BV-Blend: Uncertainty-Weighted Historical Baselines for Stable Critic-Free RL with Verifiable Rewards
Pith reviewed 2026-06-30 10:04 UTC · model grok-4.3
The pith
BV-Blend stabilizes advantage estimation in critic-free RL by blending prompt-local statistics with semantic-cluster historical moments using an SEM-derived weight.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BV-Blend maintains EMA-tracked reward moments for each cluster, derives a confidence weight from a standard error of the mean (SEM) proxy, and uses this weight to blend historical and prompt-local baseline and variance statistics into a standardized advantage for PPO-style clipped updates.
What carries the argument
The uncertainty-weighted blending mechanism that combines prompt-local on-policy statistics with semantic-cluster-conditioned historical moments via an SEM proxy weight.
If this is right
- Prevents zero advantages when within-group reward variance is zero
- Enables learning from binary verifiers in cold-start regimes
- Improves training stability on verifiable reasoning tasks
- Supports critic-free PPO-style updates without added memory overhead
Where Pith is reading between the lines
- The method could be tested with alternative cluster definitions beyond semantics, such as by task category.
- Historical blending might reduce the need for large group sizes in on-policy sampling.
- This approach may generalize to other RL settings where reward variance is sparse.
Load-bearing premise
Semantic clusters can be reliably identified such that historical reward moments from those clusters are relevant and unbiased for the current prompt group, and the SEM proxy produces a useful blending weight.
What would settle it
A direct comparison showing that removing the historical blending component causes training to stall in identical-reward cases while the full method does not.
Figures

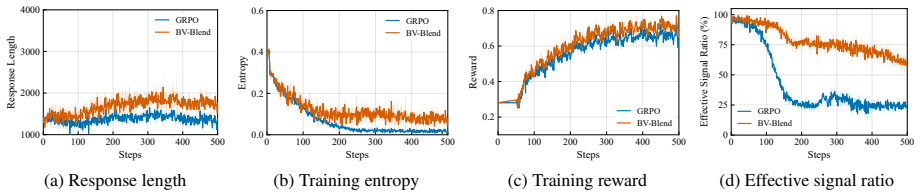
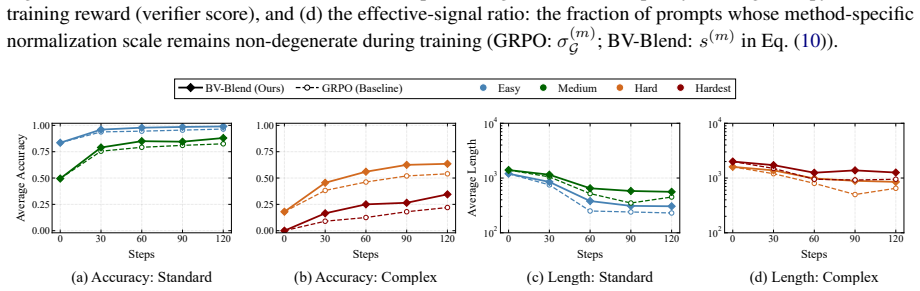

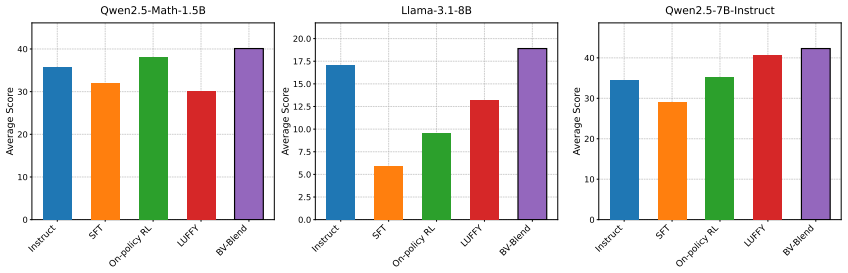
read the original abstract
Critic-free reinforcement learning with verifiable rewards (RLVR), exemplified by Group Relative Policy Optimization (GRPO), avoids training a value function (critic) and reduces memory and compute overhead relative to critic-based PPO pipelines for aligning large language models. However, GRPO-style advantage estimation depends on prompt-local (within-prompt-group) reward statistics and can be unstable. In particular, when all rollouts in a prompt group receive identical rewards, the within-group reward variance becomes zero, and group normalization yields zero advantages for that group, impeding learning in cold-start regimes with binary verifiers. We introduce BV-Blend, a critic-free framework that stabilizes advantage estimation by combining prompt-local on-policy statistics with semantic-cluster-conditioned historical moments. BV-Blend maintains EMA-tracked reward moments for each cluster, derives a confidence weight from a standard error of the mean (SEM) proxy, and uses this weight to blend historical and prompt-local baseline and variance statistics into a standardized advantage for PPO-style clipped updates. Experiments on verifiable reasoning benchmarks show that BV-Blend improves training stability and performance, and remains robust in regimes where group-normalized methods may stall.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that BV-Blend stabilizes advantage estimation in critic-free RLVR (e.g., GRPO) by blending prompt-local on-policy reward statistics with EMA-tracked historical moments from semantic clusters, using an SEM-derived confidence weight to produce standardized advantages for PPO-style clipped updates. This is intended to prevent zero-advantage stalls when within-group variance is zero (common with binary verifiers). Experiments on verifiable reasoning benchmarks are stated to show improved stability and performance.
