning from few demonstrations. The central empirical claim is that on the LIBERO benchmark with only 10 demonstrations per task, SSI-Policy improves over the strongest prior method by nearly 15% while remaining competitive with 50-demo methods that use large-scale external pretraining; ablations indicate complementary benefits from geometric and motion cues, with further validation on 13 real-world tasks spanning spatial reasoning, cross-embodiment transfer, and contact-rich manipulation.
Significance. If the performance gains and transfer properties hold under rigorous controls, the work could meaningfully advance low-data robotic manipulation by offering a structured, transferable RGB-only interface that avoids depth sensors and action labels during pretraining. The robot-agnostic design and explicit separation of perception and control are strengths that could support broader applicability across embodiments.
major comments (2)
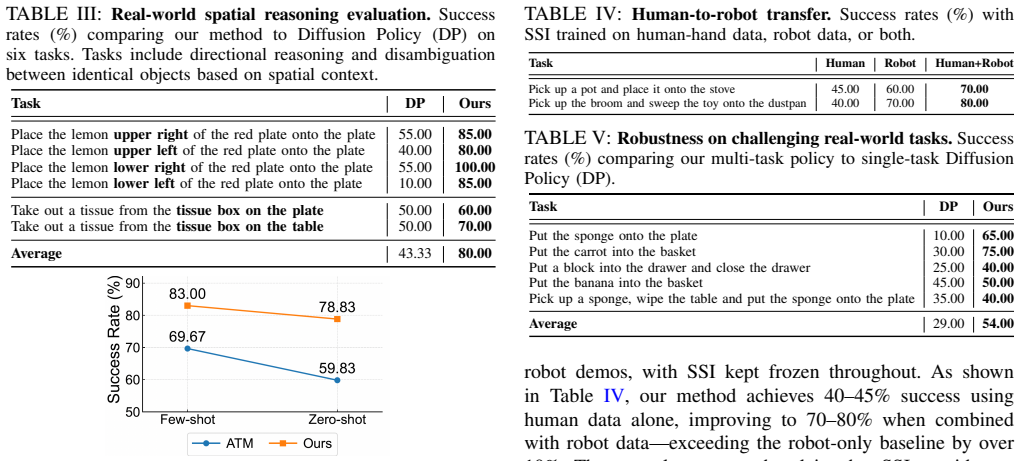
- [Experimental Results / Setup] The provided abstract states performance numbers (nearly 15% gain on LIBERO-10) but supplies no details on training procedure, error bars, data splits, or ablation controls. This absence prevents verification of the central claim; the full manuscript must include these in the experimental section for the result to be load-bearing.
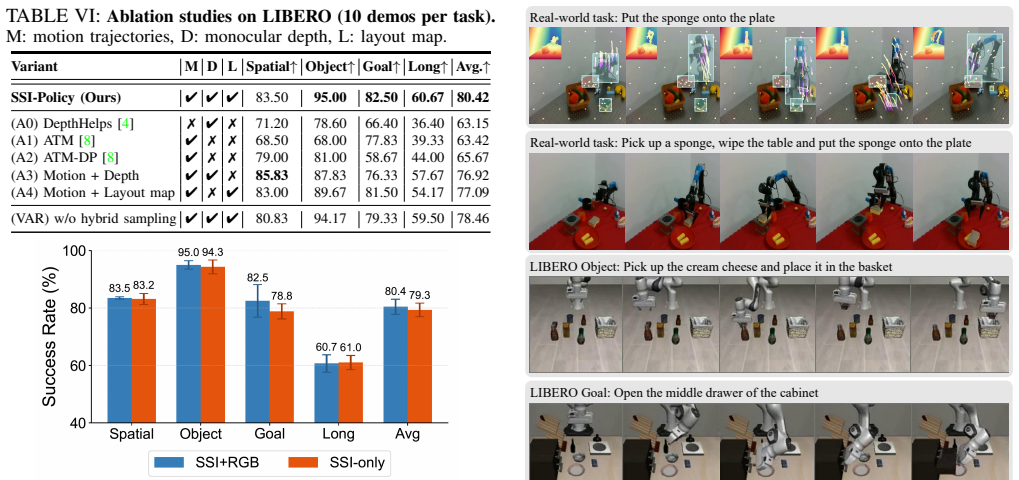
- [Method / Ablations] The weakest assumption—that the SSI trained from action-free video transfers without introducing geometric drift or control errors—requires explicit quantitative support (e.g., drift metrics or ablation on transfer error) in the results or method sections, as this is central to the few-demonstration claim.
minor comments (1)
- Clarify notation for the three SSI components (depth, layouts, trajectories) and ensure consistent use across figures and text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and have revised the manuscript to strengthen the experimental reporting and provide additional quantitative support for the core assumptions.
read point-by-point responses
-
Referee: [Experimental Results / Setup] The provided abstract states performance numbers (nearly 15% gain on LIBERO-10) but supplies no details on training procedure, error bars, data splits, or ablation controls. This absence prevents verification of the central claim; the full manuscript must include these in the experimental section for the result to be load-bearing.
