CoIn: Comprehensive 2D-3D Inpainting with Gaussian Splatting Guidance
Pith reviewed 2026-06-29 01:23 UTC · model grok-4.3
The pith
CoIn connects 2D diffusion inpainting to 3D Gaussian Splatting through a bidirectional multi-stage pipeline to handle both object removal and insertion with flexible masks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
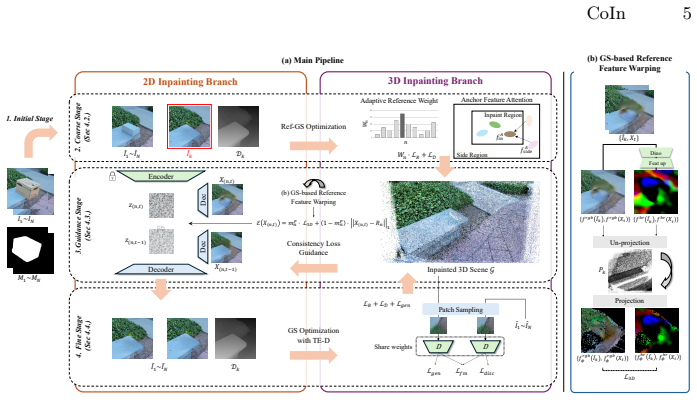
CoIn is a framework that first uses a 2D diffusion model to generate inpainted images with flexible masks, then employs Reference Adaptive GS with Feature Attention to reconstruct a coarse 3D scene, provides geometric guidance back to the diffusion process via GS-based Reference Feature Warping for multi-view consistency, and finally applies a Texture-Enhancing Discriminator to refine photometric realism.
What carries the argument
The multi-stage consistency pipeline consisting of 2D diffusion, Reference Adaptive GS, GS-based Reference Feature Warping, and Texture-Enhancing Discriminator that enables bidirectional information flow between 2D and 3D.
If this is right
- CoIn can perform 3D inpainting for object insertion as well as removal.
- The method works with arbitrary-shaped masks rather than requiring precise multi-view segmentation.
- State-of-the-art performance is achieved on 3D scene inpainting tasks through the bidirectional guidance.
- Multi-view consistency is maintained by using the 3D GS representation to guide 2D inpainting.
Where Pith is reading between the lines
- The pipeline could extend to dynamic scenes if the Gaussian Splatting representation incorporates time information.
- The warping and discriminator stages might adapt to other 3D editing tasks such as relighting or style transfer.
- Evaluation on real captured scenes with natural occlusions would test whether the consistency holds outside controlled settings.
Load-bearing premise
The multi-stage consistency pipeline will produce multi-view consistent results without requiring precise multi-view segmentation masks.
What would settle it
Visible inconsistencies or artifacts across different viewpoints in the inpainted 3D scene when using loose or arbitrary masks on complex real-world scenes would falsify the central claim.
Figures









read the original abstract
3D scene inpainting is essential for reconstructing areas corrupted by occlusions or limited viewpoints. While recent methods leverage Gaussian Splatting (GS) for efficient 3D editing, they often depend on precise multi-view segmentation masks and are inherently constrained to object removal tasks. We propose CoIn, a novel framework that bridges 2D inpainting models and 3DGS through a multi-stage consistency pipeline. Our approach first generates initial inpainted images using a diffusion model, enabling the use of arbitrary-shaped masks and diverse tasks like object insertion. We then introduce Reference Adaptive GS with Feature Attention to reconstruct a coarse 3D scene by adaptively weighing towards a reference view (2D -> 3D). This 3D representation provides geometric guidance to the diffusion process via GS-based Reference Feature Warping, ensuring multi-view consistency (3D -> 2D). Finally, a Texture-Enhancing Discriminator refines the 3D scene to achieve high photometric realism (2D -> 3D). Experiments show that CoIn, effectively leveraging bidirectional information flow, achieves state-of-the-art performance and effectively handles both object removal and object insertion with flexible mask input.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CoIn, a framework for 3D scene inpainting that integrates 2D diffusion models with 3D Gaussian Splatting via a multi-stage bidirectional pipeline: 2D diffusion generates initial inpainted images from arbitrary masks (supporting removal and insertion), Reference Adaptive GS with Feature Attention reconstructs a coarse 3D scene (2D->3D), GS-based Reference Feature Warping provides geometric guidance back to the diffusion process for multi-view consistency (3D->2D), and a Texture-Enhancing Discriminator refines photometric quality (2D->3D). Experiments are reported to demonstrate SOTA performance on both object removal and insertion tasks.
