LLawCo: Learning Laws of Cooperation for Modeling Embodied Multi-Agent Behavior
Pith reviewed 2026-06-29 04:35 UTC · model grok-4.3
The pith
Embodied agents improve cooperation by turning reflections on past failures into high-level behavioral laws and fine-tuning with them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
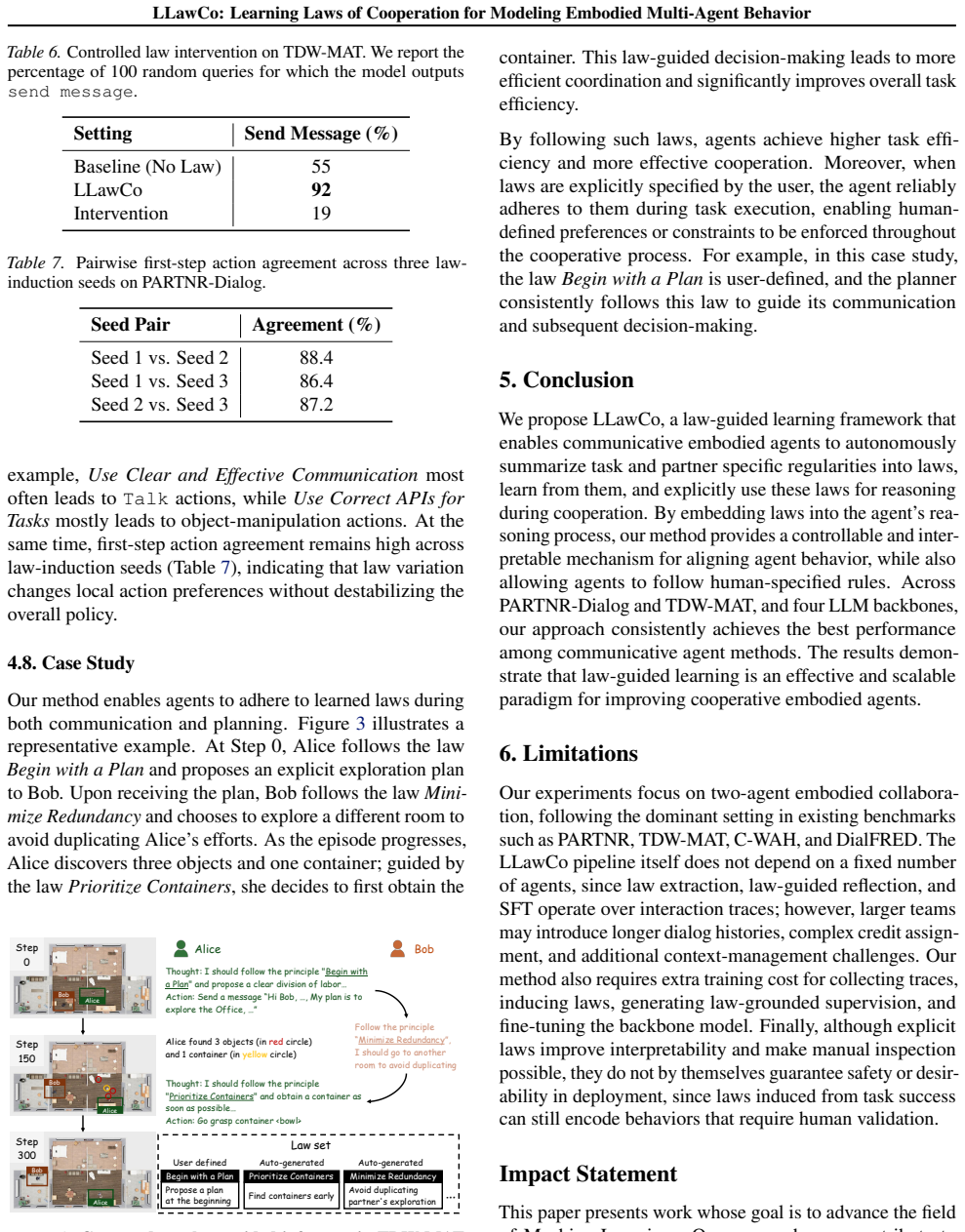
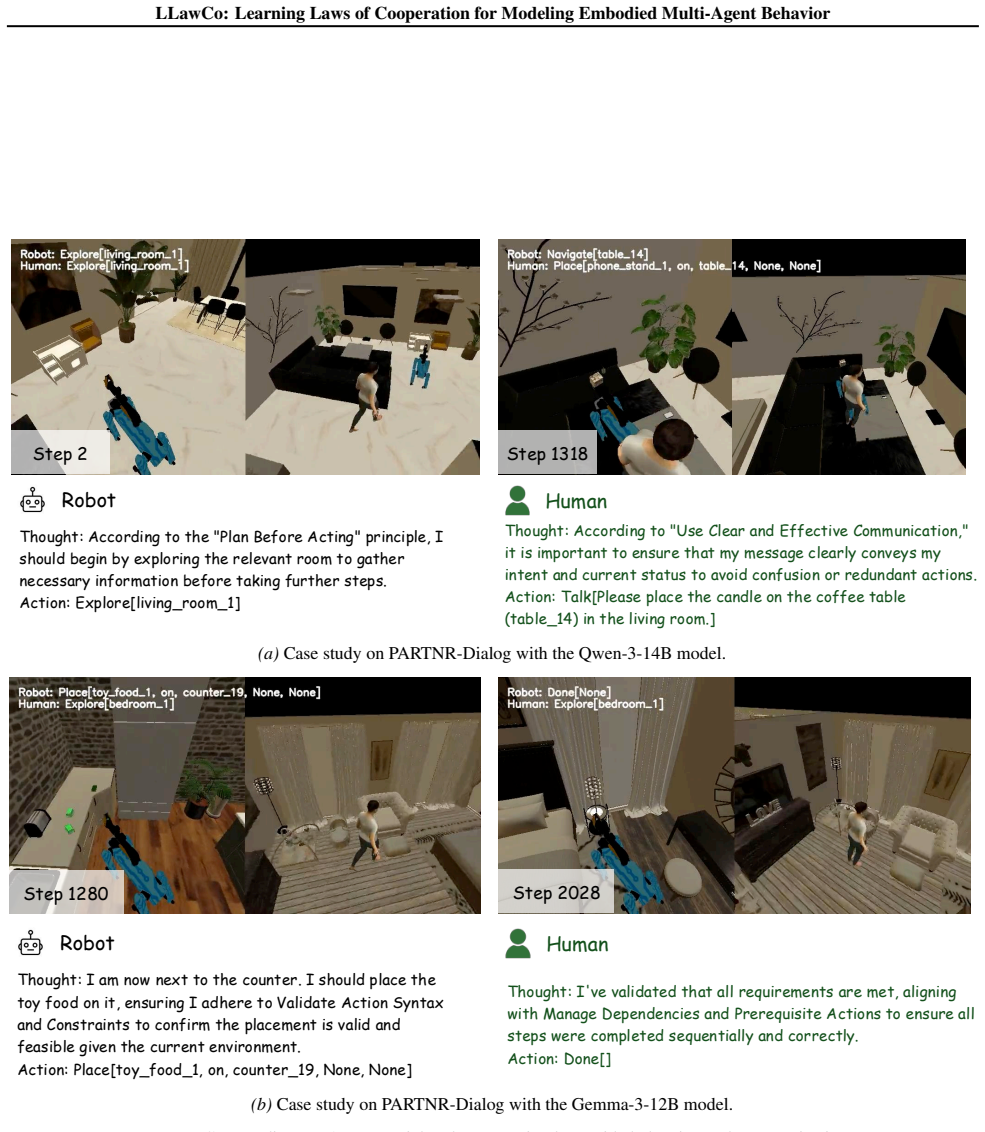
LLawCo lets agents autonomously extract high-level behavioral laws from reflections on past failures and incorporate