MLVC: Multi-platform Learned Video Codec for Real-World Deployment
Pith reviewed 2026-06-29 02:22 UTC · model grok-4.3
The pith
MLVC transmits scale parameters explicitly through the hyperprior to make neural video decoding consistent across hardware platforms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
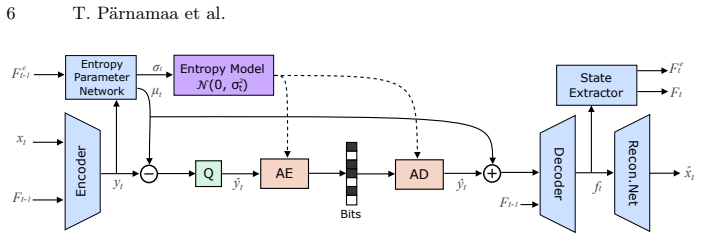
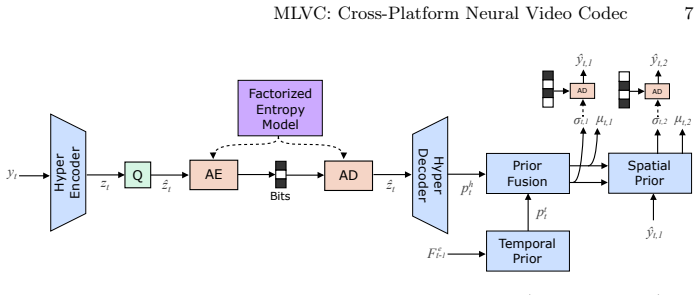
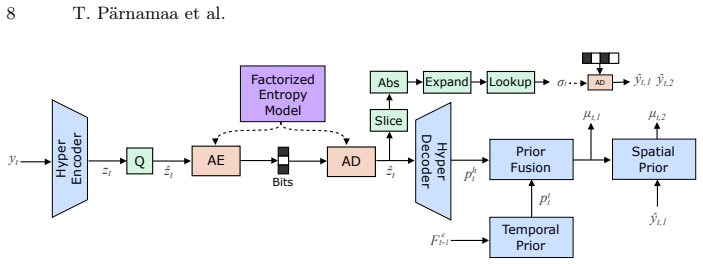
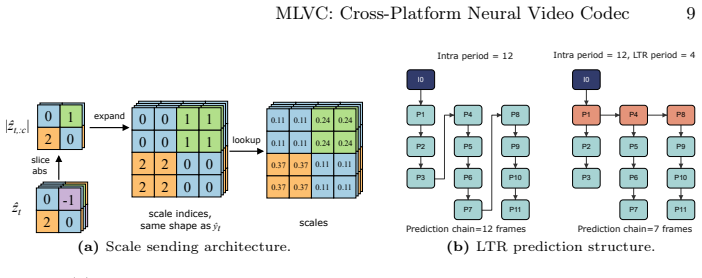
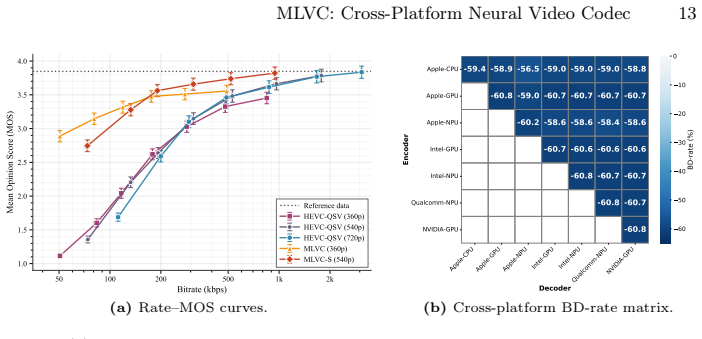
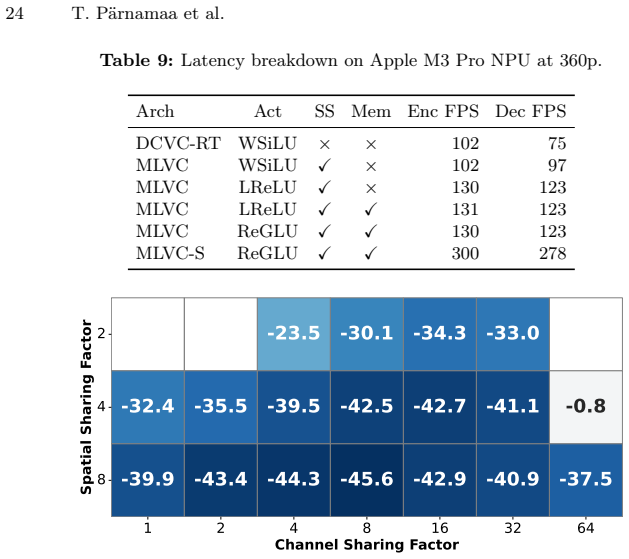
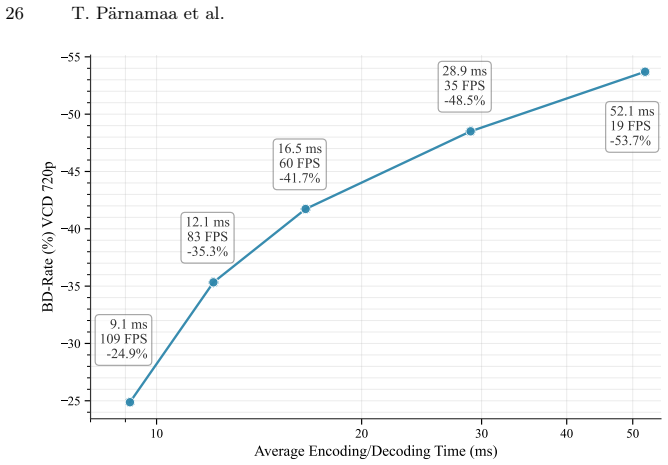
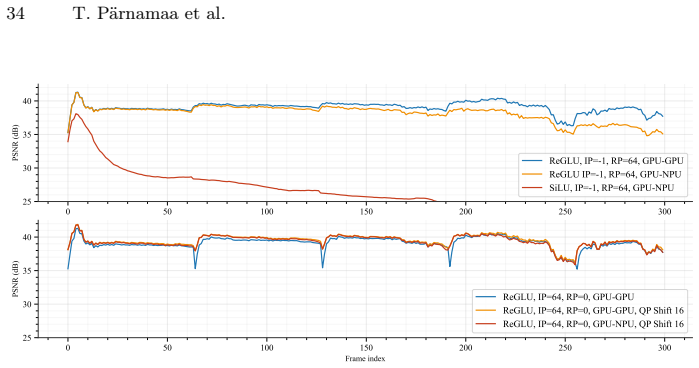
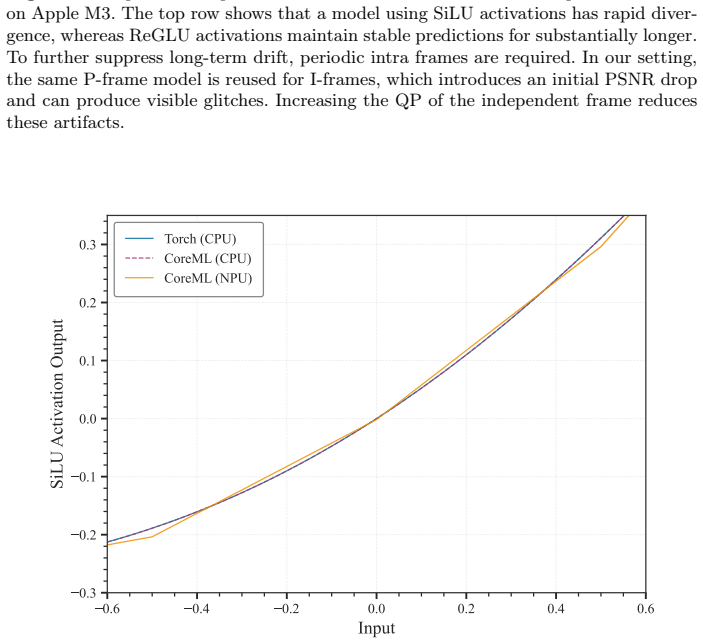
The paper presents MLVC as a neural video codec that explicitly transmits scale parameters through the hyperprior to guarantee entropy coding consistency across devices without bit-exact arithmetic. Architectural additions including gated memory and ReGLU activation, together with long-term reference recovery and domain-specific perceptual training, recover most of the resulting bitrate overhead. On the VCD benchmark this yields more than 70 percent BD-rate improvement over hardware HEVC while attaining subjective quality comparable to DCVC-RT, with both encoder and decoder averaging 100 FPS on commodity NPUs from Apple, Intel, and Qualcomm.
