Conversational Query Engine for Mixed-Modality Heterogeneous Enterprise Data Sources
Pith reviewed 2026-06-30 11:15 UTC · model grok-4.3
The pith
COGNI unifies natural-language queries over structured warehouses and unstructured documents through four architectural layers in a production BI system.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
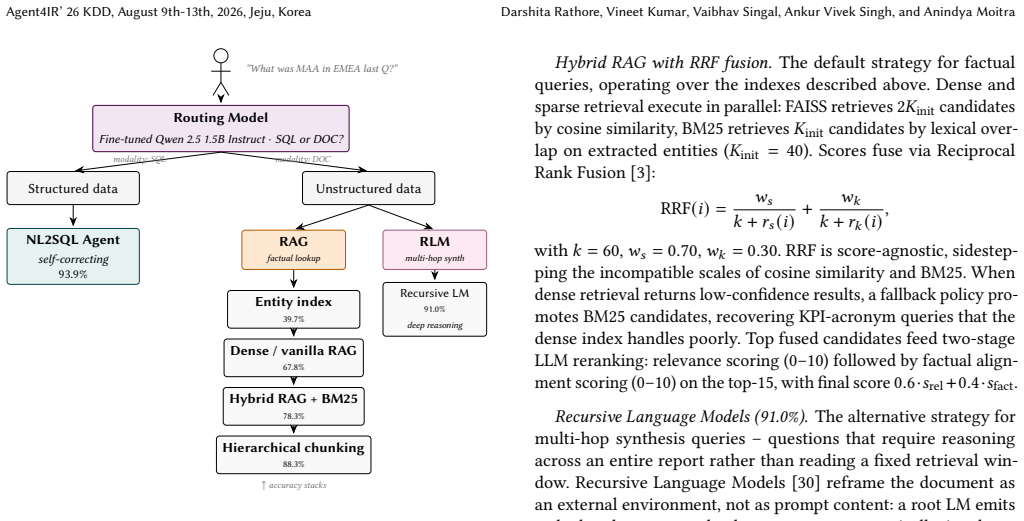
COGNI treats natural-language analytics as a heterogeneous query processing problem organized as four architectural layers. First, an indexing layer implements slide-adaptive chunking for plain-text, tables, charts and key-value blocks. Second, a routing layer built on a LoRA fine-tuned Qwen-2.5-1.5B-Instruct model outputs modality decision and complexity assessment. Third, a retrieval layer runs a self-correcting NL2SQL agent and Recursive Language Models for multi-hop synthesis. Fourth, a caching layer validates query equivalence across multiple dimensions to avoid false hits.
What carries the argument
The four architectural layers that decompose heterogeneous query processing into indexing with slide-adaptive chunking, routing with a fine-tuned small model, retrieval with self-correcting agents, and caching with multi-dimensional equivalence validation.
If this is right
- Users issue a single natural-language question without choosing between SQL and document tools.
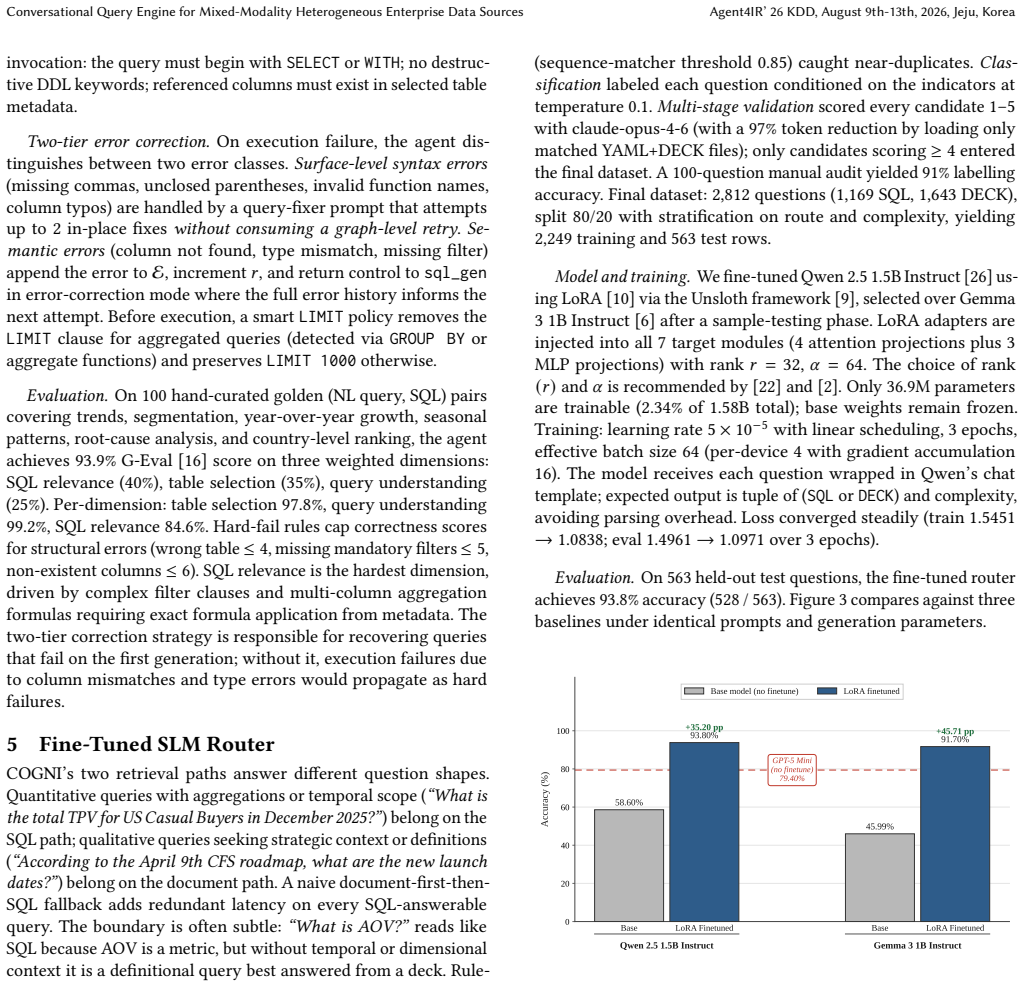
- Modality and complexity decisions run at 93.8 percent accuracy and roughly seven times lower cost than frontier models.
- NL2SQL queries reach 93.9 percent G-Eval and multi-hop synthesis reaches 91.0 percent through self-correction.
- Query caching delivers an 8.4 times latency reduction while producing zero false hits.
Where Pith is reading between the lines
- The same four-layer split could be tested on mixed data in legal discovery or clinical records where structured tables and free-text notes coexist.
- Routing via a 1.5B fine-tuned model suggests that production systems can keep most decisions cheap while reserving larger models for final synthesis.
- Multi-dimensional equivalence validation might improve cache safety in other retrieval systems that currently rely only on embedding similarity.
Load-bearing premise
The internal enterprise benchmark used for all accuracy numbers is representative of real user queries and the evaluation procedures introduce no post-hoc selection or labeling bias.
