Higher-Order Fourier Neural Operator: Explicit Mode Mixer for Nonlinear PDEs
Pith reviewed 2026-06-29 01:46 UTC · model grok-4.3
The pith
Explicit n-linear mixing of Fourier modes in one layer lets neural operators capture nonlinear PDE interactions more efficiently than stacking many standard layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
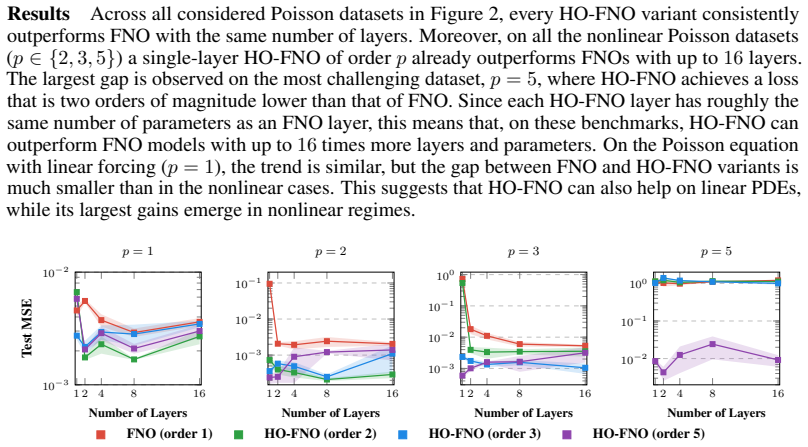
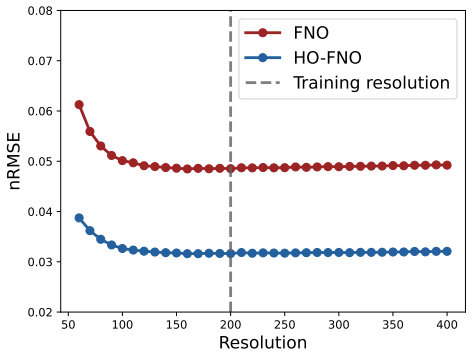
The paper replaces the diagonal spectral convolution of FNO with a Higher-Order Spectral Convolution that performs explicit n-linear mixing of Fourier modes. This mixing is chosen to match the mode-coupling structure that polynomial nonlinearities induce in the governing PDE. On standard operator-learning benchmarks the architecture matches or exceeds prior spectral operators, transformers, and state-space models; the largest gains appear in highly nonlinear regimes, where a single layer already surpasses FNO stacks of depth sixteen on the Poisson equation with polynomial right-hand side.
What carries the argument
Higher-Order Spectral Convolution: an n-linear operator applied to Fourier coefficients that mixes several modes jointly instead of modulating each coefficient independently.
If this is right
- HO-FNO retains the efficiency and multi-resolution capability of FNO architectures.
- It produces consistent accuracy gains over earlier spectral neural operators on standard nonlinear PDE benchmarks.
- A single HO-FNO layer outperforms FNO models with up to 16 layers on the Poisson equation with polynomial forcing.
- Performance is on par with or better than state-of-the-art transformers and state-space models, with larger margins in highly nonlinear regimes.
Where Pith is reading between the lines
- The same explicit mixing idea could be tried with other orthogonal bases when the nonlinearity produces known coupling rules.
- Reducing required depth may lower the cost of training operator networks for high-resolution physics simulations.
- If mode interactions are the dominant source of difficulty, similar n-linear blocks might improve non-Fourier spectral architectures as well.
Load-bearing premise
Structured interactions between Fourier modes in nonlinear PDEs are well captured by explicit n-linear mixing in the spectral domain rather than requiring deeper stacking or other mechanisms.
What would settle it
On the Poisson equation with polynomial forcing, train a single-layer HO-FNO and a 16-layer FNO under identical conditions and measure whether the single-layer error remains lower; reversal of that ordering would falsify the claimed advantage.