Authors: We agree that the abstract alone is insufficient for verification and that the experimental section must contain these details. The full manuscript already reports training procedures, data splits, and ablation controls in Section 4, but we have revised the experimental section to add explicit error bars across all LIBERO-10 runs, clearer descriptions of the 10-demonstration splits, and consolidated ablation tables with statistical controls. These changes make the central performance claim directly verifiable from the text. revision: yes
-
Referee: [Method / Ablations] The weakest assumption—that the SSI trained from action-free video transfers without introducing geometric drift or control errors—requires explicit quantitative support (e.g., drift metrics or ablation on transfer error) in the results or method sections, as this is central to the few-demonstration claim.
Authors: We acknowledge that explicit quantification of geometric drift during transfer from action-free video is important for supporting the few-demonstration claim. The current manuscript provides indirect evidence through complementary ablations on geometric and motion cues (Section 4.3) and real-world transfer results, but does not include dedicated drift metrics. We have added a new ablation subsection with quantitative transfer-error metrics (e.g., endpoint drift on held-out video sequences and policy performance degradation when SSI is frozen vs. fine-tuned) to directly address this assumption. revision: yes
Circularity Check
No significant circularity
full rationale
The abstract and context present SSI-Policy as a modular framework whose central claims rest on empirical benchmark gains (LIBERO-10) and ablations showing complementary cues, without any equations, fitted parameters renamed as predictions, or load-bearing self-citations. No derivation chain is described that reduces by construction to its inputs; results are framed as external evidence rather than self-referential definitions. The paper is therefore self-contained against the supplied material.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning universal policies via text-guided video generation,
Y . Du,et al., “Learning universal policies via text-guided video generation,” inAdvances in Neural Information Processing Systems, A. Oh,et al., Eds., vol. 36. Curran Associates, Inc., 2023, pp. 9156– 9172
2023
-
[2]
Video pretraining (vpt): Learning to act by watching unlabeled online videos,
B. Baker,et al., “Video pretraining (vpt): Learning to act by watching unlabeled online videos,”Advances in Neural Information Processing Systems, vol. 35, pp. 24 639–24 654, 2022
2022
-
[3]
Dreamitate: Real-world visuomotor policy learning via video generation,
J. Liang,et al., “Dreamitate: Real-world visuomotor policy learning via video generation,” in8th Annual Conference on Robot Learning, 2024
2024
-
[4]
Depth helps: Improving pre-trained rgb-based policy with depth information injection,
X. Pang,et al., “Depth helps: Improving pre-trained rgb-based policy with depth information injection,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 7251–7256
2024
-
[5]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Models,
D. Qu,et al., “SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Models,” inProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025
2025
-
[6]
Perceiver-actor: A multi-task transformer for robotic manipulation,
M. Shridhar,et al., “Perceiver-actor: A multi-task transformer for robotic manipulation,” inProceedings of the 6th Conference on Robot Learning (CoRL), 2022
2022
-
[7]
Visual robotic manipulation with depth-aware pretraining,
W. Wang,et al., “Visual robotic manipulation with depth-aware pretraining,” 2024. [Online]. Available: https://arxiv.org/abs/2401. 09038
2024
-
[8]
Any-point Trajectory Modeling for Policy Learning,
C. Wen,et al., “Any-point Trajectory Modeling for Policy Learning,” inProceedings of Robotics: Science and Systems, Delft, Netherlands, July 2024
2024
-
[9]
Flow as the cross-domain manipulation interface,
M. Xu,et al., “Flow as the cross-domain manipulation interface,” in 8th Annual Conference on Robot Learning, 2024
2024
-
[10]
General flow as foundation affordance for scalable robot learning,
C. Yuan,et al., “General flow as foundation affordance for scalable robot learning,” in8th Annual Conference on Robot Learning, 2024
2024
-
[11]
Flip: Flow- centric generative planning as general-purpose manipulation world model,
C. Gao,et al., “Flip: Flow-centric generative planning as general- purpose manipulation world model,” 2025. [Online]. Available: https://arxiv.org/abs/2412.08261
-
[12]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
B. Liu,et al., “Libero: Benchmarking knowledge transfer for lifelong robot learning,”arXiv preprint arXiv:2306.03310, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Imitating latent policies from observation,