What would settle it
Running COGNI on a public mixed-modality query set and finding accuracy below the reported 88-93 percent range or any false-positive cache hits on non-equivalent queries would disprove the central performance claims.
Figures

read the original abstract
Enterprise business intelligence queries span structured warehouses and unstructured document repositories -- modalities with fundamentally different access methods, cost profiles, and correctness semantics. Existing AI-enabled interfaces force users to select the right tool: NL2SQL systems cannot reason over slide decks, and RAG pipelines lack access to live warehouse tables. We present COGNI, a production conversational BI system that treats natural-language analytics as a heterogeneous query processing problem, organized as four architectural layers. First, an indexing layer implements slide-adaptive chunking -- recursive chunking for plain-text slides, hierarchical chunking for structured content such as tables, charts, and key-value blocks - achieving $88.3\%$ on our internal enterprise benchmark. Second, a routing layer built on a LoRA fine-tuned Qwen-2.5-1.5B-Instruct model that produces a dual output - modality decision and complexity assessment at $93.8\%$ accuracy and approximately $7\times$ lower cost than frontier-model. Third, a retrieval layer executes complexity-adaptive pipelines: a self-correcting NL2SQL agent at $93.9\%$ G-Eval, and Recursive Language Models reaching $91.0\%$ on multi-hop synthesis queries. Finally, a caching layer validates query equivalence across multiple dimensions beyond embedding similarity, achieving zero false cache hits and $8.4\times$ latency reduction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents COGNI, a production conversational BI system that frames natural-language analytics over mixed structured warehouses and unstructured document repositories as a heterogeneous query processing problem. It describes a four-layer architecture (indexing with slide-adaptive chunking, routing via LoRA-tuned Qwen-2.5-1.5B, retrieval with self-correcting NL2SQL and Recursive Language Models, and multi-dimensional caching) and reports empirical results of 88.3% (indexing), 93.8% (routing), 93.9% G-Eval (NL2SQL), 91.0% (multi-hop synthesis), zero false cache hits, and 8.4× latency reduction, all measured on an internal enterprise benchmark.
