Vision-driven Preference Synthesis for Mitigating Hallucinations in VLMs
Pith reviewed 2026-06-30 01:20 UTC · model grok-4.3
The pith
ViPSy builds preference pairs from visual cues in image variants to align VLMs against hallucinations while staying close to the model's own outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
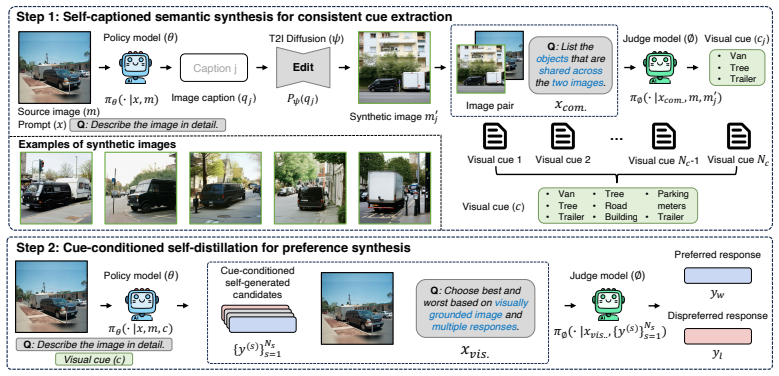
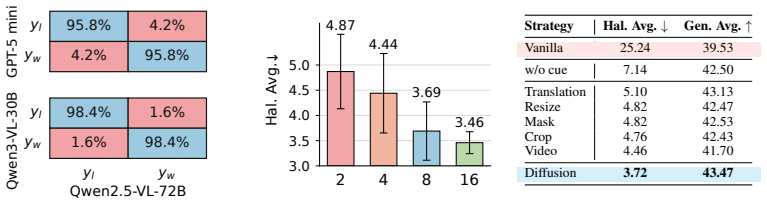
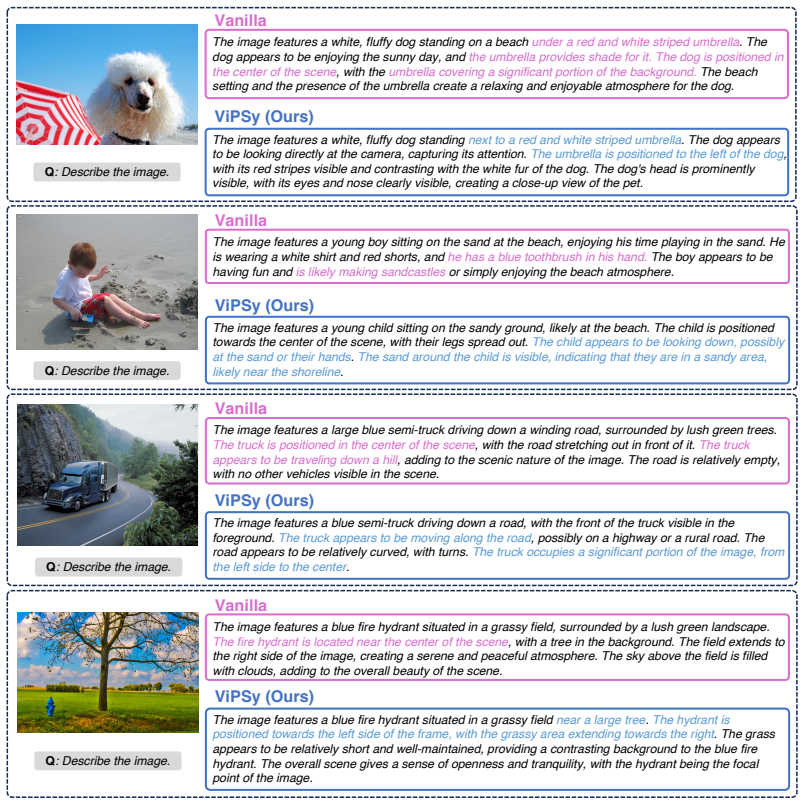
ViPSy derives a visual cue from recurring object-level content across semantically aligned image variants so that preference construction can rely on visual information rather than language priors; in the second stage it conditions the policy's own rollouts on this cue to produce candidates that remain close to the policy distribution while better leveraging visual information from the image. Preference alignment with these pairs yields a VLM that reduces hallucination rates on AMBER and Object HalBench by 35.7 percent and 24.5 percent relative to the prior state-of-the-art method, while also improving on MMStar, MMVP, CV-Bench, semantic segmentation, and ImageNet linear probing.
