CoGS: Compositional Dynamic Human-Object Scenes Gaussian Splatting from Monocular Video
Pith reviewed 2026-06-30 10:22 UTC · model grok-4.3
The pith
CoGS decomposes monocular video into separate Gaussian branches for articulated humans, rigid objects, and static scenes, stabilized by a six-stage optimization schedule.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
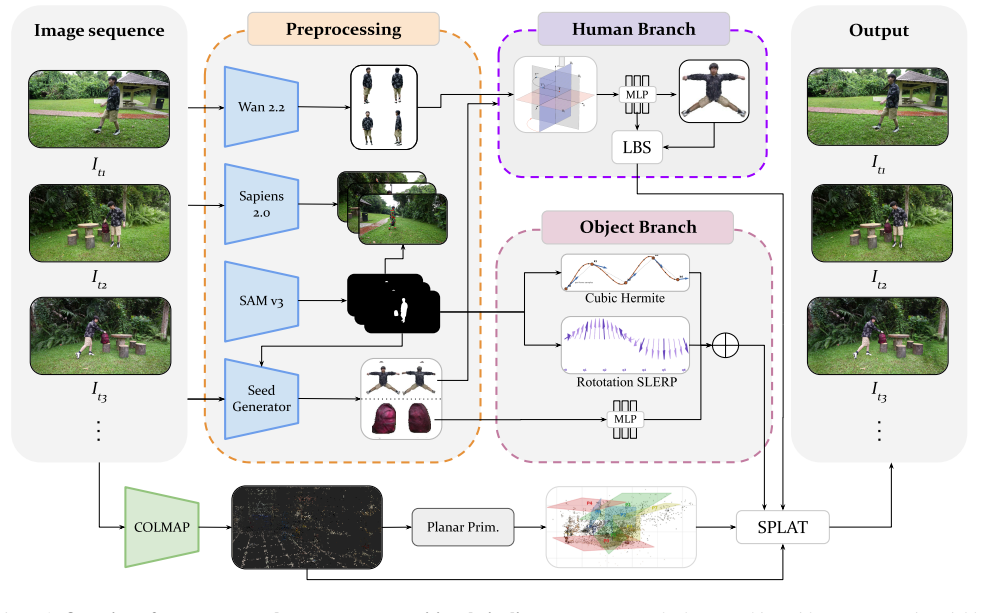
CoGS decomposes the video into three coordinated branches: an articulated human initialized from a complete canonical prior, a rigid object field driven by an estimated object trajectory, and a static scene field regularized by weak scene-only planar primitives when available. A six-stage optimization schedule first stabilizes the human and object independently, then fuses them with the scene under full-image supervision, visibility-aware human anchoring, object silhouette and motion constraints, and delayed scene regularization. This design keeps each component responsible for its own geometry and motion while allowing photometric evidence to correct the final composite.
What carries the argument
The compositional framework of three coordinated Gaussian branches managed by a six-stage optimization schedule that stabilizes components independently before fusion.
If this is right
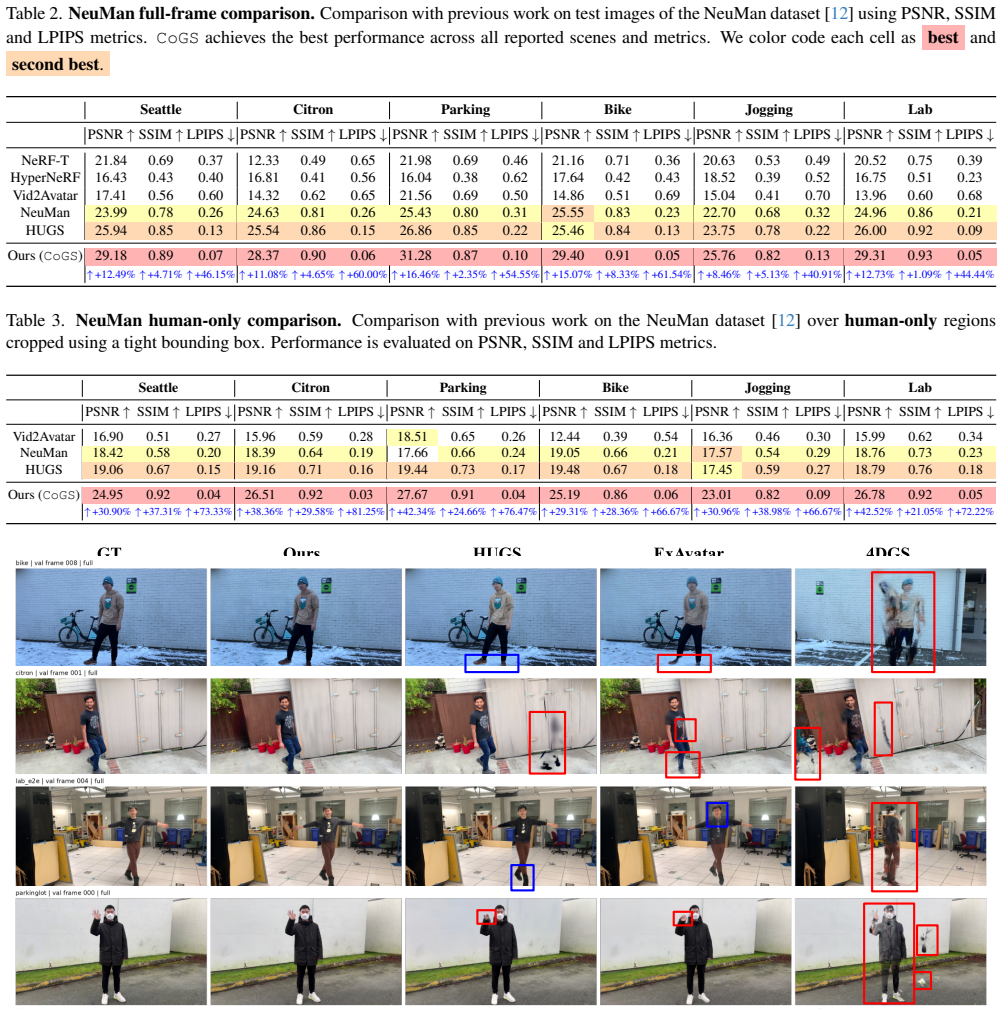
- Improved human-object interaction reconstruction on HOSNeRF without motion leakage into the human or scene.
- Stronger in-the-wild human-scene rendering on NeuMan across full-frame and human-focused metrics.
- Higher fidelity and perceptual quality than prior dynamic radiance-field or Gaussian methods that entangle components.
- Each branch remains responsible for its geometry and motion while the final composite is corrected by photometric evidence.
- Delayed scene regularization and object silhouette constraints keep the static background stable during fusion.
Where Pith is reading between the lines
- The staged independent stabilization could be tested on other multi-motion scenes such as multiple rigid objects or animals.
- Explicit branch separation might support post-reconstruction editing of the human or object in isolation.
- Removing the canonical human prior would likely require new initialization constraints to maintain the same separation.
- The method suggests that explicit motion-model decomposition is useful whenever pixels are shared across differently moving elements.
Load-bearing premise
The articulated human can be initialized from a complete canonical prior and the six-stage schedule can stabilize the human and object independently before fusion without motion leakage between components.