these laws into their reasoning via supervised fine-tuning, producing better alignment with partners and task objectives and raising average success rates by 4.5 percent on PARTNR-Dialog and 6.8 percent on TDW-MAT over prior open-source communicative agent frameworks.
What carries the argument
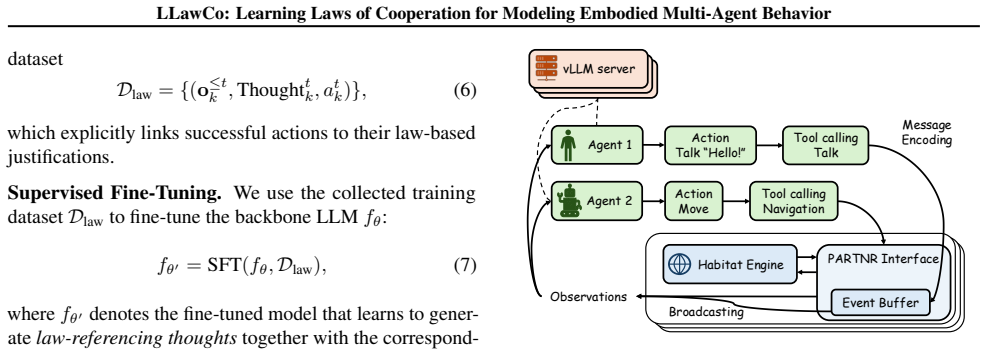
The reflection step that converts observed misaligned behaviors into reusable high-level laws, followed by supervised fine-tuning to insert those laws into the agent's chain of thought.