Significance. If the empirical results and unbiasedness properties hold, the method offers a low-overhead way to mitigate a known instability in critic-free RL for LLM alignment, potentially enabling more reliable training in sparse-reward regimes without adding a value network.
major comments (3)
- [Abstract] Abstract: the claim that 'experiments show that BV-Blend improves training stability and performance' is unsupported by any quantitative results, error bars, ablation details, number of seeds, or benchmark names, rendering the central empirical claim unevaluable from the manuscript.
- [Method] Method description: no derivation or analysis establishes that the blended advantage estimator remains unbiased or mean-zero after policy updates, nor provides bias bounds when embedding-based semantic clusters fail to align with reward-relevant features; this assumption is load-bearing for the stability claim in non-stationary RL.
- [Experiments] Experiments section (implied): the robustness claim in regimes where group-normalized methods stall lacks any reported implementation specifics, variance metrics, or comparison tables, preventing assessment of whether the SEM proxy introduces new variance.
minor comments (2)
- [Method] The precise formula for the SEM proxy and the blending weight is not given as an equation, leaving the weighting mechanism underspecified.
- [Abstract] The paper does not list the specific verifiable reasoning benchmarks or datasets used, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our work. We address each major comment in detail below and commit to substantial revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'experiments show that BV-Blend improves training stability and performance' is unsupported by any quantitative results, error bars, ablation details, number of seeds, or benchmark names, rendering the central empirical claim unevaluable from the manuscript.
Authors: We acknowledge this limitation in the current abstract. Although the full manuscript includes experimental results on verifiable reasoning benchmarks, the abstract does not provide the requested quantitative details. We will revise the abstract to include specific performance metrics with error bars, the number of seeds, key ablation findings, and benchmark names to make the empirical claims fully evaluable. revision: yes
-
Referee: [Method] Method description: no derivation or analysis establishes that the blended advantage estimator remains unbiased or mean-zero after policy updates, nor provides bias bounds when embedding-based semantic clusters fail to align with reward-relevant features; this assumption is load-bearing for the stability claim in non-stationary RL.
Authors: The referee raises an important point regarding the theoretical foundations. The manuscript describes the blending procedure but lacks a formal analysis of the estimator's unbiasedness properties or bias bounds under cluster misalignment. We will add a dedicated analysis subsection deriving the mean-zero property under the stated assumptions and providing discussion of potential biases in non-stationary environments when semantic clusters do not perfectly align with reward features. revision: yes
-
Referee: [Experiments] Experiments section (implied): the robustness claim in regimes where group-normalized methods stall lacks any reported implementation specifics, variance metrics, or comparison tables, preventing assessment of whether the SEM proxy introduces new variance.