Significance. If the results hold under external scrutiny, the work would be significant for enterprise IR by providing a unified production system that avoids forcing users to choose between NL2SQL and RAG pipelines. The explicit layering, cost-efficient LoRA routing, and equivalence-aware caching represent practical engineering contributions that could inform future heterogeneous retrieval systems.
major comments (1)
- [Abstract] Abstract: every reported performance number (88.3%, 93.8%, 93.9% G-Eval, 91.0%, zero false cache hits, 8.4× latency) rests exclusively on a single undisclosed internal enterprise benchmark. No details are supplied on query collection method, modality/complexity distribution, ground-truth labeling protocol, inter-annotator agreement, or precise success criteria, rendering the central empirical claims impossible to reproduce or stress-test for selection or labeling bias.
minor comments (1)
- [Abstract] The terms 'G-Eval' and 'Recursive Language Models' appear without prior definition or citation in the abstract.
Simulated Author's Rebuttal
We thank the referee for their review and for recognizing the practical engineering contributions of the COGNI architecture. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: every reported performance number (88.3%, 93.8%, 93.9% G-Eval, 91.0%, zero false cache hits, 8.4× latency) rests exclusively on a single undisclosed internal enterprise benchmark. No details are supplied on query collection method, modality/complexity distribution, ground-truth labeling protocol, inter-annotator agreement, or precise success criteria, rendering the central empirical claims impossible to reproduce or stress-test for selection or labeling bias.
Authors: We acknowledge the validity of this observation. All reported metrics derive from a single internal enterprise benchmark whose queries, modality distribution, labeling process, inter-annotator agreement, and exact success criteria cannot be disclosed. This restriction stems directly from confidentiality agreements with enterprise clients whose proprietary data populate the benchmark; releasing such information would violate those agreements. Consequently, external reproduction or independent bias auditing is not feasible. We do not view this as a flaw that can be remedied by revision, because the limitation is inherent to any production system paper that must protect client data. The metrics are presented to demonstrate real-world behavior rather than to support exact replication. revision: no
- Disclosure of query collection method, modality/complexity distribution, ground-truth labeling protocol, inter-annotator agreement, or precise success criteria for the internal enterprise benchmark, due to binding confidentiality agreements with enterprise clients.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes a four-layer architecture for COGNI and reports empirical performance numbers (88.3%, 93.8%, 93.9% G-Eval, 91.0%) measured on an internal benchmark. No equations, derivations, fitted parameters, or predictions appear that reduce by construction to inputs, self-citations, or ansatzes. All load-bearing claims are direct experimental results rather than quantities defined in terms of themselves, so the presentation is self-contained with no circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Dan Biderman, Jacob Portes, Jose Javier Gonzalez Ortiz, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, Cody Blakeney, and John Patrick Cunningham. 2024. LoRA Learns Less and Forgets Less.Transactions on Machine Learning Research(2024). https: //openreview.net/forum?id=aloEru2qCG
2024
-
[3]
Cormack, Charles L
Gordon V. Cormack, Charles L. A. Clarke, and Stefan Büttcher. 2009. Reciprocal Rank Fusion Outperforms Condorcet and Individual Rank Learning Methods. InProceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR). ACM, 758–759