What carries the argument
ViPSy, the two-stage vision-driven preference synthesis framework that extracts visual cues from recurring objects across image variants to guide policy rollouts for pair construction.
If this is right
- The aligned VLM reduces hallucination rates by 35.7% on AMBER and 24.5% on Object HalBench versus the prior best method.
- The same model records higher scores on the visual grounding benchmarks MMStar, MMVP, and CV-Bench.
- Downstream tasks improve as well, with measurable gains in semantic segmentation accuracy and ImageNet linear probing performance.
Where Pith is reading between the lines
- The same cue-extraction step could be applied to non-object visual elements such as spatial relations or text within images to test whether the benefit generalizes.
- If the two-stage process proves stable, it offers a template for constructing preference data in other multimodal settings where visual grounding is the main failure mode.
Load-bearing premise
Recurring object-level content across semantically aligned image variants supplies a reliable visual cue that lets preference construction rely on visual information rather than language priors.
What would settle it
Re-running the full pipeline on the same VLMs and benchmarks and finding hallucination rates on AMBER and Object HalBench that are no lower than the previous state-of-the-art method would show the claimed gains do not hold.
Figures








read the original abstract
Vision-Language Models (VLMs) have shown strong performance in visual understanding, yet they still suffer from hallucinations, generating content that is not grounded in the image. Preference alignment is a promising approach to improve visual faithfulness, but its success depends heavily on how preference pairs are constructed. Existing methods exhibit two key limitations; (a) intervention-based methods often introduce significant deviation from the policy distribution, and (b) sampling-based methods often underuse visual information during the construction. In this paper, we propose ViPSy (Vision-driven Preference Synthesis), a framework for constructing preference data that are both policy-aligned and visually grounded. Our framework consists of two stages; in the first stage, ViPSy derives a visual cue from recurring object-level content across semantically aligned image variants, so preference construction can rely on visual information rather than language priors. In the second stage, ViPSy conditions the policy's own rollouts on this cue, allowing candidates to be guided by visually grounded content while staying close to the policy's response distribution. The resulting candidates remain close to the policy's response distribution while better leveraging visual information from the image. Experiments show that the resulting VLM, preference-aligned with ViPSy-constructed preference pairs, achieves a new state-of-the-art in hallucination mitigation. Compared with the previous state-of-the-art method, it reduces hallucination rates on AMBER and Object HalBench by 35.7% and 24.5%, respectively. The resulting model further improves on general visual grounding benchmarks, e.g., MMStar, MMVP, and CV-Bench, while also yielding gains in semantic segmentation and ImageNet linear probing, underscoring the effectiveness of our framework in enhancing the model's visual capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ViPSy, a two-stage framework for synthesizing preference pairs to align VLMs and mitigate hallucinations. Stage 1 derives a visual cue from recurring object-level content across semantically aligned image variants so that construction can rely on visual information rather than language priors. Stage 2 conditions the policy's own rollouts on this cue to produce candidates that remain close to the policy distribution while better leveraging visual information. The resulting aligned VLM is reported to achieve new state-of-the-art hallucination mitigation, with 35.7% and 24.5% reductions on AMBER and Object HalBench relative to the prior SOTA, plus gains on MMStar, MMVP, CV-Bench, semantic segmentation, and ImageNet linear probing.
Significance. If the central claims hold after verification, the work would offer a concrete advance in preference alignment for VLMs by addressing both policy deviation and under-use of visual signals. The reported cross-benchmark improvements, including on non-hallucination tasks, would indicate that the synthesized pairs enhance visual grounding more broadly than prior sampling- or intervention-based methods.
major comments (2)
- [Abstract] Abstract: the central performance claim (new SOTA with 35.7% and 24.5% reductions) is presented without any experimental protocol, baseline details, statistical tests, ablation results, or dataset splits, rendering the quantitative results unverifiable from the supplied text.