Authors: We agree that the experimental validation of the robustness claims requires more detail. We will expand the experiments section to report implementation specifics for handling zero-variance cases, include variance metrics (e.g., standard deviations across multiple seeds), and add comparison tables against baseline group-normalized methods. This will allow assessment of any additional variance introduced by the SEM proxy. revision: yes
Circularity Check
No circularity detected in provided description
full rationale
The abstract and reader's summary describe a blending procedure using prompt-local statistics, EMA historical moments, and an SEM-derived weight, but contain no equations, derivations, or self-citations that reduce the advantage estimator to its inputs by construction. No load-bearing steps match the enumerated circularity patterns (self-definitional, fitted-input-called-prediction, etc.). The method is presented as a new stabilization technique without invoking uniqueness theorems or renaming known results. This matches the expectation that most papers show no circularity when no explicit reduction is exhibited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The method of paired comparisons , author=
Rank analysis of incomplete block designs: I. The method of paired comparisons , author=. Biometrika , volume=. 1952 , publisher=
1952
-
[2]
Rethinking Entropy Interventions in RLVR: An Entropy Change Perspective
Rethinking entropy interventions in rlvr: An entropy change perspective , author=. arXiv preprint arXiv:2510.10150 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
2026 , eprint=
ActorMind: Emulating Human Actor Reasoning for Speech Role-Playing , author=. 2026 , eprint=
2026
-
[4]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
ReTrack: Evidence-Driven Dual-Stream Directional Anchor Calibration Network for Composed Video Retrieval , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[5]
Haonan Dong and Wenhao Zhu and Guojie Song and Liang Wang , booktitle=. Auro. 2025 , url=
2025
-
[6]
Preconditioned Test-Time Adaptation for Out-of-Distribution Debiasing in Narrative Generation
Preconditioned Test-Time Adaptation for Out-of-Distribution Debiasing in Narrative Generation , author=. arXiv preprint arXiv:2603.13683 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
2026 , url=
Yupeng Chang and Yi Chang and Yuan Wu , booktitle=. 2026 , url=
2026
-
[8]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
LoRA-MGPO: Mitigating Double Descent in Low-Rank Adaptation via Momentum-Guided Perturbation Optimization , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
2025
-
[9]
Findings of the Association for Computational Linguistics: ACL 2025 , year =
GA-S^3 : Comprehensive Social Network Simulation with Group Agents , author =. Findings of the Association for Computational Linguistics: ACL 2025 , year =
2025
-
[10]
2026 , eprint =
Semantic-Aware Logical Reasoning via a Semiotic Framework , author =. 2026 , eprint =
2026
-
[11]
2026 , eprint =
Logical Phase Transitions: Understanding Collapse in LLM Logical Reasoning , author =. 2026 , eprint =
2026
-
[12]
2026 , eprint =
Coupling Macro Dynamics and Micro States for Long-Horizon Social Simulation , author =. 2026 , eprint =
2026
-
[13]
arXiv preprint arXiv:2602.13035 , year=
Look Inward to Explore Outward: Learning Temperature Policy from LLM Internal States via Hierarchical RL , author=. arXiv preprint arXiv:2602.13035 , year=
-
[14]
2026 , eprint=
NeuReasoner: Towards Explainable, Controllable, and Unified Reasoning via Mixture-of-Neurons , author=. 2026 , eprint=
2026
-
[15]
2026 , eprint=
FoE: Forest of Errors Makes the First Solution the Best in Large Reasoning Models , author=. 2026 , eprint=
2026
-
[16]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
HABIT: Chrono-Synergia Robust Progressive Learning Framework for Composed Image Retrieval , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[17]
Prototype Conditioned Generative Replay for Continual Learning in NLP
Chen, Xi and Zeng, Min. Prototype Conditioned Generative Replay for Continual Learning in NLP. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naacl-long.636
-
[18]
2026 , eprint=
GRASS: Gradient-based Adaptive Layer-wise Importance Sampling for Memory-efficient Large Language Model Fine-tuning , author=. 2026 , eprint=
2026
-
[19]
Table-R1: Region-based Reinforcement Learning for Table Understanding