What would settle it
A single entangled Gaussian field or an optimization without the staged separation producing equal or better fidelity and perceptual scores on the HOSNeRF and NeuMan datasets would show the decomposition is not required.
Figures

read the original abstract
Reconstructing dynamic human--object interaction scenes from monocular video is difficult because the human, manipulated object, and background obey different motion models while sharing the same pixels. Existing dynamic radiance-field and Gaussian-splatting methods often entangle these components, causing object motion to leak into the human or static scene, and monocular human reconstruction remains underconstrained in regions that are rarely observed. We present CoGS, a compositional Gaussian-splatting framework for monocular human--object scene reconstruction. CoGS decomposes the video into three coordinated branches: an articulated human initialized from a complete canonical prior, a rigid object field driven by an estimated object trajectory, and a static scene field regularized by weak scene-only planar primitives when available. A six-stage optimization schedule first stabilizes the human and object independently, then fuses them with the scene under full-image supervision, visibility-aware human anchoring, object silhouette and motion constraints, and delayed scene regularization. This design keeps each component responsible for its own geometry and motion while allowing photometric evidence to correct the final composite. Experiments on HOSNeRF and NeuMan show that CoGS improves both human--object interaction reconstruction and in-the-wild human--scene rendering, achieving stronger fidelity and perceptual quality across full-frame and human-focused evaluations. Code will be released upon publication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CoGS, a compositional Gaussian-splatting framework for monocular reconstruction of dynamic human-object interaction scenes. It decomposes the scene into three branches—an articulated human initialized from a canonical prior, a rigid object driven by estimated trajectory, and a static scene field—and optimizes them via a six-stage schedule that first stabilizes human and object independently before fusing under full-image supervision with visibility-aware anchoring, silhouette constraints, and delayed scene regularization. Experiments on HOSNeRF and NeuMan are claimed to show improved fidelity and perceptual quality over HOSNeRF and NeuMan baselines for both interaction reconstruction and in-the-wild rendering.