Significance. If the bidirectional consistency mechanism holds, the work would meaningfully extend GS-based editing by relaxing the need for precise multi-view segmentation masks and enabling insertion tasks, which prior methods largely exclude. The pipeline's explicit 2D-3D feedback loop is a clear technical contribution over unidirectional approaches.
minor comments (3)
- The abstract and introduction would benefit from explicit citation of the specific datasets, baselines, and quantitative metrics (e.g., PSNR, LPIPS, or perceptual scores) used to support the SOTA claim, as these are referenced only qualitatively.
- Notation for the Reference Adaptive GS (e.g., how the feature attention weights are computed and normalized) is introduced without an accompanying equation or pseudocode block, which would aid reproducibility.
- Figure captions for the pipeline diagram and qualitative results should include the exact mask types (arbitrary vs. multi-view) and view counts shown to make the consistency claims easier to inspect.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work, the recognition of the bidirectional 2D-3D pipeline as a technical contribution, and the recommendation for minor revision. No major comments were listed in the report.
Circularity Check
No significant circularity
full rationale
The provided abstract and description contain no equations, fitted parameters, predictions, or derivation steps. The method is presented as a multi-stage pipeline (2D diffusion to Reference Adaptive GS to warping to discriminator) whose performance is evaluated empirically. No self-definitional relations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the text. The central claim of multi-view consistency via bidirectional flow is an engineering description rather than a mathematical reduction to its own inputs, making the result self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Spin-nerf: Multiview segmentation and perceptual inpainting with neural radiance fields
Ashkan Mirzaei, Tristan Aumentado-Armstrong, Konstantinos G Derpanis, Jonathan Kelly, Marcus A Brubaker, Gilitschenski, and Alex Levinshtein. Spin-nerf: Multiview segmentation and perceptual inpainting with neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20669–20679, 2023
2023
-
[2]
Imfine: 3d inpainting via geometry-guided multi-view refinement
Zhihao Shi, Dong Huo, Yuhongze Zhou, Yan Min, Juwei Lu, and Xinxin Zuo. Imfine: 3d inpainting via geometry-guided multi-view refinement. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 26694-26703, 2025
2025
-
[3]
Learning 3d geometry and feature consistent gaussian splatting for object removal
Yuxin Wang, Qianyi Wu, Guofeng Zhang, and Dan Xu. Learning 3d geometry and feature consistent gaussian splatting for object removal. In European Conference on Computer Vision, pages 1–17. Springer, 2024
2024
-
[4]
3d gaussian inpainting with depth-guided cross-view consistency
Sheng-Yu Huang, Zi-Ting Chou, and Yu-Chiang Frank Wang. 3d gaussian inpainting with depth-guided cross-view consistency. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 26704–26713, 2025
2025
-
[5]
Structure-from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016
2016
-
[6]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[7]
Gaussian grouping: Segment and edit anything in 3d scenes
Mingqiao Ye, Martin Danelljan, Fisher Yu, and Lei Ke. Gaussian grouping: Segment and edit anything in 3d scenes. In European conference on computer vision, pages 162–179. Springer, 2024
2024
-
[10]
Gaussianeditor: Swift and controllable 3d editing with gaussian splatting
Chen, Yiwen, et al. "Gaussianeditor: Swift and controllable 3d editing with gaussian splatting." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2024
2024
-
[12]
and Kim, T.-K
Kim, J. and Kim, T.-K. , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[13]
FirstName Alpher , title =
-
[14]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[15]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[16]
FirstName Alpher and FirstName Gamow , title =
-
[17]
Computer Vision -- ECCV 2022 , year =
2022
-
[18]
2020 , booktitle=
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis , author=. 2020 , booktitle=
2020
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Scaffold-gs: Structured 3d gaussians for view-adaptive rendering , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[20]
, author=
3D Gaussian splatting for real-time radiance field rendering. , author=. ACM Trans. Graph. , volume=
-
[21]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Imfine: 3d inpainting via geometry-guided multi-view refinement , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Spin-nerf: Multiview segmentation and perceptual inpainting with neural radiance fields , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[23]
