Enhanced Neural Video Representation Compression across Extreme Complexity and Quality Scales
Pith reviewed 2026-06-29 02:11 UTC · model grok-4.3
The pith
NVRC++ maintains four fixed complexity levels while spanning wide bitrates and qualities in INR-based video compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
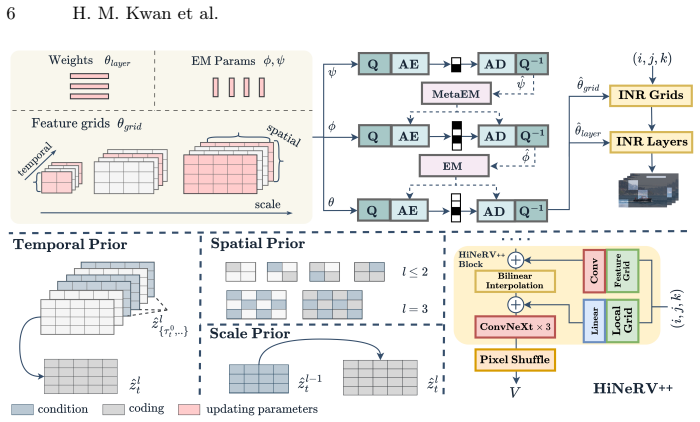
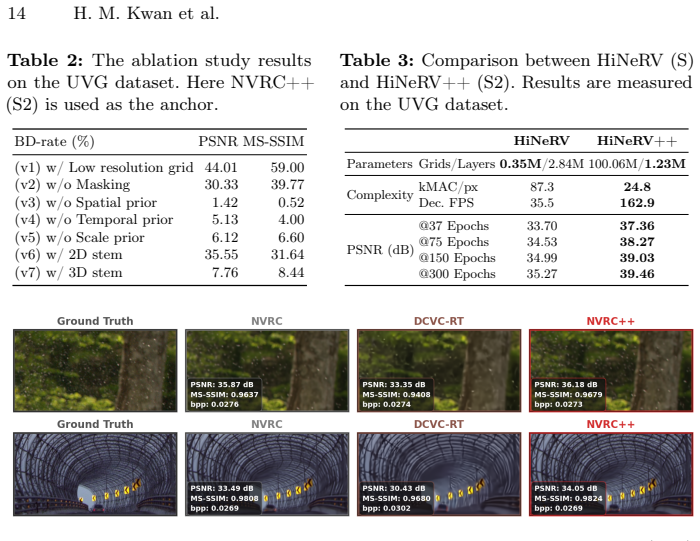
NVRC++ is a novel INR-based video codec that utilizes a lightweight INR with multiple high-resolution feature grids, paired with an optimization framework for efficient overfitting on long video sequences and an advanced entropy model for compressing the grid parameters, thereby providing four complexity levels from 7kMACs/pixel to 360kMACs/pixel, each spanning wide bitrate and quality ranges while supporting real-time decoding and delivering up to 7.6x faster decoding than NVRC at comparable performance.
What carries the argument
Lightweight INR with multiple high-resolution feature grids, which maintains fixed complexity while enabling wide bitrate-quality coverage through spatio-temporal redundancy exploitation.
If this is right
- Each of the four complexity levels can be deployed independently for different hardware constraints while still covering broad quality ranges.
- The same architecture supports real-time decoding without needing to increase model size as bitrate or quality targets rise.
- Spatio-temporal redundancies are exploited directly in the grid parameters rather than through added model capacity.
Where Pith is reading between the lines
- The grid-plus-entropy design may transfer to other high-dimensional signals such as volumetric video or light-field data.
- Hardware-specific quantization of the feature grids could further reduce the memory footprint beyond the reported entropy coding gains.
- The fixed-complexity property suggests the method could be combined with adaptive streaming systems that switch levels without retraining.
Load-bearing premise
The optimization framework can overfit high-resolution grids for long sequences without prohibitive compute or memory costs, and the entropy model can efficiently compress the high-dimensional parameters.
What would settle it
Run the reported experiments on a new set of long high-resolution videos and measure whether any complexity level exceeds its stated MACs/pixel budget or fails to reach real-time decoding speed.