Significance. If the staged optimization demonstrably prevents motion leakage while preserving component-specific geometry, the method would offer a practical advance over entangled dynamic radiance fields by explicitly handling differing motion models within shared pixels, with potential utility for in-the-wild human-scene applications.
major comments (1)
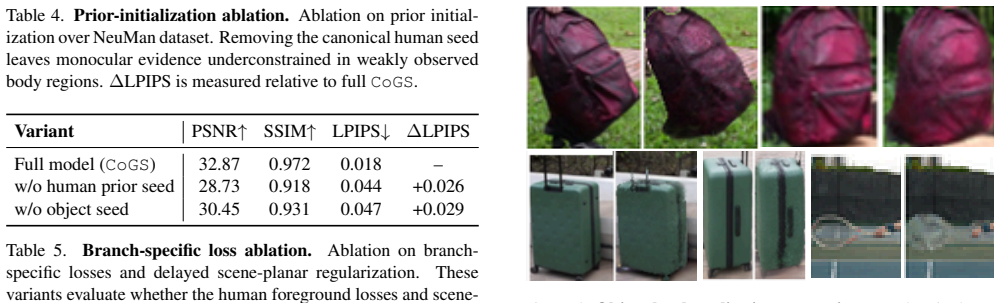
- [Abstract and method description of six-stage optimization schedule] The central claim that the six-stage schedule decouples the articulated human (from complete canonical prior) and rigid object (from estimated trajectory) without motion leakage into each other or the static scene rests on unverified assumptions; no ablations, leakage metrics, or failure-case analysis are referenced to show that visibility-aware anchoring and silhouette constraints suffice when photometric evidence is shared across branches under monocular in-the-wild conditions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the central claim regarding the six-stage optimization. We address the concern point by point below.
read point-by-point responses
-
Referee: [Abstract and method description of six-stage optimization schedule] The central claim that the six-stage schedule decouples the articulated human (from complete canonical prior) and rigid object (from estimated trajectory) without motion leakage into each other or the static scene rests on unverified assumptions; no ablations, leakage metrics, or failure-case analysis are referenced to show that visibility-aware anchoring and silhouette constraints suffice when photometric evidence is shared across branches under monocular in-the-wild conditions.
Authors: We acknowledge that the current manuscript does not include dedicated ablations, quantitative leakage metrics, or explicit failure-case analysis isolating the effect of the six-stage schedule on motion leakage. The design rationale is that independent stabilization of the human (via canonical prior) and object (via trajectory) in early stages, followed by visibility-aware anchoring, silhouette constraints, and delayed scene regularization, assigns responsibility for geometry and motion to each branch before full photometric supervision. The reported improvements over HOSNeRF and NeuMan baselines on both datasets are presented as indirect evidence that leakage is mitigated relative to entangled baselines. However, this does not constitute direct verification under shared-pixel monocular conditions. We will therefore add, in the revised manuscript: (i) an ablation removing individual stages of the schedule, (ii) a leakage metric based on cross-component optical-flow consistency between branches, and (iii) qualitative failure-case analysis on sequences with heavy occlusion or ambiguous photometric evidence. These additions will directly test whether the anchoring and silhouette constraints suffice. revision: yes
Circularity Check
No circularity: framework relies on external priors, datasets, and staged optimization without self-referential reductions.
full rationale
The abstract and available description present CoGS as a new compositional Gaussian-splatting pipeline that decomposes scenes into human, object, and scene branches, initialized from a canonical prior and optimized via a six-stage schedule. No equations, fitted parameters renamed as predictions, or self-citations are shown that would make any claimed result equivalent to its inputs by construction. The method is benchmarked on external datasets (HOSNeRF, NeuMan) with standard techniques, making the derivation self-contained against those benchmarks. No load-bearing step reduces to a self-definition or fitted input.