If this is right
- Task success rates rise by 4.5 percent on PARTNR-Dialog and 6.8 percent on TDW-MAT across four different backbone LLMs.
- Agents exhibit improved alignment with both partner behavior and overall task goals in partially observable environments.
- Cooperative efficiency increases in communicative planning benchmarks without requiring environment-specific prompt engineering at test time.
- The same law-extraction process works across multiple existing tasks and the newly introduced PARTNR-Dialog benchmark.
Where Pith is reading between the lines
- The reflection-to-law pipeline could be tested on single-agent tasks where the only partner is the environment itself.
- A growing set of such laws might eventually let agents start from a shared library rather than learning everything from scratch on each new task.
- The method might reduce the amount of human demonstration data needed to reach a given cooperation level.
Load-bearing premise
Reflecting on past failures will produce laws that remain useful and general when the fine-tuned agent faces new but similar cooperative tasks.
What would settle it
Applying the extracted laws via fine-tuning and measuring success rates that stay the same or drop on PARTNR-Dialog and TDW-MAT compared with the base models.
Figures


read the original abstract
Embodied agents operating in decentralized and partially observable environments have attracted growing attention in recent years. However, existing large language model (LLM)-based agents often exhibit behaviors that are misaligned with their partners or inconsistent with the environment state, leading to inefficient cooperation and poor task success. To address this challenge, we propose a novel framework, Learning Laws of Cooperation (LLawCo), that enables embodied agents to autonomously align with both their partners and task objectives. Our framework allows agents to reflect on past failures to extract misaligned behavioral patterns, which are used to derive high-level behavioral laws, such as "Talk when necessary" and "Wait for partner." These laws are explicitly incorporated into the agents' chains of thought via supervised fine-tuning, aligning their reasoning with task requirements and the behavior of other agents. To evaluate our approach, we introduce PARTNR-Dialog, a large-scale multi-agent communicative and cooperative planning benchmark built on the PARTNR environment. Experiments on existing tasks and our new benchmark demonstrate significant improvements in cooperative efficiency and task success rates. Across four backbone LLMs, our method achieves average success rate improvements of 4.5% on the PARTNR-Dialog benchmark and 6.8% on the TDW-MAT benchmark over state-of-the-art open-source communicative agent frameworks. See the LLawCo project page for details: https://www.merl.com/research/highlights/LLawCo
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LLawCo, a framework in which embodied LLM-based agents reflect on past failures in decentralized partially observable environments to extract high-level behavioral laws (e.g., "Talk when necessary"), incorporate those laws into chains of thought via supervised fine-tuning, and thereby improve alignment with partners and task objectives. It introduces the PARTNR-Dialog benchmark and reports average success-rate gains of 4.5% on PARTNR-Dialog and 6.8% on TDW-MAT over prior open-source communicative agent frameworks, evaluated across four backbone LLMs.
Significance. If the reported gains can be shown to arise from the extracted laws rather than from the volume of additional SFT data alone, the approach would supply an interpretable mechanism for aligning multi-agent LLM reasoning with cooperative objectives. The release of the PARTNR-Dialog benchmark constitutes a concrete community contribution.
major comments (3)
- [Abstract] Abstract and Experiments section: the central claim of 4.5% and 6.8% average success-rate improvements is presented without any description of the law-extraction algorithm, statistical significance tests, variance across runs, or baseline implementation details, preventing verification that the data support the stated gains.
- [Experiments] Experiments section: no ablation is reported that isolates the contribution of the high-level law statements from the effect of performing additional supervised fine-tuning on reflective trajectories; without such a control the attribution of gains to the laws themselves remains untested.