- [Abstract] Abstract (first stage description): the assertion that the visual cue 'derives ... so preference construction can rely on visual information rather than language priors' is load-bearing for the claimed advantage over sampling-based methods, yet no mechanism, metric, or validation is supplied to confirm that the cue extraction is independent of language priors; if the cue remains correlated with priors, the second-stage rollouts cannot be guaranteed to improve visual faithfulness.
minor comments (1)
- [Abstract] Abstract: the specific base VLM, preference-alignment algorithm (e.g., DPO), and exact construction of 'semantically aligned image variants' are not named.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that greater clarity is needed to support the central claims and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim (new SOTA with 35.7% and 24.5% reductions) is presented without any experimental protocol, baseline details, statistical tests, ablation results, or dataset splits, rendering the quantitative results unverifiable from the supplied text.
Authors: We agree that the abstract would benefit from additional context to improve verifiability. In the revised manuscript we will expand the abstract to include a brief statement of the evaluation protocol (standard benchmarks AMBER and Object HalBench, comparison against prior SOTA preference-alignment methods), while directing readers to Sections 4 and 5 for full details on baselines, statistical tests, ablations, and dataset splits. revision: yes
-
Referee: [Abstract] Abstract (first stage description): the assertion that the visual cue 'derives ... so preference construction can rely on visual information rather than language priors' is load-bearing for the claimed advantage over sampling-based methods, yet no mechanism, metric, or validation is supplied to confirm that the cue extraction is independent of language priors; if the cue remains correlated with priors, the second-stage rollouts cannot be guaranteed to improve visual faithfulness.
Authors: The mechanism for cue extraction (recurring object-level content identified via visual similarity across semantically aligned image variants) is described in Section 3.1 and validated for independence from language priors via ablation in Section 4.3. We will revise the abstract to briefly reference the visual-similarity metric. Full mechanism, metrics, and validation results remain in the main text due to abstract length constraints. revision: partial
Circularity Check
No circularity: empirical method construction with no self-referential derivations
full rationale
The paper describes a two-stage framework (ViPSy) for synthesizing preference pairs from image variants and policy rollouts. No equations, fitted parameters, or mathematical derivations are present in the provided text. The central claims rest on empirical outcomes after alignment rather than any quantity that reduces to its own inputs by construction. Stage 1 cue extraction and Stage 2 conditioning are procedural steps for data generation, not self-definitional or fitted-input predictions. No self-citations are invoked as load-bearing uniqueness theorems. The derivation chain is therefore self-contained as a constructive method whose validity is tested externally via benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Improved Baselines with Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved Baselines with Visual Instruction Tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
2024
-
[2]
Flamingo: a Visual Language Model for Few-Shot Learning.Advances in neural information processing systems, 35:23716–23736, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a Visual Language Model for Few-Shot Learning.Advances in neural information processing systems, 35:23716–23736, 2022
2022
-
[3]
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning.Advances in neural information processing systems, 36:49250–49267, 2023
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning.Advances in neural information processing systems, 36:49250–49267, 2023
2023
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-VL Technical Report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
GPT-4V(ision) System Card, 2023
OpenAI. GPT-4V(ision) System Card, 2023. URL https://api.semanticscholar.org/CorpusID: 263218031