Axiom & Free-Parameter Ledger
free parameters (1)
- stage-specific regularization weights and constraints
axioms (2)
- domain assumption Human model can be initialized from a complete canonical prior
- domain assumption Object trajectory can be estimated independently to drive the rigid field
invented entities (1)
-
Three coordinated compositional branches
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Per-Gaussian Embedding- Based Deformation for Deformable 3D Gaussian Splatting
Jeongmin Bae, Seoha Kim, Youngsik Yun, Hahyun Lee, Gun Bang, and Youngjung Uh. Per-Gaussian Embedding- Based Deformation for Deformable 3D Gaussian Splatting. InEuropean Conference on Computer Vision, pages 321–
-
[2]
Springer, 2024. 1, 2, 6
2024
-
[3]
BEHA VE: Dataset and Method for Tracking Human Object Interactions
Bharat Lal Bhatnagar, Xianghui Xie, Ilya A Petrov, Cristian Sminchisescu, Christian Theobalt, and Gerard Pons-Moll. BEHA VE: Dataset and Method for Tracking Human Object Interactions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15935– 15946, 2022. 2
2022
-
[4]
Jerrin Bright, Bavesh Balaji, Harish Prakash, Yuhao Chen, David A Clausi, and John Zelek. Distribution and depth- aware transformers for 3d human mesh recovery.arXiv preprint arXiv:2403.09063, 4(6):7, 2024. 2
-
[5]
Zelek, and David A
Jerrin Bright, Zhibo Wang, Yuhao Chen, Sirisha Rambhatla, John S. Zelek, and David A. Clausi. Gen4d: Synthesizing humans and scenes in the wild. InWorkshop on Computer Vision in the Wild at CVPR, 2025. 2
2025
-
[6]
HexPlane: A Fast Representa- tion for Dynamic Scenes
Ang Cao and Justin Johnson. HexPlane: A Fast Representa- tion for Dynamic Scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 130–141, 2023. 2
2023
-
[7]
ARCTIC: A Dataset for Dexterous Bimanual Hand- Object Manipulation
Zicong Fan, Omid Taheri, Dimitrios Tzionas, Muhammed Kocabas, Manuel Kaufmann, Michael J Black, and Otmar Hilliges. ARCTIC: A Dataset for Dexterous Bimanual Hand- Object Manipulation. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 12943–12954, 2023. 2
2023
-
[8]
HOLD: Category-Agnostic 3D Reconstruction of Interact- ing Hands and Objects from Video
Zicong Fan, Maria Parelli, Maria Eleni Kadoglou, Xu Chen, Muhammed Kocabas, Michael J Black, and Otmar Hilliges. HOLD: Category-Agnostic 3D Reconstruction of Interact- ing Hands and Objects from Video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 494–504, 2024. 2
2024
-
[9]
K- Planes: Explicit Radiance Fields in Space, Time, and Ap- pearance
Sara Fridovich-Keil, Giacomo Meanti, Frederik Rahbæk Warburg, Benjamin Recht, and Angjoo Kanazawa. K- Planes: Explicit Radiance Fields in Space, Time, and Ap- pearance. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12479– 12488, 2023. 2, 6
2023
-
[10]
Vid2Avatar: 3D Avatar Reconstruction from Videos in the Wild via Self-Supervised Scene Decomposi- tion
Chen Guo, Tianjian Jiang, Xu Chen, Jie Song, and Ot- mar Hilliges. Vid2Avatar: 3D Avatar Reconstruction from Videos in the Wild via Self-Supervised Scene Decomposi- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 12858–12868,
-
[11]
GaussianAvatar: Towards Realistic Human Avatar Modeling from a Single Video via Animatable 3D Gaussians
Liangxiao Hu, Hongwen Zhang, Yuxiang Zhang, Boyao Zhou, Boning Liu, Shengping Zhang, and Liqiang Nie. GaussianAvatar: Towards Realistic Human Avatar Modeling from a Single Video via Animatable 3D Gaussians. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 634–644, 2024. 2
2024
-
[12]
GauHuman: Artic- ulated Gaussian Splatting from Monocular Human Videos
Shoukang Hu, Tao Hu, and Ziwei Liu. GauHuman: Artic- ulated Gaussian Splatting from Monocular Human Videos. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 20418–20431, 2024. 2
2024
-
[13]
NeuMan: Neural Human Radiance Field from a Single Video
Wei Jiang, Kwang Moo Yi, Golnoosh Samei, Oncel Tuzel, and Anurag Ranjan. NeuMan: Neural Human Radiance Field from a Single Video. InEuropean Conference on Com- puter Vision, pages 402–418. Springer, 2022. 1, 2, 6, 7
