ReaORE: Reasoning-Guided Progressive Open Relation Extraction Empowered by Large Reasoning Models
Pith reviewed 2026-06-26 05:03 UTC · model grok-4.3
The pith
ReaORE extracts unseen relations more reliably by filtering candidates with multi-aspect reasoning then distinguishing them via comparative reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
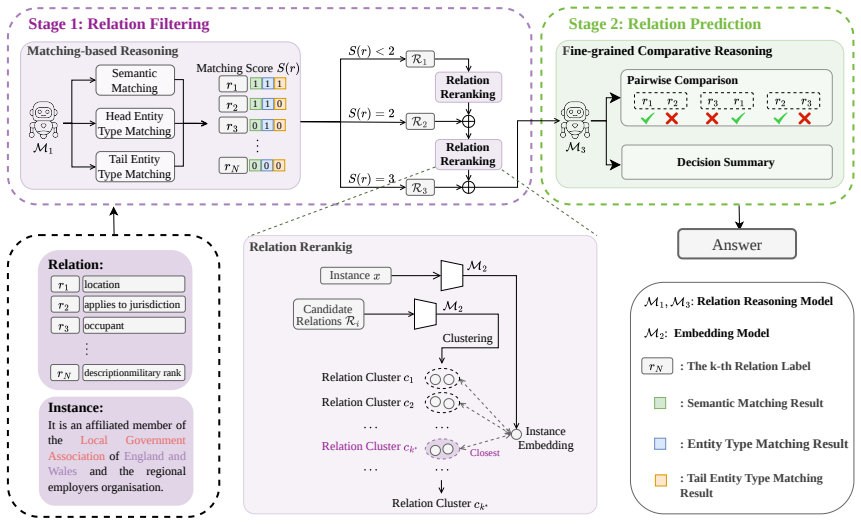
ReaORE performs relation extraction through coarse-to-fine relation reasoning consisting of relation filtering, which reasons over multiple aspects to understand relations and instances, yielding an initial relation set, and further supplements and filters relations via embedding-based similarity to ensure the target relation is included, followed by relation prediction, which aims to predict the target relations from the above set via fine-grained comparative reasoning to better distinguish easily confused relations.
What carries the argument
The two-stage coarse-to-fine reasoning process: relation filtering via multi-aspect reasoning plus embedding similarity, followed by relation prediction via fine-grained comparative reasoning.
If this is right
- Generates explicit labels for unseen relation types unlike clustering methods.
- Achieves stronger discrimination among easily confused relations than direct generation approaches.
- Outperforms existing baselines on two widely used OpenRE datasets.
- Supports more reliable generalization to novel relations in unstructured text.
Where Pith is reading between the lines
- The embedding similarity supplement in the filtering stage may be what prevents reasoning errors from dropping the correct relation.
- The same progressive filtering-plus-comparison pattern could transfer to other NLP tasks that require separating similar categories.
- Gains may scale with the underlying reasoning model's capability, suggesting tests with newer or larger models.
- The method's reliance on both reasoning and embeddings invites experiments that isolate each component's contribution.
Load-bearing premise
Large reasoning models can consistently produce reliable multi-aspect reasoning and comparative reasoning outputs that correctly include the target relation in the filtered set and distinguish easily confused relations without systematic errors or hallucinations.
What would settle it
A held-out test set or error analysis showing that the filtering stage frequently excludes the correct target relation or the prediction stage systematically mislabels pairs of similar relations on the standard OpenRE benchmarks.
Figures



read the original abstract
Open Relation Extraction (OpenRE) requires a model to extract unseen relations between head and tail entities from unstructured text for real-world applications. The core challenge of OpenRE lies in achieving reliable generalization to unseen relation types. Current OpenRE approaches either employ clustering techniques, which cannot generate relation labels and suffer from poor generalization, or rely on direct relation label generation via Large Language Models (LLMs), which lack sufficient discriminative capacity to distinguish easily confused relations. To address these limitations, we propose Reasoning-guided progressive OpenRE (ReaORE), a framework for performing relation extraction through coarse-to-fine relation reasoning. Specifically, ReaORE consists of two key stages: (i) relation filtering, which reasons over multiple aspects to understand relations and instances, yielding an initial relation set, and further supplements and filters relations via embedding-based similarity to ensure the target relation is included; (ii) relation prediction, which aims to predict the target relations from the above set via fine-grained comparative reasoning to better distinguish easily confused relations. Extensive experiments on two widely used OpenRE datasets demonstrate that ReaORE outperforms existing baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ReaORE, a framework for open relation extraction (OpenRE) that performs coarse-to-fine reasoning with large reasoning models. It consists of a relation filtering stage that applies multi-aspect reasoning over relations and instances followed by embedding-based similarity filtering to produce an initial candidate set, and a relation prediction stage that applies fine-grained comparative reasoning to select the target relation from that set. The central claim is that this progressive structure outperforms existing baselines on two widely used OpenRE datasets by improving generalization to unseen relations and discrimination among confused ones.