2023
-
[6]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning Transferable Visual Models From Natural Language Supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[7]
Sigmoid Loss for Language Image Pre-Training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid Loss for Language Image Pre-Training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
-
[8]
Gonzalez, Ion Stoica, and Eric P
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality, March 2023. URL https://lmsys.org/ blog/2023-03-30-vicuna/
2023
-
[9]
Qwen2.5-Coder Technical Report
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. Qwen2.5-Coder technical report.arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts.arXiv preprint arXiv:2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
LLaV A-Docent: Instruction Tuning with Multimodal Large Language Model to Support Art Appreciation Education.Computers and Education: Artificial Intelligence, 7:100297, 2024
Unggi Lee, Minji Jeon, Yunseo Lee, Gyuri Byun, Yoorim Son, Jaeyoon Shin, Hongkyu Ko, and Hyeon- cheol Kim. LLaV A-Docent: Instruction Tuning with Multimodal Large Language Model to Support Art Appreciation Education.Computers and Education: Artificial Intelligence, 7:100297, 2024
2024
-
[12]
LLaV A-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day.Advances in Neural Information Processing Systems, 36:28541–28564, 2023
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. LLaV A-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day.Advances in Neural Information Processing Systems, 36:28541–28564, 2023
2023
-
[13]
Yizhen Luo, Jiahuan Zhang, Siqi Fan, Kai Yang, Yushuai Wu, Mu Qiao, and Zaiqing Nie. BioMedGPT: Open Multimodal Generative Pre-trained Transformer for BioMedicine.arXiv preprint arXiv:2308.09442, 2023
-
[14]
Med-Flamingo: a Multimodal Medical Few-shot Learner
Michael Moor, Qian Huang, Shirley Wu, Michihiro Yasunaga, Yash Dalmia, Jure Leskovec, Cyril Zakka, Eduardo Pontes Reis, and Pranav Rajpurkar. Med-Flamingo: a Multimodal Medical Few-shot Learner. InMachine learning for health (ML4H), pages 353–367. PMLR, 2023
2023
-
[15]
WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation
Jongheon Jeong, Yang Zou, Taewan Kim, Dongqing Zhang, Avinash Ravichandran, and Onkar Dabeer. WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19606–19616, 2023
2023
-
[16]
AnomalyGPT: Detecting Industrial Anomalies Using Large Vision-Language Models
Zhaopeng Gu, Bingke Zhu, Guibo Zhu, Yingying Chen, Ming Tang, and Jinqiao Wang. AnomalyGPT: Detecting Industrial Anomalies Using Large Vision-Language Models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 1932–1940, 2024
1932
-
[17]
Xi Jiang, Jian Li, Hanqiu Deng, Yong Liu, Bin-Bin Gao, Yifeng Zhou, Jialin Li, Chengjie Wang, and Feng Zheng. MMAD: A Comprehensive Benchmark for Multimodal Large Language Models in Industrial Anomaly Detection.arXiv preprint arXiv:2410.09453, 2024. 10
-
[18]
Chuyan Xiong, Chengyu Shen, Xiaoqi Li, Kaichen Zhou, Jeremy Liu, Ruiping Wang, and Hao Dong. AIC MLLM: Autonomous Interactive Correction MLLM for Robust Robotic Manipulation.arXiv preprint arXiv:2406.11548, 2024
-
[19]
Jinyi Liu, Yifu Yuan, Jianye Hao, Fei Ni, Lingzhi Fu, Yibin Chen, and Yan Zheng. Enhancing Robotic Ma- nipulation with AI Feedback from Multimodal Large Language Models.arXiv preprint arXiv:2402.14245, 2024
-
[20]
ManipLLM: Embodied Multimodal Large Language Model for Object-Centric Robotic Manipulation
Xiaoqi Li, Mingxu Zhang, Yiran Geng, Haoran Geng, Yuxing Long, Yan Shen, Renrui Zhang, Jiaming Liu, and Hao Dong. ManipLLM: Embodied Multimodal Large Language Model for Object-Centric Robotic Manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18061–18070, 2024
2024
-
[21]
Detecting and Preventing Hallucinations in Large Vision Language Models
Anisha Gunjal, Jihan Yin, and Erhan Bas. Detecting and Preventing Hallucinations in Large Vision Language Models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 18135–18143, 2024
2024
-
[22]
HallusionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination and Visual Illusion in Large Vision-Language Models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. HallusionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination and Visual Illusion in Large Vision-Language Models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pag...