Figures



read the original abstract
Implicit neural representations (INRs) have recently emerged as a promising approach to video compression, delivering competitive rate-distortion performance alongside rapid decoding. However, existing neural video codecs struggle to balance complexity and scalability. Lightweight models often suffer from degraded compression performance when scaled to different bitrate/quality levels, whereas high-performance models exhibit limited scalability, as their model complexity typically increases with quality. This lack of a unified architecture capable of maintaining consistent complexity across a wide range of bitrates severely limits their diverse real-world deployment. To address these challenges, we introduce NVRC++, a novel INR-based video codec that utilizes a lightweight INR with multiple high-resolution feature grids, providing high scalability at any given complexity level. This is paired with an optimization framework that enables efficient overfitting on high-resolution grids for long video sequences, thereby exploiting spatio-temporal redundancies without prohibitive computational or memory overhead. Additionally, an advanced entropy model is designed for efficiently compressing the high-dimensional grid parameters. As a result, NVRC++ provides four complexity levels (from 7kMACs/pixel to 360kMACs/pixel), each spanning wide bitrate and quality ranges while supporting real-time decoding. The experimental results show that NVRC++ offers a much faster decoding speed (up to 7.6x) compared to the SOTA INR-based video codec, NVRC, while delivering comparable performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces NVRC++, an INR-based video codec using a lightweight INR with multiple high-resolution feature grids, paired with an optimization framework for efficient overfitting on long sequences and an advanced entropy model for grid parameters. It claims four fixed complexity levels (7k–360k MACs/pixel) each spanning wide bitrate/quality ranges with real-time decoding, delivering up to 7.6× faster decoding than NVRC at comparable performance.
Significance. If the results hold, this addresses a key limitation in INR video codecs by enabling consistent complexity across quality scales, which supports diverse real-world deployment. The fixed-complexity operating points and real-time capability are practical strengths; the optimization and entropy components are presented as jointly enabling scalability without prohibitive overhead.
major comments (2)
- [Experimental Results] Experimental Results section: the central claims of 7.6× decoding speedup and comparable rate-distortion performance to NVRC are load-bearing but rest on unspecified datasets, sequence counts, hardware platforms, and statistical reporting; without these, it is impossible to assess whether post-hoc choices or limited test conditions affect the cross-method comparison.
- [Method] Method section (optimization framework description): the claim that the framework enables efficient overfitting on high-resolution grids for long sequences without prohibitive overhead lacks quantitative analysis (e.g., memory scaling curves or per-sequence runtime breakdowns) that would confirm it supports the four complexity levels at the stated ranges.
minor comments (2)
- The abstract would be clearer if it named the specific video datasets and resolution ranges used for the reported results.
- Notation for MACs/pixel and the four complexity levels should be defined at first use with a table reference for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate the revisions that will be made to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Experimental Results] Experimental Results section: the central claims of 7.6× decoding speedup and comparable rate-distortion performance to NVRC are load-bearing but rest on unspecified datasets, sequence counts, hardware platforms, and statistical reporting; without these, it is impossible to assess whether post-hoc choices or limited test conditions affect the cross-method comparison.
Authors: We agree that greater explicitness is needed to allow readers to evaluate the comparisons. The manuscript references standard video compression benchmarks, but the Experimental Results section will be revised to add a dedicated paragraph specifying the datasets, exact sequence counts, hardware platforms used for timing, and statistical reporting (means and variability across sequences). This will be placed at the start of the section to support assessment of the 7.6× speedup and rate-distortion results. revision: yes
-
Referee: [Method] Method section (optimization framework description): the claim that the framework enables efficient overfitting on high-resolution grids for long sequences without prohibitive overhead lacks quantitative analysis (e.g., memory scaling curves or per-sequence runtime breakdowns) that would confirm it supports the four complexity levels at the stated ranges.