Figures














read the original abstract
Neural operators provide deep neural networks for learning mappings between function spaces. Among them, the Fourier Neural Operator (FNO) is particularly effective: its spectral convolution relies on low-dimensional Fourier-domain representations and can handle inputs at different resolutions. This design aligns well with settings where the Fourier basis diagonalizes the underlying operator, such as linear, constant-coefficient PDEs on periodic domains, in which Fourier modes evolve independently. However, nonlinear PDEs may benefit from an additional inductive bias, as they exhibit structured interactions between modes, governed by polynomial nonlinearities. To capture this inductive bias, we introduce the Higher-Order Spectral Convolution, a spectral mixer that extends FNO from diagonal modulation to explicit n-linear mode mixing, aligned with the dynamics of nonlinear PDEs. Our experiments on standard benchmarks show that the proposed Higher-Order FNO (HO-FNO) retains the efficiency of FNO-based architectures and consistently improves over other spectral neural operators. HO-FNO also performs on par with or better than state-of-the-art transformers and state-space models on several datasets, with stronger gains in highly nonlinear regimes, such as the Poisson equation with polynomial forcing, where a single HO-FNO layer outperforms FNO models with up to 16 layers. We open-source our code for reproducibility at: https://github.com/AlexColagrande/HO-FNO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Higher-Order Fourier Neural Operator (HO-FNO) extending FNO via a Higher-Order Spectral Convolution that performs explicit n-linear mixing of Fourier modes, intended to capture structured mode interactions from polynomial nonlinearities in PDEs. It claims consistent improvements over spectral operators on benchmarks, competitive performance with transformers and state-space models, and a key result that a single HO-FNO layer outperforms standard FNO models with up to 16 layers on the Poisson equation with polynomial forcing; code is open-sourced.
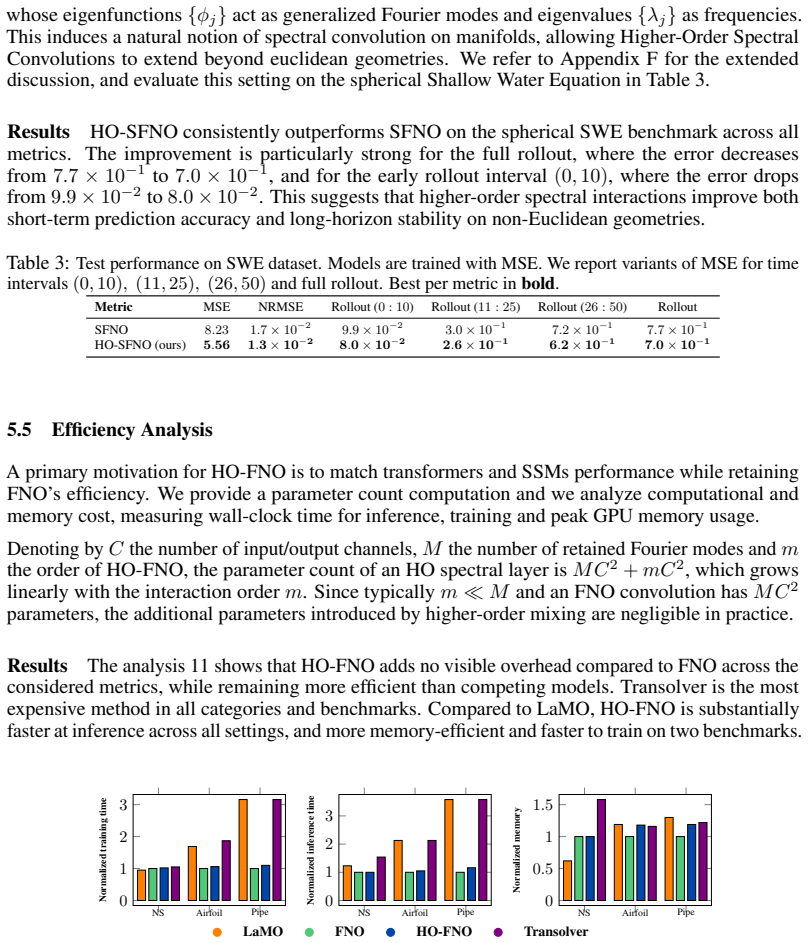
Significance. If the central experimental claims hold after parameter-matched verification, the work supplies a targeted inductive bias for spectral neural operators on nonlinear PDEs, potentially improving sample efficiency and depth requirements in operator learning. The open-sourced implementation is a clear strength supporting reproducibility.
major comments (2)
- [Abstract] Abstract and results on Poisson equation: the headline claim that a single HO-FNO layer outperforms FNO models with up to 16 layers supplies no parameter counts, FLOPs, dataset sizes, error bars, or statistical tests, leaving open whether gains arise from n-linear mode mixing or from unmatched capacity in the additional learnable coefficients over mode tuples.