A. Edwards,et al., “Imitating latent policies from observation,” in Proceedings of the 36th International Conference on Machine Learn- ing, ser. Proceedings of Machine Learning Research, K. Chaudhuri and R. Salakhutdinov, Eds., vol. 97. PMLR, 09–15 Jun 2019, pp. 1755–1763
2019
-
[14]
Learning to act without actions,
D. Schmidt and M. Jiang, “Learning to act without actions,” inSecond Agent Learning in Open-Endedness Workshop, 2023
2023
-
[15]
Genie: generative interactive environments,
J. Bruce,et al., “Genie: generative interactive environments,” inPro- ceedings of the 41st International Conference on Machine Learning, ser. ICML’24. JMLR.org, 2024
2024
-
[16]
Latent action pretraining from videos,
S. Ye,et al., “Latent action pretraining from videos,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[17]
Learning to Act Anywhere with Task-centric Latent Ac- tions,
Q. Bu,et al., “Learning to Act Anywhere with Task-centric Latent Ac- tions,” inProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025
2025
-
[18]
Generative visual foresight meets task-agnostic pose estimation in robotic table-top manipulation,
C. Zhang,et al., “Generative visual foresight meets task-agnostic pose estimation in robotic table-top manipulation,” in9th Annual Conference on Robot Learning, 2025
2025
-
[19]
Grounding video models to actions through goal conditioned exploration,
Y . Luo and Y . Du, “Grounding video models to actions through goal conditioned exploration,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[20]
Learning to act from actionless videos through dense correspondences,
P.-C. Ko,et al., “Learning to act from actionless videos through dense correspondences,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[21]
SKIL: Semantic Keypoint Imitation Learning for Generalizable Data-efficient Manipulation,
S. Wang,et al., “SKIL: Semantic Keypoint Imitation Learning for Generalizable Data-efficient Manipulation,” inProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025
2025
-
[22]
Coarse-to-Fine Q-attention: Efficient Learning for Visual Robotic Manipulation via Discretisation,
S. James,et al., “ Coarse-to-Fine Q-attention: Efficient Learning for Visual Robotic Manipulation via Discretisation,” in2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Los Alamitos, CA, USA: IEEE Computer Society, June 2022, pp. 13 729– 13 738
2022
-
[23]
Lift3d: Synthesize 3d training data by lifting 2d gan to 3d generative radiance field,
L. Li,et al., “Lift3d: Synthesize 3d training data by lifting 2d gan to 3d generative radiance field,” inProc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[24]
Frame mining: a free lunch for learning robotic manipulation from 3d point clouds,
M. Liu,et al., “Frame mining: a free lunch for learning robotic manipulation from 3d point clouds,” 2022. [Online]. Available: https://arxiv.org/abs/2210.07442
-
[25]
Polarnet: 3d point clouds for language- guided robotic manipulation,
S. Chen,et al., “Polarnet: 3d point clouds for language- guided robotic manipulation,” 2023. [Online]. Available: https: //arxiv.org/abs/2309.15596
-
[26]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations,
Y . Ze,et al., “3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations,” inProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[27]
Rise: 3d perception makes real-world robot imitation simple and effective,
C. Wang,et al., “Rise: 3d perception makes real-world robot imitation simple and effective,”arXiv preprint arXiv:2404.12281, 2024
-
[28]
Act3d: 3d feature field transformers for multi-task robotic manipulation,
T. Gervet,et al., “Act3d: 3d feature field transformers for multi-task robotic manipulation,” 2023. [Online]. Available: https: //arxiv.org/abs/2306.17817
-
[29]
3D-VLA: A 3D Vision-Language-Action Generative World Model
H. Zhen,et al., “3d-vla: A 3d vision-language-action generative world model,” 2024. [Online]. Available: https://arxiv.org/abs/2403.09631
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan,et al., “Rt-1: Robotics transformer for real-world control at scale,” inarXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
——, “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inarXiv preprint arXiv:2307.15818, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Octo: An Open-Source Generalist Robot Policy,
D. Ghosh,et al., “Octo: An Open-Source Generalist Robot Policy,” inProceedings of Robotics: Science and Systems, Delft, Netherlands, July 2024
2024
-
[33]
OpenVLA: An Open-Source Vision-Language-Action Model
M. Kim,et al., “Openvla: An open-source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
BC-z: Zero-shot task generalization with robotic imitation learning,
E. Jang,et al., “BC-z: Zero-shot task generalization with robotic imitation learning,” in5th Annual Conference on Robot Learning, 2021
2021
-
[35]
S. Reed,et al., “A generalist agent,”arXiv preprint arXiv:2205.06175, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Open x-embodiment: Robotic learning datasets and rt-x models,