Authors: We concur that quantitative support would strengthen the description. The revised Method section will incorporate new analysis consisting of memory scaling curves versus sequence length and grid resolution, together with per-sequence runtime breakdowns for the overfitting stage across the four complexity levels. These will be presented in additional figures and text to demonstrate support for the claimed operating points. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents NVRC++ as an empirical engineering contribution: a lightweight INR architecture augmented with multiple high-resolution grids, paired with a described optimization framework and entropy model. These components are introduced as design choices that enable the reported scalability across complexity levels and real-time decoding. Performance claims rest on experimental benchmarking against the external SOTA method NVRC rather than any internal derivation, equation, or fitted parameter that reduces to the inputs by construction. No self-definitional loops, uniqueness theorems, or ansatzes smuggled via self-citation appear in the load-bearing steps. The derivation chain is therefore self-contained as a set of proposed techniques validated by results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: ICLR
Ballé, J., Laparra, V., Simoncelli, E.P.: End-to-end optimized image compression. In: ICLR. OpenReview.net (2017)
2017
-
[2]
In: ICLR
Ballé, J., Minnen, D., Singh, S., Hwang, S.J., Johnston, N.: Variational image compression with a scale hyperprior. In: ICLR. OpenReview.net (2018)
2018
-
[3]
ITU SG16 Doc
Bjontegaard, G.: Calculation of average psnr differences between rd-curves. ITU SG16 Doc. VCEG-M33 (2001)
2001
-
[4]
Bross, B., Wang, Y.K., Ye, Y., Liu, S., Chen, J., Sullivan, G.J., Ohm, J.R.: Overview oftheversatilevideocoding(VVC)standardanditsapplications.IEEETransactions on Circuits and Systems for Video Technology31(10), 3736–3764 (2021)
2021
-
[5]
In: the JVET meeting
Browne, A., Ye, Y., Kim, S.H.: Algorithm description for Versatile Video Coding and Test Model 19 (VTM 19). In: the JVET meeting. ITU-T and ISO/IEC (2023)
2023
-
[6]
Academic Press (2021)
Bull, D., Zhang, F.: Intelligent image and video compression: communicating pictures. Academic Press (2021)
2021
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, H., Gwilliam, M., Lim, S.N., Shrivastava, A.: HNeRV: A hybrid neural repre- sentation for videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10270–10279 (2023)
2023
-
[8]
Advances in Neural Information Processing Systems34, 21557–21568 (2021)
Chen, H., He, B., Wang, H., Ren, Y., Lim, S.N., Shrivastava, A.: NeRV: Neural representations for videos. Advances in Neural Information Processing Systems34, 21557–21568 (2021)
2021
-
[9]
IEEE Trans
Chen, Y., Xie, H., Chen, C., Gao, Z., Benjak, M., Peng, W., Ostermann, J.: Maskcrt: Masked conditional residual transformer for learned video compression. IEEE Trans. Circuits Syst. Video Technol.34(11), 11980–11992 (2024) 16 H. M. Kwan et al
2024
-
[10]
In: Proceedings of the 31st ACM International Conference on Multimedia
Chen, Z., Relic, L., Azevedo, R., Zhang, Y., Gross, M., Xu, D., Zhou, L., Schroers, C.: Neural video compression with spatio-temporal cross-covariance transformers. In: Proceedings of the 31st ACM International Conference on Multimedia. pp. 8543–8551 (2023)
2023
-
[11]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Gao, G., Kwan, H.M., Zhang, F., Bull, D.: Pnvc: Towards practical inr-based video compression. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 3068–3076 (2025)
2025
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gomes, C., Azevedo, R., Schroers, C.: Video compression with entropy-constrained neural representations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18497–18506 (2023)
2023
-
[13]
In: ICCV
Habibian, A., van Rozendaal, T., Tomczak, J.M., Cohen, T.: Video compression with rate-distortion autoencoders. In: ICCV. pp. 7032–7041. IEEE (2019)
2019
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
He, B., Yang, X., Wang, H., Wu, Z., Chen, H., Huang, S., Ren, Y., Lim, S.N., Shrivas- tava, A.: Towards scalable neural representation for diverse videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6132–6142 (2023)
2023
-
[15]
In: CVPR
He, D., Zheng, Y., Sun, B., Wang, Y., Qin, H.: Checkerboard Context Model for Efficient Learned Image Compression. In: CVPR. pp. 14771–14780 (2021)
2021
-
[16]
Improving neural networks by preventing co-adaptation of feature detectors