2024
-
[23]
Overcoming Language Priors in Visual Question Answering via Distinguishing Superficially Similar Instances
Yike Wu, Yu Zhao, Shiwan Zhao, Ying Zhang, Xiaojie Yuan, Guoqing Zhao, and Ning Jiang. Overcoming Language Priors in Visual Question Answering via Distinguishing Superficially Similar Instances. In Proceedings of the 29th International Conference on Computational Linguistics, pages 5721–5729, 2022
2022
-
[24]
Yudong Han, Liqiang Nie, Jianhua Yin, Jianlong Wu, and Yan Yan. Visual Perturbation-aware Col- laborative Learning for Overcoming the Language Prior Problem.arXiv preprint arXiv:2207.11850, 2022
-
[25]
Overcoming Language Priors with Counterfactual Inference for Visual Question Answering
Ren Zhibo, Wang Huizhen, Zhu Muhua, Wang Yichao, Xiao Tong, and Zhu Jingbo. Overcoming Language Priors with Counterfactual Inference for Visual Question Answering. InProceedings of the 22nd Chinese National Conference on Computational Linguistics, pages 600–610, 2023
2023
-
[26]
V olcano: Mitigating Multimodal Hallu- cination through Self-Feedback Guided Revision
Seongyun Lee, Sue Hyun Park, Yongrae Jo, and Minjoon Seo. V olcano: Mitigating Multimodal Hallu- cination through Self-Feedback Guided Revision. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 391–404, 2024
2024
-
[27]
Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13872– 13882, 2024
2024
-
[28]
Analyzing the Behavior of Visual Question Answering Models
Aishwarya Agrawal, Dhruv Batra, and Devi Parikh. Analyzing the Behavior of Visual Question Answering Models. InProceedings of the 2016 conference on empirical methods in natural language processing, pages 1955–1960, 2016
2016
-
[29]
Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017
2017
-
[30]
Towards Causal VQA: Revealing and Reducing Spurious Correlations by Invariant and Covariant Semantic Editing
Vedika Agarwal, Rakshith Shetty, and Mario Fritz. Towards Causal VQA: Revealing and Reducing Spurious Correlations by Invariant and Covariant Semantic Editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9690–9698, 2020
2020
-
[31]
Yiyang Huang, Liang Shi, Yitian Zhang, Yi Xu, and Yun Fu. SHIELD: Suppressing Hallucinations In LVLM Encoders via Bias and Vulnerability Defense.arXiv preprint arXiv:2510.16596, 2025
-
[32]
Beyond Hallucinations: Enhancing LVLMs through Hallucination-Aware Direct Preference Optimization
Zhiyuan Zhao, Bin Wang, Linke Ouyang, Xiaoyi Dong, Jiaqi Wang, and Conghui He. Beyond Hallucina- tions: Enhancing LVLMs through Hallucination-Aware Direct Preference Optimization.arXiv preprint arXiv:2311.16839, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Mitigating Object Hallucinations via Sentence- Level Early Intervention
Shangpin Peng, Senqiao Yang, Li Jiang, and Zhuotao Tian. Mitigating Object Hallucinations via Sentence- Level Early Intervention. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 635–646, 2025. 11
2025
-
[34]
Zhihe Yang, Xufang Luo, Dongqi Han, Yunjian Xu, and Dongsheng Li. Mitigating Hallucinations in Large Vision-Language Models via DPO: On-Policy Data Hold the Key.arXiv preprint arXiv:2501.09695, 2025
-
[35]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model.Advances in neural information processing systems, 36:53728–53741, 2023
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct Preference Optimization: Your Language Model is Secretly a Reward Model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[36]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-Tuning Language Models from Human Preferences.arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[37]
Learning to summarize from human feedback.Advances in neural information processing systems, 33:3008–3021, 2020
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize from human feedback.Advances in neural information processing systems, 33:3008–3021, 2020
2020
-
[38]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[39]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
Aligning Large Multimodal Models with Factually Augmented RLHF
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liangyan Gui, Yu-Xiong Wang, Yiming Yang, et al. Aligning Large Multimodal Models with Factually Augmented RLHF. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13088–13110, 2024
2024
-
[41]
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jérémy Scheurer, Javier Rando, Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, et al. Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback.arXiv preprint arXiv:2307.15217, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Parameter Efficient Reinforcement Learning from Human Feedback.arXiv preprint arXiv:2403.10704, 2024