A. O’Neill,et al., “Open x-embodiment: Robotic learning datasets and rt-x models,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 6892–6903
2024
-
[37]
Instruction-following agents with multimodal transformer,
H. Liu,et al., “Instruction-following agents with multimodal transformer,” 2023. [Online]. Available: https://arxiv.org/abs/2210. 13431
2023
-
[38]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black,et al., “π0: A vision-language-action flow model for general robot control, 2024,”URL https://arxiv. org/abs/2410.24164
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Palm-e: An embodied multimodal language model,
D. Driess,et al., “Palm-e: An embodied multimodal language model,”
-
[40]
PaLM-E: An Embodied Multimodal Language Model
[Online]. Available: https://arxiv.org/abs/2303.03378
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Otter: A vision-language-action model with text- aware visual feature extraction,
H. Huang,et al., “Otter: A vision-language-action model with text- aware visual feature extraction,”arXiv preprint arXiv:2503.03734, 2025
-
[42]
Copa: General robotic manipulation through spatial constraints of parts with foundation models,
——, “Copa: General robotic manipulation through spatial constraints of parts with foundation models,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024, pp. 9488– 9495
2024
-
[43]
ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
W. Huang,et al., “Rekep: Spatio-temporal reasoning of rela- tional keypoint constraints for robotic manipulation,”arXiv preprint arXiv:2409.01652, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Y . Ju,et al., “Robo-abc: Affordance generalization beyond categories via semantic correspondence for robot manipulation,” 2024. [Online]. Available: https://arxiv.org/abs/2401.07487
-
[45]
An affordance keypoint detection network for robot manipulation,
R. Xu,et al., “An affordance keypoint detection network for robot manipulation,”IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 2870–2877, 2021
2021
-
[46]
L. Yang,et al., “Depth anything v2,”arXiv:2406.09414, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
S. Liu,et al., “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,”arXiv preprint arXiv:2303.05499, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi,et al., “Diffusion policy: Visuomotor policy learning via action diffusion,” inProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[49]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin,et al., “Bert: Pre-training of deep bidirectional transformers for language understanding,” 2019. [Online]. Available: https: //arxiv.org/abs/1810.04805
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[50]
R3m: A universal visual representation for robot manipulation,
S. Nair,et al., “R3m: A universal visual representation for robot manipulation,” inConference on Robot Learning. PMLR, 2023, pp. 892–909
2023
-
[51]
Mail: Improving imitation learning with mamba,
X. Jia,et al., “Mail: Improving imitation learning with mamba,”
-
[52]
Available: https://arxiv.org/abs/2406.08234
[Online]. Available: https://arxiv.org/abs/2406.08234
-
[53]
S. Xu,et al., “Vla-cache: Towards efficient vision-language-action model via adaptive token caching in robotic manipulation,”arXiv preprint arXiv:2502.02175, 2025
-
[54]
Z. Hou,et al., “Diffusion transformer policy,”arXiv preprint arXiv:2410.15959, 2024
-
[55]
TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies
R. Zheng,et al., “Tracevla: Visual trace prompting enhances spatial- temporal awareness for generalist robotic policies,”arXiv preprint arXiv:2412.10345, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Grape: Generalizing robot policy via preference alignment,
Z. Zhang,et al., “Grape: Generalizing robot policy via preference alignment,” 2025. [Online]. Available: https://arxiv.org/abs/2411. 19309
2025
-
[57]
Bridgedata v2: A dataset for robot learning at scale,
H. Walke,et al., “Bridgedata v2: A dataset for robot learning at scale,” inConference on Robot Learning (CoRL), 2023
2023
-
[58]
Multimodal diffusion transformer: Learning versatile behavior from multimodal goals,
M. Reuss,et al., “Multimodal diffusion transformer: Learning versatile behavior from multimodal goals,” inRobotics: Science and Systems, 2024
2024
-
[59]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
M. J. Kim,et al., “Fine-tuning vision-language-action models: Opti- mizing speed and success,”arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
FAST: Efficient Action Tokenization for Vision- Language-Action Models,
K. Pertsch,et al., “FAST: Efficient Action Tokenization for Vision- Language-Action Models,” inProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025
2025
-
[61]
CLIP-RT: Learning Language-Conditioned Robotic Policies from Natural Language Supervision,
G.-C. Kang,et al., “CLIP-RT: Learning Language-Conditioned Robotic Policies from Natural Language Supervision,” inProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.