Significance. If the experimental claims hold after proper validation, the work would be significant for OpenRE because it directly targets the discriminative weakness of direct LLM label generation and the label-less limitation of clustering methods. The explicit use of multi-aspect and comparative reasoning stages offers a concrete mechanism for leveraging LRMs that could generalize beyond the two datasets tested.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): the outperformance claim is stated without any reported metrics, baselines, dataset statistics, or error analysis, so the central empirical claim cannot be evaluated from the manuscript as written.
- [§3.1] §3.1 (Relation Filtering): no quantitative results (e.g., recall of the target relation in the filtered set) or failure-case analysis are supplied for the multi-aspect reasoning plus embedding step; this is load-bearing because the subsequent prediction stage can only succeed if the target is retained.
- [§3.2] §3.2 (Relation Prediction): no ablation or comparative-reasoning quality metrics are given to show that the fine-grained stage actually improves distinction of easily confused relations over a single-pass LLM prompt; without this, gains could be attributable to generic LLM prompting rather than the proposed coarse-to-fine structure.
minor comments (2)
- [§3.1] The description of embedding similarity in filtering lacks the exact similarity function and threshold selection procedure.
- [§3] Prompt templates or example reasoning traces for both stages are not provided, hindering reproducibility.
Simulated Author's Rebuttal
Thank you for the referee's constructive comments. We agree that the manuscript as submitted lacks the quantitative details needed to substantiate the central claims. We will revise the abstract, Sections 3 and 4 to incorporate the requested metrics, ablations, and analyses. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the outperformance claim is stated without any reported metrics, baselines, dataset statistics, or error analysis, so the central empirical claim cannot be evaluated from the manuscript as written.
Authors: We agree that the abstract and experimental section do not contain specific numbers, making evaluation difficult. In the revision we will update the abstract with key F1 scores on the two datasets, explicitly list all baselines, add dataset statistics, and expand Section 4 with an error analysis. revision: yes
-
Referee: [§3.1] §3.1 (Relation Filtering): no quantitative results (e.g., recall of the target relation in the filtered set) or failure-case analysis are supplied for the multi-aspect reasoning plus embedding step; this is load-bearing because the subsequent prediction stage can only succeed if the target is retained.
Authors: We concur that quantitative validation of the filtering stage is essential. The revised manuscript will report recall of the target relation in the filtered candidate set and include failure-case analysis for the multi-aspect reasoning and embedding-based filtering steps. revision: yes
-
Referee: [§3.2] §3.2 (Relation Prediction): no ablation or comparative-reasoning quality metrics are given to show that the fine-grained stage actually improves distinction of easily confused relations over a single-pass LLM prompt; without this, gains could be attributable to generic LLM prompting rather than the proposed coarse-to-fine structure.
Authors: We recognize the need to isolate the benefit of comparative reasoning. The revision will add ablation studies contrasting the full pipeline against a single-pass LLM baseline and will include metrics assessing the quality of the fine-grained stage on confused relations. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes a procedural framework (ReaORE) consisting of two stages—relation filtering via multi-aspect reasoning plus embedding similarity, followed by comparative reasoning for prediction—without any equations, fitted parameters, or mathematical derivations. The claimed outperformance rests on experimental results on standard datasets rather than any self-referential reduction or self-citation chain that would make the method equivalent to its inputs by construction. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Artificial Intelligence Review , volume=
A survey on cutting-edge relation extraction techniques based on language models , author=. Artificial Intelligence Review , volume=. 2025 , publisher=
2025
-
[2]
Proceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies , pages=
Knowledge base population: Successful approaches and challenges , author=. Proceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies , pages=
-
[3]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Improved neural relation detection for knowledge base question answering , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[4]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Actively supervised clustering for open relation extraction , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[5]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
LLM-OREF: An Open Relation Extraction Framework Based on Large Language Models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[6]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