- [Method] Definition of Higher-Order Spectral Convolution (method section): the extension from diagonal modulation to n-linear terms introduces per-tuple coefficients whose total parameter count is not compared against the stacked FNO baselines, so the performance delta cannot yet be attributed to the claimed structural alignment with nonlinear dynamics rather than expressivity.
minor comments (1)
- [Method] Notation for the mixing order n and the precise tensor contraction in the spectral convolution should be stated with an explicit equation to aid implementation.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments. We will revise the manuscript to include the requested details on parameter counts, FLOPs, and statistical measures to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract and results on Poisson equation: the headline claim that a single HO-FNO layer outperforms FNO models with up to 16 layers supplies no parameter counts, FLOPs, dataset sizes, error bars, or statistical tests, leaving open whether gains arise from n-linear mode mixing or from unmatched capacity in the additional learnable coefficients over mode tuples.
Authors: We agree that additional details are needed to fully substantiate the claim. In the revised manuscript, we will augment the abstract and the results section with parameter counts, FLOPs, dataset sizes, error bars, and statistical tests for the Poisson equation experiments. This will allow readers to assess whether the performance improvements stem from the n-linear mixing or from differences in model capacity. revision: yes
-
Referee: [Method] Definition of Higher-Order Spectral Convolution (method section): the extension from diagonal modulation to n-linear terms introduces per-tuple coefficients whose total parameter count is not compared against the stacked FNO baselines, so the performance delta cannot yet be attributed to the claimed structural alignment with nonlinear dynamics rather than expressivity.
Authors: We acknowledge the importance of parameter-matched comparisons. The revised version will include an explicit comparison of the total parameter counts for the Higher-Order Spectral Convolution against the standard FNO layers and the multi-layer baselines. We will also discuss how the additional coefficients are structured to align with polynomial nonlinearities, supporting the attribution to the inductive bias. revision: yes
Circularity Check
No circularity: new architecture introduced as explicit design choice with empirical validation
full rationale
The paper proposes the Higher-Order Spectral Convolution as a novel inductive bias extension to FNO, motivated by the structure of nonlinear PDEs but not derived from or reduced to any fitted parameters, self-citations, or prior results by the same authors. The central claim (single-layer outperformance on Poisson) is presented as an experimental outcome rather than a first-principles prediction that collapses to inputs by construction. No load-bearing self-citation chains, ansatzes smuggled via citation, or renaming of known results appear in the provided text. This is the common case of an honest architectural contribution evaluated empirically.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Nonlinear PDEs exhibit structured interactions between Fourier modes governed by polynomial nonlinearities.
