Aurora: A Leverage-Aware Spectral Optimizer
Pith reviewed 2026-06-29 05:22 UTC · model grok-4.3
The pith
Aurora enforces row-uniformity of matrix parameter updates while respecting Muon's polar factor geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Aurora is a spectral optimizer that enforces row-uniformity of matrix parameter updates while respecting Muon's polar factor geometry. It addresses non-uniform row norms in tall matrices without deviating from the polar factor of the momentum matrix, which prior row-normalization techniques do. In pre-training experiments Aurora outperforms Muon, reaches state-of-the-art results among spectral optimizers when combined with existing methods, and shows gains that scale with MLP expansion factor.
What carries the argument
Row normalization step that preserves the polar factor of the momentum matrix while enforcing uniform row norms.
If this is right
- Aurora outperforms Muon on pre-training tasks.
- Combined with existing methods it reaches state-of-the-art results among spectral optimizers.
- Performance gains over Muon increase with MLP expansion factor.
- The method supports effective training of wider MLP layers.
Where Pith is reading between the lines
- The same row-uniformity correction could be tested on other momentum-based matrix factorizations beyond Muon.
- If the observed scaling continues, wider hidden dimensions may become trainable without extra regularization techniques.
- The identified feedback loop may appear in any optimizer that applies matrix polar factors to tall parameter blocks.
Load-bearing premise
That moving the update away from the polar factor of the momentum matrix is undesirable and that preserving this geometry while enforcing row uniformity is both feasible and beneficial.
What would settle it
A controlled pre-training run on a model with large MLP expansion factor in which Aurora fails to outperform Muon or in which a version that drops polar-factor preservation performs better.
Figures

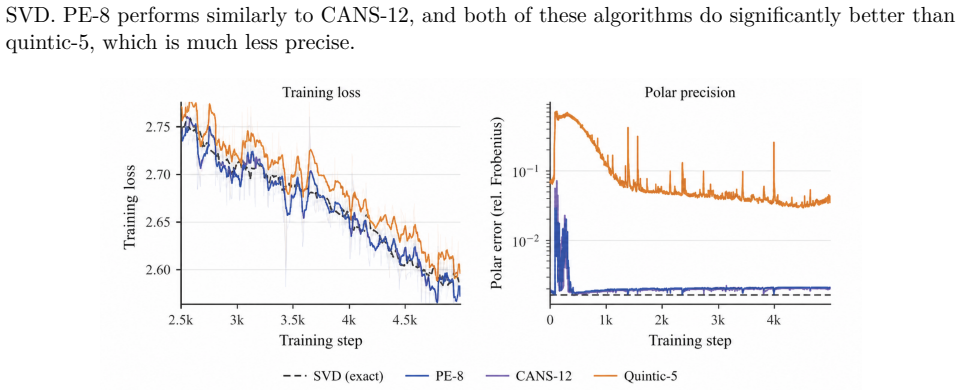
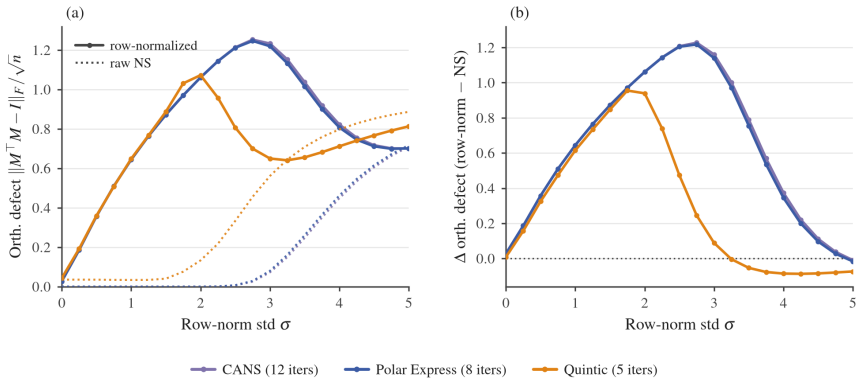









read the original abstract
We show that for tall matrix parameters, like projection matrices in the MLP layers, the Muon update can have row norms that are arbitrarily non-uniform. This can lead to a self-reinforcing feedback loop whereby neurons receive persistently small updates and eventually do not contribute meaningfully to network outputs. This problem is effectively mitigated by an additional row normalization step, but current methods do this in a way that moves the Muon update geometry away from the polar factor of the momentum matrix, which we find is undesirable. We propose Aurora, an optimizer that enforces row-uniformity of matrix parameter updates while respecting Muon's polar factor geometry. Aurora outperforms Muon in our pre-training experiments and, when combined with existing methods, achieves state-of-the-art performance among spectral optimizers on the optimizer track of the modded-nanoGPT speedrun. Additionally, we find that Aurora's empirical gains over Muon scale with the MLP expansion factor, suggesting that Aurora may allow for effective training of very wide MLP layers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies non-uniform row norms in Muon updates for tall matrices (e.g., MLP projections) that can create a self-reinforcing loop of persistently small neuron updates. It proposes Aurora, which computes the polar factor of the momentum matrix and then applies per-row scaling to enforce uniformity while preserving the polar geometry; this is realized via an explicit two-step procedure. Experiments show Aurora outperforming Muon, with gains increasing with MLP expansion factor, and state-of-the-art results among spectral optimizers on the modded-nanoGPT speedrun when combined with existing methods.