Hinton, G.E., Srivastava, N., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.R.: Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580 (2012)
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[17]
In: European Conference on Computer Vision
Ho, Y.H., Chang, C.P., Chen, P.Y., Gnutti, A., Peng, W.H.: CANF-VC: Conditional augmented normalizing flows for video compression. In: European Conference on Computer Vision. pp. 207–223. Springer (2022)
2022
-
[18]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Jia, Z., Li, B., Li, J., Xie, W., Qi, L., Li, H., Lu, Y.: Towards practical real-time neural video compression. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 12543–12552 (2025)
2025
-
[19]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Jiang, W., Li, J., Zhang, K., Zhang, L.: Biecvc: Gated diversification of bidirec- tional contexts for learned video compression. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 7248–7257 (2025)
2025
-
[20]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Jiang, W., Li, J., Zhang, K., Zhang, L.: Ecvc: Exploiting non-local correlations in multiple frames for contextual video compression. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7331–7341 (2025)
2025
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Kim, H., Bauer, M., Theis, L., Schwarz, J.R., Dupont, E.: C3: High-performance and low-complexity neural compression from a single image or video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[22]
Advances in Neural Information Processing Systems36(2024)
Kwan, H.M., Gao, G., Zhang, F., Gower, A., Bull, D.: HiNeRV: Video compres- sion with hierarchical encoding-based neural representation. Advances in Neural Information Processing Systems36(2024)
2024
-
[23]
arXiv preprint arXiv:2409.07414 (2024)
Kwan, H.M., Gao, G., Zhang, F., Gower, A., Bull, D.: Nvrc: Neural video represen- tation compression. arXiv preprint arXiv:2409.07414 (2024)
-
[24]
Kwan, H.M., Peng, T., Gao, G., Zhang, F., Nilsson, M., Gower, A., Bull, D.: Ultra-lightweight neural video representation compression. CoRRabs/2512.04019 (2025)
-
[25]
Kwan, H.M., Zhang, F., Gower, A., Bull, D.: Immersive video compression using implicit neural representations. In: PCS. pp. 1–5. IEEE (2024)
2024
-
[26]
arXiv preprint arXiv:2104.07930 (2021) Enhanced Neural Video Representation Compression 17
Ladune, T., Philippe, P., Hamidouche, W., Zhang, L., Déforges, O.: Conditional coding for flexible learned video compression. arXiv preprint arXiv:2104.07930 (2021) Enhanced Neural Video Representation Compression 17
-
[27]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ladune, T., Philippe, P., Henry, F., Clare, G., Leguay, T.: COOL-CHIC: Coordinate- based low complexity hierarchical image codec. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13515–13522 (2023)
2023
-
[28]
In: Proceedings of the 31st ACM International Conference on Multimedia
Lee, J.C., Rho, D., Ko, J.H., Park, E.: Ffnerv: Flow-guided frame-wise neural representations for videos. In: Proceedings of the 31st ACM International Conference on Multimedia. pp. 7859–7870 (2023)
2023
-
[29]
In: 2024 Data Compression Conference (DCC)
Leguay, T., Ladune, T., Philippe, P., Déforges, O.: COOL-CHIC video: Learned video coding with 800 parameters. In: 2024 Data Compression Conference (DCC). pp. 23–32. IEEE (2024)
2024
-
[30]
In: NeurIPS
Li, J., Li, B., Lu, Y.: Deep contextual video compression. In: NeurIPS. pp. 18114– 18125 (2021)
2021
-
[31]
In: ACM Multimedia
Li, J., Li, B., Lu, Y.: Hybrid Spatial-Temporal Entropy Modelling for Neural Video Compression. In: ACM Multimedia. pp. 1503–1511. ACM (2022)
2022
-
[32]
In: CVPR
Li, J., Li, B., Lu, Y.: Neural video compression with diverse contexts. In: CVPR. pp. 22616–22626. IEEE (2023)
2023
-
[33]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, J., Li, B., Lu, Y.: Neural video compression with feature modulation. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26099–26108 (2024)
2024
-
[34]
In: European Conference on Computer Vision
Li, Z., Wang, M., Pi, H., Xu, K., Mei, J., Liu, Y.: E-nerv: Expedite neural video representation with disentangled spatial-temporal context. In: European Conference on Computer Vision. pp. 267–284. Springer (2022)
2022
-
[35]
In: European Conference on Computer Vision
Liu, J., Wang, S., Ma, W.C., Shah, M., Hu, R., Dhawan, P., Urtasun, R.: Condi- tional entropy coding for efficient video compression. In: European Conference on Computer Vision. pp. 453–468. Springer (2020)
2020
-