invented entities (1)
-
Higher-Order Spectral Convolution
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2011 , publisher=
Green's functions and boundary value problems , author=. 2011 , publisher=
2011
-
[2]
2022 , publisher=
Global Atmospheric and Oceanic Modelling: Fundamental Equations , author=. 2022 , publisher=
2022
-
[3]
2007 , isbn =
LeVeque, Randall , title =. 2007 , isbn =
2007
-
[4]
Numerical solution of partial differential equations by the finite element method
Johnson, C. Numerical solution of partial differential equations by the finite element method
-
[5]
R. J. LeVeque , publisher =. Finite Volume Methods for Hyperbolic Problems , year =
-
[6]
arXiv preprint arXiv:2506.10973 , year=
Principled Approaches for Extending Neural Architectures to Function Spaces for Operator Learning , author=. arXiv preprint arXiv:2506.10973 , year=
-
[7]
arXiv preprint arXiv:2010.08895 , year=
Fourier neural operator for parametric partial differential equations , author=. arXiv preprint arXiv:2010.08895 , year=
Pith/arXiv arXiv 2010
-
[8]
International conference on machine learning , pages=
Spherical fourier neural operators: Learning stable dynamics on the sphere , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[9]
arXiv preprint arXiv:2302.08166 , year=
Learning neural operators on riemannian manifolds , author=. arXiv preprint arXiv:2302.08166 , year=
-
[10]
Advances in Neural Information Processing Systems , volume=
Geometry-informed neural operator for large-scale 3d pdes , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
arXiv preprint arXiv:2507.20065 , year=
Geometric Operator Learning with Optimal Transport , author=. arXiv preprint arXiv:2507.20065 , year=
-
[12]
Journal of Machine Learning Research , volume=
Fourier neural operator with learned deformations for pdes on general geometries , author=. Journal of Machine Learning Research , volume=
-
[13]
Journal of Machine Learning Research , volume=
On universal approximation and error bounds for Fourier neural operators , author=. Journal of Machine Learning Research , volume=
-
[14]
Journal of Machine Learning Research , volume=
Neural operator: Learning maps between function spaces with applications to pdes , author=. Journal of Machine Learning Research , volume=
-
[15]
Advances in Neural Information Processing Systems , volume=
AROMA: Preserving spatial structure for latent PDE modeling with local neural fields , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
, TITLE =
Cybenko, G. , TITLE =. Math. Control Signals Systems , FJOURNAL =. 1989 , PAGES =
1989
-
[17]
Circuits, Systems and Signal Processing , author =
Universal approximation capability of. Circuits, Systems and Signal Processing , author =. 1996 , pages =. doi:10.1007/BF01188988 , abstract =
-
[18]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[19]
arXiv preprint arXiv:1409.0473 , year=
Neural machine translation by jointly learning to align and translate , author=. arXiv preprint arXiv:1409.0473 , year=
-
[20]
arXiv preprint arXiv:2010.11929 , year=
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
Pith/arXiv arXiv 2010
-
[21]
and Kavukcuoglu, Koray and Kohli, Pushmeet and Hassabis, Demis , year =
Highly accurate protein structure prediction with. Nature , author =. 2021 , pages =. doi:10.1038/s41586-021-03819-2 , abstract =
-
[22]
Advances in Neural Information Processing Systems , volume=
Universal physics transformers: A framework for efficiently scaling neural operators , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
arXiv preprint arXiv:2507.02748 , year=
Linear Attention with Global Context: A Multipole Attention Mechanism for Vision and Physics , author=. arXiv preprint arXiv:2507.02748 , year=
-
[24]
arXiv preprint arXiv:1909.00668 , year=
Logic and the 2 -Simplicial Transformer , author=. arXiv preprint arXiv:1909.00668 , year=
arXiv 1909
-
[25]
arXiv preprint arXiv:2507.02754 , year=
Fast and Simplex: 2-Simplicial Attention in Triton , author=. arXiv preprint arXiv:2507.02754 , year=
-
[26]
Advances in Neural Information Processing Systems , volume=
Systematic generalization with edge transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
Advances in Neural Information Processing Systems , volume=
Representational strengths and limitations of transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
SIAM Journal on Applied Mathematics , author =
Stationary. SIAM Journal on Applied Mathematics , author =. 1984 , note =. doi:10.1137/0144008 , abstract =
-
[29]
Nature Methods , author =. 2020 , pages =. doi:10.1038/s41592-019-0686-2 , abstract =
-
[30]
arXiv preprint arXiv:2306.10619 , year=
Towards stability of autoregressive neural operators , author=. arXiv preprint arXiv:2306.10619 , year=
-
[31]
Journal of Computational Physics , author =
A standard test set for numerical approximations to the shallow water equations in spherical geometry , volume =. Journal of Computational Physics , author =. 1992 , pages =. doi:https://doi.org/10.1016/S0021-9991(05)80016-6 , abstract =
-
[32]
Physical Review Research , volume=
Dedalus: A flexible framework for numerical simulations with spectral methods , author=. Physical Review Research , volume=. 2020 , publisher=
2020
-
[33]
Advances in Neural Information Processing Systems , volume=
The well: a large-scale collection of diverse physics simulations for machine learning , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Hersbach, Hans and Bell, Bill and Berrisford, Paul and Hirahara, Shoji and Horányi, András and Muñoz-Sabater, Joaquín and Nicolas, Julien and Peubey, Carole and Radu, Raluca and Schepers, Dinand and Simmons, Adrian and Soci, Cornel and Abdalla, Saleh and Abellan, Xavier and Balsamo, Gianpaolo and Bechtold, Peter and Biavati, Gionata and Bidlot, Jean and B...