Significance. If the central claims hold, the result is significant for spectral optimizers in large-scale training, especially wide MLPs. The paper explicitly credits the two-step construction that isolates geometry preservation, direct ablations separating the row-normalization effect from polar-factor changes, and the falsifiable scaling prediction with expansion factor. These elements strengthen the contribution beyond empirical reporting.
minor comments (3)
- §3.2, Algorithm 1: the two-step procedure is clearly stated, but the pseudocode omits the handling of zero-norm rows after polar factorization; a one-sentence clarification would prevent ambiguity in implementation.
- Table 3: the caption does not state the number of independent runs or whether error bars reflect standard deviation across seeds; this is needed to assess the reported gains over Muon.
- §5.3: the claim that gains 'scale with the MLP expansion factor' is supported by the plotted trend, but the text does not discuss whether the trend continues beyond the tested range or saturates.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work and for recommending minor revision. No specific major comments were provided in the report, so we have no point-by-point responses to address. We are happy to incorporate any minor changes the editor deems necessary based on the overall assessment.
Circularity Check
No significant circularity; derivation is self-contained construction
full rationale
The abstract presents Aurora as an explicit two-step construction (extract polar factor of momentum matrix, then apply per-row scaling) to enforce row uniformity while preserving Muon geometry. No equations, fitted parameters, or self-citations are shown as load-bearing for the central claim. The skeptic note confirms the manuscript supplies an explicit feasible procedure and ablations without reduction to inputs by definition. No self-definitional, fitted-prediction, or self-citation patterns are present in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Laguna M.1/XS.2 Technical Report
Julien Abadji et al. Laguna m.1/xs.2 technical report.arXiv preprint arXiv:2605.27605, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Noah Amsel, David Persson, Christopher Musco, and Robert M. Gower. The polar express: Optimal matrix sign methods and their application to the muon algorithm, 2025
2025
-
[3]
PIQA: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. PIQA: Reasoning about physical commonsense in natural language. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7432–7439, 2020. doi: 10.1609/aaai.v34i05.6239. URL https://ojs.aaai.org/index.php/AAAI/article/view/6239
-
[4]
MuonEq: Balancing Before Orthogonalization with Lightweight Equilibration
Da Chang, Qiankun Shi, Lvgang Zhang, Yu Li, Ruijie Zhang, Yao Lu, Yongxiang Liu, and Ganzhao Yuan. Muoneq: Balancing before orthogonalization with lightweight equilibration. arXiv preprint arXiv:2603.28254, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
DeepSeek-AI. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
2026
-
[8]
RMNP: Row-momentum normalized preconditioning for scalable matrix-based optimization, 2026
Shenyang Deng, Zhuoli Ouyang, Tianyu Pang, Zihang Liu, Ruochen Jin, Shuhua Yu, and Yaoqing Yang. RMNP: Row-momentum normalized preconditioning for scalable matrix-based optimization, 2026
2026
-
[9]
Fernando Hernandez-Garcia, Qingfeng Lan, Parash Rahman, A
Shibhansh Dohare, J. Fernando Hernandez-Garcia, Qingfeng Lan, Parash Rahman, A. Rupam Mahmood, and Richard S. Sutton. Loss of plasticity in deep continual learning.Nature, 632: 768–774, 2024. doi: 10.1038/s41586-024-07711-7
-
[10]
A minimalist optimizer design for LLM pretraining, 2025
Athanasios Glentis, Jiaxiang Li, Andi Han, and Mingyi Hong. A minimalist optimizer design for LLM pretraining, 2025
2025
-
[11]
GLM-5: from Vibe Coding to Agentic Engineering