SelfORE: Self-supervised relational feature learning for open relation extraction , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[7]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
A relation-oriented clustering method for open relation extraction , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[8]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Towards a more generalized approach in open relation extraction , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[9]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Deepresearcher: Scaling deep research via reinforcement learning in real-world environments , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[10]
Frontiers of Computer Science , volume=
Large language models for generative information extraction: A survey , author=. Frontiers of Computer Science , volume=. 2024 , publisher=
2024
-
[11]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
When phrases meet probabilities: Enabling open relation extraction with cooperating large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[13]
Transactions of the Association for Computational Linguistics , volume=
Lost in the Middle: How Language Models Use Long Contexts , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , doi=
2024
-
[14]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Never Lost in the Middle: Mastering Long-Context Question Answering with Position-Agnostic Decompositional Training , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2024 , doi=
2024
-
[15]
Nature , volume=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
2025
-
[17]
Qwq: Reflect deeply on the boundaries of the unknown , author=
-
[19]
Academic Emergency Medicine , volume=
Diagnostic reasoning and cognitive error in emergency medicine: Implications for teaching and learning , author=. Academic Emergency Medicine , volume=. 2025 , publisher=
2025
-
[21]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[22]
Publications Manual , year = "1983", publisher =
1983
-
[23]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[24]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[25]
Dan Gusfield , title =. 1997
1997
-
[26]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[27]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[28]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
FewRel: A Large-Scale Supervised Few-Shot Relation Classification Dataset with State-of-the-Art Evaluation , author=. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
2018
-
[29]
Conference on empirical methods in natural language processing , year=
Position-aware attention and supervised data improve slot filling , author=. Conference on empirical methods in natural language processing , year=
-
[30]
The first international conference on language resources and evaluation workshop on linguistics coreference , volume=
Algorithms for scoring coreference chains , author=. The first international conference on language resources and evaluation workshop on linguistics coreference , volume=. 1998 , organization=
1998
-
[31]
V-Measure: A Conditional Entropy-Based External Cluster Evaluation Measure , journal=
Rosenberg, Andrew and Hirschberg, Julia , year=. V-Measure: A Conditional Entropy-Based External Cluster Evaluation Measure , journal=
-
[32]
Journal of classification , volume=
Comparing partitions , author=. Journal of classification , volume=. 1985 , publisher=
1985
-
[36]
2021 , eprint=
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
2021
-
[37]
2019 , eprint=
Decoupled Weight Decay Regularization , author=. 2019 , eprint=
2019
-
[38]
2023 , eprint=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. 2023 , eprint=
2023
-
[39]
S elf ORE : Self-supervised Relational Feature Learning for Open Relation Extraction
Hu, Xuming and Wen, Lijie and Xu, Yusong and Zhang, Chenwei and Yu, Philip. S elf ORE : Self-supervised Relational Feature Learning for Open Relation Extraction. EMNLP 2020. 2020. doi:10.18653/v1/2020.emnlp-main.299
-
[40]
Actively Supervised Clustering for Open Relation Extraction
Zhao, Jun and Zhang, Yongxin and Zhang, Qi and Gui, Tao and Wei, Zhongyu and Peng, Minlong and Sun, Mingming. Actively Supervised Clustering for Open Relation Extraction. ACL 2023. 2023. doi:10.18653/v1/2023.acl-long.273
-
[41]
Amit Bagga and Breck Baldwin. 1998. Algorithms for scoring coreference chains. In The first international conference on language resources and evaluation workshop on linguistics coreference, volume 1, pages 563--566. Citeseer
1998
-
[42]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. arXiv preprint arXiv:2402.03216, 4(5)
Pith/arXiv arXiv 2024
-
[43]
Jose A Diaz-Garcia and Julio Amador Diaz Lopez. 2025. A survey on cutting-edge relation extraction techniques based on language models. Artificial Intelligence Review, 58(9):287
2025
-
[44]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature, 645(8081):633--638
2025
-
[45]
Xu Han, Hao Zhu, Pengfei Yu, Ziyun Wang, Yuan Yao, Zhiyuan Liu, and Maosong Sun. 2018. Fewrel: A large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4803--4809
2018
-
[46]
Junqing He, Kunhao Pan, Xiaoqun Dong, Zhuoyang Song, Yibo Liu, Qianguo Sun, Yuxin Liang, Hao Wang, Enming Zhang, and Jiaxing Zhang. 2024. https://doi.org/10.18653/v1/2024.acl-long.736 Never lost in the middle: Mastering long-context question answering with position-agnostic decompositional training . In Proceedings of the 62nd Annual Meeting of the Associ...