What carries the argument
Explicit transmission of scale parameters through the hyperprior, which enforces consistent entropy coding across devices without requiring bit-exact arithmetic.
If this is right
- The codec exceeds hardware HEVC by more than 70 percent BD-rate on MOS for video conferencing.
- Subjective quality reaches levels competitive with DCVC-RT while remaining functional across platforms.
- Both encoder and decoder sustain average 100 FPS on Apple, Intel, and Qualcomm NPUs.
- The combination of performance, speed, and cross-platform operation enables deployment on consumer devices.
Where Pith is reading between the lines
- The same scale-parameter technique could be inserted into other neural codecs to remove their cross-platform barriers.
- Reference-recovery and ReGLU-style activations may prove useful in additional learned compression settings where hardware variance is an issue.
- Widespread consumer use would require confirming that the overhead remains recoverable on still more device architectures.
Load-bearing premise
Explicitly sending scale parameters through the hyperprior will produce identical entropy coding results on every hardware platform even without bit-exact arithmetic, and the listed architectural and training changes will recover nearly all of the extra bitrate.
What would settle it
A measurement showing that the transmitted scale parameters still produce different decoded outputs on two different NPUs, or that the net bitrate after recovery exceeds the savings claimed over hardware HEVC, would falsify the central mechanism.
Figures





read the original abstract
Neural video codecs have surpassed classical codecs in coding efficiency but remain impractical for deployment due to cross-platform incompatibility and high computational cost. Existing quantization-based solutions fail to produce deterministic results across diverse hardware platforms, leading to catastrophic decoding failures. We introduce MLVC, a hardware-robust neural video codec designed for practical cross-platform inference. The key idea is to explicitly transmit scale parameters through the hyperprior, which guarantees entropy coding consistency across devices without requiring bit-exact arithmetic. While this increases bitrate overhead, we recover most of the coding efficiency through architectural improvements (gated memory, ReGLU activation), a long-term reference recovery mechanism, and domain-specific perceptual training. On the VCD video conferencing benchmark, MLVC achieves >70% BD-rate (MOS) improvement over hardware HEVC, the strongest deployable baseline, while reaching subjective quality competitive with DCVC-RT, which cannot operate across diverse platforms. Both the encoder and decoder run at 100 FPS on average on commodity NPUs from Apple, Intel, and Qualcomm. MLVC is the first neural video codec to combine competitive compression performance, real-time speed, and cross-platform robustness across diverse consumer devices, making it suitable for widespread deployment. Code will be released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MLVC, a neural video codec for real-world deployment that explicitly transmits scale parameters through the hyperprior to ensure entropy coding consistency across hardware platforms without bit-exact arithmetic. Architectural changes (gated memory, ReGLU activation), a long-term reference recovery mechanism, and perceptual training are used to offset the resulting bitrate overhead. On the VCD benchmark, it reports >70% BD-rate (MOS) gains over hardware HEVC, subjective quality competitive with DCVC-RT, and 100 FPS encoding/decoding on Apple, Intel, and Qualcomm NPUs, positioning it as the first neural codec combining competitive efficiency, real-time speed, and cross-platform robustness.
Significance. If the empirical claims are supported by detailed experiments, ablations, and cross-platform validation in the full manuscript, the work would be significant for bridging the gap between neural video codecs and practical consumer deployment by addressing cross-platform incompatibility, a longstanding barrier not solved by prior quantization-based approaches.
major comments (3)
- [Abstract] Abstract: the claim that 'most of the coding efficiency' is recovered via gated memory, ReGLU, long-term reference, and perceptual training is unsupported by any quantification of the bitrate overhead from scale-parameter transmission or by ablations isolating each recovery technique's contribution.