2022
-
[14]
3D Gaussian Splatting for Real-Time Radiance Field Rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3D Gaussian Splatting for Real-Time Radiance Field Rendering.ACM Trans. Graph., 42(4):139– 1, 2023. 1, 2
2023
-
[15]
HUGS: Human Gaussian Splats
Muhammed Kocabas, Jen-Hao Rick Chang, James Gabriel, Oncel Tuzel, and Anurag Ranjan. HUGS: Human Gaussian Splats. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 505–515, 2024. 1, 2
2024
-
[16]
Fully Explicit Dynamic Gaussian Splat- ting.Advances in Neural Information Processing Systems, 37:5384–5409, 2024
Junoh Lee, ChangYeon Won, Hyunjun Jung, Inhwan Bae, and Hae-Gon Jeon. Fully Explicit Dynamic Gaussian Splat- ting.Advances in Neural Information Processing Systems, 37:5384–5409, 2024. 1, 2, 6
2024
-
[17]
HOSNeRF: Dynamic Human-Object-Scene Neural Radiance Fields from a Single Video
Jia-Wei Liu, Yan-Pei Cao, Tianyuan Yang, Zhongcong Xu, Jussi Keppo, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. HOSNeRF: Dynamic Human-Object-Scene Neural Radiance Fields from a Single Video. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 18483–18494, 2023. 1, 2, 6
2023
-
[18]
MoDGS: Dy- namic gaussian splatting from casually-captured monocular videos with depth priors
Qingming LIU, Yuan Liu, Jiepeng Wang, Xianqiang Lyu, Peng Wang, Wenping Wang, and Junhui Hou. MoDGS: Dy- namic gaussian splatting from casually-captured monocular videos with depth priors. InThe Thirteenth International Conference on Learning Representations, 2025. 1, 2
2025
-
[19]
SMPL: A Skinned Multi-Person Linear Model.ACM Transactions on Graphics (TOG), 34(6):248:1–248:16, 2015
Matthew Loper, Naureen Mahmood, Javier Romero, Ger- ard Pons-Moll, and Michael J Black. SMPL: A Skinned Multi-Person Linear Model.ACM Transactions on Graphics (TOG), 34(6):248:1–248:16, 2015. 1, 2
2015
-
[20]
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis.Communications of the ACM, 65(1):99–106,
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis.Communications of the ACM, 65(1):99–106,
-
[21]
Aymen Mir, Arthur Moreau, Helisa Dhamo, Zhensong Zhang, and Eduardo P ´erez-Pellitero. GASPACHO: Gaus- sian Splatting for Controllable Humans and Objects.arXiv preprint arXiv:2503.09342, 2025. 2
-
[22]
Expressive Whole-Body 3D Gaussian Avatar
Gyeongsik Moon, Takaaki Shiratori, and Shunsuke Saito. Expressive Whole-Body 3D Gaussian Avatar. InEuropean Conference on Computer Vision, pages 19–35. Springer,
-
[23]
Nerfies: Deformable Neural Radiance Fields
Keunhong Park, Utkarsh Sinha, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Steven M Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable Neural Radiance Fields. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 5865–5874, 2021. 1, 2, 6
2021
-
[24]
Keunhong Park, Utkarsh Sinha, Peter Hedman, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Ricardo Martin- Brualla, and Steven M Seitz. HyperNeRF: A Higher- Dimensional Representation for Topologically Varying Neu- 9 ral Radiance Fields.arXiv preprint arXiv:2106.13228, 2021. 1, 2, 6
- [25]
-
[26]
Expressive Body Capture: 3D Hands, Face, and Body from a Single Image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive Body Capture: 3D Hands, Face, and Body from a Single Image. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10975–10985, 2019. 1, 2
2019
-
[27]
Neural Body: Implicit Neural Representations with Structured La- tent Codes for Novel View Synthesis of Dynamic Humans
Sida Peng, Yuanqing Zhang, Yinghao Xu, Qianqian Wang, Qing Shuai, Hujun Bao, and Xiaowei Zhou. Neural Body: Implicit Neural Representations with Structured La- tent Codes for Novel View Synthesis of Dynamic Humans. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 9054–9063, 2021. 2
2021
-
[28]
3DGS-Avatar: Animatable Avatars via Deformable 3D Gaussian Splatting
Zhiyin Qian, Shaofei Wang, Marko Mihajlovic, Andreas Geiger, and Siyu Tang. 3DGS-Avatar: Animatable Avatars via Deformable 3D Gaussian Splatting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5020–5030, 2024. 2