Hakim Sidahmed, Samrat Phatale, Alex Hutcheson, Zhuonan Lin, Zhang Chen, Zac Yu, Jarvis Jin, Simral Chaudhary, Roman Komarytsia, Christiane Ahlheim, et al. Parameter Efficient Reinforcement Learning from Human Feedback.arXiv preprint arXiv:2403.10704, 2024
-
[43]
Provably Efficient Online RLHF with One-Pass Reward Modeling.arXiv preprint arXiv:2502.07193, 2025
Long-Fei Li, Yu-Yang Qian, Peng Zhao, and Zhi-Hua Zhou. Provably Efficient Online RLHF with One-Pass Reward Modeling.arXiv preprint arXiv:2502.07193, 2025
-
[44]
Unpacking DPO and PPO: Disentangling Best Practices for Learning from Preference Feedback.Advances in neural information processing systems, 37:36602– 36633, 2024
Hamish Ivison, Yizhong Wang, Jiacheng Liu, Zeqiu Wu, Valentina Pyatkin, Nathan Lambert, Noah A Smith, Yejin Choi, and Hannaneh Hajishirzi. Unpacking DPO and PPO: Disentangling Best Practices for Learning from Preference Feedback.Advances in neural information processing systems, 37:36602– 36633, 2024
2024
-
[45]
What Matters in Data for DPO?arXiv preprint arXiv:2508.18312, 2025
Yu Pan, Zhongze Cai, Guanting Chen, Huaiyang Zhong, and Chonghuan Wang. What Matters in Data for DPO?arXiv preprint arXiv:2508.18312, 2025
-
[46]
Aligning Modalities in Vision Large Language Models via Preference Fine-tuning
Yiyang Zhou, Chenhang Cui, Rafael Rafailov, Chelsea Finn, and Huaxiu Yao. Aligning Modalities in Vision Large Language Models via Preference Fine-tuning.arXiv preprint arXiv:2402.11411, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Arık, and Tomas Pfister
Pritam Sarkar, Sayna Ebrahimi, Ali Etemad, Ahmad Beirami, Sercan Ö. Arık, and Tomas Pfister. Mitigating Object Hallucination in MLLMs via Data-augmented Phrase-level Alignment, 2024
2024
-
[48]
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine- Grained AI Feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Fangxun Shu, Hao Jiang, and Linchao Zhu. Detecting and Mitigating Hallucination in Large Vision Language Models via Fine- Grained AI Feedback. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 25543–25551, 2025
2025
-
[49]
Tianyu Yu, Haoye Zhang, Yuan Yao, Yunkai Dang, Da Chen, Xiaoman Lu, Ganqu Cui, Taiwen He, Zhiyuan Liu, Tat-Seng Chua, et al. RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness.arXiv preprint arXiv:2405.17220, 2(3):8, 2024
-
[50]
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes. InThe twelfth international conference on learning representations, 2024. 12
2024
-
[51]
Self- Distillation Bridges Distribution Gap in Language Model Fine-Tuning
Zhaorui Yang, Tianyu Pang, Haozhe Feng, Han Wang, Wei Chen, Minfeng Zhu, and Qian Liu. Self- Distillation Bridges Distribution Gap in Language Model Fine-Tuning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1028–1043, 2024
2024
-
[52]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[53]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal Policy Optimization Algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[54]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional AI: Harmlessness from AI Feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[55]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
SLiC-HF: Sequence Likelihood Calibration with Human Feedback.arXiv preprint arXiv:2305.10425, 2023
Yao Zhao, Rishabh Joshi, Tianqi Liu, Misha Khalman, Mohammad Saleh, and Peter J Liu. SLiC-HF: Sequence Likelihood Calibration with Human Feedback.arXiv preprint arXiv:2305.10425, 2023
-
[57]
A General Theoretical Paradigm to Understand Learning from Human Preferences
Mohammad Gheshlaghi Azar, Zhaohan Daniel Guo, Bilal Piot, Remi Munos, Mark Rowland, Michal Valko, and Daniele Calandriello. A General Theoretical Paradigm to Understand Learning from Human Preferences. InInternational Conference on Artificial Intelligence and Statistics, pages 4447–4455. PMLR, 2024
2024
-
[58]
KTO: Model Alignment as Prospect Theoretic Optimization
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. KTO: Model Alignment as Prospect Theoretic Optimization.arXiv preprint arXiv:2402.01306, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
ORPO: Monolithic Preference Optimization without Reference Model
Jiwoo Hong, Noah Lee, and James Thorne. ORPO: Monolithic Preference Optimization without Reference Model. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 11170–11189, 2024
2024
-
[60]
SimPO: Simple Preference Optimization with a Reference- Free Reward.Advances in Neural Information Processing Systems, 37:124198–124235, 2024
Yu Meng, Mengzhou Xia, and Danqi Chen. SimPO: Simple Preference Optimization with a Reference- Free Reward.Advances in Neural Information Processing Systems, 37:124198–124235, 2024
2024
-
[61]