European Conference on Computer Vision , pages=
Taming latent diffusion model for neural radiance field inpainting , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[24]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
3d gaussian inpainting with depth-guided cross-view consistency , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[25]
European Conference on Computer Vision , pages=
Learning 3d geometry and feature consistent gaussian splatting for object removal , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mvip-nerf: Multi-view 3d inpainting on nerf scenes via diffusion prior , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[27]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Met3r: Measuring multi-view consistency in generated images , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[28]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Freedom: Training-free energy-guided conditional diffusion model , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[29]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Emerging properties in self-supervised vision transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[30]
arXiv preprint arXiv:2403.10516 , year=
Featup: A model-agnostic framework for features at any resolution , author=. arXiv preprint arXiv:2403.10516 , year=
-
[31]
European conference on computer vision , pages=
Gaussian grouping: Segment and edit anything in 3d scenes , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[32]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Reference-guided controllable inpainting of neural radiance fields , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[33]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
The unreasonable effectiveness of deep features as a perceptual metric , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[34]
Advances in neural information processing systems , volume=
Gans trained by a two time-scale update rule converge to a local nash equilibrium , author=. Advances in neural information processing systems , volume=
-
[35]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Resolution-robust large mask inpainting with fourier convolutions , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[36]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Repaint: Inpainting using denoising diffusion probabilistic models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[37]
Classifier-Free Diffusion Guidance
Ho, Jonathan and Salimans, Tim , title =. arXiv preprint arXiv:2207.12598 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[39]
arXiv preprint arXiv:2307.00407 , year=
Wavepaint: Resource-efficient token-mixer for self-supervised inpainting , author=. arXiv preprint arXiv:2307.00407 , year=
-
[40]
European Conference on Computer Vision , pages=
Brushnet: A plug-and-play image inpainting model with decomposed dual-branch diffusion , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[41]
arXiv preprint arXiv:2312.04831 , year=
Towards Context-Stable and Visual-Consistent Image Inpainting , author=. arXiv preprint arXiv:2312.04831 , year=
-
[42]
European Conference on Computer Vision , pages=
Objectdrop: Bootstrapping counterfactuals for photorealistic object removal and insertion , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[43]
ACM SIGGRAPH 2022 conference proceedings , pages=
Palette: Image-to-image diffusion models , author=. ACM SIGGRAPH 2022 conference proceedings , pages=
2022
-
[44]
arXiv preprint arXiv:2408.08000 , year=
Mvinpainter: Learning multi-view consistent inpainting to bridge 2d and 3d editing , author=. arXiv preprint arXiv:2408.08000 , year=
-
[45]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Editsplat: Multi-view fusion and attention-guided optimization for view-consistent 3d scene editing with 3d gaussian splatting , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[46]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Instant3dit: Multiview inpainting for fast editing of 3d objects , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[47]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Consistdreamer: 3d-consistent 2d diffusion for high-fidelity scene editing , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[48]
DreamFusion: Text-to-3D using 2D Diffusion
Dreamfusion: Text-to-3d using 2d diffusion , author=. arXiv preprint arXiv:2209.14988 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Proceedings of the seventh IEEE international conference on computer vision , volume=
Texture synthesis by non-parametric sampling , author=. Proceedings of the seventh IEEE international conference on computer vision , volume=. 1999 , organization=
1999
-