-
[35]
Cheung, Lawrence C. and Zaki, Tamer A. , year=. An exact representation of the nonlinear triad interaction terms in spectral space , volume=. doi:10.1017/jfm.2014.179 , journal=
-
[36]
Advances in Neural Information Processing Systems , volume=
Pdebench: An extensive benchmark for scientific machine learning , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
arXiv preprint arXiv:2204.11127 , year=
U-no: U-shaped neural operators , author=. arXiv preprint arXiv:2204.11127 , year=
-
[38]
Transactions on Machine Learning Research , year=
Dynamic Schwartz-Fourier Neural Operator for Enhanced Expressive Power , author=. Transactions on Machine Learning Research , year=
-
[39]
arXiv preprint arXiv:2412.10354 , year=
A library for learning neural operators , author=. arXiv preprint arXiv:2412.10354 , year=
-
[40]
arXiv preprint arXiv:1910.03193 , year=
Deeponet: Learning nonlinear operators for identifying differential equations based on the universal approximation theorem of operators , author=. arXiv preprint arXiv:1910.03193 , year=
Pith/arXiv arXiv 1910
-
[41]
Journal of fluid mechanics , volume=
An exact representation of the nonlinear triad interaction terms in spectral space , author=. Journal of fluid mechanics , volume=. 2014 , publisher=
2014
-
[42]
Journal of Computational Physics , volume=
Computing nearly singular solutions using pseudo-spectral methods , author=. Journal of Computational Physics , volume=. 2007 , publisher=
2007
-
[43]
IEEE Transactions on neural networks , volume=
Volterra models and three-layer perceptrons , author=. IEEE Transactions on neural networks , volume=. 1997 , publisher=
1997
-
[44]
Journal of Machine Learning Research , volume=
Volterra neural networks (vnns) , author=. Journal of Machine Learning Research , volume=
-
[45]
The cubic nonlinear Schr
Killip, Rowan and Tao, Terence and Vișan, Monica , journal=. The cubic nonlinear Schr
-
[46]
Reviews of modern physics , volume=
The world of the complex Ginzburg-Landau equation , author=. Reviews of modern physics , volume=. 2002 , publisher=
2002
-
[47]
Computer Methods in Applied Mechanics and Engineering , volume=
An energy stable method for the Swift--Hohenberg equation with quadratic--cubic nonlinearity , author=. Computer Methods in Applied Mechanics and Engineering , volume=. 2019 , publisher=
2019
-
[48]
SIAM Journal on Scientific Computing , volume=
Galerkin neural networks: A framework for approximating variational equations with error control , author=. SIAM Journal on Scientific Computing , volume=. 2021 , publisher=
2021
-
[49]
Advances in neural information processing systems , volume=
Choose a transformer: Fourier or galerkin , author=. Advances in neural information processing systems , volume=
-
[50]
arXiv preprint arXiv:2003.03485 , year=
Neural operator: Graph kernel network for partial differential equations , author=. arXiv preprint arXiv:2003.03485 , year=
Pith/arXiv arXiv 2003
-
[51]
Seidman and Leonardo Ferreira Guilhoto and Victor M
Georgios Kissas and Jacob H. Seidman and Leonardo Ferreira Guilhoto and Victor M. Preciado and George J. Pappas and Paris Perdikaris , title =. Journal of Machine Learning Research , year =
-
[52]
arXiv preprint arXiv:2406.06486 , year=
Continuum attention for neural operators , author=. arXiv preprint arXiv:2406.06486 , year=
-
[53]
arXiv preprint arXiv:2412.06740 , year=
Convolution goes higher-order: a biologically inspired mechanism empowers image classification , author=. arXiv preprint arXiv:2412.06740 , year=
-
[54]
2015 , eprint=
U-Net: Convolutional Networks for Biomedical Image Segmentation , author=. 2015 , eprint=