2009
-
[4]
Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. 2024. DAIL-SQL: Optimized Few-Shot Text-to-SQL with Retrieval and LLMs.Proceedings of the VLDB Endowment17, 4 (2024), 950–962
2024
-
[5]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. 2024. Retrieval-Augmented Generation for Large Language Models: A Survey.arXiv preprint arXiv:2312.10997(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Gemma Team, Google DeepMind. 2025. Gemma 3 Technical Report. https: //ai.google.dev/gemma. Accessed 2026-04-15
2025
-
[7]
Google Cloud. 2026. BigQuery: Serverless, highly scalable, and cost-effective data warehouse. https://cloud.google.com/bigquery Accessed: 2026-03-30
2026
-
[8]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Yuanzhuo Wang, and Jian Guo
-
[9]
A Survey on LLM-as-a-Judge.arXiv preprint arXiv:2411.15594(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Daniel Han, Michael Han, and Unsloth team. 2024. Unsloth: Faster, more memory- efficient LLM fine-tuning. https://github.com/unslothai/unsloth. GitHub reposi- tory, accessed 2026-04-15
2024
-
[11]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InInternational Conference on Learning Representations (ICLR). https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Kanishka, Chetna Bansal, and Anindya Moitra
Vineet Kumar, Ronald Tony, Darshita Rathore, Vipasha Rana, Bhuvanesh Man- dora, . Kanishka, Chetna Bansal, and Anindya Moitra. 2025. Genicious: Contextual Agent4IR’ 26 KDD, August 9th-13th, 2026, Jeju, Korea Darshita Rathore, Vineet Kumar, Vaibhav Singal, Ankur Vivek Singh, and Anindya Moitra Few-shot Prompting for Insights Discovery. InProceedings of the...
-
[13]
LangChain. 2026. LangGraph: Agent orchestration framework for reliable AI agents. https://www.langchain.com/langgraph Accessed: 2026-03-30
2026
-
[14]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al
-
[15]
In Advances in Neural Information Processing Systems (NeurIPS), Vol
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In Advances in Neural Information Processing Systems (NeurIPS), Vol. 33. 9459–9474
-
[16]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al. 2024. Can LLM Already Serve as a Database Interface? A BIRd Benchmark for Big Bench for Large-Scale Database Grounded Text-to-SQL Evaluation. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 36
2024
-
[17]
Siran Li, Linus Stenzel, Carsten Eickhoff, and Seyed Ali Bahrainian. 2025. Enhanc- ing Retrieval-Augmented Generation: A Study of Best Practices. InProceedings of the 31st International Conference on Computational Linguistics (COLING). 6705– 6717
2025
-
[18]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 2511–2522. doi:...
- [19]
-
[20]
Meta AI (Facebook AI Research). 2026. Faiss: A library for efficient similarity search and clustering of dense vectors. https://faiss.ai/index.html Accessed: 2026-03-30
2026
-
[21]
Microsoft. 2026. SharePoint Collaboration. https://www.microsoft.com/en- in/microsoft-365/sharepoint/collaboration. Accessed: 2026-03-28
2026
-
[22]
Kakkar, Yu Gan, Amin Saberi, Fatma Ozcan, and Sercan Ö
Mohammadreza Pourreza, Hailong Li, Ruochen Sun, Yeounoh Chung, Shayan Talaei, Gaurav T. Kakkar, Yu Gan, Amin Saberi, Fatma Ozcan, and Sercan Ö. Arik
-
[23]
InInternational Conference on Learning Representations (ICLR)
CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL. InInternational Conference on Learning Representations (ICLR)
-
[24]
Mohammadreza Pourreza and Davood Rafiei. 2024. DIN-SQL: Decomposed In- Context Learning of Text-to-SQL with Self-Correction. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 36
2024
-
[25]
Darshita Rathore, Vineet Kumar, Chetna Bansal, and Anindya Moitra. 2025. How Much is Too Much? Exploring LoRA Rank Trade-offs for Retaining Knowledge and Domain Robustness. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguist...