Table-r1: Region-based reinforcement learning for table understanding , author=. arXiv preprint arXiv:2505.12415 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
UCS-SQL: uniting content and structure for enhanced semantic bridging in text-to-sql , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[21]
International Conference on Database Systems for Advanced Applications , pages=
MR-SQL: multi-level retrieval enhances inference for llm in text-to-sql , author=. International Conference on Database Systems for Advanced Applications , pages=. 2025 , organization=
2025
-
[22]
ReCreate: Reasoning and Creating Domain Agents Driven by Experience
ReCreate: Reasoning and Creating Domain Agents Driven by Experience , author=. arXiv preprint arXiv:2601.11100 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Chat templates , author =
-
[24]
2025 , month = feb, day =
Fixing Open LLM Leaderboard and Introducing Math-Verify , author =. 2025 , month = feb, day =
2025
-
[25]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
The Twelfth International Conference on Learning Representations , year=
Let's verify step by step , author=. The Twelfth International Conference on Learning Representations , year=
-
[27]
arXiv preprint arXiv:2509.21880 , year=
No prompt left behind: Exploiting zero-variance prompts in llm reinforcement learning via entropy-guided advantage shaping , author=. arXiv preprint arXiv:2509.21880 , year=
-
[28]
arXiv preprint arXiv:2503.23829 , year=
Crossing the Reward Bridge: Expanding RL with Verifiable Rewards Across Diverse Domains , author=. arXiv preprint arXiv:2503.23829 , year=
-
[29]
Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base llms , author=. arXiv preprint arXiv:2506.14245 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[31]
RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
Rlaif: Scaling reinforcement learning from human feedback with ai feedback , author=. arXiv preprint arXiv:2309.00267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Constitutional AI: Harmlessness from AI Feedback
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Advances in Neural Information Processing Systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
arXiv preprint arXiv:2401.06080 , year=
Secrets of rlhf in large language models part ii: Reward modeling , author=. arXiv preprint arXiv:2401.06080 , year=
-
[35]
International Conference on Artificial Intelligence and Statistics , pages=
A general theoretical paradigm to understand learning from human preferences , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
2024
-
[36]
KTO: Model Alignment as Prospect Theoretic Optimization
Kto: Model alignment as prospect theoretic optimization , author=. arXiv preprint arXiv:2402.01306 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
arXiv preprint arXiv:2401.08417 , year=
Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation , author=. arXiv preprint arXiv:2401.08417 , year=
-
[38]
ORPO: Monolithic Preference Optimization without Reference Model
Reference-free monolithic preference optimization with odds ratio , author=. arXiv preprint arXiv:2403.07691 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
arXiv preprint arXiv:2406.06424 , year=
Margin-aware Preference Optimization for Aligning Diffusion Models without Reference , author=. arXiv preprint arXiv:2406.06424 , year=
-
[40]
Simpo: Simple preference optimization with a reference- free reward.arXiv preprint arXiv:2405.14734,
Simpo: Simple preference optimization with a reference-free reward , author=. arXiv preprint arXiv:2405.14734 , year=
-
[41]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
arXiv preprint arXiv:2311.08045 , year=
Adversarial preference optimization: Enhancing your alignment via rm-llm game , author=. arXiv preprint arXiv:2311.08045 , year=
-
[43]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[44]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
2025 , howpublished=
Understanding R1-Zero-Like Training: A Critical Perspective , author=. 2025 , howpublished=
2025
-
[46]
ACM transactions on intelligent systems and technology , volume=
A survey on evaluation of large language models , author=. ACM transactions on intelligent systems and technology , volume=. 2024 , publisher=
2024
-
[47]
arXiv preprint arXiv:2406.11191 , year=
A Survey on Human Preference Learning for Large Language Models , author=. arXiv preprint arXiv:2406.11191 , year=
-
[48]
arXiv preprint arXiv:2404.08555 , year=
RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs , author=. arXiv preprint arXiv:2404.08555 , year=