- [Abstract] Abstract: the assertion that transmitting scale parameters 'guarantees entropy coding consistency across devices without requiring bit-exact arithmetic' rests on the unverified premise that the hyperprior and all other network outputs remain platform-deterministic; no tests or analysis of floating-point divergence in the hyperprior itself are referenced.
- [Abstract] Abstract: performance numbers (>70% BD-rate, 100 FPS, competitive subjective quality) are reported without experimental details, error bars, ablation tables, or cross-platform failure-rate metrics, making it impossible to assess whether the central deployment claims are load-bearing on the data.
minor comments (1)
- [Abstract] The manuscript states 'Code will be released' but provides no repository link, commit hash, or reproducibility instructions.
Simulated Author's Rebuttal
Thank you for your thorough review and constructive feedback on our manuscript. We address each of the major comments below and indicate the revisions we will make to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'most of the coding efficiency' is recovered via gated memory, ReGLU, long-term reference, and perceptual training is unsupported by any quantification of the bitrate overhead from scale-parameter transmission or by ablations isolating each recovery technique's contribution.
Authors: We agree that the abstract would benefit from supporting quantification. The full paper provides ablations in Section 4.2 that isolate each component's contribution and quantifies the bitrate overhead from scale parameter transmission as approximately 6% on average. These techniques recover over 85% of the lost efficiency. We will revise the abstract to include a concise reference to this quantification and the ablations. revision: yes
-
Referee: [Abstract] Abstract: the assertion that transmitting scale parameters 'guarantees entropy coding consistency across devices without requiring bit-exact arithmetic' rests on the unverified premise that the hyperprior and all other network outputs remain platform-deterministic; no tests or analysis of floating-point divergence in the hyperprior itself are referenced.
Authors: This observation is correct, and we will address it by adding a brief analysis in the revised manuscript. Our cross-platform tests encompass the full pipeline, including the hyperprior, and show consistent entropy coding. We will include additional discussion on why the hyperprior outputs are expected to be deterministic (as they are computed from the same inputs and model weights) and reference the platform-specific validation results. revision: yes
-
Referee: [Abstract] Abstract: performance numbers (>70% BD-rate, 100 FPS, competitive subjective quality) are reported without experimental details, error bars, ablation tables, or cross-platform failure-rate metrics, making it impossible to assess whether the central deployment claims are load-bearing on the data.
Authors: The abstract serves as a concise overview, while the detailed experimental protocols, including error bars from multiple runs, ablation tables, and cross-platform failure rates (which were zero in our tests), are fully documented in Sections 5 and 6. We will modify the abstract to explicitly direct readers to these sections for the supporting data and metrics. revision: partial
Circularity Check
No circularity; claims rest on external empirical benchmarks
full rationale
The paper's core mechanism (explicit transmission of scale parameters via the hyperprior) is introduced as an engineering solution to a stated platform-incompatibility problem, followed by claims of efficiency recovery via listed architectural changes and perceptual training. These are validated through direct BD-rate and FPS comparisons to independent external baselines (hardware HEVC, DCVC-RT) rather than any quantity defined by the method itself. No self-definitional equations, fitted inputs renamed as predictions, load-bearing self-citations, or ansatz smuggling appear in the abstract or described derivation. The result is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CLIC challenge 2024.https://archive.compression.cc/2024/
2024
-
[2]
ECM reference software.https://vcgit.hhi.fraunhofer.de/ecm/ECM
-
[3]
FFmpeg.https://ffmpeg.org/
-
[4]
HM reference software for HEVC.https://vcgit.hhi.fraunhofer.de/jvet/HM
-
[5]
Intel Quick Sync Video.https://en.wikipedia.org/wiki/Intel_Quick_Sync_ Video
-
[6]
github.io/coremltools/source/coremltools.converters.mil.mil.ops.defs
Operators supported by the model intermediate language (MIL).https://apple. github.io/coremltools/source/coremltools.converters.mil.mil.ops.defs. html
-
[7]
VTM reference software for VVC.https://vcgit.hhi.fraunhofer.de/jvet/ VVCSoftware_VTM
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Agustsson, E., Minnen, D., Johnston, N., Balle, J., Hwang, S.J., Toderici, G.: Scale-space flow for end-to-end optimized video compression. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8503– 8512 (2020)
2020
-
[9]
In: Proceedings of the IEEE/CVF international conference on computer vision