GLM-5-Team. Glm-5: from vibe coding to agentic engineering, 2026. URLhttps://arxiv. org/abs/2602.15763
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Accelerating newton-schulz iteration for orthogonalization via chebyshev-type polynomials, 2025
Ekaterina Grishina, Matvey Smirnov, and Maxim Rakhuba. Accelerating newton-schulz iteration for orthogonalization via chebyshev-type polynomials, 2025
2025
-
[13]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations, 2021. URLhttps://openreview.net/forum?id=d7KBjmI3GmQ
2021
-
[14]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan. Muon: An optimizer for hidden layers in neural networks, 2024. URLhttps: //kellerjordan.github.io/posts/muon/
2024
-
[15]
modded-nanogpt: Speedrunning the nanogpt baseline, 2024
Keller Jordan, Jeremy Bernstein, Brendan Rappazzo, @fernbear.bsky.social, Boza Vlado, You Jiacheng, Franz Cesista, Braden Koszarsky, and @Grad62304977. modded-nanogpt: Speedrunning the nanogpt baseline, 2024. URLhttps://github.com/KellerJordan/modded-nanogpt
2024
-
[16]
Convergence of muon with newton-schulz, 2026
Gyu Yeol Kim and Min hwan Oh. Convergence of muon with newton-schulz, 2026. URL https://arxiv.org/abs/2601.19156. 20
-
[17]
Kimi k2.5: Visual agentic intelligence, 2026
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, et al. Kimi k2.5: Visual agentic intelligence, 2026
2026
-
[18]
Namhoon Lee, Thalaiyasingam Ajanthan, and Philip H. S. Torr. SNIP: Single-shot network pruning based on connection sensitivity. InInternational Conference on Learning Representations,
-
[19]
URLhttps://openreview.net/forum?id=B1VZqjAcYX
-
[20]
Intrinsic Muon: Spectral Optimization on Riemannian Matrix Manifolds
Yibang Li, Bihari Lal Pandey, Ravi Sah, Andi Han, Cyrus Mostajeran, Pratik Jawanpuria, and Bamdev Mishra. Intrinsic muon: Spectral optimization on riemannian matrix manifolds.arXiv preprint arXiv:2605.09238, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Normuon: Making muon more efficient and scalable, 2025
Zichong Li, Liming Liu, Chen Liang, Weizhu Chen, and Tuo Zhao. Normuon: Making muon more efficient and scalable, 2025. URLhttps://arxiv.org/abs/2510.05491
-
[22]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Dying ReLU and initialization: Theory and numerical examples.Communications in Computational Physics, 28(5):1671–1706,
Lu Lu, Yeonjong Shin, Yanhui Su, and George Em Karniadakis. Dying ReLU and initialization: Theory and numerical examples.Communications in Computational Physics, 28(5):1671–1706,
-
[24]
doi: 10.4208/cicp.OA-2020-0165
-
[25]
SWAN: SGD with normalization and whitening enables stateless LLM training, 2024
Chao Ma, Wenbo Gong, Meyer Scetbon, and Edward Meeds. SWAN: SGD with normalization and whitening enables stateless LLM training, 2024
2024
-
[26]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of EMNLP, 2018
2018
-
[27]
Importanceestimation for neural network pruning
PavloMolchanov, ArunMallya, StephenTyree, IuriFrosio, andJanKautz. Importanceestimation for neural network pruning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11264–11272, 2019. doi: 10.1109/CVPR.2019.01152
-
[28]
Kimi k2.6, 2026
Moonshot AI. Kimi k2.6, 2026. Model card
2026
-
[29]
Contra-muon and soft-muon, May 2026
Nilin. Contra-muon and soft-muon, May 2026. URL https://nilin.github.io/ contra-muon-and-soft-muon/. First version: 2026-05-04; edited: 2026-05-14
2026
-
[30]
Nemotron-CC-v2, 2025
NVIDIA. Nemotron-CC-v2, 2025. URL https://huggingface.co/datasets/nvidia/ Nemotron-CC-v2. Dataset, version 1.0, released 2025-08-18
2025
-
[31]
Nemotron-cc-code-v1
NVIDIA Corporation. Nemotron-cc-code-v1. https://huggingface.co/datasets/nvidia/ Nemotron-CC-Code-v1, December 2025. Hugging Face dataset
2025
-
[32]
The lambada dataset: Word prediction requiring a broad discourse context
Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Ngoc Quan Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The lambada dataset: Word prediction requiring a broad discourse context. InProceedings of ACL, 2016
2016
-
[33]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Guilherme Penedo, Hynek Kydlíček, Loubna Ben Allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro von Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale, 2024. URLhttps://arxiv.org/abs/2406.17557
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Winogrande: An adversarial winograd schema challenge at scale.Proceedings of the AAAI Conference on Artificial Intelligence, 2020
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale.Proceedings of the AAAI Conference on Artificial Intelligence, 2020. 21
2020
-
[35]
Gradient multi-normalization for stateless and scalable LLM training, 2025
Meyer Scetbon, Chao Ma, Wenbo Gong, and Edward Meeds. Gradient multi-normalization for stateless and scalable LLM training, 2025
2025
-
[36]
GLU variants improve transformer, 2020
Noam Shazeer. GLU variants improve transformer, 2020
2020
-
[37]
Le, Geoffrey E
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V. Le, Geoffrey E. Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of- experts layer. InInternational Conference on Learning Representations, 2017
2017
-
[38]
Adamuon: Adaptive muon optimizer, 2025
Chongjie Si, Debing Zhang, and Wei Shen. Adamuon: Adaptive muon optimizer, 2025. URL https://arxiv.org/abs/2507.11005
-
[39]
Arcee trinity large technical report.arXiv preprint arXiv:2602.17004, 2026
Varun Singh, Lucas Krauss, Sami Jaghouar, Matej Sirovatka, Charles Goddard, Fares Obied, Jack Min Ong, Jannik Straube, Aria Harley, Conner Stewart, et al. Arcee trinity large technical report.arXiv preprint arXiv:2602.17004, 2026
-
[40]
The dormant neuron phenomenon in deep reinforcement learning
Ghada Sokar, Rishabh Agarwal, Pablo Samuel Castro, and Utku Evci. The dormant neuron phenomenon in deep reinforcement learning. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 32145– 32168. PMLR, 2023. URLhttps://proceedings.mlr.press/v202/sokar23a.html
2023
-
[41]
Rnj-1, 2025
Ashish Vaswani, Mike Callahan, Adarsh Chaluvaraju, Aleksa Gordić, Devaansh Gupta, Yash Jain, Divya Mansingka, Philip Monk, Khoi Nguyen, Mohit Parmar, Michael Pust, Tim Romanski, Peter Rushton, Ali Shehper, Divya Shivaprasad, Somanshu Singla, Kurt Smith, Saurabh Srivastava, Anil Thomas, Alok Tripathy, Yash Vanjani, Ameya Velingker, and Essential AI. Rnj-1,...
2025
-
[42]
Picking winning tickets before training by preserving gradient flow
Chaoqi Wang, Guodong Zhang, and Roger Grosse. Picking winning tickets before training by preserving gradient flow. InInternational Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=SkgsACVKPH
2020
-
[43]
SRON: State-free LLM training via row-wise gradient normalization, 2025
Zhenrui Wen, Yilei Shi, Jipeng Wang, Ping Luo, Liang Qiao, Dongsheng Li, and Tianxiang Sun. SRON: State-free LLM training via row-wise gradient normalization, 2025. URLhttps: //openreview.net/forum?id=BtQLBWr6zI
2025
-
[44]
On the width scaling of neural optimizers under matrix operator norms i: Row/column normalization and hyperparameter transfer, 2026
Ruihan Xu, Jiajin Li, and Yiping Lu. On the width scaling of neural optimizers under matrix operator norms i: Row/column normalization and hyperparameter transfer, 2026
2026
-
[45]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, 2019. doi: 10.18653/v1/P19-1472. URLhttps://aclanthology.org/P19-1472
-
[46]
UltraData-Math, 2026
Chuyue Zhou, Hongya Lyu, Xinle Lin, Hengyu Zhao, Junshao Guo, Xueren Zhang, Shuaikang Xue, Qiang Ma, Jie Zhou, Yudong Wang, and Zhiyuan Liu. UltraData-Math, 2026. URL https://huggingface.co/datasets/openbmb/UltraData-Math. A U-NorMuon Ablation Study We ablate all the modifications U-NorMuon applies onto NorMuon individually. We use the term statefulto ref...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.