- [Method] Method section: the procedure that converts failure reflections into generalizable high-level laws is not specified at a level that would allow reproduction or that would rule out overfitting to the particular failure distributions of PARTNR and TDW-MAT.
minor comments (1)
- [Abstract] The project-page URL is given but the manuscript should contain a self-contained summary of benchmark construction and evaluation protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the manuscript requires additional details on the law-extraction process, statistical reporting, baseline implementations, and an ablation study to strengthen the claims. We will revise the paper accordingly to address these points.
read point-by-point responses
-
Referee: [Abstract] Abstract and Experiments section: the central claim of 4.5% and 6.8% average success-rate improvements is presented without any description of the law-extraction algorithm, statistical significance tests, variance across runs, or baseline implementation details, preventing verification that the data support the stated gains.
Authors: We agree that the current presentation lacks sufficient detail for verification. In the revised manuscript, we will expand the Method section with a step-by-step description of the law-extraction algorithm (including prompting templates and generalization criteria), add standard deviations across runs, report p-values from appropriate statistical tests, and provide explicit implementation details for all baselines. revision: yes
-
Referee: [Experiments] Experiments section: no ablation is reported that isolates the contribution of the high-level law statements from the effect of performing additional supervised fine-tuning on reflective trajectories; without such a control the attribution of gains to the laws themselves remains untested.
Authors: This is a fair criticism. We will add a new ablation experiment comparing (i) SFT on reflective trajectories alone versus (ii) SFT on reflective trajectories augmented with the extracted laws. Results will be reported on both benchmarks to isolate the laws' contribution. revision: yes
-
Referee: [Method] Method section: the procedure that converts failure reflections into generalizable high-level laws is not specified at a level that would allow reproduction or that would rule out overfitting to the particular failure distributions of PARTNR and TDW-MAT.
Authors: We will revise the Method section to include pseudocode, concrete examples of reflection-to-law conversion, and explicit discussion of generalization steps and safeguards against overfitting to the training failure distributions. revision: yes
Circularity Check
No circularity: empirical benchmark gains from proposed framework
full rationale
The paper presents an empirical method (reflect on failures, extract laws like 'Talk when necessary', apply via SFT) and reports success-rate improvements on PARTNR-Dialog and TDW-MAT. No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps exist. Results are measured outcomes on held-out benchmarks rather than quantities forced by construction from the method's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reflecting on past failures can extract misaligned behavioral patterns that generalize into high-level laws useful for future tasks.
Reference graph
Works this paper leans on
-
[1]
Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073,
Bai, Y ., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., Goldie, A., Mirhoseini, A., McKin- non, C., et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073,
-
[2]
Beattie, C., Leibo, J. Z., Teplyashin, D., Ward, T., Wain- wright, M., K¨uttler, H., Lefrancq, A., Green, S., Vald´es, V ., Sadik, A., et al. Deepmind lab.arXiv preprint arXiv:1612.03801,
-
[3]
D., Desai, R., Hlavac, M., Karashchuk, V ., Krantz, J., Mottaghi, R., Parashar, P., et al
Chang, M., Chhablani, G., Clegg, A., Cote, M. D., Desai, R., Hlavac, M., Karashchuk, V ., Krantz, J., Mottaghi, R., Parashar, P., et al. Partnr: A benchmark for planning and reasoning in embodied multi-agent tasks.arXiv preprint arXiv:2411.00081,
-
[4]
Chen, Y ., Arkin, J., Zhang, Y ., Roy, N., and Fan, C. Scalable multi-robot collaboration with large language models: Centralized or decentralized systems? In2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 4311–4317. IEEE, 2024a. Chen, Z., Deng, Y ., Yuan, H., Ji, K., and Gu, Q. Self-play fine-tuning converts weak language models...
-
[5]
Findeis, A., Kaufmann, T., H¨ullermeier, E., Albanie, S., and Mullins, R. Inverse constitutional ai: Compressing pref- erences into principles.arXiv preprint arXiv:2406.06560,
-
[6]
Gan, C., Schwartz, J., Alter, S., Mrowca, D., Schrimpf, M., Traer, J., De Freitas, J., Kubilius, J., Bhandwaldar, A., Haber, N., et al. Threedworld: A platform for inter- active multi-modal physical simulation.arXiv preprint arXiv:2007.04954,
arXiv 2007
-
[7]
L., DiCarlo, J
Gan, C., Zhou, S., Schwartz, J., Alter, S., Bhandwaldar, A., Gutfreund, D., Yamins, D. L., DiCarlo, J. J., McDer- mott, J., Torralba, A., et al. The threedworld transport challenge: A visually guided task-and-motion planning benchmark towards physically realistic embodied ai. In 2022 International conference on robotics and automa- tion (ICRA), pp. 8847–8...