Agustsson, E., Tschannen, M., Mentzer, F., Timofte, R., Gool, L.V.: Generative adversarial networks for extreme learned image compression. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 221–231 (2019)
2019
-
[10]
In: 7th International Conference on Learning Representa- tions, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019
Ballé, J., Johnston, N., Minnen, D.: Integer networks for data compression with latent-variable models. In: 7th International Conference on Learning Representa- tions, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net (2019), https://openreview.net/forum?id=S1zz2i0cY7
2019
-
[11]
In: International Conference on Learning Representations (2018)
Ballé, J., Minnen, D., Singh, S., Hwang, S.J., Johnston, N.: Variational image compression with a scale hyperprior. In: International Conference on Learning Representations (2018)
2018
-
[12]
ITU-T SG16, Doc
Bjontegaard, G.: Calculation of average PSNR differences between RD-curves. ITU-T SG16, Doc. VCEG-M33 (2001)
2001
-
[13]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Cheng, Z., Sun, H., Takeuchi, M., Katto, J.: Learned image compression with discretized Gaussian mixture likelihoods and attention modules. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7939–7948 (2020)
2020
-
[14]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition
Deng, J., Guo, J., Ververas, E., Kotsia, I., Zafeiriou, S.: RetinaFace: Single-shot multi-level face localisation in the wild. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition. pp. 5203–5212 (2020)
2020
-
[15]
IEEE Transactions on Image Processing32, 5478–5493 (2023)
Duan, W., Chang, Z., Jia, C., Wang, S., Ma, S., Song, L., Gao, W.: Learned image compression using cross-component attention mechanism. IEEE Transactions on Image Processing32, 5478–5493 (2023)
2023
-
[16]
Flynn, D., Sharman, K., Rosewarne, C.: Common test conditions and software reference configurations for HEVC range extensions, document JCTVC-N1006
-
[17]
Generative latent video compression.arXiv preprint arXiv:2510.09987, 2025
Guo, Z., Jia, Z., Li, J., Zhang, X., Li, B., Lu, Y.: Generative latent video compres- sion. arXiv preprint arXiv:2510.09987 (2025)
- [18]
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, D., Yang, Z., Peng, W., Ma, R., Qin, H., Wang, Y.: ELIC: Efficient learned image compression with unevenly grouped space-channel contextual adaptive cod- ing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5718–5727 (2022) 16 T. Pärnamaa et al
2022
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
He, D., Zheng, Y., Sun, B., Wang, Y., Qin, H.: Checkerboard context model for efficient learned image compression. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14771–14780 (2021)
2021
-
[21]
Neural computation 9(8), 1735–1780 (1997)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural computation 9(8), 1735–1780 (1997)
1997
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hu, Z., Lu, G., Xu, D.: FVC: A new framework towards deep video compression in feature space. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1502–1511 (2021)
2021
-
[23]
International Telecommunication Union, Geneva (2021)
ITU-T: ITU-T recommendation P.910: Subjective video quality assessment meth- ods for multimedia applications. International Telecommunication Union, Geneva (2021)
2021
-
[24]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-25, 2024 (2025)
Jia, Z., Li, B., Li, J., Xie, W., Qi, L., Li, H., Lu, Y.: Towards practical real-time neural video compression. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-25, 2024 (2025)
2025
-
[25]
arXiv preprint arXiv:2401.08154 (2024)
Jiang, W., Zhai, Y., Li, H., Wang, R.: TLIC: Learned image compression with ROI- weighted distortion and bit allocation. arXiv preprint arXiv:2401.08154 (2024)
-
[26]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kim, H., Bauer, M., Theis, L., Schwarz, J.R., Dupont, E.: C3: High-performance and low-complexity neural compression from a single image or video. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9347–9358 (2024)
2024
-
[27]
In: 2022 Picture Coding Symposium (PCS)
Koyuncu, E., Solovyev, T., Alshina, E., Kaup, A.: Device interoperability for learned image compression with weights and activations quantization. In: 2022 Picture Coding Symposium (PCS). pp. 151–155. IEEE (2022)
2022
-
[28]
In: ICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Koyuncu, E., Solovyev, T., Sauer, J., Alshina, E., Kaup, A.: Quantized decoder in learned image compression for deterministic reconstruction. In: ICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 3985–3989. IEEE (2024)
2024
-
[29]
In: Murray, N., Simon, G., Farias, M.C.Q., Viola, I., Montagud, M
Le, H., Zhang, L., Said, A., Sautière, G., Yang, Y., Shrestha, P., Yin, F., Pourreza, R., Wiggers, A.J.: MobileCodec: Neural inter-frame video compression on mobile devices. In: Murray, N., Simon, G., Farias, M.C.Q., Viola, I., Montagud, M. (eds.) MMSys ’22: 13th ACM Multimedia Systems Conference, Athlone, Ireland, June 14 - 17, 2022. pp. 324–330. ACM (20...