[36]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lu, G., Ouyang, W., Xu, D., Zhang, X., Cai, C., Gao, Z.: DVC: An end-to-end deep video compression framework. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11006–11015 (2019)
2019
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Maiya, S.R., Girish, S., Ehrlich, M., Wang, H., Lee, K.S., Poirson, P., Wu, P., Wang, C., Shrivastava, A.: Nirvana: Neural implicit representations of videos with adaptive networks and autoregressive patch-wise modeling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14378–14387 (2023)
2023
-
[38]
Vct: A video compression transformer.arXiv preprint arXiv:2206.07307, 2022
Mentzer, F., Toderici, G., Minnen, D., Hwang, S.J., Caelles, S., Lucic, M., Agustsson, E.: VCT: A video compression transformer. arXiv preprint arXiv:2206.07307 (2022)
-
[39]
In: MMSys
Mercat, A., Viitanen, M., Vanne, J.: UVG Dataset: 50/120fps 4K Sequences for Video Codec Analysis and Development. In: MMSys. pp. 297–302. ACM (2020)
2020
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., Geiger, A.: Occupancy networks: Learning 3d reconstruction in function space. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4460–4470 (2019)
2019
-
[41]
Commu- nications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021)
2021
-
[42]
In: NeurIPS
Minnen, D., Ballé, J., Toderici, G.: Joint autoregressive and hierarchical priors for learned image compression. In: NeurIPS. pp. 10794–10803 (2018)
2018
-
[43]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Park, J.J., Florence, P., Straub, J., Newcombe, R., Lovegrove, S.: Deepsdf: Learning continuous signed distance functions for shape representation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 165–174 (2019)
2019
-
[44]
In: the JVET meeting
Rosewarne, C., Sharman, K., Sjoberg, R., Sullivan, G.: High efficiency video coding (HEVC) test model 16 (HM 16) improved encoder description update 16. In: the JVET meeting. ITU-T and ISO/IEC (2022) 18 H. M. Kwan et al
2022
-
[45]
IEEE Transactions on Multimedia (2025)
Sheng,X.,Li,L.,Liu,D.,Wang,S.:Bi-directionaldeepcontextualvideocompression. IEEE Transactions on Multimedia (2025)
2025
-
[46]
In: CVPR
Shi, W., Caballero, J., Huszar, F., Totz, J., Aitken, A.P., Bishop, R., Rueckert, D., Wang, Z.: Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: CVPR. pp. 1874–1883. IEEE Computer Society (2016)
2016
-
[47]
Advances in neural information processing systems33, 7462–7473 (2020)
Sitzmann, V., Martel, J., Bergman, A., Lindell, D., Wetzstein, G.: Implicit neural representations with periodic activation functions. Advances in neural information processing systems33, 7462–7473 (2020)
2020
-
[48]
IEEE Transactions on circuits and systems for video technology22(12), 1649–1668 (2012)
Sullivan, G.J., Ohm, J.R., Han, W.J., Wiegand, T.: Overview of the high efficiency video coding (HEVC) standard. IEEE Transactions on circuits and systems for video technology22(12), 1649–1668 (2012)
2012
-
[49]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.: Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1–9 (2015)
2015
-
[50]
In: VCIP
Teng, S., Jiang, Y., Gao, G., Zhang, F., Davis, T., Liu, Z., Bull, D.: Benchmarking conventional and learned video codecs with a low-delay configuration. In: VCIP. pp. 1–5. IEEE (2024)
2024
-
[51]
In: ICIP
Wang, H., Gan, W., Hu, S., Lin, J.Y., Jin, L., Song, L., Wang, P., Katsavounidis, I., Aaron, A., Kuo, C.J.: MCL-JCV: A JND-based H.264/AVC video quality assessment dataset. In: ICIP. pp. 1509–1513. IEEE (2016)
2016
-
[52]
x265:https://www.videolan.org/developers/x265.html
-
[53]
In: The Eleventh International Conference on Learning Repre- sentations (2022)
Xiang, J., Tian, K., Zhang, J.: MIMT: Masked image modeling transformer for video compression. In: The Eleventh International Conference on Learning Repre- sentations (2022)
2022
-
[54]
arXiv preprint arXiv:2402.18152 (2024)
Zhang, X., Yang, R., He, D., Ge, X., Xu, T., Wang, Y., Qin, H., Zhang, J.: Boosting neural representations for videos with a conditional decoder. arXiv preprint arXiv:2402.18152 (2024)
-
[55]
arXiv preprint arXiv:2112.11312 (2021)
Zhang, Y., Van Rozendaal, T., Brehmer, J., Nagel, M., Cohen, T.: Implicit neural video compression. arXiv preprint arXiv:2112.11312 (2021)
-
[56]
arXiv preprint arXiv:2506.15276 (2025)
Zhu, J., Zhang, X., Tang, L., Jiang, J.: Msnerv: neural video representation with multi-scale feature fusion. arXiv preprint arXiv:2506.15276 (2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.