2022
-
[8]
A Cordial Sync: Going beyond marginal policies for multi-agent embodied tasks
Jain, U., Weihs, L., Kolve, E., Farhadi, A., Lazebnik, S., Kembhavi, A., and Schwing, A. A Cordial Sync: Going beyond marginal policies for multi-agent embodied tasks. InComputer Vision–ECCV 2020: 16th European Con- ference, Glasgow, UK, August 23–28, 2020, Proceedings, Part V 16, pp. 471–490. Springer,
2020
-
[9]
Specific versus general principles for constitutional ai.arXiv preprint arXiv:2310.13798,
Kundu, S., Bai, Y ., Kadavath, S., Askell, A., Callahan, A., Chen, A., Goldie, A., Balwit, A., Mirhoseini, A., McLean, B., et al. Specific versus general principles for constitutional ai.arXiv preprint arXiv:2310.13798,
-
[10]
R., Villa-Renteria, I., Tang, J
Li, C., Zhang, R., Wong, J., Gokmen, C., Srivastava, S., Mart´ın-Mart´ın, R., Wang, C., Levine, G., Ai, W., Mar- tinez, B., Yin, H., Lingelbach, M., Hwang, M., Hiranaka, A., Garlanka, S., Aydin, A., Lee, S., Sun, J., Anvari, M., Sharma, M., Bansal, D., Hunter, S., Kim, K.-Y ., Lou, A., 10 LLawCo: Learning Laws of Cooperation for Modeling Embodied Multi-Ag...
-
[11]
Ling, S., Wang, Y ., Fan, C., Lam, T. L., and Hu, J. Elh- plan: Efficient long-horizon task planning for multi-agent collaboration.arXiv preprint arXiv:2509.24230,
-
[12]
G., Sonke, J.- J., and Gavves, E
Liu, J., Zhou, P., Du, Y ., Tan, A.-H., Snoek, C. G., Sonke, J.- J., and Gavves, E. Capo: Cooperative plan optimization for efficient embodied multi-agent cooperation.arXiv preprint arXiv:2411.04679,
-
[13]
B., Fidler, S., and Torralba, A
Puig, X., Shu, T., Li, S., Wang, Z., Liao, Y .-H., Tenenbaum, J. B., Fidler, S., and Torralba, A. Watch-and-help: A chal- lenge for social perception and human-ai collaboration. arXiv preprint arXiv:2010.09890,
arXiv 2010
-
[14]
D., Yang, T.- Y ., Partsey, R., Desai, R., Clegg, A
Puig, X., Undersander, E., Szot, A., Cote, M. D., Yang, T.- Y ., Partsey, R., Desai, R., Clegg, A. W., Hlavac, M., Min, S. Y ., et al. Habitat 3.0: A co-habitat for humans, avatars and robots.arXiv preprint arXiv:2310.13724,
-
[15]
Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ram ´e, A., Rivi`ere, M., et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
-
[16]
URL https://arxiv.org/abs/ 1801.02209. Xiang, F., Qin, Y ., Mo, K., Xia, Y ., Zhu, H., Liu, F., Liu, M., Jiang, H., Yuan, Y ., Wang, H., et al. Sapien: A simulated part-based interactive environment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11097–11107,
-
[17]
Chalet: Cornell house agent learning envi- ronment.arXiv preprint arXiv:1801.07357,
Yan, C., Misra, D., Bennnett, A., Walsman, A., Bisk, Y ., and Artzi, Y . Chalet: Cornell house agent learning envi- ronment.arXiv preprint arXiv:1801.07357,
-
[18]
Qwen3 technical report.arXiv preprint arXiv:2505.09388,
11 LLawCo: Learning Laws of Cooperation for Modeling Embodied Multi-Agent Behavior Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[19]
Proa- gent: building proactive cooperative agents with large language models
Zhang, C., Yang, K., Hu, S., Wang, Z., Li, G., Sun, Y ., Zhang, C., Zhang, Z., Liu, A., Zhu, S.-C., et al. Proa- gent: building proactive cooperative agents with large language models. InProceedings of the AAAI Conference on Artificial Intelligence, pp. 17591–17599, 2024a. Zhang, H., Du, W., Shan, J., Zhou, Q., Du, Y ., Tenenbaum, J. B., Shu, T., and Gan,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.