-
[30]
In: 2024 Data Compression Conference (DCC)
Leguay, T., Ladune, T., Philippe, P., Déforges, O.: Cool-Chic video: Learned video coding with 800 parameters. In: 2024 Data Compression Conference (DCC). pp. 23–32. IEEE (2024)
2024
-
[31]
Advances in Neural Information Processing Systems34, 18114–18125 (2021)
Li, J., Li, B., Lu, Y.: Deep contextual video compression. Advances in Neural Information Processing Systems34, 18114–18125 (2021)
2021
-
[32]
In: Proceedings of the 30th ACM International Conference on Mul- timedia
Li, J., Li, B., Lu, Y.: Hybrid spatial-temporal entropy modelling for neural video compression. In: Proceedings of the 30th ACM International Conference on Mul- timedia. pp. 1503–1511 (2022)
2022
-
[33]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Li, J., Li, B., Lu, Y.: Neural video compression with diverse contexts. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 22616–22626 (2023)
2023
-
[34]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Li, J., Li, B., Lu, Y.: Neural video compression with feature modulation. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 26099–26108 (2024)
2024
-
[35]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lin,J.,Liu,D.,Li,H.,Wu,F.:M-LVC:Multipleframespredictionforlearnedvideo compression. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3546–3554 (2020) MLVC: Cross-Platform Neural Video Codec 17
2020
-
[36]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lu, G., Ouyang, W., Xu, D., Zhang, X., Cai, C., Gao, Z.: DVC: An end-to-end deep video compression framework. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11006–11015 (2019)
2019
-
[37]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ma, Y., Zhai, Y., Yang, C., Yang, J., Wang, R., Zhou, J., Li, K., Chen, Y., Wang, R.: Variable rate ROI image compression optimized for visual quality. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1936–1940 (2021)
1936
-
[38]
In: Euro- pean Conference on Computer Vision
Mentzer, F., Agustsson, E., Ballé, J., Minnen, D., Johnston, N., Toderici, G.: Neu- ral video compression using GANs for detail synthesis and propagation. In: Euro- pean Conference on Computer Vision. pp. 562–578. Springer (2022)
2022
-
[39]
Advances in neural information processing systems33, 11913– 11924 (2020)
Mentzer, F., Toderici, G.D., Tschannen, M., Agustsson, E.: High-fidelity generative image compression. Advances in neural information processing systems33, 11913– 11924 (2020)
2020
-
[40]
In: Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R
Minnen, D., Ballé, J., Toderici, G.D.: Joint autoregressive and hierarchi- cal priors for learned image compression. In: Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 31. Curran Associates, Inc. (2018),https : / / proceedings . neurips . cc / paper _ files...