-
[26]
Stephen Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Frame- work: BM25 and Beyond.Foundations and Trends in Information Retrieval3, 4 (2009), 333–389
2009
- [27]
-
[28]
Shayan Talaei, Mohammadreza Pourreza, Yu-Chen Chang, Azalia Mirhoseini, and Amin Saberi. 2024. CHESS: Contextual Harnessing for Efficient SQL Synthesis. arXiv preprint arXiv:2405.16755(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Qwen Team. 2024. Qwen2.5 Technical Report. arXiv:2412.15115 [cs.CL] https: //arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
VectifyAI. 2026. PageIndex: Document Index for Vectorless, Reasoning-based RAG. https://github.com/VectifyAI/PageIndex. GitHub repository, accessed 2026-03-28
2026
-
[31]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR)
2023
-
[32]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, et al. 2018. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP). 3911–3921
2018
-
[33]
Alex L Zhang, Tim Kraska, and Omar Khattab. 2025. Recursive language models. arXiv preprint arXiv:2512.24601(2025). Appendix A Production Model Configuration Component Model Retrieval Embedding text-embedding-3-large (3072d) LLM reranking / answer synthesis claude-sonnet-4-6 Hierarchical extraction (vision) gemini-2.5-flash RLM root / sub-agent GPT-5 / GP...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
ONLY use column names from <db_mapping> tags in metadata
-
[35]
AOV", "ARPA
DO NOT use measure names directly (e.g., "AOV", "ARPA") - these are labels, not columns
-
[36]
For calculated metrics: - Check if there's a <formula> tag - use that exact formula - Otherwise, derive from basic columns (e.g., TPV/Txns for AOV)
-
[37]
Always" or
For column names with spaces or special characters: - Use backticks:`column name with spaces` ***CRITICAL REQUIREMENTS*** - Check table descriptions for mandatory filter requirements - Pay attention to dimension definitions that mention "Always" or "must" requirements - Do not assume or hardcode values for any columns - Prefer subqueries or filtering from...
-
[38]
First, identify what columns exist in <db_mapping> tags
-
[39]
For aggregated metrics mentioned in user query: - Check if column exists in db_mapping - If not, check for <formula> in measures section - If no formula, calculate from base columns
-
[40]
Always validate column names match exactly Give only the SQL as output, no explanations. Conversational Query Engine for Mixed-Modality Heterogeneous Enterprise Data Sources Agent4IR’ 26 KDD, August 9th-13th, 2026, Jeju, Korea B.2 NL2SQL Error Correction Invoked when the previous SQL execution fails. Receives the failed SQL, the error message, and the sch...
2026
-
[41]
Use ONLY BigQuery Standard SQL (not legacy SQL)
-
[42]
Use fully-qualified table names (project.dataset.table)
-
[43]
Map user's natural language to exact column names using synonyms provided
-
[44]
For derived metrics, use the formulas from metadata
-
[45]
ALWAYS include a LIMIT clause (default: LIMIT 1000)
-
[46]
Fix the specific error mentioned
-
[47]
Ensure column names exactly match db_mapping values
-
[48]
Use proper aggregation and GROUP BY clauses
-
[49]
Column X not found
Return ONLY the corrected SQL query, no explanations COMMON ERRORS AND FIXES: - "Column X not found" -> Check db_mapping, use exact name - "Type mismatch" -> Use CAST() for date comparisons - "JOIN error" -> Verify JOIN keys exist in both tables - "WITH clause" -> CTEs allowed, ensure final SELECT has LIMIT Return ONLY the SQL query. B.3 SQL G-Eval Rubric...
-
[50]
QUERY UNDERSTANDING (Weight: 25%) - Does the answer directly address the user's question? - Is the scope correct (timeframe, geography, metrics)? - Is all information grounded in the data? - Is the detail level appropriate?
-
[51]
TABLE SELECTION (Weight: 35%) Score 9-10 if correct table, 7-8 if acceptable, lower if wrong table
-
[52]
SQL RELEVANCE (Weight: 40%) - Are aggregations correct (SUM, AVG, COUNT)? - Are WHERE filters appropriate FOR THE QUESTION ASKED? - Is GROUP BY correct? - Do all columns exist in the table? - Is the SQL logic sound? IMPORTANT: Only require WHERE filters that are NECESSARY to answer the specific question. === HARD-FAIL CAPS === - Wrong table: score <= 4 - ...
-
[53]
Write a 2-3 sentence narrative summary answering the user's question
-
[54]
List 2-4 key highlights as bullet points (trends, patterns, anomalies, or notable values)
-
[55]
Focus on actionable insights
-
[56]
Mention specific numbers and metrics
-
[57]
Flag any data quality issues (nulls, zeros, unexpected values) if present FORMAT: Summary: [2-3 sentence overview] Key Highlights: - [First key finding with specific numbers] - [Second key finding] - [Additional findings as relevant] Return ONLY the formatted insights
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.