[50]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Universal guidance for diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[51]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[52]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models , author=. arXiv preprint arXiv:2308.06721 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Proceedings of the AAAI conference on artificial intelligence , volume=
T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[54]
International Conference on Machine Learning , pages=
Loss-guided diffusion models for plug-and-play controllable generation , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[55]
European Conference on Computer Vision , pages=
High-fidelity image inpainting with gan inversion , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[56]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Gaussianeditor: Swift and controllable 3d editing with gaussian splatting , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[57]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Instruct-nerf2nerf: Editing 3d scenes with instructions , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[58]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Nerfiller: Completing scenes via generative 3d inpainting , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[59]
Advances in Neural Information Processing Systems , volume=
Depth anything v2 , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Repurposing diffusion-based image generators for monocular depth estimation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[61]
Advances in neural information processing systems , volume=
Monosdf: Exploring monocular geometric cues for neural implicit surface reconstruction , author=. Advances in neural information processing systems , volume=
-
[62]
Proceedings of the 31st ACM International Conference on Multimedia , pages=
MV-Diffusion: Motion-aware video diffusion model , author=. Proceedings of the 31st ACM International Conference on Multimedia , pages=
-
[63]
and Zhang, K
Wang, T. and Zhang, K. and Shao, Z. and Luo, W. and Stenger, B. and Lu, T. and Kim, T.-K. and Liu, W. and Li, H. , title =. International Journal of Computer Vision (IJCV) , volume =
-
[64]
MVDream: Multi-view Diffusion for 3D Generation
Mvdream: Multi-view diffusion for 3d generation , author=. arXiv preprint arXiv:2308.16512 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Zero-1-to-3: Zero-shot one image to 3d object , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[66]
European Conference on Computer Vision , pages=
Lgm: Large multi-view gaussian model for high-resolution 3d content creation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[67]
arXiv preprint arXiv:2304.10261 , year=
Anything-3d: Towards single-view anything reconstruction in the wild , author=. arXiv preprint arXiv:2304.10261 , year=
-
[68]
and Cao, Z
Ai, H. and Cao, Z. and Lu, H. and Chen, C. and Ma, J. and Zhou, P. and Kim, T.-K. and Hui, P. and Wang, L. , title =. IEEE Transactions on Visualization and Computer Graphics , volume =. 2024 , note =
2024
-
[69]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Structure-from-motion revisited , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[70]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Image-to-image translation with conditional adversarial networks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[71]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Control4d: Efficient 4d portrait editing with text , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[72]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Aurafusion360: Augmented unseen region alignment for reference-based 360deg unbounded scene inpainting , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[73]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Sdxl: Improving latent diffusion models for high-resolution image synthesis , author=. arXiv preprint arXiv:2307.01952 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
SAM 2: Segment Anything in Images and Videos
Sam 2: Segment anything in images and videos , author=. arXiv preprint arXiv:2408.00714 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
arXiv preprint arXiv:2404.11613 , year=
Infusion: Inpainting 3d gaussians via learning depth completion from diffusion prior , author=. arXiv preprint arXiv:2404.11613 , year=
-
[76]
ACM Transactions on Graphics (ToG) , volume=
Tip-editor: An accurate 3d editor following both text-prompts and image-prompts , author=. ACM Transactions on Graphics (ToG) , volume=. 2024 , publisher=
2024
-
[77]
Advances in Neural Information Processing Systems (NIPS) , year =
Kim, Minje and Kim, Tae-Kyun , title =. Advances in Neural Information Processing Systems (NIPS) , year =
-
[78]
Pattern Recognition , volume=
LLDiffusion: Learning degradation representations in diffusion models for low-light image enhancement , author=. Pattern Recognition , volume=. 2025 , publisher=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.