2024
-
[29]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. SAM 2: Segment Anything in Images and Videos. arXiv preprint arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digi- tization
Shunsuke Saito, Zeng Huang, Ryota Natsume, Shigeo Mor- ishima, Angjoo Kanazawa, and Hao Li. PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digi- tization. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 2304–2314, 2019. 2
2019
-
[31]
PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization
Shunsuke Saito, Tomas Simon, Jason Saragih, and Hanbyul Joo. PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 84–93, 2020. 2
2020
-
[32]
Structure- from-Motion Revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure- from-Motion Revisited. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 4104–4113, 2016. 1
2016
-
[33]
DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. DreamGaussian: Generative Gaussian Splat- ting for Efficient 3D Content Creation.arXiv preprint arXiv:2309.16653, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Hu- manNeRF: Free-Viewpoint Rendering of Moving People from Monocular Video
Chung-Yi Weng, Brian Curless, Pratul P Srinivasan, Jonathan T Barron, and Ira Kemelmacher-Shlizerman. Hu- manNeRF: Free-Viewpoint Rendering of Moving People from Monocular Video. InProceedings of the IEEE/CVF conference on computer vision and pattern Recognition, pages 16210–16220, 2022. 2
2022
-
[35]
4D Gaussian Splatting for Real-Time Dynamic Scene Ren- dering
Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 4D Gaussian Splatting for Real-Time Dynamic Scene Ren- dering. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 20310–20320,
-
[36]
Dˆ2-NeRF: Self-Supervised Decoupling of Dynamic and Static Objects from a Monocu- lar Video.Advances in neural information processing sys- tems, 35:32653–32666, 2022
Tianhao Wu, Fangcheng Zhong, Andrea Tagliasacchi, For- rester Cole, and Cengiz Oztireli. Dˆ2-NeRF: Self-Supervised Decoupling of Dynamic and Static Objects from a Monocu- lar Video.Advances in neural information processing sys- tems, 35:32653–32666, 2022. 2, 6
2022
-
[37]
Rendering Humans from Object-Occluded Monoc- ular Videos
Tiange Xiang, Adam Sun, Jiajun Wu, Ehsan Adeli, and Li Fei-Fei. Rendering Humans from Object-Occluded Monoc- ular Videos. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3239–3250, 2023. 1, 2
2023
-
[38]
Wild2Avatar: Rendering Humans Behind Occlusions.arXiv preprint arXiv:2401.00431, 2024
Tiange Xiang, Adam Sun, Scott Delp, Kazuki Kozuka, Li Fei-Fei, and Ehsan Adeli. Wild2Avatar: Rendering Humans Behind Occlusions.arXiv preprint arXiv:2401.00431, 2024. 1, 2
-
[39]
ICON: Implicit Clothed Humans Obtained from Normals
Yuliang Xiu, Jinlong Yang, Dimitrios Tzionas, and Michael J Black. ICON: Implicit Clothed Humans Obtained from Normals. In2022 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 13286–13296. IEEE, 2022. 2
2022
-
[40]
ECON: Explicit Clothed Humans Optimized via Normal Integration
Yuliang Xiu, Jinlong Yang, Xu Cao, Dimitrios Tzionas, and Michael J Black. ECON: Explicit Clothed Humans Optimized via Normal Integration. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 512–523, 2023. 2
2023
-
[41]
HSR: Holistic 3D Human-Scene Recon- struction from Monocular Videos
Lixin Xue, Chen Guo, Chengwei Zheng, Fangjinhua Wang, Tianjian Jiang, Hsuan-I Ho, Manuel Kaufmann, Jie Song, and Otmar Hilliges. HSR: Holistic 3D Human-Scene Recon- struction from Monocular Videos. InEuropean Conference on Computer Vision, 2024. 2
2024
-
[42]
Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction
Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 20331–20341, 2024. 1, 2, 6
2024
-
[43]
Zetong Zhang, Manuel Kaufmann, Lixin Xue, Jie Song, and Martin R. Oswald. ODHSR: Online Dense 3D Reconstruc- tion of Humans and Scenes from Monocular Videos. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 2 10
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.