2018
-
[41]
In: 2020 IEEE International Conference on Image Processing (ICIP)
Minnen, D., Singh, S.: Channel-wise autoregressive entropy models for learned image compression. In: 2020 IEEE International Conference on Image Processing (ICIP). pp. 3339–3343. IEEE (2020)
2020
-
[42]
Naderi, B., Cutler, R.: A crowdsourcing approach to video quality assessment (2024)
2024
-
[43]
In: ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Naderi, B., Cutler, R., Khongbantabam, N.S., Hosseinkashi, Y., Turbell, H., Sadovnikov, A., Zou, Q.: VCD: A video conferencing dataset for video compres- sion. In: ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 3970–3974. IEEE (2024)
2024
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Qi, L., Li, J., Li, B., Li, H., Lu, Y.: Motion information propagation for neural video compression. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6111–6120 (2023)
2023
-
[45]
GLU Variants Improve Transformer
Shazeer, N.: GLU variants improve transformer. arXiv preprint arXiv:2002.05202 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[46]
IEEE Transactions on Multimedia25, 7311–7322 (2022)
Sheng, X., Li, J., Li, B., Li, L., Liu, D., Lu, Y.: Temporal context mining for learned video compression. IEEE Transactions on Multimedia25, 7311–7322 (2022)
2022
-
[47]
In: European Conference on Computer Vision
Shi, Y., Ge, Y., Wang, J., Mao, J.: AlphaVC: High-performance and efficient learned video compression. In: European Conference on Computer Vision. pp. 616–
-
[48]
In: 2021 Picture Coding Symposium (PCS)
Sun, H., Yu, L., Katto, J.: Learned image compression with fixed-point arithmetic. In: 2021 Picture Coding Symposium (PCS). pp. 1–5. IEEE (2021)
2021
-
[49]
Tian, K., Guan, Y., Xiang, J., Zhang, J., Han, X., Wei, Y.: Effortless cross-platform video codec: A codebook-based method (2024),https://openreview.net/forum? id=mRw9BuNO9i
2024
-
[50]
In: Proceedings of the 31st ACM International Conference on Multimedia
Tian, K., Guan, Y., Xiang, J., Zhang, J., Han, X., Yang, W.: Towards real-time neural video codec for cross-platform application using calibration information. In: Proceedings of the 31st ACM International Conference on Multimedia. pp. 7961– 7970 (2023)
2023
-
[51]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Van Rozendaal, T., Singhal, T., Le, H., Sautiere, G., Said, A., Buska, K., Raha, A., Kalatzis, D., Mehta, H., Mayer, F., et al.: MobileNVC: Real-time 1080p neural video compression on a mobile device. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 4323–4333 (2024) 18 T. Pärnamaa et al
2024
-
[52]
International Journal of Computer Vision (IJCV)127(8), 1106–1125 (2019)
Xue, T., Chen, B., Wu, J., Wei, D., Freeman, W.T.: Video enhancement with task- oriented flow. International Journal of Computer Vision (IJCV)127(8), 1106–1125 (2019)
2019
-
[53]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yang,R.,Mentzer,F.,Gool,L.V.,Timofte,R.:Learningforvideocompressionwith hierarchical quality and recurrent enhancement. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6628–6637 (2020)
2020
-
[54]
In: CVPR (2018)
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR (2018)
2018
-
[55]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zheng, Y., Yang, H., Zhang, T., Bao, J., Chen, D., Huang, Y., Yuan, L., Chen, D., Zeng, M., Wen, F.: General facial representation learning in a visual-linguistic manner. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18697–18709 (2022) MLVC: Cross-Platform Neural Video Codec 19 ML VC: Multi-platform Learned Vid...
-
[56]
It is evident that on CPU, most inference engines use the standard round function along with FP32 precision. One notable exception is ORT, which ap- pears to use truncate instead of round for FP16 models; this likely explains the large divergence observed in the INT8 quantized convolution results in Table
-
[57]
On MLVC: Cross-Platform Neural Video Codec 31 T able 14:Output error from fake quantization under different rounding modes and precisions
On GPUs, the behavior is close to FP32 round but not an exact match. On MLVC: Cross-Platform Neural Video Codec 31 T able 14:Output error from fake quantization under different rounding modes and precisions. Fake Quantization Round Truncate Device Precision Runtime Vendor FP16 FP32 FP16 FP32 CPU FP32 ORT Apple 0.00298 0.00000 0.02164 0.02180 ORT Intel 0.0...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.