2015
-
[55]
2015 , eprint=
Deep Residual Learning for Image Recognition , author=. 2015 , eprint=
2015
-
[56]
2021 , eprint=
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows , author=. 2021 , eprint=
2021
-
[57]
doi:10.1038/s42256-021-00302-5 Lu Lu, Raphaël Pestourie, Steven G
Lu, Lu and Jin, Pengzhan and Pang, Guofei and Zhang, Zhongqiang and Karniadakis, George Em , year=. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators , volume=. Nature Machine Intelligence , publisher=. doi:10.1038/s42256-021-00302-5 , number=
-
[58]
2021 , eprint=
Multiwavelet-based Operator Learning for Differential Equations , author=. 2021 , eprint=
2021
-
[59]
2022 , eprint=
U-FNO -- An enhanced Fourier neural operator-based deep-learning model for multiphase flow , author=. 2022 , eprint=
2022
-
[60]
2023 , eprint=
Factorized Fourier Neural Operators , author=. 2023 , eprint=
2023
-
[61]
2023 , eprint=
Solving High-Dimensional PDEs with Latent Spectral Models , author=. 2023 , eprint=
2023
-
[62]
2021 , eprint=
Choose a Transformer: Fourier or Galerkin , author=. 2021 , eprint=
2021
-
[63]
Ht-net: Hierarchical transformer based operator learning model for multiscale pdes , author=
-
[64]
2023 , eprint=
Transformer for Partial Differential Equations' Operator Learning , author=. 2023 , eprint=
2023
-
[65]
2023 , eprint=
GNOT: A General Neural Operator Transformer for Operator Learning , author=. 2023 , eprint=
2023
-
[66]
2023 , eprint=
Scalable Transformer for PDE Surrogate Modeling , author=. 2023 , eprint=
2023
-
[67]
2024 , eprint=
Improved Operator Learning by Orthogonal Attention , author=. 2024 , eprint=
2024
-
[68]
2024 , eprint=
Transolver: A Fast Transformer Solver for PDEs on General Geometries , author=. 2024 , eprint=
2024
-
[69]
Forty-second International Conference on Machine Learning , year=
Latent Mamba Operator for Partial Differential Equations , author=. Forty-second International Conference on Machine Learning , year=
-
[70]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[71]
2017 , url=
Ilya Loshchilov and Frank Hutter , booktitle=. 2017 , url=
2017
-
[72]
2023 , eprint=
PDE-Refiner: Achieving Accurate Long Rollouts with Neural PDE Solvers , author=. 2023 , eprint=
2023
-
[73]
ICLR 2024 Workshop on AI4DifferentialEquations In Science , year=
Mixture of neural operators: Incorporating historical information for longer rollouts , author=. ICLR 2024 Workshop on AI4DifferentialEquations In Science , year=
2024
-
[74]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
MSPT: Efficient Large-Scale Physical Modeling via Parallelized Multi-Scale Attention , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[75]
International Conference on Machine Learning , pages=
Erwin: A Tree-based Hierarchical Transformer for Large-scale Physical Systems , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[76]
2025 , eprint=
Transolver++: An Accurate Neural Solver for PDEs on Million-Scale Geometries , author=. 2025 , eprint=
2025
-
[77]
arXiv preprint arXiv:2310.00120 , year=
Multi-grid tensorized fourier neural operator for high-resolution pdes , author=. arXiv preprint arXiv:2310.00120 , year=
-
[78]
1996 , publisher=
Spectral methods , author=. 1996 , publisher=
1996
-
[79]
Klimenko, A. Y. and Pope, S. B. , title =. Physics of Fluids , volume =. 2003 , month =. doi:10.1063/1.1575754 , url =
-
[80]
European Journal of Physics , volume=
Nonlinear electrostatics: the Poisson--Boltzmann equation , author=. European Journal of Physics , volume=. 2018 , publisher=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.