V-DPO: Mitigating Hallucination in Large Vision Language Models via Vision-Guided Direct Preference Optimization
Yuxi Xie, Guanzhen Li, Xiao Xu, and Min-Yen Kan. V-DPO: Mitigating Hallucination in Large Vision Language Models via Vision-Guided Direct Preference Optimization. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 13258–13273, 2024
2024
-
[62]
Songtao Jiang, Yan Zhang, Ruizhe Chen, Tianxiang Hu, Yeying Jin, Qinglin He, Yang Feng, Jian Wu, and Zuozhu Liu. Modality-Fair Preference Optimization for Trustworthy MLLM Alignment.arXiv preprint arXiv:2410.15334, 2024
-
[63]
mDPO: Conditional Preference Optimization for Multimodal Large Language Models
Fei Wang, Wenxuan Zhou, James Y Huang, Nan Xu, Sheng Zhang, Hoifung Poon, and Muhao Chen. mDPO: Conditional Preference Optimization for Multimodal Large Language Models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8078–8088, 2024
2024
-
[64]
Wenqi Liu, Xuemeng Song, Jiaxi Li, Yinwei Wei, Na Zheng, Jianhua Yin, and Liqiang Nie. Mitigating Hallucination Through Theory-Consistent Symmetric Multimodal Preference Optimization.arXiv preprint arXiv:2506.11712, 2025
-
[65]
RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, et al. RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13807–13816, 2024
2024
-
[66]
Fu, X., Hu, Y ., Li, B., Feng, Y ., Wang, H., Lin, X., Roth, D., Smith, N
Lehan He, Zeren Chen, Zhelun Shi, Tianyu Yu, Jing Shao, and Lu Sheng. Systematic Reward Gap Optimization for Mitigating VLM Hallucinations.arXiv preprint arXiv:2411.17265, 2024
-
[67]
Strengthening Multimodal Large Language Model with Bootstrapped Preference Optimization
Renjie Pi, Tianyang Han, Wei Xiong, Jipeng Zhang, Runtao Liu, Rui Pan, and Tong Zhang. Strengthening Multimodal Large Language Model with Bootstrapped Preference Optimization. InEuropean Conference on Computer Vision, pages 382–398. Springer, 2024
2024
-
[68]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection. InEuropean conference on computer vision, pages 38–55. Springer, 2024. 13
2024
-
[69]
YOLO-World: Real-Time Open-V ocabulary Object Detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, and Ying Shan. YOLO-World: Real-Time Open-V ocabulary Object Detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16901–16911, 2024
2024
-
[70]
Fahim Tajwar, Anikait Singh, Archit Sharma, Rafael Rafailov, Jeff Schneider, Tengyang Xie, Stefano Ermon, Chelsea Finn, and Aviral Kumar. Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data.arXiv preprint arXiv:2404.14367, 2024
-
[71]
Self-instruct: Aligning language models with self-generated instructions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions. In Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 13484–13508, 2023
2023
-
[72]
Self-Rewarding Language Models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-Rewarding Language Models.arXiv preprint arXiv:2401.10020, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
Self-Play Preference Optimization for Language Model Alignment.arXiv preprint arXiv:2405.00675, 2024
Yue Wu, Zhiqing Sun, Huizhuo Yuan, Kaixuan Ji, Yiming Yang, and Quanquan Gu. Self-Play Preference Optimization for Language Model Alignment.arXiv preprint arXiv:2405.00675, 2024
-
[74]
Qingxiu Dong, Li Dong, Xingxing Zhang, Zhifang Sui, and Furu Wei. Self-Boosting Large Language Models with Synthetic Preference Data.arXiv preprint arXiv:2410.06961, 2024
-
[75]
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James Glass, and Pengcheng He. DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models.arXiv preprint arXiv:2309.03883, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[76]
OPERA: Alleviating Hallucination in Multi-Modal Large Language Models via Over-Trust Penalty and Retrospection-Allocation
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. OPERA: Alleviating Hallucination in Multi-Modal Large Language Models via Over-Trust Penalty and Retrospection-Allocation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13418–13427, 2024
2024
-
[77]
EFUF: Efficient Fine-grained Unlearning Framework for Mitigating Hallucinations in Multimodal Large Language Models
Shangyu Xing, Fei Zhao, Zhen Wu, Tuo An, Weihao Chen, Chunhui Li, Jianbing Zhang, and Xinyu Dai. EFUF: Efficient Fine-grained Unlearning Framework for Mitigating Hallucinations in Multimodal Large Language Models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1167–1181, 2024
2024
-
[78]
Qwen2.5-VL, January 2025
Qwen Team. Qwen2.5-VL, January 2025. URLhttps://qwenlm.github.io/blog/qwen2.5-vl/
2025
-
[79]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. InForty-first international conference on machine learning, 2024
2024
-
[80]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.