-
[49]
arXiv preprint arXiv:2307.12966 , year=
Aligning large language models with human: A survey , author=. arXiv preprint arXiv:2307.12966 , year=
-
[50]
arXiv preprint arXiv:2304.05302 , year=
Rrhf: Rank responses to align language models with human feedback without tears , author=. arXiv preprint arXiv:2304.05302 , year=
-
[51]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Direct preference optimization: Your language model is secretly a reward model , author=. arXiv preprint arXiv:2305.18290 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
arXiv preprint arXiv:2309.06657 , year=
Statistical Rejection Sampling Improves Preference Optimization , author=. arXiv preprint arXiv:2309.06657 , year=
-
[53]
RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
Raft: Reward ranked finetuning for generative foundation model alignment , author=. arXiv preprint arXiv:2304.06767 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
2023 , eprint=
OpenChat: Advancing Open-source Language Models with Mixed-Quality Data , author=. 2023 , eprint=
2023
-
[56]
Proceedings of NAACL-HLT , pages=
Can Neural Machine Translation be Improved with User Feedback? , author=. Proceedings of NAACL-HLT , pages=
-
[57]
Fine-Tuning Language Models from Human Preferences
Fine-tuning language models from human preferences , author=. arXiv preprint arXiv:1909.08593 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[58]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Advances in Neural Information Processing Systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in Neural Information Processing Systems , volume=
-
[62]
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. arXiv preprint arXiv:2402.14008 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
2024 , eprint=
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement , author=. 2024 , eprint=
2024
-
[64]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild , author=. arXiv preprint arXiv:2503.18892 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
2025 , eprint=
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model , author=. 2025 , eprint=
2025
-
[66]
Process Reinforcement through Implicit Rewards
Process reinforcement through implicit rewards , author=. arXiv preprint arXiv:2502.01456 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
arXiv preprint arXiv:2506.07527 , year=
Learning What Reinforcement Learning Can't: Interleaved Online Fine-Tuning for Hardest Questions , author=. arXiv preprint arXiv:2506.07527 , year=
-
[69]
international conference on machine learning , pages=
Dropout as a bayesian approximation: Representing model uncertainty in deep learning , author=. international conference on machine learning , pages=. 2016 , organization=
2016
-
[70]
2009 , publisher=
Active learning literature survey , author=. 2009 , publisher=
2009
-
[71]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[73]
arXiv preprint arXiv:2404.00213 , year=
Injecting new knowledge into large language models via supervised fine-tuning , author=. arXiv preprint arXiv:2404.00213 , year=
-
[74]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? , author=. arXiv preprint arXiv:2504.13837 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
TemplateRL: Structured Template-Guided Reinforcement Learning for LLM Reasoning
Thought-Augmented Policy Optimization: Bridging External Guidance and Internal Capabilities , author=. arXiv preprint arXiv:2505.15692 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[76]
Hu, Jingcheng and Zhang, Yinmin and Han, Qi and Jiang, Daxin and Zhang, Xiangyu and Shum, Heung-Yeung , journal=
-
[77]
2025 , eprint=
KodCode: A Diverse, Challenging, and Verifiable Synthetic Dataset for Coding , author=. 2025 , eprint=
2025
-
[78]
Ponti and Ivan Titov , title =
Zeyu Huang and Zihan Qiu and Zili Wang and Edoardo M. Ponti and Ivan Titov , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[79]
The Thirteenth International Conference on Learning Representations,
Xiaosen Zheng and Tianyu Pang and Chao Du and Qian Liu and Jing Jiang and Min Lin , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[80]
Open R1: A fully open reproduction of DeepSeek-R1 , url =
Hugging Face , month =. Open R1: A fully open reproduction of DeepSeek-R1 , url =
-
[81]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement , author=. arXiv preprint arXiv:2409.12122 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.