-
[47]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. https://arxiv.org/abs/2106.09685 Lora: Low-rank adaptation of large language models . Preprint, arXiv:2106.09685
Pith/arXiv arXiv 2021
-
[48]
Xuming Hu, Lijie Wen, Yusong Xu, Chenwei Zhang, and Philip S Yu. 2020. Selfore: Self-supervised relational feature learning for open relation extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 3673--3682
2020
-
[49]
Kaixuan Huang, Jiacheng Guo, Zihao Li, Xiang Ji, Jiawei Ge, Wenzhe Li, Yingqing Guo, Tianle Cai, Hui Yuan, Runzhe Wang, and 1 others. 2025. Math-perturb: Benchmarking llms' math reasoning abilities against hard perturbations. arXiv preprint arXiv:2502.06453
arXiv 2025
-
[50]
Lawrence Hubert and Phipps Arabie. 1985. Comparing partitions. Journal of classification, 2:193--218
1985
-
[51]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, and 1 others. 2024. Openai o1 system card. arXiv preprint arXiv:2412.16720
Pith/arXiv arXiv 2024
-
[52]
Heng Ji and Ralph Grishman. 2011. Knowledge base population: Successful approaches and challenges. In Proceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies, pages 1148--1158
2011
-
[53]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. https://arxiv.org/abs/2309.06180 Efficient memory management for large language model serving with pagedattention . Preprint, arXiv:2309.06180
Pith/arXiv arXiv 2023
-
[54]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. https://doi.org/10.1162/tacl_a_00638 Lost in the middle: How language models use long contexts . Transactions of the Association for Computational Linguistics, 12:157--173
-
[55]
Juri Opitz and Sebastian Burst. 2019. Macro f1 and macro f1. arXiv preprint arXiv:1911.03347
arXiv 2019
-
[56]
Thierry Pelaccia, Jonathan Sherbino, Peter Wyer, and Geoff Norman. 2025. Diagnostic reasoning and cognitive error in emergency medicine: Implications for teaching and learning. Academic Emergency Medicine, 32(3):320--326
2025
-
[57]
Andrew Rosenberg and Julia Hirschberg. 2007. V-measure: A conditional entropy-based external cluster evaluation measure. Empirical Methods in Natural Language Processing,Empirical Methods in Natural Language Processing
2007
-
[58]
Qwen Team. 2024. Qwq: Reflect deeply on the boundaries of the unknown
2024
-
[59]
Hongyao Tu, Liang Zhang, Yujie Lin, Xin Lin, Haibo Zhang, Long Zhang, and Jinsong Su. 2025. Llm-oref: An open relation extraction framework based on large language models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 9051--9063
2025
-
[60]
Jiaxin Wang, Lingling Zhang, Wee Sun Lee, Yujie Zhong, Liwei Kang, and Jun Liu. 2024. When phrases meet probabilities: Enabling open relation extraction with cooperating large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13130--13147
2024
-
[61]
Qing Wang, Yuepei Li, Qiao Qiao, Kang Zhou, and Qi Li. 2025 a . Towards a more generalized approach in open relation extraction. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6343--6354
2025
-
[62]
Ziyue Wang, Junde Wu, Linghan Cai, Chang Han Low, Xihong Yang, Qiaxuan Li, and Yueming Jin. 2025 b . Medagent-pro: Towards evidence-based multi-modal medical diagnosis via reasoning agentic workflow. arXiv preprint arXiv:2503.18968
arXiv 2025
-
[63]
Derong Xu, Wei Chen, Wenjun Peng, Chao Zhang, Tong Xu, Xiangyu Zhao, Xian Wu, Yefeng Zheng, Yang Wang, and Enhong Chen. 2024. Large language models for generative information extraction: A survey. Frontiers of Computer Science, 18(6):186357
2024
-
[64]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[65]
Mo Yu, Wenpeng Yin, Kazi Saidul Hasan, Cicero Dos Santos, Bing Xiang, and Bowen Zhou. 2017. Improved neural relation detection for knowledge base question answering. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 571--581
2017
-
[66]
Yuhao Zhang, Victor Zhong, Danqi Chen, Gabor Angeli, and Christopher D Manning. 2017. Position-aware attention and supervised data improve slot filling. In Conference on empirical methods in natural language processing
2017
-
[67]
Jun Zhao, Tao Gui, Qi Zhang, and Yaqian Zhou. 2021. A relation-oriented clustering method for open relation extraction. In Proceedings of the 2021 conference on empirical methods in natural language processing, pages 9707--9718
2021
-
[68]
Jun Zhao, Yongxin Zhang, Qi Zhang, Tao Gui, Zhongyu Wei, Minlong Peng, and Mingming Sun. 2023. Actively supervised clustering for open relation extraction. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4985--4997
2023
-
[69]
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, and Zheyan Luo. 2024. https://doi.org/10.18653/v1/2024.acl-demos.38 L lama F actory: Unified efficient fine-tuning of 100+ language models . In ACL 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.